
1. 들어가며 — 후보 압축기 뒤에 남은 질문
5주차 글에서 Root Cause Analysis (RCA) 를 이렇게 정리했습니다.
“RCA 는 정답을 찍는 작업이 아니라, confidence 가 부여된 probable cause 후보들을 압축해 운영자의 조사 순서를 추천하는 작업이다.”
좋은 정의입니다. 그런데 그 후보 압축기는 어디에서 만들어지는가 라는 질문이 곧장 따라옵니다.
마케팅 페이지는 흔히 “AI 가 원인을 찾아낸다” 한 줄로 답하지만, 실제 오픈소스 (OSS) 코드를 열어 보면 “AI” 라는 박스 따위는 한가운데에 없습니다.
거기 있는 건 세 컴포넌트 × 19 검사 stage × 4 종 Check × 3 자리 AI 의 결정론적 책임 분담 입니다.
이번 글은 그 책임 분담을 코드 위에서 한 단계씩 따라갑니다. 표본은 Coroot — eBPF 기반의 옵저버빌리티 OSS 입니다.
1.1 마스터 비유 — 물류 허브 운영실
복잡한 시스템은 흐름 으로 보면 단번에 잡힙니다.
6주차 글 전체를 물류 허브 운영실 한 비유로 관통하겠습니다.
| Coroot 컴포넌트 | 비유에서의 자리 | 한 줄 |
|---|---|---|
coroot-node-agent | 라인 끝의 카메라 | 박스가 컨베이어를 통과할 때마다 자동으로 스캔 — 운영자 손이 닿지 않아도 된다 |
coroot-cluster-agent | 관리 사무소 | 어느 트럭이 어느 게이트로 들어왔고 어떤 화물을 실었는지 입출고 장부 를 갱신 |
coroot 본체 | 허브 운영실 | 두 시야를 합쳐 판정 하고, 전광판 으로 보여 주고, 외부 보고 까지 한다 |
Check 4-type | 검사관 판정표 4 종 | “이벤트형 / 항목 목록형 / 수치 게이지형 / 사람 판단형” |
| AI 가 끼는 세 자리 | 운영실의 컨설턴트 / 야간 조사관 / 외부 질의 창구 | 셋이 완전히 다른 곳 에서 일한다 |
1.2 Coroot 공식 architecture
전체 그림은 공식 docs 의 architecture 페이지가 가장 잘 보여 줍니다
docs.coroot.com / Installation / Architecture 에서 “Coroot’s main components” 도식을 한 번 클릭해 두고 오면 좋습니다.
Docusaurus 의 해시 URL 은 docs 가 새로 배포될 때 깨지기 쉬워서, 여기서는 원문 페이지로 거는 링크만 두었습니다.
그 그림이 현실 배포 토폴로지라면, 본문에서 따라갈 코드 구조는 다음의 3 층 도식에 가깝습니다.
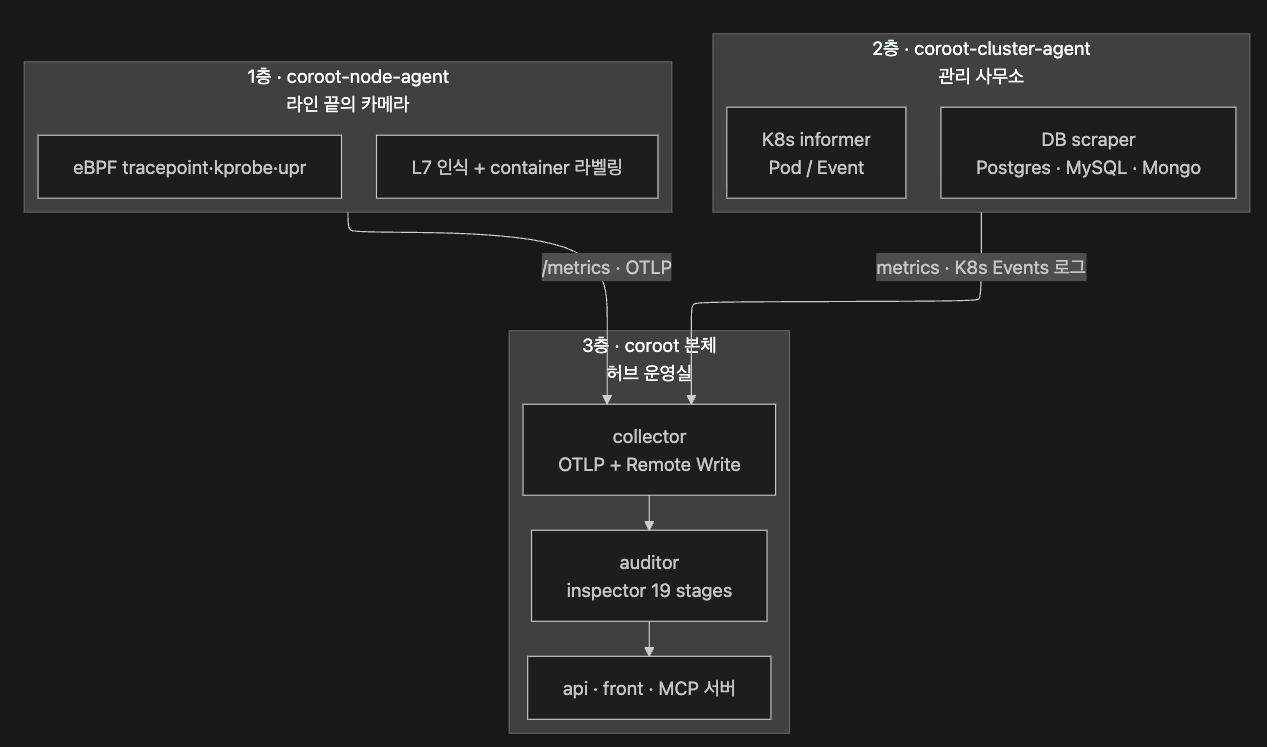
위·아래는 상하 위계가 아니라 관측면이 다름 을 뜻합니다.
node-agent 는 커널 시야, cluster-agent 는 K8s API 시야, coroot 본체는 집계·룰·UI 시야 — 셋이 합쳐져야 하나의 사고 가 여러 각도로 보입니다.
1.3 글의 위치와 두 deep-read 축
| 주차 | 질문 | 답 |
|---|---|---|
| 5주차 | “원인은 무엇인가?” | RCA = probable cause + confidence — “후보 압축기” |
| 6주차 (본 글) | “그 후보 압축기를 누가 어떤 관측면 으로 만드는가?” | 3 컴포넌트 × 19 inspector × 4 Check × 3 AI 자리 의 결정론적 책임 분담 |
| 7주차 (예정) | “그 책임 분담을 실제로 띄우려면?” | k3d + helm + 3 컴포넌트 + OTel Astronomy Shop |
| 8주차 (예정) | “그 분담이 살아 움직일 때?” | chaos 주입 + 5층 동시 캡처 + MCP 클라이언트 |
이 글에서는 두 축으로 깊이 들어갑니다.
- (B) 데이터 흐름 — eBPF event → 저장소 →
Application/AppToAppConnection모델 → Check → UI / MCP - (C) 책임 분담 — node-agent 의 커널 시야, cluster-agent 의 K8s 시야, 본체의 판단·UI·MCP 시야
1.4 미리 보는 Demo 현장
본문에 들어가기 전 화면 감을 잡고 싶다면 공식 live demo 한 번:
- Live demo — https://demo.coroot.com/p/tbuzvelk/applications
- 보조 docs — Inspections overview · Alerts detail · Application logs · Concepts & terminology
UI 묘사 대신 코드상의 자리만 보고, 실 화면 비교는 7주차에서 다룹니다.
1.5 글 전체 지도 (§2~§10 이 어디로 가는가)
§2~§10 을 다섯 갈래로 묶으면 본문이 한 줄로 잡힙니다.
| 본문 | 다루는 것 | 비유 자리 |
|---|---|---|
| §2~§4 | 신호 수집 — eBPF · cgroup · K8s API | 라인 끝 카메라 + 관리 사무소 |
| §5~§6 | 입력 프로토콜 + 저장소 분기 | 컨베이어 + 창고 |
| §7~§8 | 본체 wiring + 도메인 모델 (AppToAppConnection) | 운영실 입구 + 노선 카드 |
| §9 | 판단 — 19 inspector · Check 4-type · watchers | 검사관 |
| §10 | AI 가 끼는 세 자리 | 컨설턴트 + 야간 조사관 + 외부 창구 |
§11 부터는 비유의 한계 / 마무리 / FAQ / 참고자료입니다.
1.6 사전 지식 (5 박스, 읽기 전 전처리)
§2 이하 본론은 Coroot 가 다음 다섯 가지를 어떻게 쓰는가 만 다룹니다. 각 기술이 무엇이고 왜 필요한지 는 여기서 한 박스씩 짧게 정리하고 본론에서는 다시 풀지 않습니다.
A. eBPF — 커널 무계측 관측. 리눅스 커널 안에 안전 검증을 통과한 작은 프로그램을 동적으로 로딩해 시스템콜·네트워크·스케줄링 이벤트를 user-space 로 흘려보내는 메커니즘. 애플리케이션 코드 한 줄 안 바꾸고 TCP / L7 신호를 뽑게 합니다. 핵심 후킹은
tracepoint·kprobe·uprobe·TC/XDP네 가지. 한계: L7 plain text 9 종까지·TLS 는 uprobe 필요·비즈니스 인과 (correlation ID) 는 보지 못함.→ Coroot 에서는
coroot-node-agent가 이 메커니즘으로 §2 의 신호 수집을 담당합니다.
B. cgroup · namespace · /proc — 커널 이벤트를 컨테이너로 묶기. eBPF 가 본 PID 단위 이벤트가 어느 컨테이너 / 어느 Pod 의 것인지 매핑하려면 cgroup v2 (자원 라벨) + namespace 7 종 (격리 단위) +
/proc(프로세스 메타) 세 가지가 필요합니다. K8s 에서는 컨테이너마다 cgroup 한 개 + namespace 그룹이 붙어 있어 이 셋이 안정적인 라벨링 근거가 됩니다.→ Coroot 에서는 동일하게
coroot-node-agent가/proc와 cgroup tree 를 읽어 §3 의 컨테이너 매핑을 처리합니다.
C. Kubernetes Informer — K8s API 시야. K8s API 서버를 매번 GET 하지 않고 한 번 watch 로 연결한 뒤 로컬 cache + 이벤트 큐로 받는 client-go 표준 패턴. 변경분만 받아 부하를 낮추면서 현재 클러스터 상태를 항상 들고 있게 합니다. Pod / Service / Endpoints / Events 같은 K8s 객체의 변동을 효율적으로 따라가는 길.
→ Coroot 에서는
coroot-cluster-agent가 informer 를 통해 §4 의 K8s 메타와 이벤트를 받습니다.
D. OTLP vs Prometheus Remote Write — 두 프로토콜 병행. OTLP 는 trace / log / profile 같은 원시 이벤트 스트림의 표준 wire format (batch + 라벨 풍부). Remote Write 는 metric 같은 집계 시계열의 고밀도 푸시 표준. 한 프로토콜로 통일하려는 시도는 있지만 운영 현장은 둘을 병행하는 게 표준입니다.
→ Coroot 에서는 본체의
collector/디렉터리가 두 프로토콜의 입구. metric 은 Remote Write, trace · log · profile 은 OTLP — §5.
E. ClickHouse vs Prometheus — 두 저장소. ClickHouse 는 대용량 원시 이벤트 (trace / log / profile) 의 컬럼 저장소 (10× 압축 + SQL 검색). Prometheus 는 집계 시계열 metric 의 TSDB (라벨 인덱싱 + PromQL). 두 저장소는 책임이 다르고 어느 한쪽으로 통일되지 않습니다.
→ Coroot 에서는 본체의
cfg.UseClickHouse분기가 trace · log · profile 은 항상 ClickHouse 로, metric 은 설정에 따라 ClickHouse 또는 Prometheus 로 보냅니다 — §6.
이제 본론 — Coroot 가 이 다섯을 실제로 어떻게 쓰는가 입니다.
2. eBPF — 커널 시야의 출발점
배경 정의는 §1.6 박스 A 참고. 이 절은 Coroot 의
coroot-node-agent가 그 eBPF 를 실제 코드에서 어떻게 쓰는가 만 다룹니다.
2.3 Coroot 의 그 자리 — coroot-node-agent
coroot-node-agent 의 ebpftracer/ 디렉터리가 eBPF 코드의 거점입니다.
ebpftracer/
├── tracer.go ← Go 측 eBPF 프로그램 로더 (cilium/ebpf 라이브러리)
├── ebpf/ ← C 소스 (커널에서 실행)
│ ├── ebpf.c ← 메인 진입점
│ ├── tcp/
│ │ ├── state.c ← TCP 상태 전환
│ │ ├── conntrack.c ← netfilter conntrack (NAT)
│ │ └── retransmit.c ← 재전송 추적
│ ├── proc.c ← 프로세스 lifecycle + OOM
│ ├── file.c ← 파일 I/O
│ ├── nodejs.c ← Node.js 이벤트 루프 (uprobe)
│ ├── python.c ← Python GIL 대기 (uprobe)
│ └── l7/
│ ├── gotls.c ← Go TLS payload 풀기 (uprobe)
│ └── http2.c ← HTTP/2 프레임 파싱
└── l7/ ← Go 측 L7 파서
├── http.go, http2.go, dns.go
├── postgres.go, mysql.go, mongo.go
├── redis.go ← (memcached.go)
└── clickhouse.go2.4 실제 후킹 — tracepoint 가 주축
node-agent 는 kprobe/tcp_v4_connect 를 직접 후킹하지 않습니다. TCP 상태 전환 tracepoint 한 곳 (sock/inet_sock_set_state) 에서 connect 와 listen 을 함께 처리합니다.
| 후킹 종류 | 후킹 지점 | 무엇을 보는가 |
|---|---|---|
| tracepoint | sock/inet_sock_set_state | TCP 상태 전환 — connect 와 listen 을 함께 처리 |
| tracepoint | tcp/tcp_retransmit_skb | TCP 재전송 |
| tracepoint | task/task_newtask | 프로세스 생성 |
| tracepoint | sched/sched_process_exit | 프로세스 종료 |
| tracepoint | oom/mark_victim | OOM Killer 발동 |
| kprobe | nf_ct_deliver_cached_events | netfilter conntrack (NAT 매핑) |
| uprobe | pthread_cond_* (Python) | Python GIL 대기 시간 |
| uprobe | uv_io_poll_* (Node.js) | Node.js 이벤트 루프 블록 시간 |
코드 한 줄로 확인 가능
// coroot-node-agent/ebpftracer/ebpf/tcp/state.c
SEC("tracepoint/sock/inet_sock_set_state")
int inet_sock_set_state_handler(...) { ... }왜 tracepoint 위주인가?
kprobe 는 임의의 커널 함수 에 부착할 수 있어 강력하지만 함수 시그니처가 커널 버전마다 바뀝니다.
tracepoint 는 커널이 유지를 약속한 안정 인터페이스 이므로 버전 간 호환성이 더 안정적입니다.
node-agent README 가 “minimum supported Linux kernel version is 5.1” 라고 명시한 이유가 여기 있습니다 (상한은 명시 안 됨 — “5.1 이상” 만 단정)
2.5 이벤트 10 종 — 무엇이 user-space 로 흘러가는가
ebpftracer/tracer.go 의 EventType 정의를 그대로 봅니다.
// coroot-node-agent/ebpftracer/tracer.go (commit d9b5c26)
const (
EventTypeProcessStart EventType = 1
EventTypeProcessExit EventType = 2
EventTypeConnectionOpen EventType = 3
EventTypeConnectionClose EventType = 4
EventTypeConnectionError EventType = 5
EventTypeListenOpen EventType = 6
EventTypeListenClose EventType = 7
EventTypeFileOpen EventType = 8
EventTypeTCPRetransmit EventType = 9
EventTypeL7Request EventType = 10
EventReasonNone EventReason = 0
EventReasonOOMKill EventReason = 1
)10 종 이벤트 중 L7Request (10번) 가 핵심입니다. node-agent 는 HTTP / HTTP2 / DNS / Postgres / MySQL / MongoDB / Redis / Memcached / ClickHouse 9 종 프로토콜을 커널 안에서 인식해 어떤 요청이 갔는지까지 봅니다 (commit d9b5c26 기준 — 공식 docs 에는 Kafka 등 추가 프로토콜이 있고, 새 commit 에서 더 늘어날 수 있습니다).
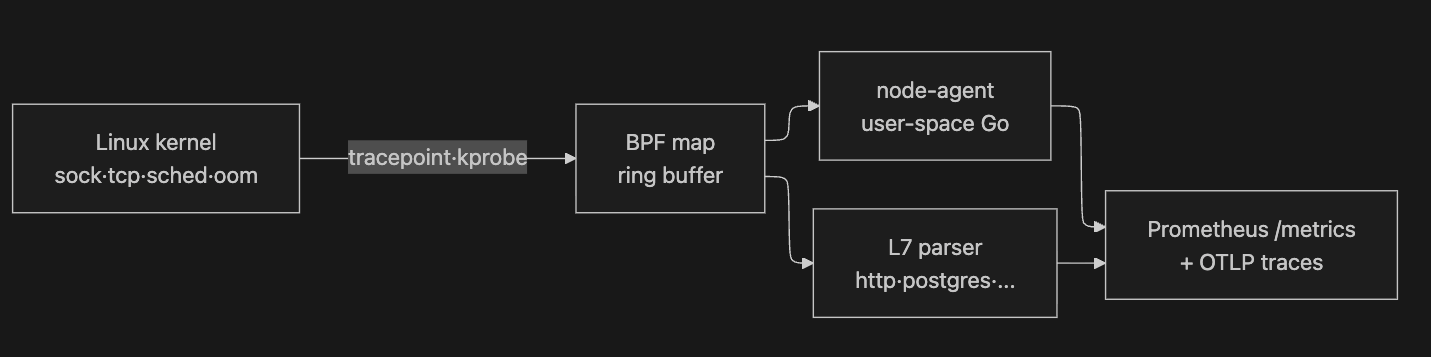
단 eBPF 가 만능은 아닙니다. "eBPF 만 있으면 모든 걸 다 본다" 는 식으로 쓰면 곤란합니다.
L7 인식은 well-known 포트와 payload 패턴에 의존하고, TLS payload 는 uprobe 로 SSL 라이브러리를 후킹해야 풀리며, 비즈니스 단의 인과(correlation ID 가 가리키는 “이 요청이 사용자 A 의 주문에서 시작됐다”) 는 eBPF 가 끝내 못 잡습니다. 그 자리는 OTel span 이나 로그의 correlation ID 와 결합돼야 채워집니다.
2.6 또 하나의 신호 — Delay accounting
eBPF 외에 node-agent 가 프로세스 단위 지연 을 별도 채널 로 수집한다는 사실은 README 만 빠르게 읽으면 놓치기 쉽습니다. node-agent README 의 “Delay accounting” 절이 핵심:
Delay accounting allows engineers to accurately identify situations where a container is experiencing a lack of CPU time or waiting for I/O. The agent gathers per-process counters through Netlink and aggregates them into per-container metrics.
즉 container_resources_cpu_delay_seconds_total 같은 메트릭이 Netlink 채널로 프로세스가 CPU 를 기다린 시간 을 직접 측정합니다. eBPF 가 이벤트 를 잡는다면, Delay accounting 은 시간 누적 을 잡습니다 — 둘은 다른 layer 의 보완 신호. 5주차 “결정적 단서” 의 직접 증거 후보입니다.
3. cgroup·namespace — 커널 신호를 컨테이너로 묶기
배경 정의는 §1.6 박스 B 참고. 이 절은 node-agent 가 PID → 컨테이너 → Pod / Application 매핑을 cgroup v2 + namespace 7 종 +
/proc로 어떻게 푸는지만 다룹니다.
3.3 Coroot 의 그 자리
coroot-node-agent 의 세 디렉터리가 협업합니다.
coroot-node-agent/
├── cgroup/ ← /sys/fs/cgroup 파싱, container ID 추출
├── containers/ ← container metadata (image, labels)
├── proc/ ← /proc/<pid>/* 읽기 (uts, ns, ...)
└── node/ ← 노드 메타 (kernel version, hostname)main.go 의 도입부에서 호스트 UTS namespace 를 잠깐 빌려 호스트 kernel version 을 읽는 트릭이 보입니다 (커널 5.1 호환성 체크용).
// coroot-node-agent/main.go 발췌 (commit d9b5c26)
err = unix.Setns(int(f.Fd()), unix.CLONE_NEWUTS)
if err != nil {
return "", "", err
}
var utsname unix.Utsname
if err := unix.Uname(&utsname); err != nil {
return "", "", err
}3.4 어떤 권한이 필요한가 — DaemonSet 매니페스트
node-agent 가 호스트 cgroup 파일시스템·debugfs·다른 컨테이너의 PID 까지 보려면 상당히 강한 권한 이 필요합니다.
[실제 K8s 매니페스트]
# coroot-node-agent/manifests/coroot-node-agent.yaml 발췌 (commit d9b5c26)
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: coroot-node-agent
namespace: default
labels:
app: coroot-node-agent
spec:
selector:
matchLabels:
app: coroot-node-agent
template:
metadata:
labels:
app: coroot-node-agent
spec:
hostPID: true
containers:
- name: coroot-node-agent
image: coroot/coroot-node-agent:latest
args:
- "--cgroupfs-root"
- "/host/sys/fs/cgroup"
securityContext:
privileged: true
volumeMounts:
- name: cgroupfs
mountPath: /host/sys/fs/cgroup
readOnly: true
- name: debugfs
mountPath: /sys/kernel/debug
readOnly: false
volumes:
- name: cgroupfs
hostPath:
path: /sys/fs/cgroup
type: Directory
- name: debugfs
hostPath:
path: /sys/kernel/debug
type: DirectoryOrCreate요점은 세 가지
1. hostPID: true — 다른 컨테이너의 프로세스를 볼 수 있어야 라벨링 가능
2. privileged: true — CAP_BPF / CAP_PERFMON / CAP_SYS_ADMIN 모두 필요한 eBPF 로딩
3. /sys/kernel/debug 읽기·쓰기 — eBPF 프로그램 디버그 정보 + BPF map 접근
3.5 Continuous Profiling — eBPF 외 두 갈래
본 글의 흐름은 metric · trace · log 3 신호 중심이지만, Coroot 의 자기 소개 는 “metrics, logs, traces, continuous profiling, SLO-based alerting” 5 종을 나란히 둡니다 (coroot/coroot repo README 인용). Profiling 만 떼어 보면 3 축 으로 수집됩니다.
| # | 축 | 수집기 | 어떻게 |
|---|---|---|---|
| 1 | eBPF CPU profiling | coroot-node-agent | 커널 perf event + eBPF stack walking |
| 2 | user-space profiler | 애플리케이션 자체 (Java agent / Go pprof 엔드포인트 등) | 언어별 standard |
| 3 | cluster-agent annotated pod scrape | coroot-cluster-agent profiles/ | Pod 의 pprof annotation 보고 정기 scrape |
세 축이 공통적으로 ClickHouse 로 적재되어 /profiling 화면의 flame graph 로 시각화됩니다. flame graph 의 실 화면과 비교 분석은 7주차에서 다룹니다.
4. Kubernetes Informer — 클러스터 시야의 입구
배경 정의는 §1.6 박스 C 참고. node-agent 가 Pod IP 까지는 알아도 어떤 Service / Deployment / 직전 배포 인지는 K8s API 만 알기 때문에 cluster-agent 가 그 시야를 채웁니다.
4.3 Coroot 의 그 자리 — coroot-cluster-agent
cluster-agent 의 main.go 도입부를 보면 informer 패턴이 그대로 보입니다.
// coroot-cluster-agent/main.go 발췌 (commit 2c7bef0)
import (
"github.com/coroot/coroot-cluster-agent/k8s"
...
)
func main() {
k8s, err := k8s.NewK8S()
if err != nil { klog.Exitln(err) }
...
k8s.SubscribeForPodEvents(ms) // Pod event subscriber 등록
}k8s/k8s.go 의 핵심 패턴
// coroot-cluster-agent/k8s/k8s.go 발췌 (commit 2c7bef0)
import (
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/cache"
)
func NewK8S() (*K8S, error) {
config, err := rest.InClusterConfig()
if err != nil {
if errors.Is(err, rest.ErrNotInCluster) {
klog.Infoln("not running inside a kubernetes cluster")
return nil, nil
}
...
}
...
}[세 가지 단정 가능한 사실]
1. rest.InClusterConfig() 사용 — 클러스터 안에서만 동작 (호스트에서 직접 실행 안 됨)
2. Pod event 패턴: PodEventTypeAdd / Change / Delete
3. 여러 구독자 (subscribers) 가 한 informer 를 공유 (SubscribeForPodEvents)
4.4 cluster-agent 의 확장된 책임
cluster-agent 는 K8s informer 전용이 아니라 6 가지 책임 을 갖습니다.
| 디렉터리 | 책임 |
|---|---|
k8s/ | informer + Pod events + K8s Events → OTLP logs 전송 |
metrics/postgres, mysql, mongo (+ redis, memcached — 공식 docs) | DB credentials 자동 발견 후 직접 스크래핑 — Coroot 의 Service Map 이 DB endpoint 를 인식하면 K8s Secret 의 인증 정보를 자동으로 매칭해 별도 설정 없이 스크래핑 (운영 편의성의 핵심 매직) |
metrics/ksm | kube-state-metrics 통합 |
metrics/aws | AWS RDS / ElastiCache 메트릭 |
metrics/scraper.go | Prometheus 자체 스크래퍼 (K8s service discovery 기반) |
profiles/ | pprof 프로파일 수집 — §3.5 의 3 축 중 cluster-agent annotated pod scrape 축 |
k8s/event.go 의 패턴은 주목할 만합니다. K8s Events (Pod scheduling 실패·OOMKilled·deployment rollout 등) 를 OTLP logs 로 변환해 Coroot 본체에 보냅니다. 즉 K8s Events 는 log 신호로 들어옵니다.
// coroot-cluster-agent/k8s/event.go 발췌 (commit 2c7bef0)
import (
"go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp"
...
)
func NewEventsLogger() *EventsLogger {
opts := []otlploghttp.Option{
otlploghttp.WithEndpointURL(
(*flags.CorootURL).JoinPath("/v1/logs").String()),
...
}
...
return &EventsLogger{logger: provider.Logger("coroot-cluster-agent")}
}4.5 Log clustering 과 Distributed Tracing
Coroot 가 옵저버빌리티 OSS 로서 가지는 두 사용자 가치를 한 단락씩 짚어 둡니다 (실 화면은 7주차).
- Log Monitoring (
docs.coroot.com/logs/)coroot-node-agent가 노드 위에서 직접 로그 파일을 읽어 pattern extraction 을 함께 수행합니다.- 4 source —
/var/log/*파일, Journald, Dockerd JSON, Containerd CRI — 를 자동 감지하고, 비슷한 메시지를 클러스터링해 "같은 패턴이 N 번" 형태로 정규화합니다. - 로그 원문과 패턴 통계가 함께 올라와 "어떤 종류의 오류가 얼마나 났는지" 가 집계 단위로 즉시 보입니다.
- Distributed Tracing (
docs.coroot.com/tracing/)- node-agent 의 eBPF-based tracing 은 애플리케이션 계측 없이 L7 9 종 (§2.5) 의 span 을 만듭니다.
- UI 는 HeatMap (duration 분포), error grouping, attribute comparison (정상 vs 비정상 span 의 attribute 차이) 같은 분석 layer 를 위에 얹습니다.
- trace 가 단순 저장이 아니라 분석 도구까지 한 묶음이라는 의미입니다.
이 두 가치 명제가 본문 eBPF / 모델 / inspector 와 합쳐져 Coroot 의 폭을 만듭니다.
5. 입력 프로토콜 — OTLP vs Prometheus Remote Write
배경 정의는 §1.6 박스 D 참고. Coroot 의 4 시그널 입구 구조:
| 시그널 | 형태 | 표준 프로토콜 |
|---|---|---|
| metric | (timestamp, label_set, value) 시계열 | Prometheus Remote Write |
| trace | span 트리 (parent_id 그래프) | OTLP (OpenTelemetry Protocol) |
| log | timestamp + structured / unstructured 텍스트 | OTLP (logs) |
| profile | pprof binary (flamegraph 입력) | Coroot 의 custom HTTP-based protocol (+ pprof 자체) — OTLP 가 아닌 별도 채널 |
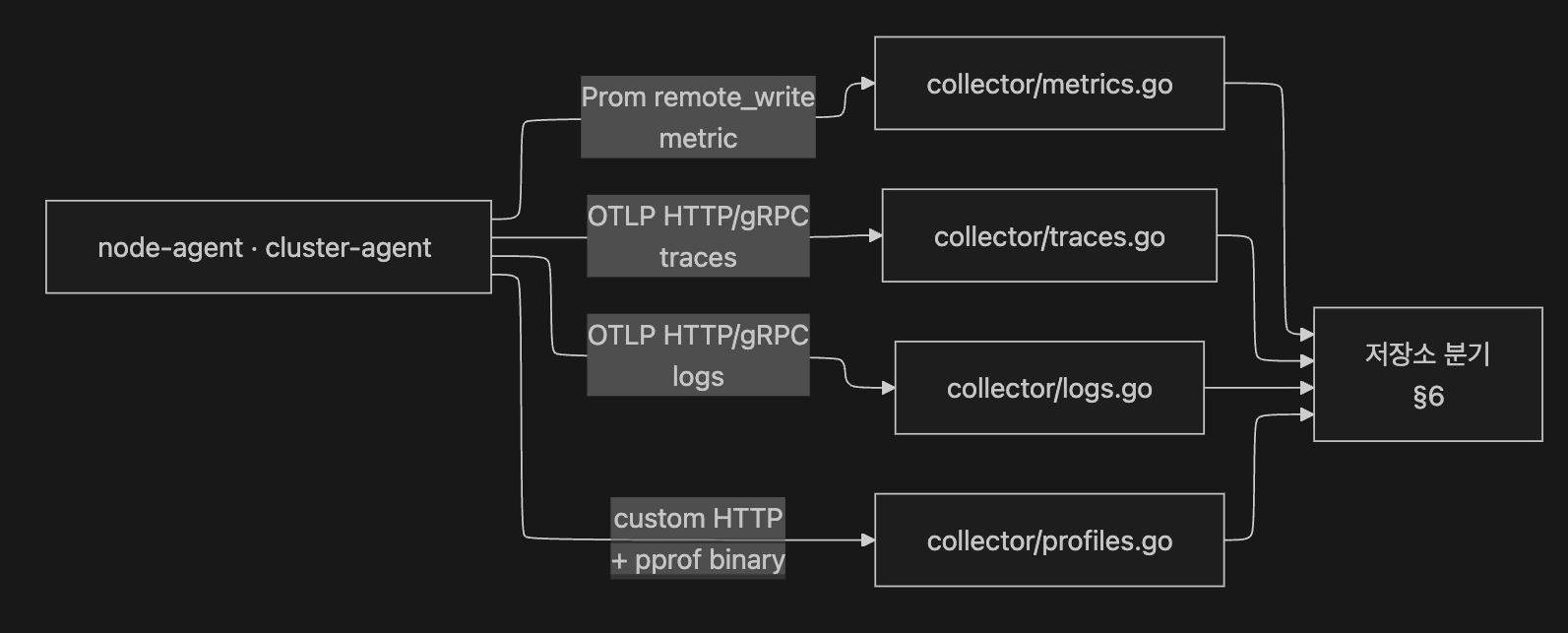
5.2 Coroot 의 그 자리 — collector/ 디렉터리
Coroot 본체의 collector/ 디렉터리가 네 시그널을 모두 받는 입구입니다.
coroot/collector/
├── collector.go ← 공통 wiring
├── grpc.go ← gRPC 엔드포인트 (OTLP/grpc)
├── metrics.go ← Prom remote_write 수신
├── traces.go ← OTLP traces 수신
├── logs.go ← OTLP logs 수신
└── profiles.go ← profiles 수신 (custom HTTP-based protocol + pprof binary)각 파일이 하나의 시그널 + 하나의 프로토콜 을 담당합니다. 즉 “한 프로토콜 한 책임” 의 깔끔한 분리.
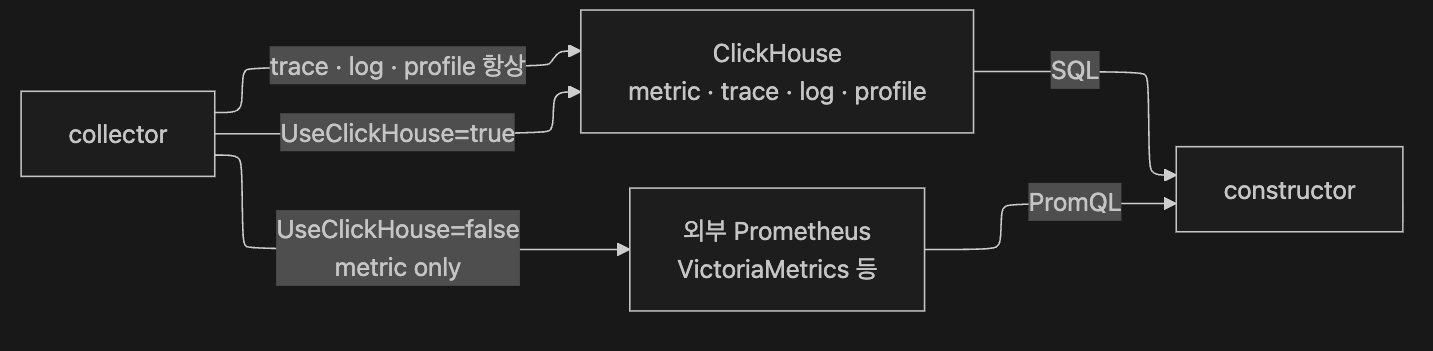
6. 저장소 — ClickHouse 와 Prometheus 의 분기
배경 정의는 §1.6 박스 E 참고. 본 절은
cfg.UseClickHouse분기가 어디서 metric 을 어디로 보내는가만 다룹니다.
6.2 Coroot 의 그 자리 — cfg.UseClickHouse 분기
collector 안의 cfg.UseClickHouse 분기는 metric 도 선택에 따라 ClickHouse 로 보낼 수 있게 합니다. "metric=Prometheus, trace=ClickHouse" 라는 이분법은 사실과 다릅니다.
collector/metrics.go 의 Metrics 핸들러
// coroot/collector/metrics.go:55-100 발췌 (commit bb13d53)
func (c *Collector) Metrics(w http.ResponseWriter, r *http.Request) {
cfg := project.PrometheusConfig(c.globalPrometheus)
body, _ := io.ReadAll(r.Body)
if cfg.UseClickHouse { // ① 분기 진입
req, _ := parseMetricsRequestBody(r, body)
c.getMetricsBatch(project).Add(req) // → ClickHouse batch 적재
return
}
// ② 외부 Prom 의 /api/v1/write 로 프록시
u, _ := url.Parse(cfg.Url)
u = u.JoinPath("/api/v1/write")
httpClient.Do(req) // remote_write proxy
}trace / log / profile 은 분기 없이 항상 ClickHouse 로 이동합니다.
6.3 두 모드의 운영 의미
UseClickHouse=true— ClickHouse 한 곳에 다 모음 → 저장소 운영 단일화, 압축 효율 ↑.UseClickHouse=false— metric 만 기존 Prometheus 자산에 → 사내 Grafana / 알람 정책 재사용.
10 배 압축 효율은 ClickHouse 공식 docs 와 Coroot architecture 페이지 둘 다 인용하는 수치 (단, 워크로드 의존성 있음).
7. 본체의 5 컴포넌트 — main.go wiring 한 컷
entry point 는 coroot repo 루트의 main.go (관례적인 cmd/coroot/ 디렉터리가 따로 없음). 본체가 main() 에서 직접 등록하는 컴포넌트가 곧 본체의 공식 책임 경계입니다.
| 컴포넌트 | 책임 | 본문 위치 |
|---|---|---|
| 메타데이터 DB | Postgres / SQLite 중 분기. 옵저버빌리티 데이터 X, 프로젝트·사용자·알람 설정 메타만 | (이 절) |
| collector | 4 시그널 입구 (metric / trace / log / profile) | §5.2 / §6.2 |
| promCache | 외부 Prometheus 의 짧은 윈도우 metric 캐시 (별도 layer) | (이 절) |
| api | REST / WebSocket / MCP | §10 |
| watchers | 시간 차원 누적 (burn-rate / deployments) | §9.7 |
배포 모델은 2 종 Edition + 1 종 통합 모드 입니다 (const Edition = "Community").
| 배포 | 의미 |
|---|---|
| Community Edition | OSS, 본 글이 다루는 코드 (coroot/coroot) |
| Enterprise Edition | 라이선스 ($1 / CPU core / month), 추가 기능 (고급 알람·SAML 등) |
| Coroot Cloud integration | Community 가 Coroot Cloud SaaS 에 연결하는 모드. AI RCA 같은 일부 기능을 통합으로 사용 가능 |
즉 "Cloud" 는 Edition 이 아니라 Community 가 SaaS 에 연결하는 모드 입니다. 마케팅의 "3 종 edition" 표현은 정확하지 않습니다.
이 5 컴포넌트 중 collector·promCache 는 §5·§6 에서 입구·저장소 분기로 다뤘고, api·watchers 는 §10·§9 로 갑니다. 본체의 핵심 도메인 모델인 AppToAppConnection 은 곧 §8 에서.
8. Service Graph 와 AppToAppConnection — 관계가 굳는 곳
8.1 왜 Service Graph 가 필요한가
5주차에서 정리한 RCA 의 핵심 입력은 “누가 누구를 호출하는가” 의 의존 그래프입니다 (4주차 § Service Dependency Graph). 그래프가 정확하지 않으면 “이 서비스가 느린 건 downstream 의 영향이다” 라는 추론 자체가 무너집니다.
Coroot 는 그 그래프를 코드로 모델링한 객체 로 갖고 있습니다.
8.2 Coroot 의 그 자리 — Application 과 AppToAppConnection
// coroot/model/application.go:14-52 발췌 (commit bb13d53)
type Application struct {
Id ApplicationId
Instances []*Instance
Downstreams map[ApplicationId]*AppToAppConnection
Upstreams map[ApplicationId]*AppToAppConnection
LatencySLIs []*LatencySLI
AvailabilitySLIs []*AvailabilitySLI
Events []*ApplicationEvent
Deployments []*ApplicationDeployment
Incidents []*ApplicationIncident
Status Status
Reports []*AuditReport
...
}// coroot/model/connection.go:49-68 발췌 (commit bb13d53)
type AppToAppConnection struct {
RemoteApplication *Application
Application *Application
Rtt *timeseries.TimeSeries
SuccessfulConnections *timeseries.TimeSeries
Active *timeseries.TimeSeries
FailedConnections *timeseries.TimeSeries
Retransmissions *timeseries.TimeSeries
RequestsCount map[Protocol]map[string]*timeseries.TimeSeries // by status
RequestsLatency map[Protocol]*timeseries.TimeSeries
...
}8.3 모델 닻은 connection.go, dependency_map.go 는 UI 직렬화
AppToAppConnection 의 정의는 model/connection.go:49 입니다. dependency_map.go 는 같은 이름처럼 보이지만 UI 직렬화용 의 DependencyMapNode / DependencyMapLink 만 갖습니다.
model/connection.go ← 도메인 모델 (inspector·auditor 가 읽음)
model/dependency_map.go ← UI 직렬화 (front 가 JSON 으로 받음)AppToAppConnection 은 UI 선이 아니라 모델 닻입니다. Service Map 화면의 노드·엣지 색은 AppToAppConnection.Status 를 그대로 시각화한 결과지, 별도의 추론 엔진이 색을 칠하는 게 아닙니다.
8.4 TCP 이벤트가 edge 로 굳는 경로

핵심 변환은 S 단계 — 목적지 IP 를 어떤 Application 인지 매핑하는 작업입니다. cluster-agent 가 informer 로 본 Service / Endpoints 가 여기 입력으로 들어옵니다. 즉 Service Map 정확도 = node-agent 의 L7 인식 + cluster-agent 의 K8s 메타 정확도 의 곱입니다.
운영 노트 —
rr_*recording rule 은 외부에 노출되지 않습니다.
constructor가 PromQL 비용을 줄이려고 만든 recording rule (rr_connection_*등) 은 coroot 프로세스 메모리 안에서만 평가됩니다./api/metrics노출 296 종 중rr_접두사는 0 개.즉 외부 Prometheus / Grafana 에서 같은 이름으로 service map 을 재현하려면 별도 PromQL 을 직접 작성해야 합니다. Coroot UI 의 service map 은 Coroot 본체 안에서만 같은 비용으로 그려진다 — 운영 시각의 한 줄 결론입니다.
8.5 constructor 내부는 후속 글로
raw ClickHouse row 와 PromQL 결과를 결합해 Application·AppToAppConnection 을 채우는 constructor/{connections,sli,queries}.go 함수 매핑은 7주차의 실 쿼리 시연 뒤 부록으로 이어집니다.
9. 판단의 구조 — inspector 19 stages · watchers · Check 4-type
9.1 왜 룰 기반 엔진이 필요한가
5주차 RCA 이론은 “후보 압축기” 의 자리를 정의했습니다. 그 압축기 가 코드에서 어떤 형태 인지가 6주차의 무게중심입니다. 답은 단순합니다 — 결정론적 룰 기반 진단 엔진 입니다.
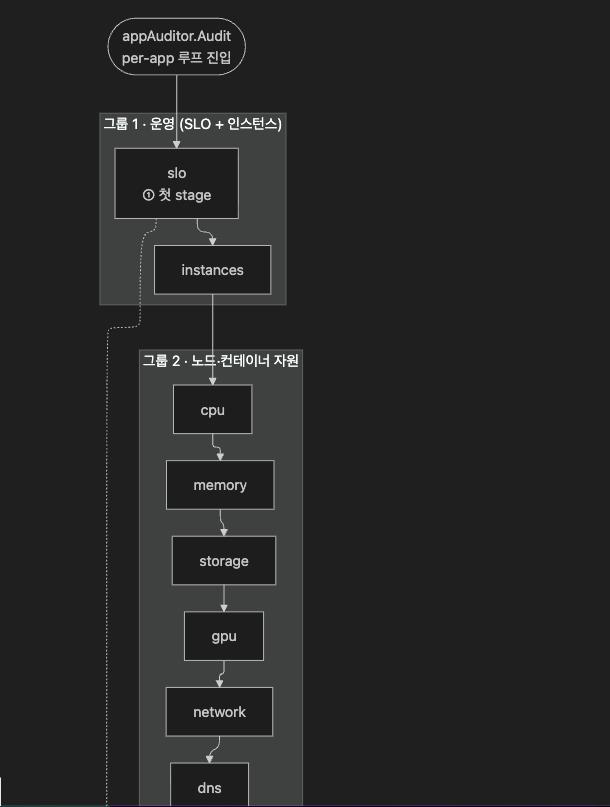
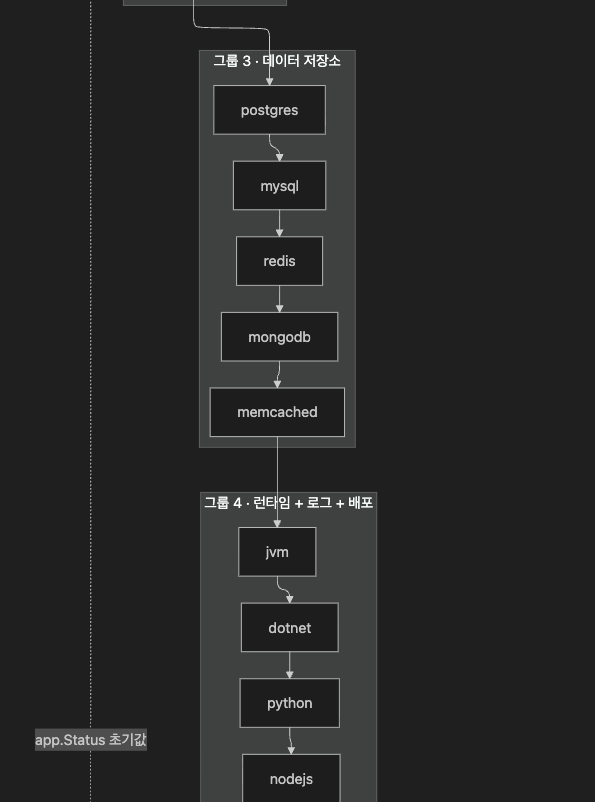
9.2 auditor.Audit(...) 의 19 stages 루프
// coroot/auditor/auditor.go:44-69 발췌 (commit bb13d53)
for _, app := range w.Applications {
a := &appAuditor{w: w, p: p, app: app, ...}
stages.stage("slo", a.slo) // ① 항상 첫 번째
stages.stage("instances", a.instances)
stages.stage("cpu", func() { a.cpu(ncs) })
stages.stage("memory", func() { a.memory(ncs) })
stages.stage("storage", a.storage)
stages.stage("gpu", a.gpu)
stages.stage("network", a.network)
stages.stage("dns", a.dns)
stages.stage("postgres", a.postgres)
stages.stage("mysql", a.mysql)
stages.stage("redis", a.redis)
stages.stage("mongodb", a.mongodb)
stages.stage("memcached", a.memcached)
stages.stage("jvm", a.jvm)
stages.stage("dotnet", a.dotnet)
stages.stage("python", a.python)
stages.stage("nodejs", a.nodejs)
stages.stage("logs", a.logs)
stages.stage("deployments", a.deployments) // ② 항상 마지막
...
}19 stages 를 4 그룹 으로 묶어 보면:
| 그룹 | stages | 무엇을 보는가 |
|---|---|---|
| SLO + 인스턴스 (운영) | slo, instances | 사용자 영향도 + 가용성 |
| 노드·컨테이너 자원 | cpu, memory, storage, gpu, network, dns | 인프라 자원 |
| 데이터 저장소 | postgres, mysql, redis, mongodb, memcached | DB / 캐시 |
| 언어 런타임 + 로그 + 배포 | jvm, dotnet, python, nodejs, logs, deployments | 애플리케이션 측 |
stage 는 정확히 19 개, 그리고 SLO 가 첫 / deployments 가 마지막 이라는 순서가 의미를 가집니다. SLO 가 만든 status 는 app.Status 의 초기값이 되고, deployments timeline 은 다른 모든 widget 에 annotation 으로 합류합니다.
공식 docs 는 20 inspections 로 카운트 — 코드의 19 stage + UI 의 Overview 통합 뷰 1 개 = 20. 여기서는 코드 stage 만 단정합니다.
9.3 Check 4-type — 판정 양식의 차이
// coroot/model/check.go:18-25 (commit bb13d53)
type CheckType int
const (
CheckTypeEventBased CheckType = iota
CheckTypeItemBased
CheckTypeValueBased
CheckTypeManual
)| Check 타입 | 의미 | 본 글의 4 종 inspector 사례 |
|---|---|---|
| EventBased | “어떤 사건이 일어났다” — 시점 단위 | MemoryOOM, LogErrors, DnsServerErrors |
| ItemBased | “어떤 항목들이 문제다” — 목록 단위 | postgres 4 checks, network 5 checks 모두 |
| ValueBased | “수치 자체가 status 다” — 게이지 | DeploymentStatus, MemoryLeakPercent |
| Manual | “사람 / 외부 문맥이 status 를 정함” | SLOAvailability, SLOLatency |
9.4 inspector 4 종 한 컷 표
| inspector | 입력 | Check 개수 | default 임계 | Check 타입 |
|---|---|---|---|---|
| postgres | Instance.Postgres.* | 4 | latency 0.1 s · replication 30 s · connections 90 % · availability 0 | ItemBased × 4 |
| network | Application.Upstreams.AppToAppConnection.* | 5 | in-cluster RTT 10 ms · cross-cluster 100 ms · external 200 ms · connectivity 0 · failed 0 | ItemBased × 5 |
| deployments | Application.Deployments | 1 | rollout in progress > 180s | ValueBased × 1 |
| slo | Application.AvailabilitySLIs / LatencySLIs / Incidents | 2 | objective 99% (default) | Manual × 2 |
postgres replication lag 의 time-based 추정:
auditor/postgres.go:151-192의checkReplicationLag가 primary 의 LSN 시계열을 뒤로 iterate 하며 현재 replica 의 LSN 값이 primary 에 있던 시점 을 찾아lagTime = tCurr - tPast로 시간 단위 추정. 바이트 단위 lag 가 아닌 시간 단위 lag 가 화면에 보이는 이유.
inspector 4 종 — 운영 관점의 잡는 것 / 놓치는 것
위 표는 "어디를 담당하는가" 의 코드 관점이고, 아래 표는 "실제 장애에서 무엇을 잡고 무엇을 놓치는가" 의 운영 관점입니다.
| inspector | 잡는 결정적 사례 | 놓치는 전형적 사례 |
|---|---|---|
| postgres | 풀 포화가 서버 측 90 % 를 넘는 순간, replication lag 가 30 s 를 넘는 순간 | 애플리케이션 측 풀 (HikariCP maximumPoolSize, pgbouncer pool_size) 포화, 90 % 이하에서 latency 만 먼저 치솟는 부분 saturation (§9.6) |
| network | in-cluster RTT > 10 ms, cross-cluster > 100 ms, connection failed 증가 — 어느 두 앱 사이 인지 함께 | mTLS sidecar 내부의 L7 payload, 비즈니스 인과 (correlation ID), 외부 Internet hop 의 RTT 분해 (§11.2 (1)) |
| deployments | rollout 이 180 s 를 넘으면 진행 중인 배포 가 모든 위젯에 annotation 으로 합류 | Canary / Argo Rollouts 같은 배포 도메인 모델, artifact digest 단위 변경 (§11.2 (2)) |
| slo | SLO objective 99 % 가깝게 burn-rate 가 14.4× 또는 6× 임계 도달 (§9.7) | objective 가 비즈니스 분리 (free vs paid) 로 다중 인 경우 — 단일 임계 1 개만 평가 |
9.5 임계값의 철학 — 어디서 임계가 오나 (토론 Q2)
토론 질문 2 — “임계·baseline·패턴은 코드에서 상수 인가 설정 인가 학습 인가” 에 대한 명시적 답.
4 분류로 정리:
| # | 분류 | 코드 위치 | 예시 |
|---|---|---|---|
| 1 | 상수 기본값 | model/check.go 의 CheckConfig.DefaultThreshold 필드 | PostgresConnections.DefaultThreshold = 90 (%) |
| 2 | 설정 주입 (코드 경로) | model/audit_report.go 의 CreateCheck(...) 가 checkConfigs 에서 임계를 가져옴 | 프로젝트 / 앱 override 가능 |
| 3 | UI 노출 | api/views/inspections/inspections.go 가 GlobalThreshold · ProjectThreshold · ApplicationOverrides 를 API 응답으로 노출 | 운영자가 UI 에서 threshold override 가능 |
| 4 | 데이터 계산 (학습 X) | watchers/incidents.go 가 burn-rate 를 계산, auditor/slo.go 가 그 severity 를 채택 | 학습된 ML 모델 이 아니라 결정론적 시간 누적 계산 |
학습은 어디에도 없습니다. ML 임계 자동 조정 같은 것은 OSS Coroot 의 inspector 범위 밖. AI 가 끼는 자리는 §10 의 세 곳 뿐, 임계 결정 자리에는 없음.
9.6 DB pool 시나리오 — 결정적 단서, 그리고 놓치는 경우
토론 Q2 의 DB connection pool 시나리오 답.
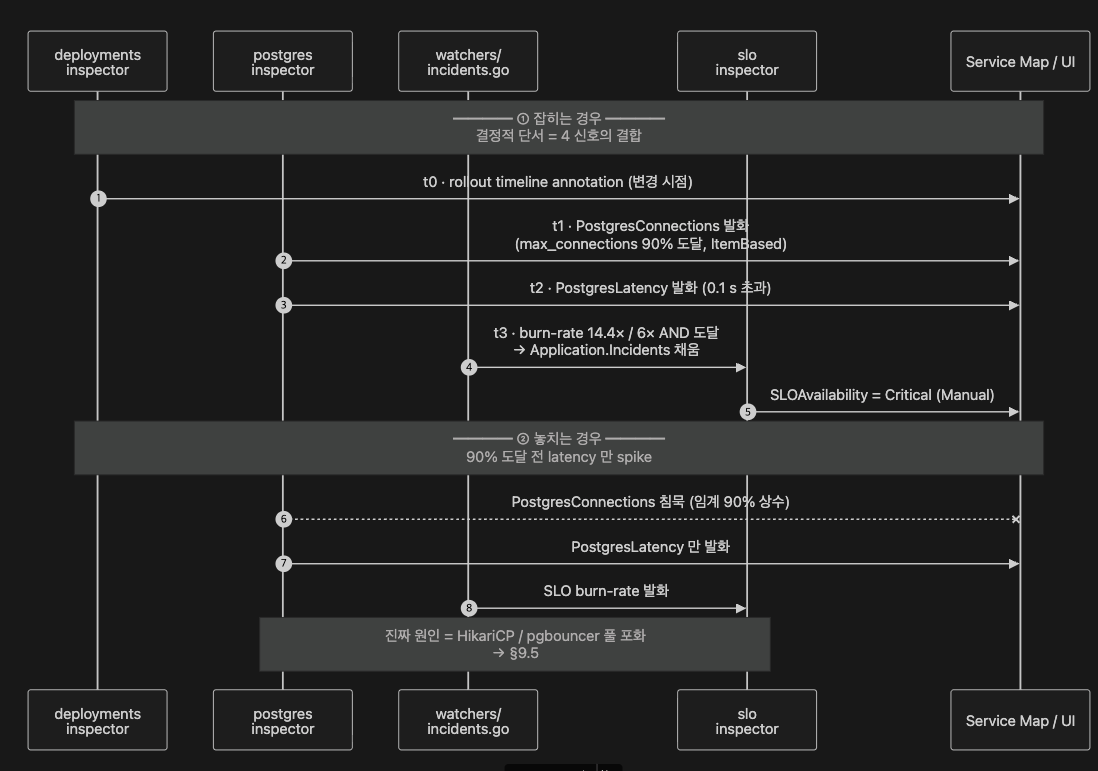
잡히는 경우 (시간순 발화):
t0: 새 배포가 들어오면deploymentsinspector 가 rollout timeline annotation 을 만듦 — 변경 시점.t1: 잘못된 pool 설정으로connections(pg_stat_activity) 가 늘어max_connections의 90 % 에 닿음 →PostgresConnections발화 (ItemBased).t2: 이어PostgresLatency(0.1 s 초과) 가 발화 가능.t3: SLOburn-rate가 악화 →watchers/incidents.go가 incident 를 열어SLOAvailability(Manual) status 가 Critical 로.- 결정적 단서 = 배포 시점 annotation + connection saturation + DB latency + SLO 악화의 결합.
놓치는 경우
- 풀 설정이 나쁘게 잡혔어도 90% 를 넘기 전 에 latency 만 먼저 치솟으면
PostgresConnections는 침묵 합니다 — 임계가 90% 상수이기 때문. 임계의 한계 가 결정적 단서의 한계 로 직결. - 이 경우 잡히는 신호는 PostgresLatency + SLO burn-rate 뿐 — 연결 saturation 이라는 진짜 원인 은 §9.5 의 #3 (UI override) 으로 임계를 50% 로 낮춰야 잡힘.
→ 그래서 Q2 의 답은 “상수다” 가 아니라 “기본값은 상수, 실제 적용은 override 가능, SLO 는 데이터 계산, 학습 모델은 없음” 의 4 분류 답 이 정확.
사각지대 — 애플리케이션 측 풀은 Coroot 시야 밖.
§9.6 의 코드 경로는 Postgres 서버 측 max_connections 만 봅니다. 애플리케이션 측 connection pool 은 직접 보지 않습니다.
- HikariCP —
maximumPoolSize가 10 으로 잡혀 서버max_connections200 의 5 % 만 점유해도, Java 앱 내부에서 풀 대기가 길어지면 latency 만 치솟습니다.PostgresConnections는 침묵. - pgbouncer —
pool_size/max_client_conn도 동일. transaction pooling 모드의 대기 큐는 Coroot inspector 가 직접 모릅니다. - 간접 단서 —
PostgresLatency(0.1 s) 와 SLO burn-rate 뿐. 진짜 원인은 애플리케이션 메트릭 (HikariCP JMX, pgbouncerSHOW POOLS) 으로 별도 보강해야 보입니다. §9.5 의 UI override 로 임계를 낮춰도 서버 측만 낮추는 것이라 동일한 한계가 남습니다.
9.7 watchers — 시간 차원의 분업
여기 결정적인 분담 이 있습니다. auditor 는 “현재 상태의 룰 평가” 만 합니다. “지난 1 시간 burn-rate 가 X% 인가” 같은 시간 누적 계산 은 watchers/ 가 책임집니다.
coroot/
├── auditor/ ← 룰 평가 (읽기 전용 layer)
└── watchers/
├── incidents.go ← burn-rate 누적 → Application.Incidents 채움
└── deployments.go ← ReplicaSet 패턴에서 deployment 추출 → Application.Deployments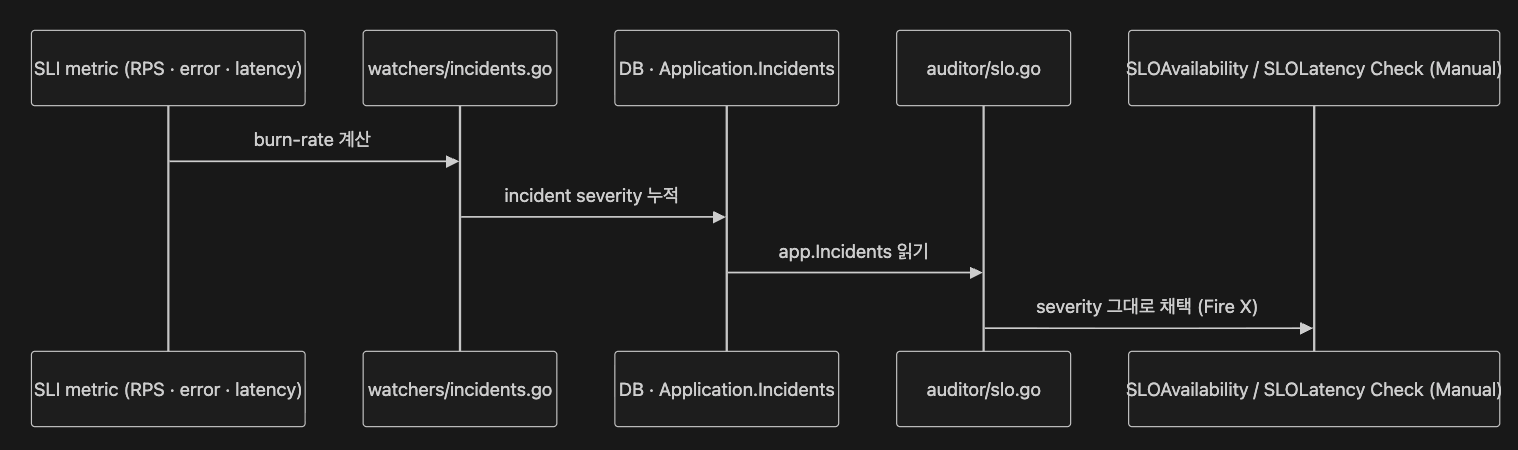
즉 watchers 가 쓰고 auditor 가 읽는 분업. SLO inspector 가 “단순 임계” 가 아니라 “이미 계산된 severity 채택” 인 이유입니다. 학습된 모델 도 AI 도 어디에도 없습니다.
burn-rate 두 줄 — multi-window AND 게이트
watchers/incidents.go 가 burn-rate 를 “단일 임계” 가 아니라 두 윈도우 동시 충족 으로 평가하는 코드 차원의 정확한 모양:
// coroot/model/alert.go:19-20 발췌 (commit bb13d53)
{LongWindow: timeseries.Hour, ShortWindow: 5 * timeseries.Minute, BurnRateThreshold: 14.4, Severity: CRITICAL},
{LongWindow: 6 * timeseries.Hour, ShortWindow: 15 * timeseries.Minute, BurnRateThreshold: 6, Severity: CRITICAL},
| 윈도우 쌍 | 임계 burn-rate | 의미 (Google SRE Workbook 의 multi-window 패턴) |
|---|---|---|
| 1 시간 / 5 분 | 14.4× | 빠른 burn — 2 % budget 을 1 시간 안에 태우는 속도 |
| 6 시간 / 15 분 | 6× | 느린 burn — 5 % budget 을 6 시간 안에 태우는 속도 |
→ 두 윈도우가 동시에 임계에 도달할 때만 incident 가 열립니다. 짧은 spike 만 또는 오래된 burn 의 잔존만으로는 발화하지 않는다는 뜻 — false alarm 억제와 빠른 감지의 동시 달성 패턴.
§9.4 의 상수 (90 % / 0.1 s / 30 s) 와 동일한 결정론이지만, 시간 누적 차원에 있다는 점만 다릅니다.
9.8 Status propagation 의 한정 — 4 카테고리만
inspector 19 종이 모두 발화한 결과 중 단 4 카테고리 만 app.Status (Service Map 노드 색) 로 올라갑니다.
// coroot/auditor/auditor.go:84-89 (commit bb13d53)
switch r.Name {
case model.AuditReportPostgres,
model.AuditReportRedis,
model.AuditReportInstances,
model.AuditReportSLO:
if app.Status < r.Status {
app.Status = r.Status
}
}| inspector report | app.Status 로 propagate? |
|---|---|
| Postgres, Redis, Instances, SLO | O |
| CPU, Memory, Network, Deployments, …나머지 15 | X (해당 report 위젯에는 표시되지만 노드 색은 안 바뀜) |
즉 app.Status 는 ML 판단이 아니라 auditor.go:84-89 의 결정론적 매핑 입니다.
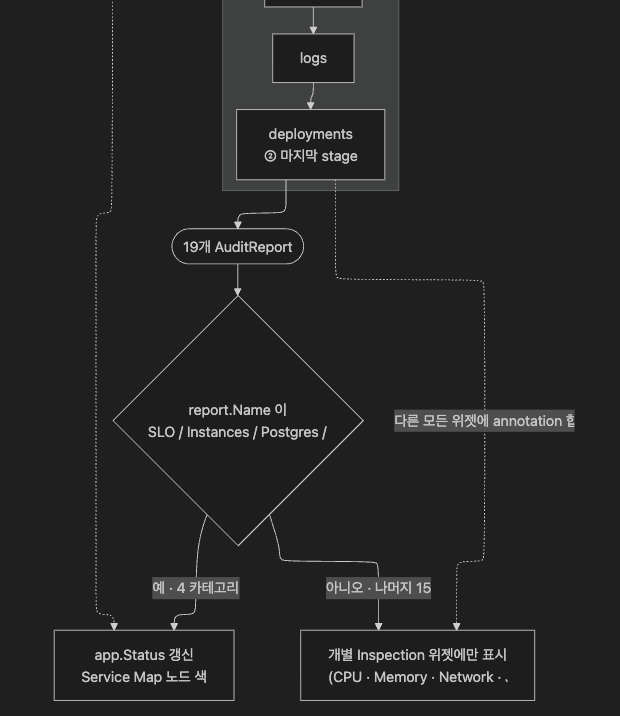
9.9 Alerting 출구 — checks/watchers 가 어디로 나가나
inspector 의 Check 와 watchers 의 incident 가 발화 한 뒤, 그 정보가 외부 운영자 에게 도달하는 경로가 alerting/ 입니다. 공식 docs (docs.coroot.com/alerting/alerts/) 가 정의하는 4 종 alert source type 과 외부 통합을 짧게.
| Alert source type | 트리거 |
|---|---|
| Check-based | 내장 inspector 의 Check 가 임계 초과 (CPU / 가용성 / latency 등 §9 의 19 stages 결과) |
| Log-based | 로그에서 error / fatal 패턴 이 자동 감지됨 (node-agent 의 §4.5 log clustering 결과) |
| Kubernetes events-based | K8s Events (FailedScheduling / BackOff 등) 가 도달 — cluster-agent 의 §4.4 OTLP logs 경로 |
| PromQL-based | 사용자 정의 PromQL 식이 평가 — custom rule 자리 |
→ alerts 와 incidents 는 다릅니다. 위 4 source 의 발화는 alerts 로 처리되고, 그중 SLO 가 깨질 정도의 사건만 별도로 incidents 로 누적됩니다 (watchers/incidents.go 가 burn-rate 를 시간 단위로 모음). 공식 docs 가 alerts ≠ incidents 로 분리해 묘사하는 이유입니다.
외부 채널 5 종: Slack · Microsoft Teams · PagerDuty · Opsgenie · Webhook. 이론적 가치만 — 실 연결은 7주차에 위임합니다.
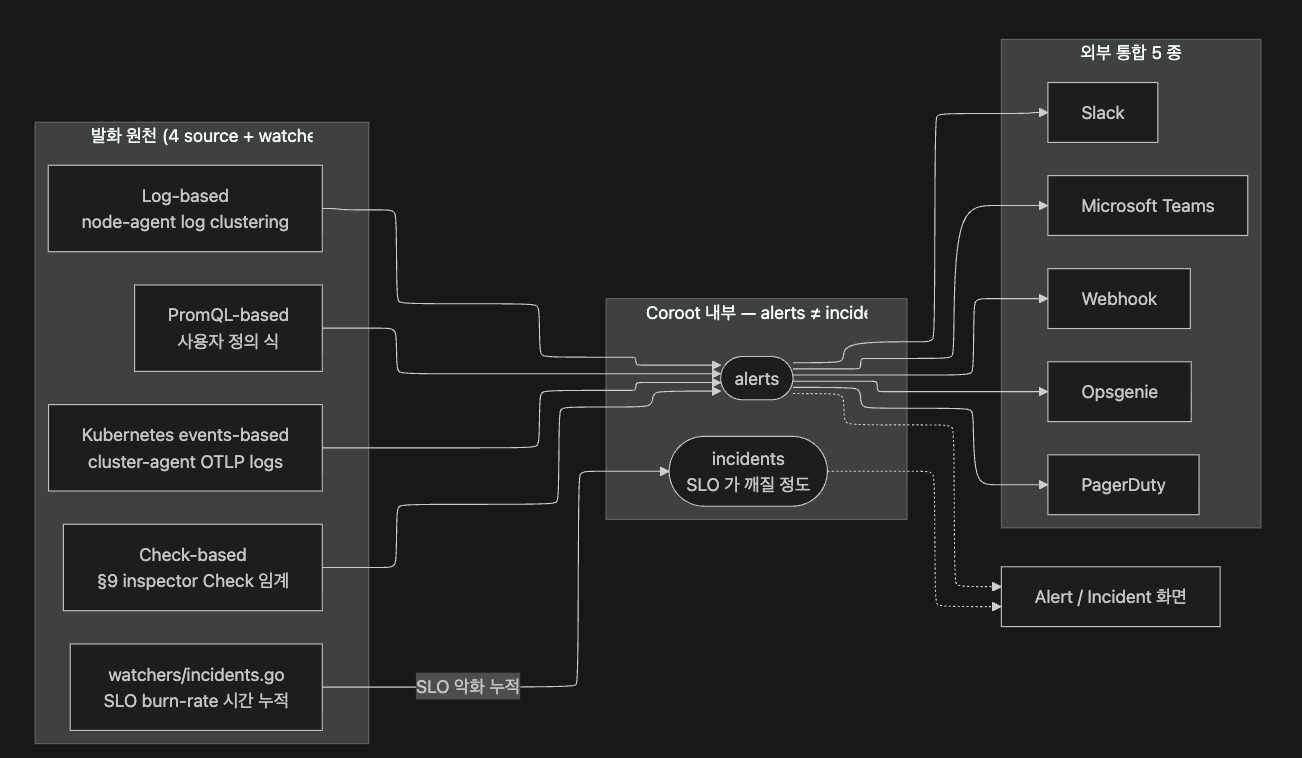
§9 의 결정론 룰이 어디로 흐르는지의 마지막 단계입니다. 한 줄로 요약하면:
inspector → Check → app.Status → AuditReport → (alert source) → 외부 채널
9.10 UI rendering 경로 — AuditReport 는 어느 함수에서 결정되나 (토론 Q3)
토론 질문 3 — “AuditReport / Inspect dialog 가 evidence 를 어떤 순서·형식으로 제시하나, 어느 함수에서 결정되나” 에 대한 명시적 답.
evidence 흐름
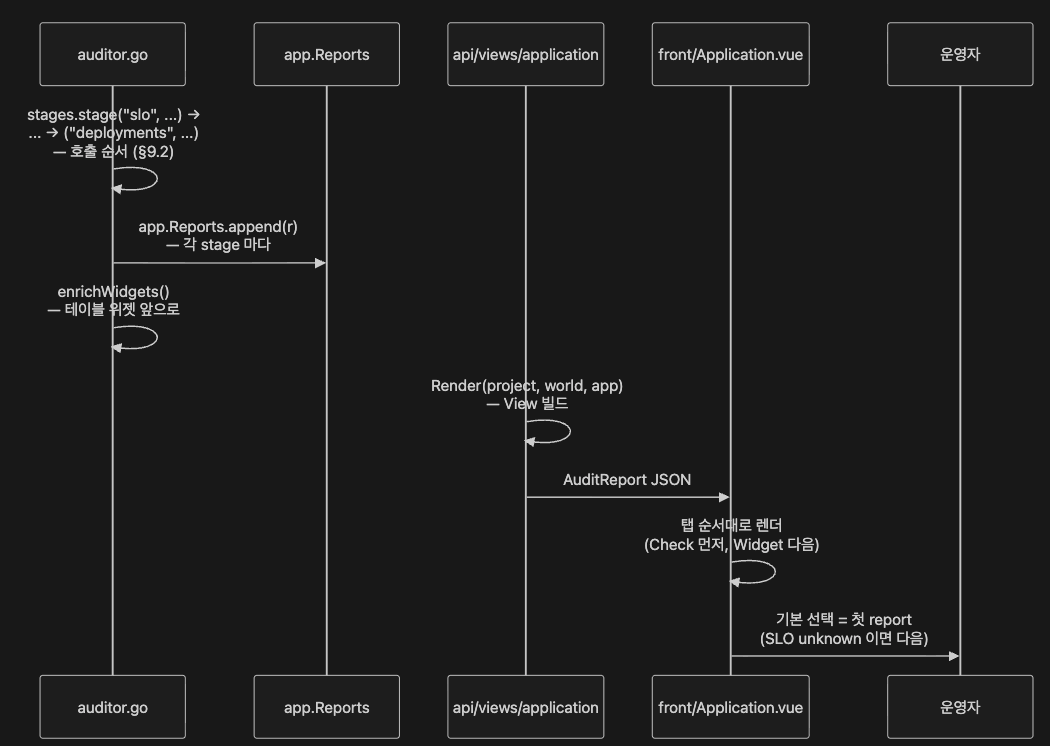
evidence 순서·형식의 결정 함수 4 개 (commit bb13d53 기준):
| 결정 사항 | 결정하는 함수 / 파일 |
|---|---|
| report 순서 | auditor/auditor.go:44-69 의 stages.stage(...) 호출 순서 |
| widget 내 재배치 (테이블 앞으로) | auditor/auditor.go 의 enrichWidgets() |
| API view 빌드 | api/views/application/application.go:52 의 Render(project, world, app) *View |
| front 렌더 + 기본 탭 선택 | front/src/views/Application.vue 의 탭 순서 + Check 목록 우선 렌더 + SLO unknown 시 다음 탭 fallback |
Inspect dialog 라는 별도 컴포넌트 경로는 작성 시점 코드에서 미확정. 7주차에서 실 화면을 띄우며 컴포넌트명을 확정합니다.
이 흐름이 왜 SLO 탭이 맨 위에 보이는지, 왜 어떤 Check 가 먼저 보이는지 의 코드 차원 답입니다. AI 의 추천이 아니라 코드의 순서가 UI 순서입니다.
10. AI 가 끼는 자리 — Cloud ML · Cloud LLM · OSS MCP
10.1 왜 세 자리인가
여기까지 이론을 따라온 독자는 “그래서 AI 는 어디에 끼나” 가 궁금해집니다. 답은 세 곳 이고, 완전히 다른 책임 을 갖습니다.
10.2 공식 docs 가 직접 인용한 분업
Coroot 공식 docs (docs.coroot.com/ai/overview/) 가 결정적인 한 문장을 적습니다.
“This step uses various ML (Machine Learning) algorithms and doesn’t involve LLMs. … we avoid relying on LLMs for the actual root cause analysis, where they are not very effective. Instead, we use them for what they do best: explaining complex issues and summarizing results.”
요약하면
- RCA 후보 압축 = Cloud 측 ML 알고리즘 (LLM 미사용)
- “Explain with AI” = Cloud 측 LLM (후보 요약·설명 만)
- 그리고 OSS 안에는 AI 호출 이 별도로 있습니다 — MCP 서버 (§10.4).
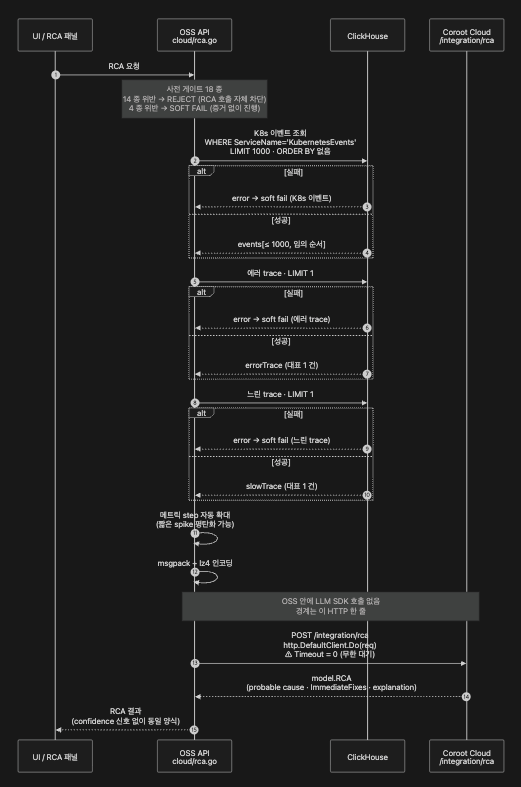
10.3 OSS 의 Cloud 호출 클라이언트 — cloud/rca.go
// coroot/cloud/rca.go:34-49 발췌 (commit bb13d53)
func (api *Api) RCA(ctx context.Context, req RCARequest) (*model.RCA, error) {
buf := bytes.NewBuffer(nil)
lw := lz4.NewWriter(buf)
if err := msgpack.NewEncoder(lw).Encode(req); err != nil { ... }
// ↓ OSS / Cloud 경계가 사실상 여기서 그어진다
if err := api.request(ctx, http.MethodPost,
"/integration/rca", "application/msgpack", "lz4", buf, &rca); err != nil {
return nil, err
}
return &rca, nil
}OSS 안에는 openai / anthropic 라이브러리 호출이 없습니다. 대신 Cloud HTTP API 로 데이터를 보내고 결과를 받아 표시합니다. 경계가 이 한 줄에서 깨끗이 그어집니다.
Cloud 호출의 세 가지 흠 — cloud/rca.go 가 Cloud 로 보내기 전에 조용히 두는 제약, 그리고 게이트·전송 단계의 흠을 한 표로:
| 단계 | 현상 | 운영 영향 |
|---|---|---|
| 입력 큐레이션 | K8s 이벤트 LIMIT 1000·ORDER BY 없음 / 에러 trace LIMIT 1 / 느린 trace LIMIT 1 / 메트릭 step 자동 확대 | 결정론적 기준 없이 잘려, 같은 입력이라도 런마다 다른 증거 묶음 이 Cloud 로 갑니다. |
| 게이트 (14 reject vs 4 soft fail) | 18 종 게이트 중 14 종 위반 시 reject. 4 종(ClickHouse·K8s 이벤트·에러 trace·느린 trace 조회 실패)은 soft fail — 증거 없이 진행. | RCA 응답에 부분 증거 표시가 없어, "confidence 낮음" 신호 없이 동일 양식으로 돌아옵니다. |
| 전송 | http.DefaultClient.Do(req) — Go 기본 타임아웃 0 (무한 대기) | Cloud 가 느리면 RCA 핸들러가 hang 처럼 보입니다. reverse proxy / Ingress 에서 타임아웃을 강제하거나 http.Client{Timeout: ...} 주입이 필요합니다. |
10.4 제 3 자리 — OSS 내장 MCP 서버 17 도구
4주차 § Anthropic MCP 메시지와 가장 직접 연결되는 부분입니다.
coroot/api/mcp.go 는 Coroot 가 직접 MCP (Model Context Protocol) 서버를 호스팅 함을 보여 줍니다.
// coroot/api/mcp.go:27 부분 발췌 (commit bb13d53)
const MCPInstructions = `Coroot is a production observability platform.
Reach for it when the user asks about live behavior of a running system:
why a service is slow or erroring, what changed, what alerts are firing,
what depends on what, recent incidents, capacity, deploys.
...
Pick a tool by intent, cheapest first:
- "What's currently broken?" → list_alerts (firing alerts), list_incidents,
list_applications (per-app inspection issues + SLO status).
- "What's wrong with <app>?" → get_application_status: overall status,
per-inspection (CPU, memory, SLO, postgres, ...) issues, log-pattern samples,
upstream dependencies with connectivity/RTT/latency, and downstream clients.
- Distributed traces — three drill-down levels:
• triage → traces_summary, errors → traces_errors, slow tail → traces_outliers,
• full trace → get_trace ...
- "Show me logs" → query_logs ...
- "Acting on alerts" → resolve_alerts ...
...`17 도구 중 8 개 (본문 표):
| 카테고리 | 도구 | 의미 |
|---|---|---|
| 알람 | list_alerts, list_incidents | 무엇이 깨졌는지 |
| 단일 앱 | get_application_status | 한 앱의 RCA 상태·dependency |
| 트레이스 | traces_summary, traces_errors, traces_outliers, get_trace | 4 단 drill-down |
| 로그 | query_logs | 검색·심각도·시간 범위 |
(나머지 9 개 — list_projects, select_project, list_nodes, get_node_details, query_metrics, list_metric_names, get_incident_details, resolve_alerts 등 — 은 부록 또는 8주차 실습.)
10.5 AI 3 자리 한 컷

세 자리는 색·책임·활성화 조건이 모두 다릅니다.
| AI 자리 | 위치 | 활성화 조건 |
|---|---|---|
| Cloud ML (후보 압축) | Cloud 서버 | Community Edition + Coroot Cloud integration (월 10 free credits, 1 credit = 1 RCA) 또는 Enterprise Edition ($1 / CPU core / month) |
| Cloud LLM (“Explain with AI”) | Cloud 서버 | 위와 동일 |
| OSS MCP 서버 (17 도구) | OSS 에 직접 내장 | OSS 단독으로 가능. 외부 LLM 에이전트가 클라이언트 |
그래서 Coroot 가 AI 로 RCA 를 자동으로 한다 는 한 줄 마케팅 문구를 다시 풀어쓰면, AI 가 끼는 자리는 정확히 세 곳이고 §3 부터 §9 까지 다룬 룰·watchers·inspector·Check 는 어디에도 AI 가 없는 결정론입니다.
11. 비유의 한계
비유는 입구일 뿐. 박스 비유가 잡지 못하는 두 자리만 짚어 둡니다.
(1) eBPF 가 보는 것의 한계
"바닥 센서가 모든 박스를 본다" 는 과장에 가깝습니다. 실제 eBPF 가 잡는 범위:
- L3 / L4 (TCP / UDP) — 거의 다 본다
- L7 plain text — well-known 포트 + payload 패턴 매칭, 9 종 프로토콜만
- L7 TLS — uprobe + SSL 라이브러리 후킹 (Go gotls 등) 필요. mTLS sidecar 환경에서는 비용이 큼
- 비즈니스 인과 — correlation ID 는 보지 못함 (애플리케이션 로그 / span 과 결합해야 보임)
(2) 도메인 실행 의미론의 한계 — run / job / artifact / DAG
박스 비유는 물리적 흐름까지만 잡습니다. Coroot 의 inspector / watchers / Check 도 기본적으로 다음 9 종을 모릅니다 — 데이터·배치 엔지니어 독자용 가드레일:
| 사각지대 | 무엇 | 보강 경로 |
|---|---|---|
| run / job / attempt 단위 | Airflow DAG run, Argo Workflow, Spark job, K8s Job 의 재시도 attempt | 애플리케이션 메트릭 / 자체 이벤트 모델로 별도 |
| artifact digest | 컨테이너 이미지 digest, 모델 weights hash, 데이터셋 버전 | 배포 도메인 (Argo CD / Flux) 의 별도 신호 |
| DAG 의존성 | upstream task 가 실패해서 downstream 이 skip 됐는지 | Airflow / Argo 의 자체 이벤트 모델 |
| retry / fail-fast 정책 | 어떤 실패가 의도된 retry 인지, 어떤 실패가 fail-fast 인지 | 애플리케이션 측 분류 — Coroot 는 그냥 에러 카운트 |
| queue wait time | Kafka consumer lag, SQS visibility timeout, K8s scheduler 대기 | Prometheus exporter 별도, K8s 이벤트 일부만 |
| business correlation ID | “이 요청은 사용자 A 의 주문” | 애플리케이션 trace context 전파 필요 (§11.2 (1) 재참조) |
| multi-tenant 분리 | 같은 SLO 라도 tenant 별 로 다른 obj | UI override 1 개 — 다중 tenant 별 SLO 는 별도 application 으로 쪼개야 |
| 외부 SLA 의존성 | 외부 API / 결제 / SaaS 의 SLA | external dependency 의 RTT 까지만 (§11.2 (1)) |
| provenance 체인 | 어떤 입력 으로 어떤 모델 / 코드 가 어떤 출력 을 만들었는지 | Sigstore / SLSA 별도 — Coroot 시야 밖 |
→ Coroot 가 부족해서가 아니라, 책임 범위가 아니다. 그 위에 도메인 의미론을 얹는 것은 애플리케이션 / 배포 / 비즈니스 측 별도 모델의 몫입니다.
12. 마무리 — 하는 것과 하지 않는 것
12.1 한 페이지 요약
| 질문 | 답 |
|---|---|
| Coroot 의 RCA 는 어떤 시스템? | 결정론적 책임 분담 파이프라인. node-agent → cluster-agent → 본체 → watchers + auditor → Check → UI / MCP. AI 가 끼는 자리는 정확히 세 곳. |
| 6주차 두 deep-read 축? | (B) 데이터 흐름 (eBPF → 저장소 → 모델 → Check) (C) 책임 분담 (3 컴포넌트의 다른 관측면) |
Check 4-type 의 정체? | CheckTypeEventBased / ItemBased / ValueBased / Manual — 4 종 운영 시나리오 분리 양식 |
| inspector 의 Check 가 곧 root cause? | 아니다. 후보 압축. 결정적 단서는 “변경 시점 × 변경 내용 × 직접 증거” 의 시간순 결합 필요. |
| Service Map 색은 무엇이 정함? | app.Status. 단 4 카테고리 (postgres/redis/instances/slo) Check status 만 받음. 나머지 15 종은 위젯에만 표시. |
| MCP 서버가 OSS 에 내장됨? | 17 도구. 외부 LLM 에이전트가 표준 프로토콜로 Coroot 데이터를 조회·resolve 가능. |
12.2 하는 것과 하지 않는 것
| Coroot 가 하는 것 | Coroot 가 안 하는 것 |
|---|---|
| eBPF 로 애플리케이션 변경 없이 TCP / L7 (9 종) 신호 수집 | 비즈니스 인과 (correlation ID) 자체 추론 |
| K8s informer + DB credentials 발견 + AWS / ksm 통합 | 사내 고유 메트릭 의 자동 의미 해석 |
cfg.UseClickHouse 분기로 metric 저장 위치 선택 | metric 의 retention 정책 자동 결정 |
| 19 inspector 의 결정론 룰 평가 | 학습된 ML 모델 로 임계 자동 조정 |
Check 4-type 으로 판정 양식 분리 | confidence score (5주차 ML RCA 의 의미) 출력 |
| watchers 로 시간 차원 누적 (burn-rate 등) | 실시간 < 1 초 의 reactive alerting |
| OSS 안에 MCP 서버 17 도구 내장 | OSS 안에서 LLM 직접 호출 |
| Cloud 연결 시 RCA 후보 압축 (ML) 과 자연어 요약 (LLM) 보조 | OSS 단독으로 AI RCA 수행 |
포지셔닝 한 줄 (ADR 양식).
Coroot 는 내부 실행 시스템의 정본 이벤트 모델을 대체하지 않습니다. DAG run, artifact digest, business correlation ID 같은 §11.2 (2) 의 도메인 실행 의미론은 각 도메인의 정본 모델 (Airflow / Argo / Flux / SLSA) 이 갖고, Coroot 는 그 위에 붙는 RCA 보조 관측 계층 입니다.
따라서 RCA 결과는 조사의 출발 가설 로 다루고,
ImmediateFixes를 검증 없이 실행하지 않는 것이 안전한 운영입니다. §9.6 의 사각지대 박스와 §10.3 의 soft fail 비대칭이 모두 이 한 줄에서 같은 결론으로 모입니다.
12.3 마스터 비유 회수 — 7주차로의 다리
운영실은 셋의 시야를 합치는 곳입니다. 라인 끝 카메라가 박스 흐름을 보고, 관리 사무소가 입출고 장부를 갱신하고, 운영실이 그 둘을 합쳐 결정 합니다. AI 는 그 결정 위에 세 자리로만 얹힙니다.
7주차는 이 셋을 실제로 띄우는 단계입니다 — k3d + helm + 3 컴포넌트 + OTel Astronomy Shop. 본 글의 §1 architecture 도식이 그림이라면, 7주차는 그 그림이 실제로 동작하는 클러스터입니다.
8주차는 그 클러스터에 chaos 를 주입했을 때 본 글의 19 stages 가 시간순으로 어떻게 발화하는지의 timeline 입니다.
12.4 코드의 반전 — Discussion Wrap-up (토론 Q1)
토론 질문 1 — “deep-read 한 영역에서 처음 짐작과 실제 코드 동작이 가장 크게 달랐던 한 곳” 에 대한 명시적 답.
4 가지 가설 정정 (본문 곳곳 분산 — 한 박스로 회수):
| # | 처음 짐작 | 실제 코드 | 근거 |
|---|---|---|---|
| 1 | kprobe/tcp_v4_connect 후킹 / connect 와 listen 이 별도 후킹 | tracepoint/sock/inet_sock_set_state 한 곳에서 TCP 상태 전환 (connect + listen) 모두 처리 | coroot-node-agent/ebpftracer/ebpf/tcp/state.c — SEC 라인 |
| 2 | coroot-cluster-agent = K8s informer 전용 | informer + DB scraper (Postgres/MySQL/Mongo/Redis/Memcached) + AWS + ksm + Prom 자체 스크래퍼 + DB credentials 자동 발견 | coroot-cluster-agent/main.go (entry) + metrics/ 디렉터리 (6 개 metric 패키지) |
| 3 | entry point = cmd/coroot/main.go | main.go (repo 루트) — cmd/ 디렉터리 없음, const Edition = "Community" | coroot/main.go:36 |
| 4 | AppToAppConnection 정의 = model/dependency_map.go | model/connection.go:49 — dependency_map.go 는 UI 직렬화용 별개 | coroot/model/connection.go:49 |
가장 크게 달랐던 한 곳 = #2 — cluster-agent.
"informer 전용" 가설이 DB credentials 자동 발견 · AWS / ksm 통합 · Prom 자체 스크래퍼 · K8s Events → OTLP logs 변환 까지 네 가지 추가 책임으로 확장됐습니다. 코드 reading 의 첫 인상이 제품의 실제 운영 가치와 가장 어긋난 자리. (§4.4 표는 informer · DB scraper 까지 포함한 총 6 행.)
이 가설 정정이 본 글 메시지와 가장 직결됩니다. "3 컴포넌트의 책임 분담"이 과장이 아니라 실제로 더 정교한 분담이라는 사실을 코드가 보여 줍니다.
13. FAQ
Q1. 왜 Coroot 는 컴포넌트를 셋으로 나눴나?
→ 관측면이 다르기 때문. node-agent 는 커널 시야 (eBPF / cgroup / /proc), cluster-agent 는 K8s API 시야 (informer / Service / Event / DB credentials), 본체는 집계·룰·UI·MCP 시야. 셋이 같은 데이터를 다른 각도로 봅니다 — 상하 위계가 아니라 관측면 차이. (§1.2)
Q2. 왜 OTLP 와 Prometheus Remote Write 를 둘 다 쓰나?
→ 시그널 종류가 다르기 때문. metric 은 집계된 시계열이라 고밀도 푸시 (Remote Write) 가 효율적이고, trace · log · profile 은 원시 이벤트 스트림이라 batch + 라벨 풍부한 wire format (OTLP) 이 적합합니다. 한 프로토콜로 통일하려는 시도 (OTLP metrics 등) 도 있지만, 운영 현장은 둘을 병행 하는 게 표준입니다. (§5)
Q3. eBPF 만 있으면 OpenTelemetry SDK 는 불필요한가?
→ 아니오 — 상호 보완 관계. eBPF 는 L3 / L4 + 일부 L7 protocol 까지를 무계측으로 보지만, 비즈니스 인과 (correlation ID) — “이 요청은 사용자 A 의 주문 때문이다” — 는 애플리케이션이 명시적으로 trace context 를 전파해야 잡힙니다. eBPF 는 좋은 1차 신호, OTel 은 의미 보강. (§2 끝 가드레일 박스, §11.2 (1))
Q4. 왜 status propagation 은 4 카테고리만 타나?
→ auditor/auditor.go:84-89 의 결정론적 매핑 규칙 때문. Service Map 의 노드 색은 사용자 영향도가 직접 보이는 Postgres · Redis · Instances · SLO 4 종만 받습니다. 나머지 15 종 (CPU · Memory · Network · Deployments 등) 은 해당 위젯에는 표시되지만 노드 색에는 반영되지 않습니다 — “AI 가 종합 판단” 한 줄로 가려지기 쉬운 코드 차원의 룰. (§9.8)
Q5. MCP 서버는 RCA 엔진인가, 질의 창구인가?
→ 질의 창구. coroot/api/mcp.go 의 17 도구는 Coroot 가 이미 계산한 데이터 (inspector 의 Check, traces, logs, metrics) 를 외부 LLM 에이전트가 표준 프로토콜로 조회하는 인터페이스입니다. RCA 자체를 LLM 이 하지 않고, 외부 에이전트가 Coroot 의 결정론적 결과를 도구로 가져가 조사 순서 추천을 사람과 함께 합니다 — 5주차 §11 메시지의 코드 차원 발현. (§10.4)
14. 참고자료
14.1 1차 자료 (코드 + 공식)
| 자료 | 링크 |
|---|---|
coroot/coroot repo (본 글 commit lock) | https://github.com/coroot/coroot/tree/bb13d53 |
coroot/coroot-cluster-agent (commit lock) | https://github.com/coroot/coroot-cluster-agent/tree/2c7bef0 |
coroot/coroot-node-agent (commit lock) | https://github.com/coroot/coroot-node-agent/tree/d9b5c26 |
| Coroot docs · Architecture | https://docs.coroot.com/installation/architecture/ |
| Coroot docs · AI Overview (LLM 분업 명시) | https://docs.coroot.com/ai/overview/ |
| Coroot docs · ClickHouse Schema | https://docs.coroot.com/configuration/clickhouse/ |
| OpenTelemetry · OTLP 사양 | https://opentelemetry.io/docs/specs/otel/ |
| OpenTelemetry · Semantic Conventions | https://opentelemetry.io/docs/specs/semconv/ |
| Prometheus · Remote Write 사양 | https://prometheus.io/docs/concepts/remote_write_spec/ |
| ClickHouse · MergeTree 가이드 | https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree |
14.2 2차 자료 (배경 지식)
| 자료 | 분야 |
|---|---|
| ebpf.io · “What is eBPF?” | eBPF 입문 |
| Brendan Gregg · BPF Performance Tools | eBPF 심화 |
| Liz Rice · Learning eBPF | eBPF 핸즈온 |
| client-go · SharedInformer 패턴 docs | K8s informer |
| Google SRE Workbook · “Alerting on SLOs” | SLO burn rate |
| Anthropic · Model Context Protocol | MCP 표준 |
| Linux Foundation · Agentic AI Foundation (AAIF, 2025-12-09) | MCP 거버넌스 |
14.3 4 · 5주차 글과의 연결
| 이전 § | 6주차 재참조 |
|---|---|
| 4주차 § Service Dependency Graph (SDG) | §8 (AppToAppConnection 의 모델 닻) |
| 4주차 § eBPF 의 L7 / TLS trade-off | §2 끝의 가드레일 박스, §11.2 (1) |
| 4주차 § stale topology | §8.4 (Service Map 정확도 = node + cluster 곱) |
| 4주차 § MCP 표준 / AAIF | §10.4 ~ §10.5 |
| 5주차 §1.1 “RCA = probable cause + confidence” | §1, §9, §12 |
| 5주차 §7 “결정적 단서 = 변경 시점 × 변경 내용 × 직접 증거” | §12.2 |
| 5주차 §11 “RCA 는 자동화가 아니라 조사 순서 추천” | §10 (AI 3 자리), §12 전체 |
14.4 코드 인용 출처 (commit-locked permalink)
본 글 본문에 인용된 코드 위치를 한 자리에 정리. 모두 commit-locked permalink (변경 없는 영구 링크).
coroot/api/mcp.gocoroot/cloud/rca.gocoroot/model/check.gocoroot/auditor/auditor.gocoroot/model/connection.gocoroot/model/application.gocoroot/main.gocoroot/collector/metrics.gocoroot/collector/coroot-cluster-agent/k8s/event.gocoroot-cluster-agent/k8s/k8s.gocoroot-node-agent/manifests/coroot-node-agent.yamlcoroot-node-agent/main.gocoroot-node-agent/ebpftracer/tracer.gocoroot-node-agent/ebpftracer/ebpf/tcp/state.c
