용어부터 정리하고 넘어가겠습니다.
회귀(Regression)?
회귀는 독립변수(independant variable)를 통해 종속변수(dependant variable)의 값을 예측하는 행위를 말합니다. 쉽게 말하자면, 숫자를 예측하는 것을 말합니다. 일기예보에서 내일의 기온과 강수량을 예측하는 것도, 기업에서 다음 분기 매출액을 예상하는 것도 모두 회귀에 해당하는 셈이죠.
여기서 기온, 강수량, 매출액 등 예상할 값을 종속변수라 하고, 이를 추론하기 위한 다양한 정보들(작년 기온과 강수량, 제품 생산에 필요한 원자재 가격 등)을 독립변수라 합니다.
또한 회귀를 위해선 독립변수와 종속변수 사이에 유의미한 연관성이 있어야 하는데, 이 연관성을 찾는 분석과정을 회귀분석(Regression Analysis)이라고 합니다. 종속변수 하나와 독립변수 하나의 연관성을 분석한다면 단일 회귀 분석(Simple Regression Analysis), 종속변수 하나와 독립변수 여러 개의 연관성을 분석한다면 다중 회귀 분석(Multiple Regression Analysis)이라고 하죠.
회귀과정의 오차
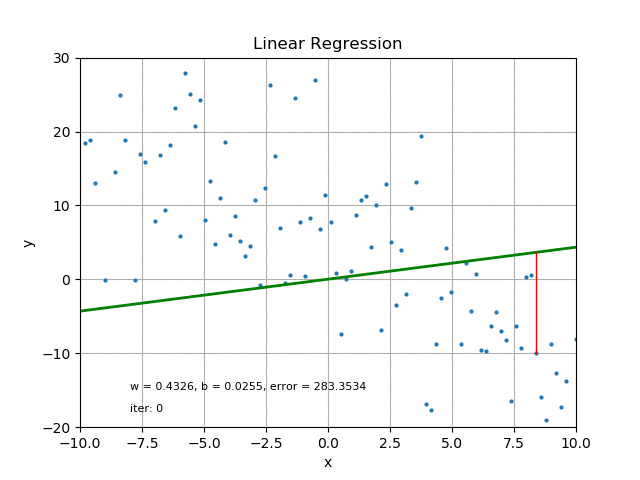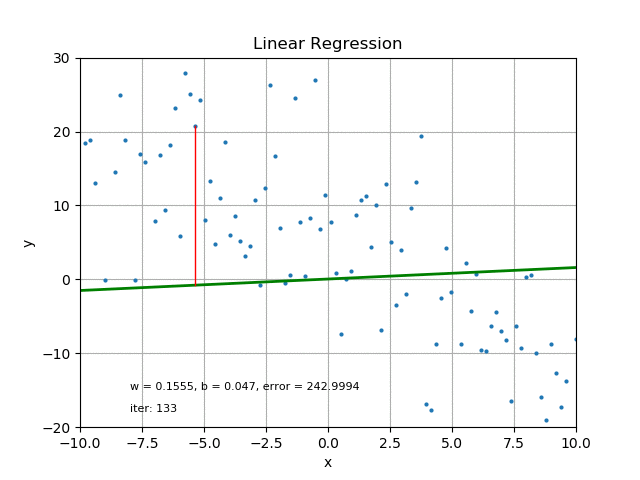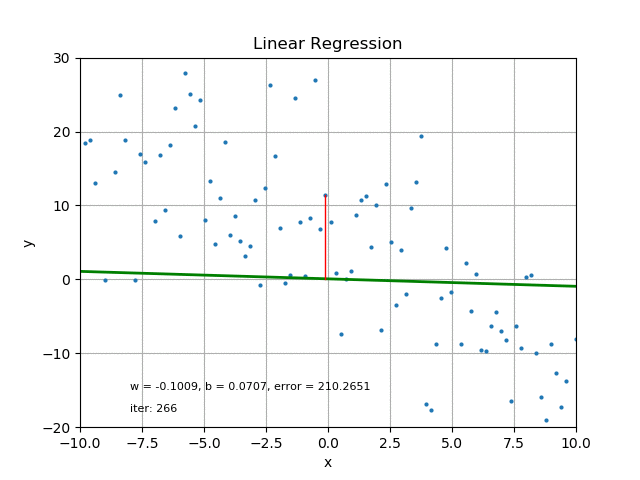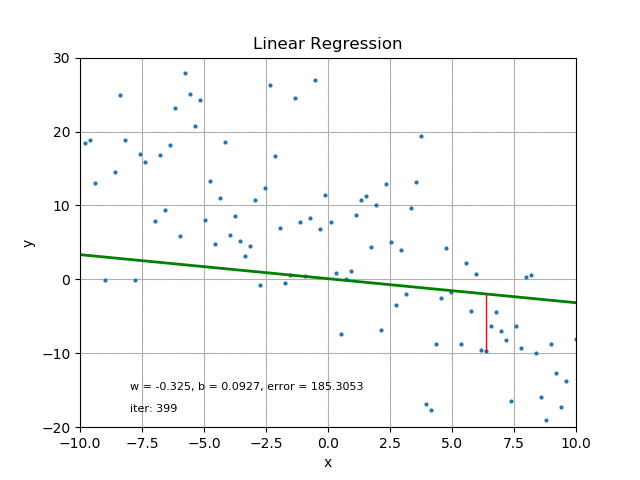
회귀를 완벽하게 해내는 것은 불가능하죠. 아무리 과학기술이 발달한들 내일 오후 3시 12분 서울시청 옥상의 기온을 정확히 아는 것은 먼 미래에도 어려우리라 생각합니다. 그렇기에 당연히 회귀 과정에서는 오차가 발생하게 됩니다. 아래의 그림을 보시면,
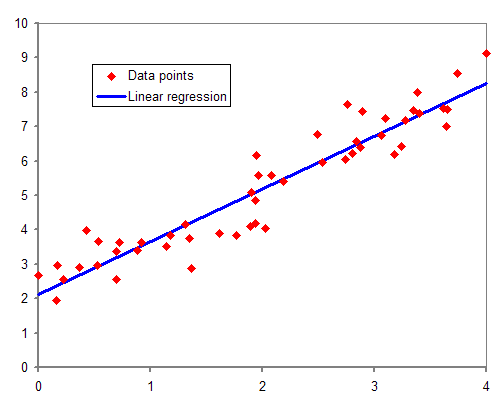
어떤 두 변수 간의 예상된 관계를 푸른색 직선으로, 실제 예측한 데이터를 붉은색 점으로 표현했습니다. 이렇게 예측 결과를 직선의 형태로 표현할 경우 선형 회귀라 하고, 여기서 예측치와 회귀 모델 사이의 오차는 붉은색 점과 푸른색 직선 사이의 수직방향(y축 방향) 거리입니다.
기계학습과정에서는 여러 번의 계산을 통해 오차를 측정하고, 이 오차를 줄이는 방향으로 모델이 계속 업데이트 됩니다. 회귀 모델이 데이터의 전체적인 경향성을 대표할 수 있을 때까지요.
그러나 오차를 계산할 때에도 데이터의 분포 특징을 고려해야 합니다.
가령 두 교실의 키(cm)를 비교하는 상황을 가정해봅시다.
| 반 | 학생1 | 학생2 | 학생3 | 학생4 |
|---|---|---|---|---|
| A | 170 | 174 | 168 | 176 |
| B | 172 | 172 | 171 | 173 |
두 반의 평균 신장은 172cm로 동일합니다. 그러나 오차를 계산하는 상황에서 오차의 값을 그대로 사용하지 않고, 값들에 절댓값을 적용할 경우 두 반에서 측정한 오차는 다음과 같겠지요.
| 반 | 학생1 | 학생2 | 학생3 | 학생4 |
|---|---|---|---|---|
| A | 2 | 2 | 4 | 4 |
| B | 0 | 0 | 1 | 1 |
이렇게 될 경우 "A 반이 평균에서 거리가 더 멀다"는 결론을 내리게 될 수 있기에 상황에 따라 오차를 선택하는 기준이 달라질 수 있습니다.
즉, 오차 함수란, 얼마만큼의 오차를 어떻게 계산할 지에 대한 다양한 접근법이라 보면 될 듯 합니다. 오차를 합리적으로 계산할 경우, 회귀 모델이 데이터를 잘 대표할 수 있는 셈이죠.
대표적 손실함수
를 설명하기에 앞서 각 변수들이 무엇을 의미하는지 말하자면,
= 전체 데이터의 수
= 전체 데이터 중 임의의 값()
= 모델을 통해 예상된 값 / 평균
= 실제 데이터 값/관측치
= 오차
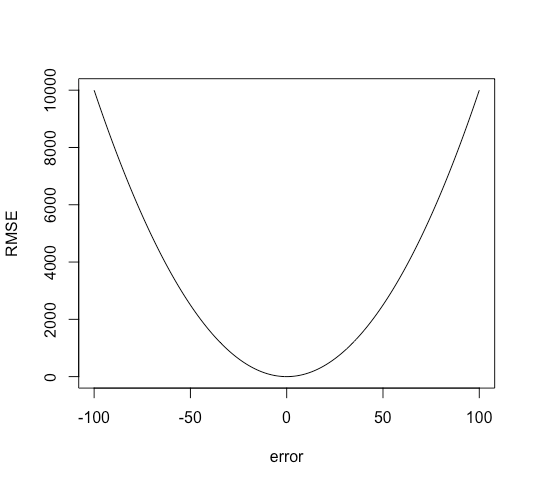
MSE(Mean Squared Error, 평균 제곱 오차)

모든 오차의 제곱값에 대한 평균을 낸 지표입니다.
- 정확성을 추정하는 함수 중 가장 대표적입니다. 이는 계산이 간단하고 분석하기 쉬운 특성(2차함수의 형태)에 기인합니다.
- 오차의 크기(얼만큼 차이가 나는지)는 알 수 있지만, 오차의 방향(기준치보다 큰지 작은지-overestimate or underestimate)은 알 수 없습니다. 제곱 과정에서 부호가 사라지기 때문이겠죠?
- 제곱을 하게되면 오차가 클 수록 손실값이 커지는 경향이 있습니다.
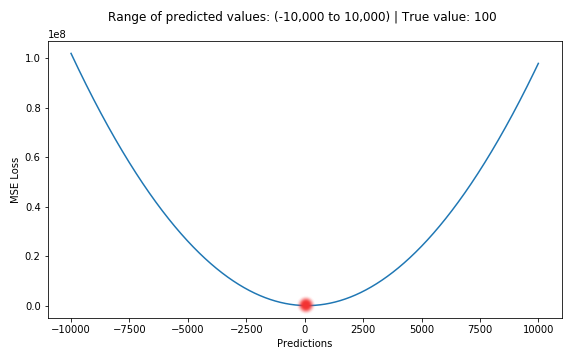 출처: https://medium.com/@DilaneKombou/presentation-of-mse-mean-squared-error-a4ee9b6cff49
출처: https://medium.com/@DilaneKombou/presentation-of-mse-mean-squared-error-a4ee9b6cff49 - 오차가 크게 표현될 수록, 이를 발견하기가 쉽지만, 계산과정에서 손실이 큰 데이터들의 영향력이 손실이 작은 데이터보다 지나치게 큰 영향력을 행사하여 방해가 될 때도 있습니다. 어떻게 사용하는지는 사용자의 재량에 달려있습니다.
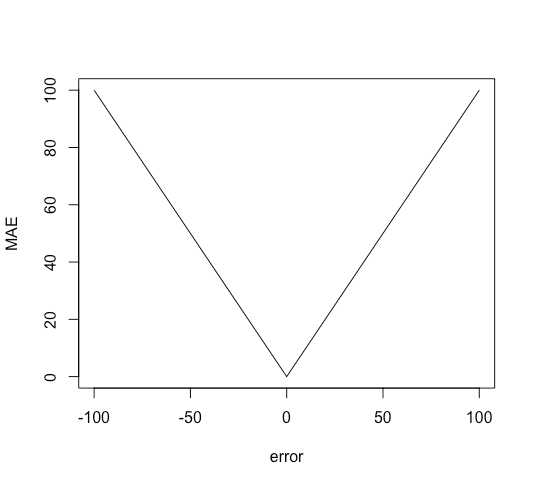
MAE(Mean Absolute Error, 평균 절대 오차)
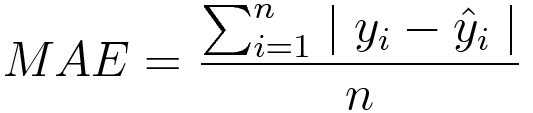
모든 오차에 절댓값을 취하여 평균을 낸 지표입니다.
- MSE와 마찬가지로 오차의 크기를 알 수 있지만, 절댓값 때문에 방향은 알 수 없습니다.
- 계산 과정에서 제곱이 없으므로 오차가 크다 해도 손실이 MSE만큼 기하급수적으로 증가하지는 않습니다.
- 그렇기 때문에 이상치(대푯값과의 차이가 비정상적으로 큰 데이터)가 많은 상황에서 유리한 함수가 되겠습니다.
RMSE(Rooted Mean Squared Error, 평균 제곱근 오차)
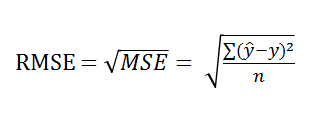
MSE에 근호(Root)를 씌운 지표입니다
- MSE의 특징 중 오차값이 커질 때, 손실은 이의 제곱이 되는 문제를 감쇄하기 위해 고안한 방법입니다.
- 제곱되었던 손실을 제곱근으로 풀어주기 때문에, 이를 직관적으로 판단할 수 있습니다.
- MSE가 갖는 계산의 용이함은 여전히 갖고 있기에 이상치에 강하다고 볼 수 있습니다.
RMSLE(Rooted Mean Squared Logarithmic Error)
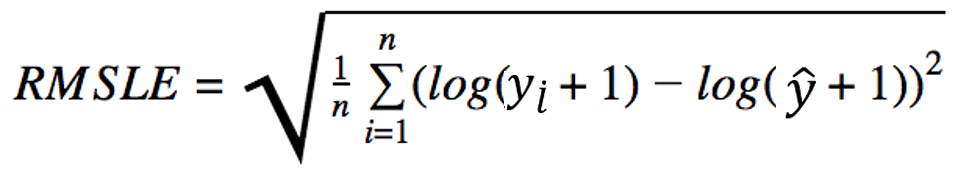
RMSE에 로그를 취한 지표입니다.
- 의 수학적인 역할은 "큰 수를 작은 수로 바꾸기"입니다. 즉 MSE로 뻥튀기 된 손실을 작은 수로 표현하겠다는 의지로 보시면 됩니다.
- 결론적으로 RMSLE는 실제값보다 예상치가 많이 클 때 영향을 적게 받으며, 이를 robust(강인)하다고 표현합니다.
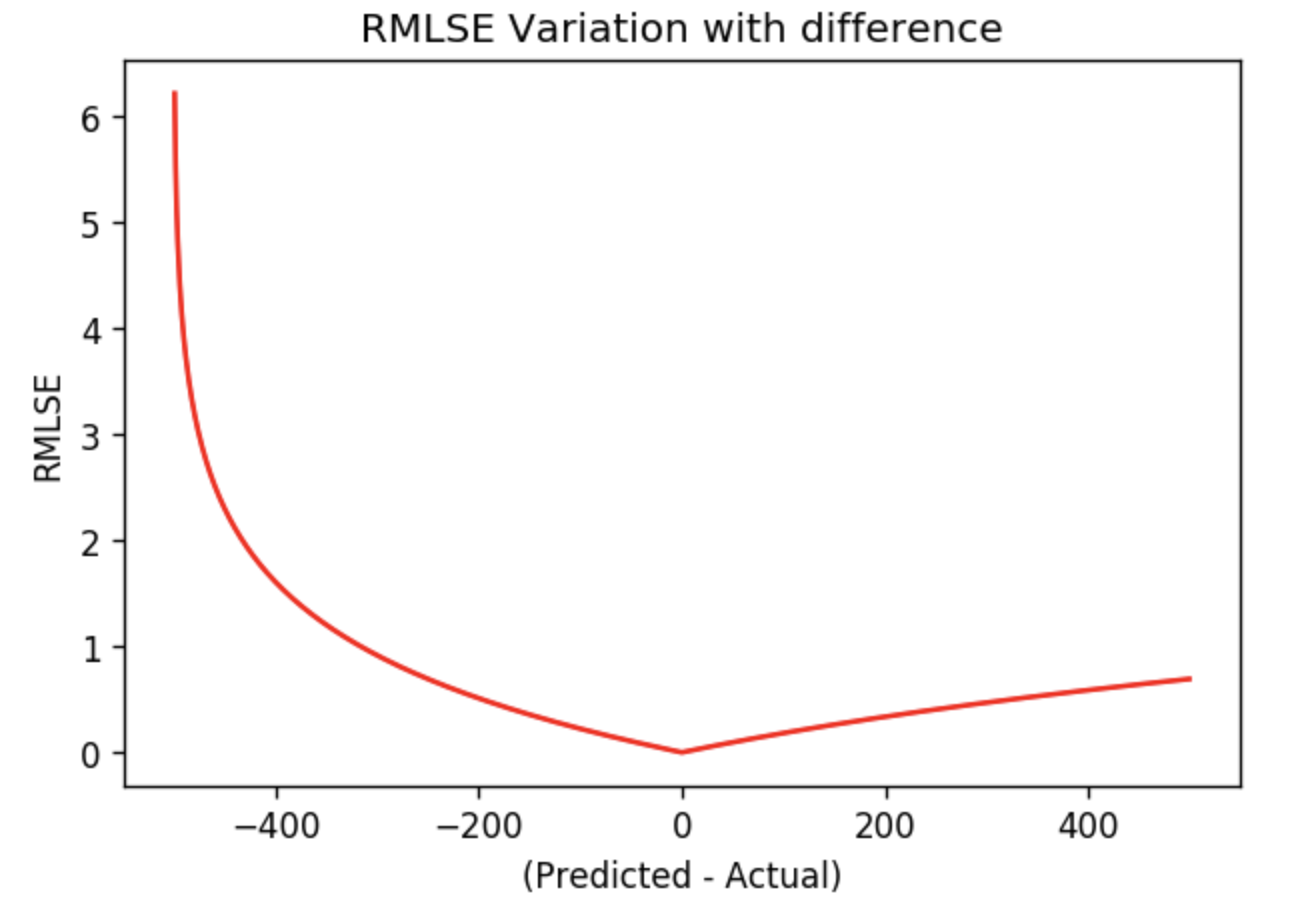
- 다만 모든 상황에서 강인한 것은 아닙니다. 예상치가 실제값보다 많이 작을 경우, 즉 음의 방향으로 오차가 클 경우(underestimated) 손실이 기하급수적으로 증가하는데, 이러한 점을 감안하여 사용하셔야 할 함수입니다.
참고
MAPE(Mean Absolute Percentage Error, 평균 절대 백분율 오차)
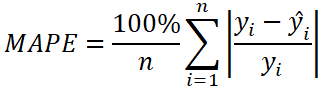
오차를 실제값으로 나눈 후 평균치를 구하여 백분율로 환산합니다(???).
설명이 조금 복잡하지만 천천히 의미를 따져보면
1. 오차를 실제값으로 나눔: 실제값에 비해 오차가 갖는 힘을 측정합니다. 값이 작을 수록 오차의 영향력이 작고, 모델이 좋다고 할 수 있죠.
2. 평균치를 구함: 말 그대로 수많은 오차/실제값들의 평균을 내는 과정입니다.
3. 백분율로 환산: [0, 1]의 범위로 표현된 값들을 백분율로 표현합니다. 직관적 표현을 위한 도구인 셈이죠.
- 사실 구조를 뜯어보면 MAE의 오차를 실제값으로 나누고, 100과 단위기호인 %를 곱해준 셈입니다. 즉 MAE와 마찬가지로 underestimate와 overestimate를 구분하지 못합니다.
- 단위가 "비율"이므로 지표를 비교하는 상황에 좋습니다. 반면 비율이 아닌 구체적 값을 예측하는 상황에는 불리하죠.
- 실제값이 분모로 들어갑니다. 만일 실제값 중 0이 포함된다면 계산이 불가능합니다.
MASE(Mean Absolute Scaled Error, 평균 절대 조정 오차)
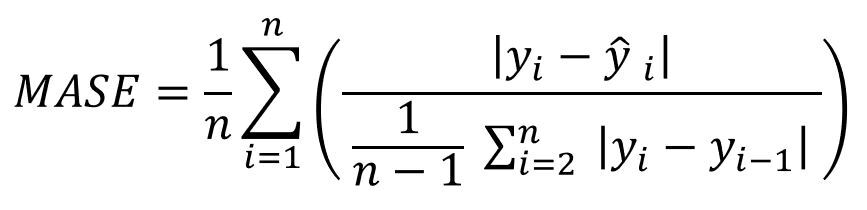
나중에 시계열 데이터를 다룰 때 구체적으로 설명하도록 하겠습니다.
