
사실 엄청나게 오래됐지만, 내일이면 더 오래된 일이 되기에 지금이라도 회고를 해본다.
때는 1월로 거슬러 올라간다.0. 데이터 캠프
데이터톤을 진행하기 전에, 부산대학교 교수님과 여러 멘토 분들께서 사전 교육으로 데이터 캠프를 해주셨다. 나를 포함해서 대부분의 친구들이 데이터 분석, AI와 관련해서 아무것도 모르는 상태였기 때문이다. 이 레포지토리에 캠프 때 한 실습들을 올려놨다. pandas로 데이터 형식을 만드는 것과, seaborn, pyplot으로 시각화하는 것, sklearn으로 머신러닝하는 것을 배웠다. 아무것도 몰랐지만, 열심히 수업을 들었다.
1. 팀 빌딩
말이 팀 빌딩이지 그냥 쌩 랜덤이었다. 체육관을 가보니 넌 16조야~ 라고 되어있었다. 어차피 나도 할 줄 아는 거 아무것도 없어서 딱히 불만은 없었다. 민폐만 끼치지 말자는 마인드로 참가했다. 그리고 조 이름을 mbti로 B1A4느낌으로다가 E 한명 I 세명 E1I3라고 지었다.
2. 주제와 진행 방식
주제는
키, 나이, 성별, 혈압, 점프 높이 등의 인체 데이터로 체지방률을 구하는 것
이었고, AI Factory라는 회사의 서비스를 통해 실시간으로 채점당했다. 결과가 나와 있는 파일을 통해 모델을 학습시킨 뒤 학습시킨 모델로 결과가 나와있지 않은 데이터들의 결과를 예측하고, 그 결과 파일을 제출해서 채점하는 방식이다. 데이터톤 멘토로 AI Factory의 직원 분들?께서 계셔서 많이 도와주셨다. (AI KOREA 2022 할 때 부스에서 한 번 더 뵀었는데 야무지게 챙겨주셨당... 좋은 분들...)

3. 모델 개발!
데이터 전처리
가장 먼저 사용할 column을 정했다. seaborn 라이브러리를 사용해서 scatter 형태로 column에 따른 체지방률 값을 보며 유의미한 column을 찾았다. 애매한 그래프의 column을 사용했다 안했다를 반복하며, 각 column이 영향을 주는지 확인했다. 결과적으로 모든 column을 사용하기로 결정했다. 이곳에서 확인할 수 있다.
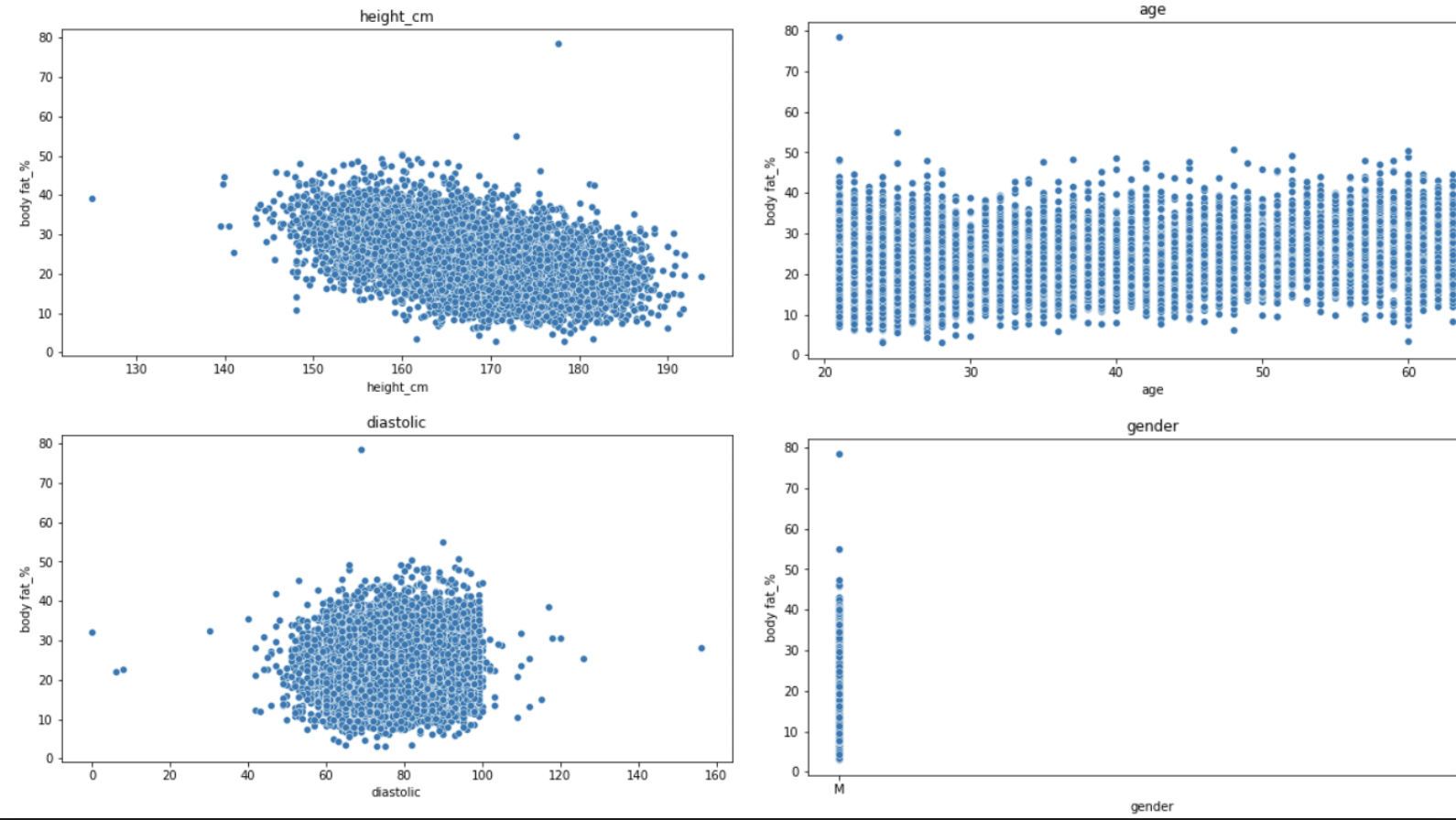
또한, data에서 혼자 너무 큰 값이나, 혼자 너무 작은 값들을 예외처리 해보고, 영향을 얼마나 미치는지 확인했는데, 예외처리를 한 것보다 안 한 게 성능이 더 좋아서 예외처리를 하지 않기로 결정했다.
이후로 gender 데이터를 제외한 뒤 데이터 정규화를 진행하고 이후에 기존 M, F로 되어있던 gender data를 0과 1로 변환한 뒤 다시 데이터에 추가했다.
머신 러닝 고도화를 위해 4가지 방법으로 데이터 정규화를 했는데 MinMaxScaler가 가장 성능이 좋아서 MinMaxScaler를 사용하기로 결정했다.
알고리즘
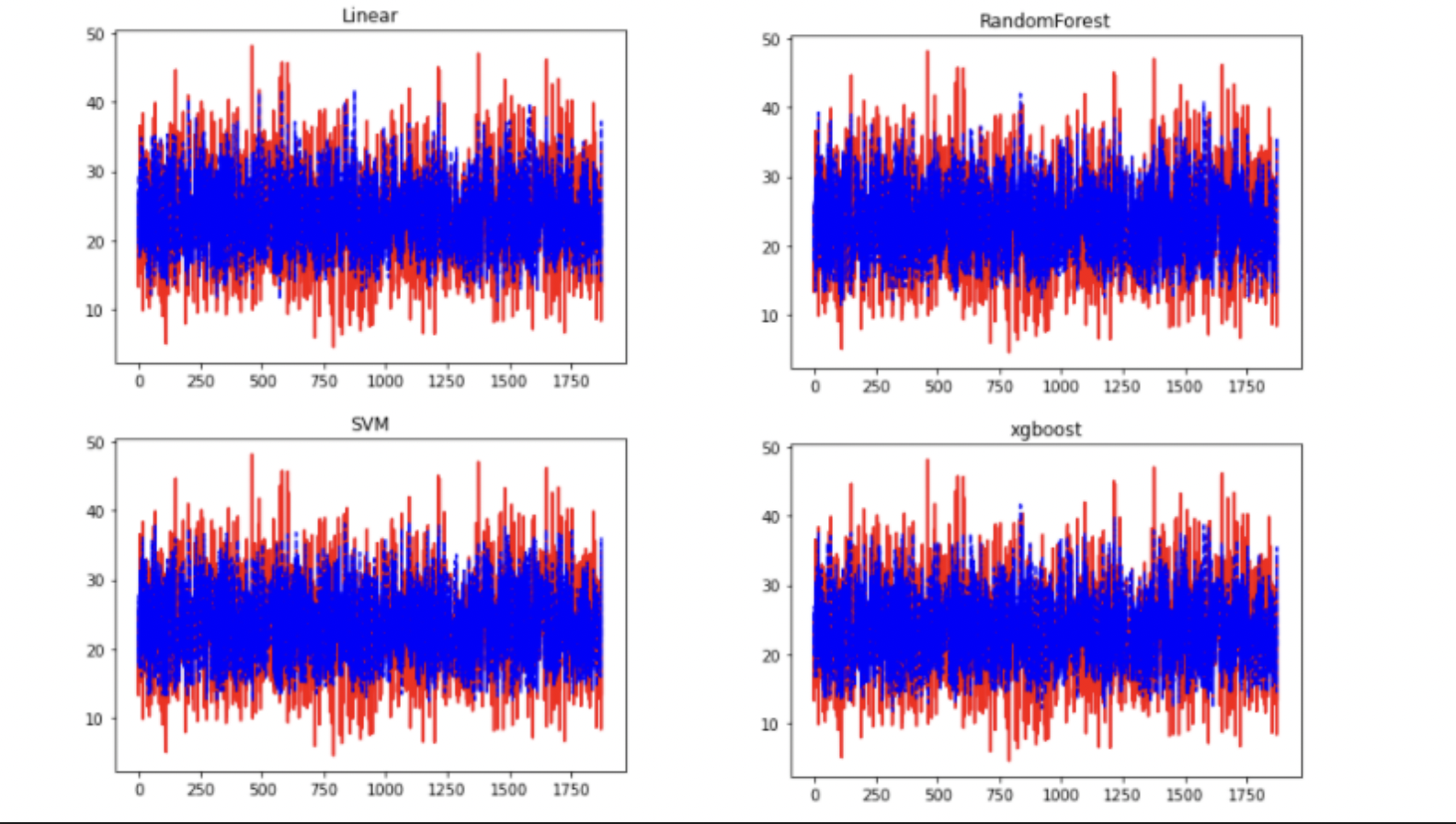
알고리즘의 특징에 대해 아는 것이 없기 때문에 그냥 아는 알고리즘을 다 돌려보고, 가장 성능이 좋은 알고리즘인 SVM 알고리즘을 사용했다. 나름대로 4가지 모델을 평가도 했다...
mean_absolute_error를 사용하여 성능을 계산했다.
SVM은 Support Vector Machine의 약자로, 이름대로 Vector 개념을 사용한다.
SVM은 서포트 벡터(support vectors)를 사용해서 결정 경계(Decision Boundary)를 정의하고, 분류되지 않은 점을 해당 결정 경계와 비교해서 분류하는 모델이다. SVM 알고리즘에 hyperparameter를 사용하여 option을 주어 성능을 개선했다.
교차검증
이 이후로는 멘토쌤들한테 힌트 하나만 달라 해도 안 주시고, 너네는 할 수 있는 걸 다 했다고 하셨다. 근데 한 멘토쌤이 교차검증을 해보라고 하셨다. 완벽하게 이해하지 못했지만, 어느정도 이해하고 각 case들의 평균을 사용하여 test를 했는데, 개선에 실패했다. 시도는 좋았다...!
사실 하고 다른 멘토쌤한테 혼났다. 교차 검증은 이럴 때 쓰는 게 아니라며...
랜덤 스테이트
더 할 수 있는 것도 없고, 우리 팀은 2등이었다. 1등 팀이랑은 근소한 차이가 났다. 그래서 더 할 수 있는 게 뭐가 있는지 생각하다가, train을 나눌 때 넣는 random state 값을 요래조래 변형하면서 성능을 개선(이게 맞나)했다. random state를 parameter로 해서 성능을 구하는 코드를 함수화 시켜 for문을 돌리며 가장 성능이 좋은 random state 값을 찾았다. 이곳에서 확인할 수 있다. 그래서 1등과 2등을 엎치락뒤치락하다가, 결국 2등으로 끝났다.
로또 번호도 넣어보고, 팀원들 생일도 넣어보고 엄청 웃겼다...
4. 결과
아무래도 결과가 2등이니 발표 점수를 많이 받아야 했다. 그래서 발표를 열심히 잘 했더니 최우수상을 받았다.

5. 느낀점
해커톤은 잘 알았지만 데이터톤은 생소하고 잘 몰랐던 거라 처음에는 이게 뭐지? 싶었다. 하지만 데이터 캠프를 통해 아주 조금이지만 머신러닝에 대해 알게 되고, 흥미를 느꼈던 것 같다. 하루동안 모델 개발에 집중하면서 노력하는 과정이 재미있었다. 사실 그냥 최우수상 받아서 좋았다 ㅎㅎ.
