딥러닝을 공부할 때 접하는 용어들을 간략하게 정리해보았다.
1. NN 기초
-
뉴런
뉴런 구조도에서 동그라미로 표시되는 부분으로, '노드'라고도 한다. input 값과 weight(가중치), bias(편향)을 사용해서 연산을 수행한다. -
weight
input 신호에 대해서 필터 역할을 한다. 각 뉴런은 input 신호에 할당된 각각의 가중치를 곱해서 넘겨 받는데, 해당 input 신호가 결과에 미칠 영향력을 가중치의 크기를 통해서 조절한다. -
bias
각 노드의 활성화 여부를 조절하는 역할을 한다. 각 노드마다 독립적인 bias를 가지고 있으며, 가중치처럼 학습에 의해 업데이트 된다. -
활성화 함수
출력층과 은닉층에 적용되는 함수로, input 값, weight, bias를 사용해서 구한 가중합을 다음 뉴런으로 넘겨주기 전에 조정하는 역할을 한다. 예를 들어, 이진 분류 문제에서는 출력층에 sigmoid 함수를 사용하고, 다중 분류 문제에서는 출력층에 softmax 함수를 사용한다. 이처럼 활성화 함수는 풀고자 하는 문제에 따라 알맞게 선택해야 한다.-
sigmoid
-
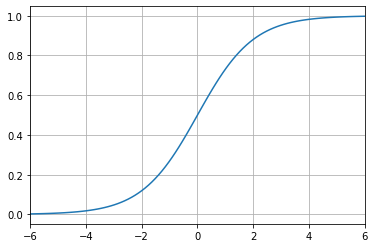
이진 분류의 output layer에 sigmoid 함수를 사용하면 output 값이 0.5보다 크면 1, 0.5보다 작으면 0으로 분류한다.
-
softmax
다중 분류의 output layer에서 많이 사용하는 함수로, 모든 input 값을 0 ~ 1 사이의 값으로 변환한다. 이때 output의 합은 1이다. 따라서 이 output을 해당 데이터가 각 클래스에 속할 확률처럼 사용할 수 있다. -
ReLU
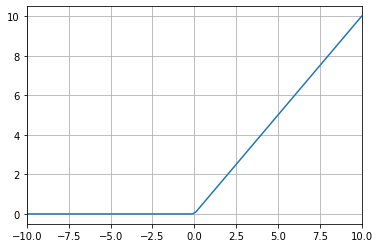
-
Leaky ReLU
(는 보통 0.01로 설정한다.)
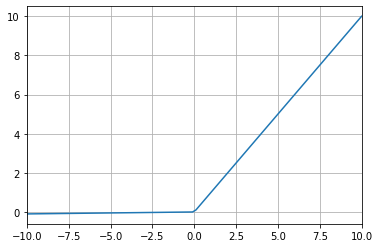
-
tanh
-
layer
- input layer
신경망의 가장 첫 부분으로, 데이터를 입력받는 곳이다. input layer에서는 특정한 계산이 행해지지 않으며, 값을 전달받아서 넘겨주기만 한다. 따라서 신경망의 층수를 셀 때 포함하지 않는다.
- output layer
신경망의 가장 마지막 부분이다. output layer의 노드 수는 타겟의 수와 동일하며, 풀고자 하는 문제에 따라 알맞는 활성화 함수가 적용되어야 한다.
- hidden layer
input layer와 output layer의 사이에 있는 부분이다. 이 곳에서 이뤄지는 계산을 사람이 볼 수 없기 때문에 hidden layer라고 한다. hidden layer에는 활성화 함수를 사용할 수도 있고 사용하지 않을 수도 있으며, 활성화 함수의 노드 수는 input 값과 ouput 값의 수를 고려해서 사람이 직접 정해야 한다.
- input layer
-
퍼셉트론
신경망을 이루는 가장 기본 단위이다. 단층 퍼셉트론의 경우, input layer와 output layer로만 이루어져 있으며 input layer의 노드 수는 여러 개이고, output layer의 노드 수는 한 개이다.
2. 신경망 학습
-
역전파
입력층에서 은닉층, 출력층 순서로 가는 것을 순전파(foward propagation)라고 하며, 반대로 출력층에서 은닉층, 입력층 순서로 가는 것을 역전파(back propagation)이라고 한다. 신경망의 오차를 줄이기 위해서, 즉 실제값과 예측값 사이의 차이를 줄이기 위해서는 가중치를 조절하는 수밖에 없다. 실제값은 정해져 있으니 바꿀 수 없는데, 예측값은 가중치와 입력값을 바탕으로 산출되므로 가중치를 변경한다면 예측값을 바꿀 수 있기 때문이다. 역전파는 가중치를 적절하게 조절하기 위해서 사용된다. 출력층에서 은닉층, 입력층으로 순서로 가면서 각 가중치가 변할 때 오차는 얼마나 변하는지를 계산한 값을 사용해서 가중치를 업데이트한다. -
learning rate
한 학습에 대해서 얼마나 weight를 업데이트할 지를 조절하는 값이다. -
(mini-)batch
흔히 batch라고 하면 mini-batch를 말한다. mini-batch는 데이터를 특정 개수만큼 묶어서 각 묶음에 대해서 학습한 후 가중치를 업데이트 하는 방법이다. 이때 한 묶음에 들어가는 데이터의 수를 batch size라고 한다. batch size가 클수록 빠르게 학습할 수 있으나, 데이터를 처리할 때 batch size만큼 병렬처리 하기 때문에 너무 크게 설정할 경우 컴퓨터가 버티지 못한다. -
epoch
train dataset 전체를 학습에 몇 번 사용할 것인가를 나타내는 값이다. 예를 들어 train dataset이 1만 개이고 2epoch만큼 학습한다면, 1만 개의 데이터를 2번 사용해서 학습한다. epoch 값이 너무 작으면 과소적합의 위험이, 너무 크면 과적합의 위험이 있다. -
최적화
- GD
loss function의 기울기를 줄이는 방향으로 이동하면서 loss function이 최솟값을 갖는 지점을 찾는 방법이다.
- Adam
Momentum과 AdaGrad의 장점을 결합한 방법으로, 최솟값이 되는 지점을 찾아갈 때 현재 지점의 정보뿐만 아니라 이전에 이동했던 이동 방향도 고려해서 이동 방향과 학습률을 조절하는 방법이다.
- GD
-
손실함수
-
분류
- binary cross-entropy
이진 분류일 때 사용하는 cross-entropy loss이다.
- categorical cross-entropy
다중분류이고 target이 one-hot encoding 형태로 표현되었을 때 사용하는 cross-entropy loss이다.
- sparse cross-entropy
다중분류이고 target이 integer 형식으로 표현되었을 때 사용하는 cross-entropy loss이다.
- binary cross-entropy
-
회귀
- MAE (Mean Absolute Error)
실제값과 예측값의 차에 절대값을 취한 것을 모두 더하여 평균을 낸 값이다. 타겟과 단위가 같기 때문에 오차의 크기를 직관적으로 알 수 있다.
- MSE (Mean Squared Error)
실제값과 예측값의 차를 제곱해서 모두 더하여 평균을 낸 값이다. 제곱을 하기 때문에 MAE보다 이상치에 민감하다.
- MAE (Mean Absolute Error)
-
-
학습 규제 전략: 과적합을 막기 위한 여러 전략들
-
early stopping
일정 epoch동안 모니터링하는 값(validation loss)이 감소하지 않으면 처음에 설정한 epoch 값에 아직 도달하지 않았어도 학습을 멈춤으로써 weight가 더이상 변하지 않도록 한다.
-
learning rate decay
학습을 할수록 학습률을 감소시키는 전략이다. -
weight decay
weight를 감소하는 전략으로, weight가 커지면 loss가 커지는 것이라고 여겨지도록 하여 weight가 매우 커지는 것을 방지한다.- L1
weight의 절대값의 합을 이용하여 작은 weight들은 0에 수렴하도록 하는 방법이다. 따라서 어떤 weight들은 사라진다.
- L2
가중치의 업데이트에 규제를 주는 것은 L1과 동일하나, weight의 제곱의 합을 이용하며 작은 weight를 아예 없애지는 않는다. 를 크게할 수록 가중치에 대한 규제가 더 커진다.
- L1
-
constraints
weight의 값을 물리적으로 제한한다. 예를 들어, max(x, 3)으로 설정한다면 가중치가 3보다 클 경우 무조건 3으로 대체한다. weight decay보다 조금 더 강하게 규제하는 셈이다. -
dropout
랜덤한 특정 노드의 input을 0으로 변경해버린다. 즉, 노드를 랜덤하게 일시적으로 끊어버림으로써 해당 뉴런 없이 학습을 하도록 하여 과적합을 방지한다.
-
-
Transfer learning
학습된 모델을 가져와서 필요한 부분만 잘라서 사용하는 것을 말한다. 학습할 때 다른 모델에서 가져온 부분의 가중치는 고정한 채 사용자가 새로 만든 부분에 대해서만 학습을 할 수도 있고, 모델 전체를 다 재학습할 수도 있다. 새로 만든 부분에 대해서만 학습할 경우 학습 데이터를 적게 사용하고, 학습 속도가 빠르며, 더 일반화가 잘 된 모델을 만들 수 있다는 장점이 있다.
3. CNN
-
conv
convolution을 사용하면 fully connected layer를 사용할 때보다 weight의 수가 현저하게 줄어든다.- filter
weight의 집합으로, 데이터의 특징을 잡아낸다.
- stride
filter를 움직일 칸 수를 말한다. 예를 들어, stride가 1이면 filter를 한 칸씩 움직이며, stride가 2이면 filter를 한 칸 건너뛰어 두 칸씩 움직인다.
- padding
데이터셋의 외곽을 0 또는 다른 값으로 둘러싸는 것을 말한다. 만약 padding을 하지 않은 상태에서 convolution 연산을 한다면 데이터셋의 크기가 줄어들며, 가장 끝에 있는 데이터는 안쪽에 위치한 데이터에 비해서 사용되는 횟수가 적을 것이다. 하지만 padding을 해주면 데이터를 고루고루 쓸 수 있으며, convolution 연산을 해도 크기가 유지되므로 다루기 편리하다.
- filter
-
pooling
feature map의 차원을 줄일 수 있다. 보통 convolution 연산을 수행한 후에 pooling layer를 사용한다.- max
특징을 추출하는 창 안에서 가장 큰 값을 추출한다.
- avg
특징을 추출하는 창 안의 값들의 평균 값을 추출한다.
- size
특징을 추출할 창의 크기를 말한다.
- stride
특징을 추출하는 창이 이동하는 칸 수를 말한다.
- max
4. RNN
-
RNN
RNN에는 순환 구조, 즉 자기 자신으로 돌아오는 edge가 있다. 이 때문에 데이터의 순서 정보를 이용할 수 있으며, 주식, 날씨, 언어 등 시계열 데이터를 다룰 때 주로 사용한다. -
LSTM
RNN의 Gradient vanishing 문제를 해결하기 위해서 등장했다. forget gate, input gate, ouput gate를 사용해서 이전 정보를 얼마나 잊어버릴지, 현재 정보는 얼마나 반영할지, 정보를 얼마나 밖으로 표출할지를 결정한다. LSTM의 장점은 최근 사건에 더 많은 비중을 둘 수 있음과 동시에 오래 전의 정보를 완전히 잃지 않을 수 있다는 것이다. -
GRU
LSTM은 gate 수가 너무 많다는 단점이 있다. LSTM의 구조를 간소화하여 gate의 수를 줄이기 위해서 등장한 것이 GRU이다. GRU에서는 forget gate와 input gate가 하나로 합쳐져 있으며(), output gate는 없다. 를 통해서 현재 정보와 과거 정보의 비율을 결정하며, 를 통해서 과거 정보에서 출력될 부분을 제어한다. -
Bidirectional RNN
Bidirectional RNN은 '아버지가 ( )에 들어가신다.'에서 괄호를 채우는 문제처럼, 특정 시점의 데이터를 예측할 때 이전 시점의 데이터 뿐만 아니라 이후 시점의 데이터들도 고려한다. 즉, 기존의 RNN이 시간 순서대로 한 방향으로의 정보만을 사용하였다면, Bidirectional RNN은 순방향뿐만 아니라 시간 순서의 역방향을 처리하는 RNN을 추가함으로써 문맥을 더 잘 이해할 수 있게 해준다. -
Attention
- Transformer
기존의 RNN은 데이터를 순서대로 넣어서 처리해야 했다. 그런데 Transformer는 Encoder 부분에서 RNN을 제거하고 순서 정보를 아예 임베딩하여 attention으로 변경하므로 데이터를 순서대로 처리할 필요가 없어졌다.
- Transformer
5. 활용
-
Autoencoder
입력된 데이터에서 중요한 특성을 추출하여 차원을 축소할 수 있는 도구이다. Encoder와 Decoder 구조로 되어있으며, Encoder는 차원을 축소하는 부분이고 Decoder는 차원을 원래의 상태로 되돌리는 부분이다. 입력된 데이터가 Encoder를 통과하면서 차원이 축소되면 그 결과물이 중요한 특성만 남이있는 게 맞는지, 제대로 차원이 축소된 것인지 알 수 없다. 해당 데이터를 축소하면 어떤 값을 가지고 있어야 한다는 답안이 없기 때문이다. 따라서 차원 축소한 결과물을 Decoder를 사용해서 다시 원래 차원으로 복구한 후 원본 데이터와 복구된 데이터가 얼마나 다른지 비교해서 Encoder가 차원 축소를 제대로 하고 있는지 확인한다. 이때 Encoder와 Decoder는 가중치를 공유하고 있으며, 원본 데이터와 차원 축소 후 복구된 데이터의 차이를 줄이는 방향으로 학습한다. -
GAN
- DCGAN
DCGAN의 목적은 세상에 있을 법한 이미지를 만들어내는 것이다. Generator와 Discriminator로 이루어져 있는데, Generator는 가짜 이미지를 만드는 부분이고 Discriminator는 만들어진 이미지가 가짜인지 진짜인지 판별하는 부분이다. 우리가 원하는 것은 성능 좋은 Generator인데, 이를 위해서는 성능 좋은 Discriminator가 필요하다. 만약 가짜 이미지와 진짜 이미지를 정말 잘 구별해내는 Discriminator가 있고 Generator가 만든 이미지가 이 Discriminator를 속일 수 있다면 Generator의 성능이 뛰어난 것이기 때문이다. 그래서 Generator와 Discriminator는 가중치를 공유하고 있고, Generator는 가짜 이미지를 잘 만들도록, Discrinator는 가짜 이미지와 진짜 이미지를 잘 구별해내도록 loss function이 설정되어 있어서 학습을 거듭할수록 Generator와 Discriminator의 성능이 모두 올라간다.
- CycleGAN
CycleGAN은 원래의 형상은 유지하면서 특성만 변환하는 도구이다. 예를 들어, 말과 얼룩말 사진이 주어지면 말을 얼룩말으로, 얼룩말은 말으로 변경하되 무늬나 색깔 등 말과 얼룩말을 구별할 수 있는 특징만 변경되며 위치 등은 변경되지 않는다. CycleGAN을 학습할 때는 (말, 얼룩말), (오렌지, 사과) 등 이미지 쌍이 필요하다. 학습을 할 때는 말을 얼룩말으로 바꾼 이미지는 얼룩말인지 아닌지 판단하여 얼룩말이라고 판단되도록, 또 변경된 이미지를 다시 말로 바꿔서 원본과 비교함으로써 다른 속성들은 그대로 유지되었는지 판단하며 그 차이를 줄이는 방향으로 학습한다.
- DCGAN
6. project
- Siamse Neural Network
두 개의 입력값을 각각의 layer를 통과하도록 처리하는데, 이때 해당 layer가 서로 동일한 순서로 놓여 있으며, 같은 종류, 같은 순서의 layer끼리는 가중치를 공유하는 구조의 모델을 말한다.
