
엔트로피(Entropy)
분류과정의 손실함수를 설명하기 위해선 엔트로피에 대한 설명이 먼저 필요합니다. 물리학과 정보학에서 사용하는 엔트로피는 유래가 같지만 사용 목적에 따라 의미가 갈린다고 생각합니다. 전자에서는 자연상태를 설명하기 위한 수단이라면, 후자에서는 자원을 배분하기 위해 고안한 개념에 가깝습니다.
엔트로피는 본래 물리학의 열역학에서 이용되는 함수 이름입니다. "무질서도" 혹은 "불확실성"이라는 말로 번역되기도 하는데, 어떤 공간 안에서 에너지가 골고루 퍼져나가려는 상태를 말합니다. 아무리 질서정연하게 모아놓고 정리하려 해도 분산되려는 성질을 의미하는거죠.
사전적 의미
정보학에서의 엔트로피는 정보를 표현하는데 필요한 가장 작은 평균 자원량을 의미합니다.출처
친구와 SNS로 대화를 나눌 때 "ㅋㅋㅋ"를 "감수분열비분리"보다 훨씬 높은 빈도로 사용하겠죠. 전파를 효율적으로 사용하려면 "ㅋㅋㅋ"에 적은 자원을, "감수분열비분리"에 많은 자원을 할당해야합니다.
이를 불확실성이라는 개념과 연관짓는다면, 정보학에서는 엔트로피를 정보를 얻을 수 있는 가능성(확률) 으로 표현합니다. 즉 어떤 정보를 얻었을 때, 이것의 정보량(가치가 있는지 없는지)을 판단하는 척도인 셈입니다. 정보량을 나타내는 방법은 다음과 같습니다. 출처
-
가능성이 높은(likely) 사건은 정보량이 적고, 가능성이 낮은 사건은 정보량이 많음
-> 가능성과 정보량은 반비례 -
가능성이 필연적인(guaranteed to happen)사건은 정보량이 없는 것과 같음
-> 가능성(확률)이 1에 가까우면 정보량은 0으로 수렴 -
독립적인(앞 사건이 뒷 사건에 영향을 주지 않는) 사건들이 여러 번 발생한 경우, 각각의 정보량을 모두 더한 것이 전체 정보량임
-> 각 정보량에 대한 덧셈이 가능해야 함
위 세 가지 방법을 모두 고려했을 때, 어떤 사건 에 대한 정보량 와 확률 의 관계는 로그를 통해 깔끔하게 표현할 수 있습니다.
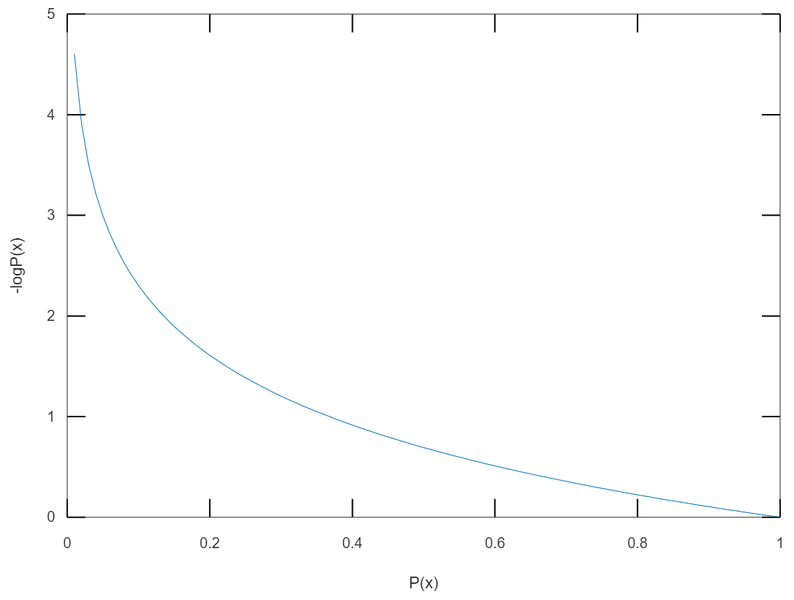
단조 감소 함수이며 확률이 1에 가까워질 때("ㅋㅋㅋ"를 남발하는 경우), 정보량이 0으로 수렴하네요. 반대로 확률이 0에 가까워지면 정보량은 무한대로 발산하는 것도 관찰할 수 있습니다.
수식의 의미
다시 자원 배분 문제로 돌아와서, 엔트로피를 통해 우리는 최소"평균"자원량을 나타내고 싶기 때문에 기댓값(Expected value)의 형태로 표현해야 합니다. 고등학교 수학시간에 기댓값 공식을 떠올려보면 아래와 같습니다.
여기서 는 도수, 는 가 일어날 확률, 는 의 기댓값입니다. 즉 기댓값이란 모든 도수에 대해 각 도수와 확률을 곱하여, 이를 전부 더해주는 셈입니다.
다만 위의 내용은 이산확률변수에 해당하는 공식이고, 연속확률변수의 경우는 적분을 통해 면적을 구해주면 됩니다.
아까 보여드렸던 그래프에서 x축을 로, y축을 로 두었기 때문에 엔트로피 공식()에 대입을 하면
또는
가 됩니다.
위 계산을 통해 구한 엔트로피의 값이 크면 데이터를 표현하기 위한 평균 정보량이 많이 요구되고, 작을 수록 최소 평균 자원량이 조금만 필요하다는 뜻이 됩니다. 만일 여러분께서 처리한 정보가 엔트로피와 같거나 비슷하게 수렴한다면, 엄청나게 효율적으로 처리하셨다는 의미가 됩니다.
엔트로피의 최대
정보량을 최대한 꾹꾹 눌러담아 효율성을 높이는게 엔트로피의 목표인데, 엔트로피 그 자체가 커진다는 건 효율성이 나빠진다는 뜻이겠죠. 인간이 생물학 지식만 추구하고 즐거움을 포기해서 "ㅋㅋㅋ"와 "감수분열비분리"가 SNS에서 같은 빈도로 사용된다면 정보량에 우선순위를 부여할 수가 없는 구조가 되고, 만일 모든 단어가 같은 빈도로 사용된다면 효율성을 포기하는게 효율적일지도 모릅니다.
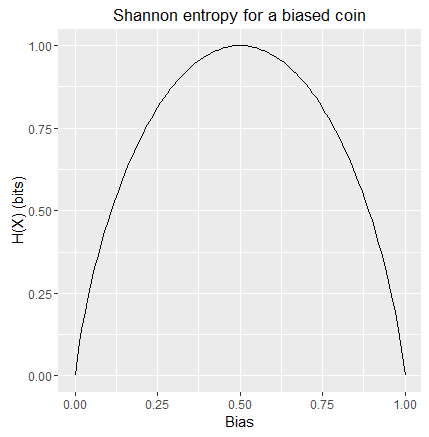
이렇게 엔트로피가 최대가 되는 경우는 각 도수의 확률이 같아지는 경우고, 효율성을 추구하기 힘들어졌거나 비교하려는 대상의 정보량에 차이가 없는 것으로 이해해야 합니다. 주가 추세를 예측하여 투자 여부를 판단하는 모델에서 "투자해라" 의견이 0.5, "투자하지 마라" 의견이 0.5라면 그 모델은 투자자의 판단에 도움을 전혀 주지 못하는 셈인거죠.
