
AIOps 시리즈 (8주차).
"telemetry를 받는 수집기"로 흔히 소개되는 오픈소스 OpenObserve를, 이번엔 실제 Rust 코드와 공식 문서로 직접 정독한다.
분석 대상은 릴리스 태그
v0.90.3(커밋ebe26d7c810ea05ada6d14c611b6131ac3ad620b)으로 고정했다.본문의 모든
file:line은 이 태그 기준이며, 핵심 인용 permalink는 글 끝 §6 참고 자료에 둔다.
0. 배경 — 왜 OpenObserve를 코드로 정독했나
OpenObserve를 처음 봤을 때 머릿속 분류는 단순했습니다. "Elasticsearch 대체재, 로그 수집기 하나 더." 그런데 도입을 검토하다 소스를 열어보니 그 분류가 절반밖에 안 맞더군요. 로그 한 줄이 내부에서 생각보다 훨씬 많은 것으로 갈라지고 있었습니다.
그래서 이 글은 질문 하나에서 출발합니다. observability 플랫폼은 로그 한 줄을 받아 내부에서 무엇으로 바꾸는가?
OpenObserve(이하 O2)에서 그 한 줄은 parquet 파일이자 인버티드 인덱스이고, 실시간 알림의 입력이면서, 자기 자신을 다시 관측하는 usage 레코드이기도 합니다. 정규화 → parquet/index → 메타데이터 스트림 → 검색·알림·AIOps 신호로 계속 불어나죠. 저는 이걸 telemetry의 "증식"이라 부르기로 했고, 이 글 전체가 그 한 단어를 따라갑니다.
읽는 방식은 두 축입니다. 하나는 데이터가 수집→저장→검색으로 흐르는 경로(워크플로우 축), 다른 하나는 그 과정에서 어떤 필드가 언제 붙고 늘어나는지(수집 데이터 축)입니다.
1. 소개 — OpenObserve, 그리고 이 글을 읽는 법
- 출처를 셋으로 구분합니다. 코드는
file:line, 공식 문서는 (docs), 벤더 벤치마크는 (벤더 주장)으로 표기해 추측을 사실처럼 적지 않습니다. - 기능마다 edition을 밝힙니다. 예를 들어 알림의 dedup/grouping/incident는 전부 Enterprise이고, 핵심 알고리즘은 비공개 크레이트
o2_enterprise뒤에 있어 코드로는 끝까지 볼 수 없습니다. 그런 곳은 "확인된 것"과 "못 본 것"을 그때그때 갈라 적었습니다.
순서는 배경 → 소개 → 전체 흐름 조감 → 생애주기 6단계(이 글의 본론) → Coroot 비교 → 요약 → 참고 자료입니다. 코드가 버겁다면 각 코드 앞 한 줄 설명과 절 끝의 "증식" 정리만 따라와도 큰 줄기는 잡힙니다.
이 글의 대상 독자와 용어.
observability 플랫폼을 도입·검토하는 엔지니어, 그리고 Rust 데이터 시스템의 내부가 궁금한 독자를 위한 글입니다.
SQL·parquet·기본 telemetry 개념은 안다고 가정합니다. 운영 매뉴얼이 아니라 코드 구조 분석글입니다.
자주 쓰는 용어는 먼저 한 줄씩 정리해 둡니다.
- WAL — write-ahead log. 메모리에 반영하기 전 디스크에 먼저 남기는 쓰기 로그.
- memtable — 메모리 안에 쌓는 누적 버퍼.
- Puffin — Iceberg가 정의한 인덱스/통계 blob 포맷.
- tantivy — Rust 풀텍스트 검색 엔진(Lucene 류).
- VRL — Vector Remap Language. 로그 변환 DSL.
- RCF — Random Cut Forest. 스트리밍 이상탐지 알고리즘.
2. 상세 흐름 — 전체 데이터 흐름과 노드 구조
2-1. 한눈에 보는 전체 데이터 흐름
큰 그림부터 펼치겠습니다. 아래 다이어그램은 raw telemetry가 들어와 parquet/index가 되고, 메타데이터 스트림으로 불어나고, 다시 검색·알림·AIOps 신호로 파생되는 end-to-end 경로입니다. §3의 각 절은 이 그림의 한 구간을 확대한 것이라고 보면 됩니다.
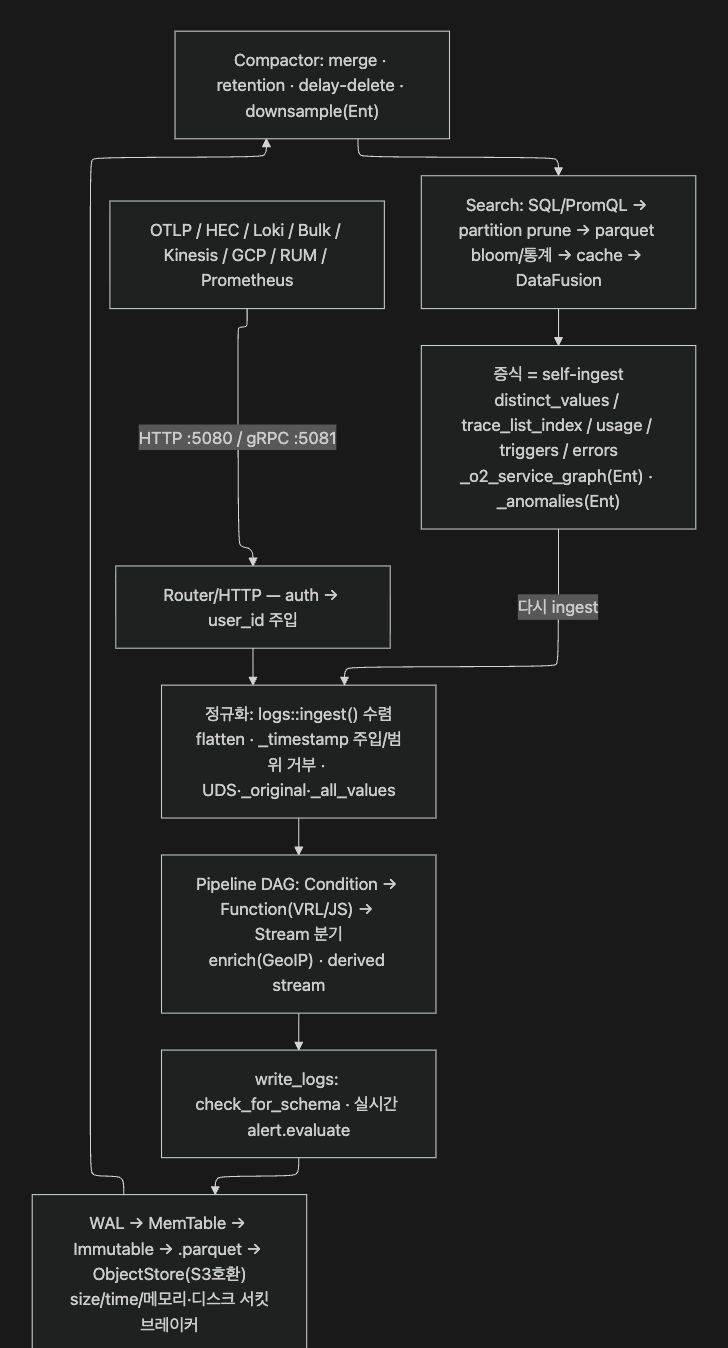
여기서 눈여겨볼 건 맨 마지막 화살표 하나입니다. 출력이 다시 입력으로 되돌아가는 self-ingest 루프 — 이게 제목에 박아 둔 "증식"의 실체입니다.
골격인 WAL→memtable→immutable→parquet→object store는 §2-2와 §3-3의 코드에서 그대로 확인되고(handler/http/router/mod.rs, job/mod.rs 계열), §6 permalink로 직접 열어볼 수 있습니다. 공식 문서도 같은 경로를 "ingestion pipeline"이라 부릅니다(docs).
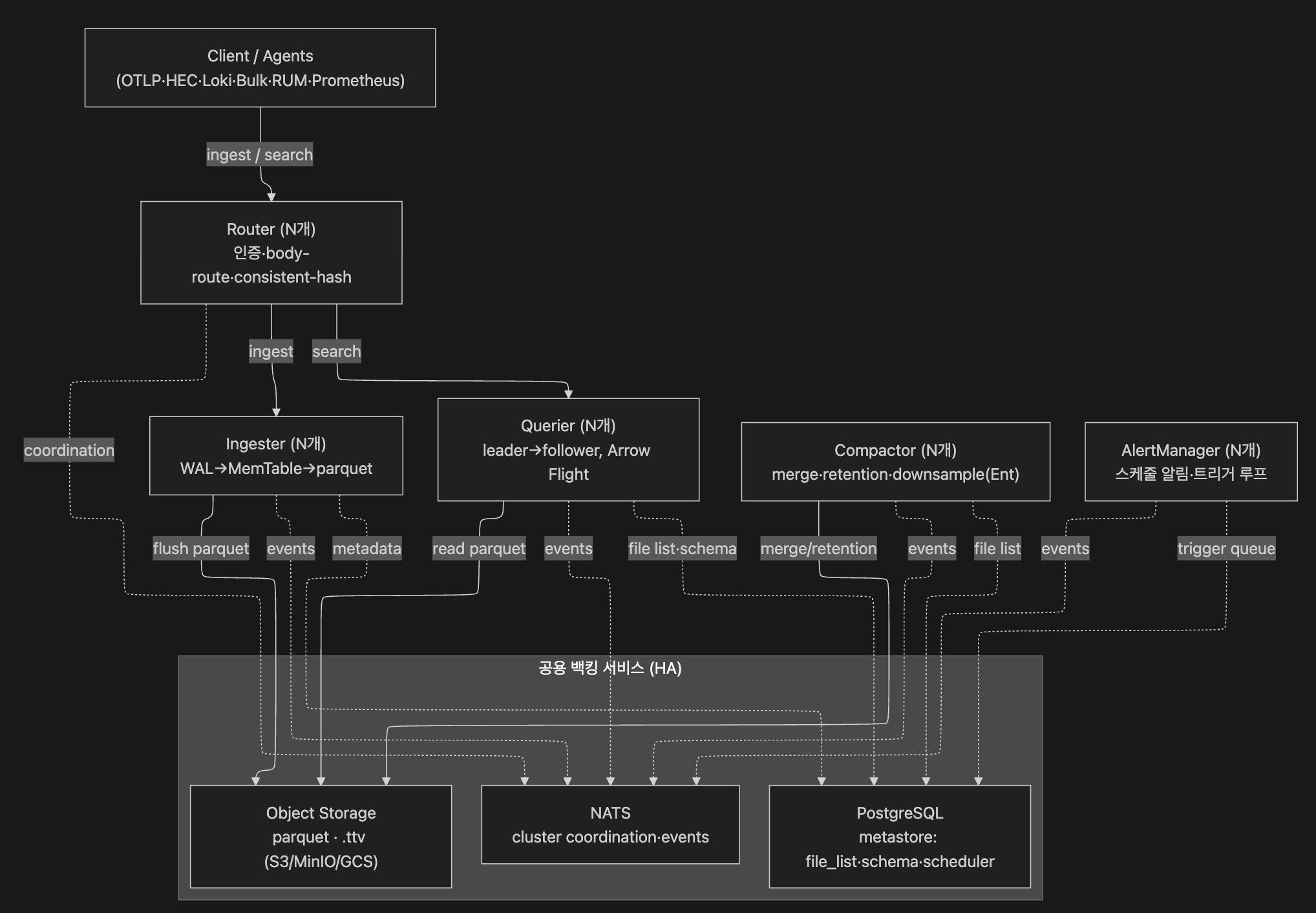
2-2. 부팅·라우팅과 백그라운드 Job 레이어
§1에서 말한 대로, O2는 한 바이너리가 노드 역할에 따라 router·ingester·querier·compactor·alertmanager로 다르게 뜨는 구조입니다. main()의 부팅 순서는 cluster 등록 → config 초기화 → DB migration → infra 초기화 → ingester 초기화 → job::init()이고요(src/main.rs:251,256,262,268,286,292; docs — Architecture).
HA 모드에서는 이 다섯 역할이 분산 배치되고 공용 백킹 서비스를 공유합니다. 아래 토폴로지는 v0.90.3 기준으로 재구성한 건데, 노드·역할 정의는 공식 문서를 따랐고 세부 동작은 각 절의 코드로 따로 검증했습니다.
| 항목 | 값 | 출처 |
|---|---|---|
| memtable flush (메모리/디스크) | 256MB / 128MB | (docs) — §3-3에서 코드로 트리거 확인 |
| object store 파일 목표 크기 | 256MB | (docs) |
| querier 메모리 캐시 | 기본 50% | (docs) |
| HA 메타스토어 / 코디네이션 | PostgreSQL / NATS | (docs) — 단일노드는 SQLite |
공식 아키텍처 페이지는 정적 이미지(JPG/WebP/SVG) 중심입니다.
본문은 버전 고정·검증이 쉬운 텍스트(mermaid)로 재구성했습니다.
원전은 OpenObserve Docs — Architecture 참조(docs 티어). 수집·쿼리의 시퀀스 흐름은 공식 시퀀스 다이어그램이 잘 정리해 두었습니다.
라우터는 요청을 어디서 처리할지 정합니다. 노드가 router면 프록시 라우트를, 아니면 직접 서비스 라우트를 달고, 인증 미들웨어가 자격을 검증한 뒤 user_id 헤더를 주입하죠(handler/http/router/mod.rs:1060, :1086-1091, 프로토콜별 검증기 aws/gcp/rum_auth_middleware:201/223/245). 권한(FGA/RBAC)과 rate-limit 미들웨어는 #[cfg(feature="enterprise")]라, 사실상 여기서부터 Enterprise 경계가 시작됩니다.
정작 흥미로운 건 부팅 때 함께 뜨는 백그라운드 워커 레이어입니다. src/job/은 파일 기준 21개 모듈이고, 실제 spawn되는 워커 수는 feature/role 조합에 따라 더 늘어납니다. 한 가지만 기억해 두면 좋은데, 알림의 정의는 service/alerts/*에 있고 실제 실행 루프는 job/alert_manager.rs에 있다는 분업입니다.
| job 워커 | 역할 | edition |
|---|---|---|
files::run / stats::run | parquet 수집·이동 / stream 통계 | OSS |
compactor::run | merge·retention·delay-delete 스케줄 | OSS |
flatten_compactor::run | flatten 컬럼 parquet 생성 | OSS |
file_downloader::run | 노드 간 parquet 다운로드 | OSS |
alert_manager::run | 스케줄 알림 평가 루프(→§3-6) | OSS |
mmdb_downloader::run | MaxMind GeoIP DB 다운로드 | OSS |
self_reporting::run | usage/trigger 재수집(→§3-6) | OSS |
alert_grouping / incidents | 만료 배치 발송 / 인시던트 처리 | Enterprise |
service_graph::run | traces→서비스 그래프 파생 | Enterprise |
| cloud jobs (billing/quota) | 과금·트라이얼 쿼터 | Cloud |
근거: src/job/mod.rs, src/job/{alert_manager,compactor,service_graph}.rs
참고: 대부분 워커는 if !LOCAL_NODE.is_alert_manager() { return } 같은 역할 가드로 한 노드에서만 돕니다(예: job/alert_manager.rs:23).
3. 코드로 읽는 telemetry 생애주기
이제 본론입니다. 로그 한 줄이 수집 → 변환 → 저장 → 검색 → 인덱싱 → AIOps 신호로 "증식"하는 여섯 단계를, 각 단계의 핵심 코드와 함께 따라가 보겠습니다. 코드가 버거우면 블록 앞 한 줄 설명과 절 끝의 "증식" 정리만 읽어도 흐름은 이어집니다.
3-1. 수집·정규화 — 무엇을 받고, 어떻게 공통 포맷으로 만드나
O2가 받는 입력의 폭은 꽤 넓습니다. 그런데 그 다양성은 입구에서만 흡수되고, 그 뒤로는 전부 같은 파이프라인으로 수렴합니다.
먼저 HTTP 라우트에서 직접 확인한 수집 엔드포인트입니다.
| 프로토콜/소스 | HTTP 라우트 | 핸들러 | 근거 |
|---|---|---|---|
Elasticsearch _bulk | /{org}/_bulk | logs::ingest::bulk | router/mod.rs:613 |
| NDJSON multi / JSON array | /{org}/{stream}/_multi·_json | logs::ingest::{multi,json} | router/mod.rs:614-615 |
| Splunk HEC | /{org}/_hec | logs::ingest::hec | router/mod.rs:616 |
| Grafana Loki push | /{org}/loki/api/v1/push | logs::loki::loki_push | router/mod.rs:617 |
| OTLP logs/metrics/traces | /{org}/v1/{logs,metrics,traces} | {logs,metrics,traces}::* | router/mod.rs:618-620 |
| Prometheus remote-write | /{org}/prometheus/api/v1/write | promql::remote_write | router/mod.rs:643 |
| AWS Kinesis / GCP Pub/Sub | /aws/.../_kinesis_firehose·/gcp/.../_sub | logs::ingest::handle_{kinesis,gcp}_request | router/mod.rs:1020,1032 |
| RUM logs/replay/data | /rum/v1/{org}/{logs,replay,rum} | rum::ingest::{log,sessionreplay,data} | router/mod.rs:1043-1045 |
OTLP는 gRPC(:5081)로도 받습니다.
그리고 이 모든 로그 소스는 하나의 함수로 수렴합니다.
service/logs/ingest.rs:66 ingest()
입력 종류는 IngestionRequest enum으로 분기되고, 각각 (endpoint, UsageType, IngestionData) 튜플로 정규화됩니다. 프로토콜 차이는 입구에서 사라지고, 이후는 동일 파이프라인입니다.
근거: ingest.rs:142-188
공식 문서: docs — Ingestion
정규화의 1급 단계는 _timestamp 처리입니다.
이것은 단순한 필드 주입이 아니라 첫 번째 가드레일입니다.
쉽게 말하면 아래 함수는 입구의 '시간표 검사원'입니다. 로그에 시각이 없으면 받은 시각을 찍어 주고, 너무 과거거나 너무 미래면 입장을 거절합니다.
// src/service/logs/ingest.rs:602
pub fn handle_timestamp(value: &mut json::Value, min_ts: i64, max_ts: i64) -> Result<i64, anyhow::Error> {
let local_val = value.as_object_mut().ok_or_else(|| anyhow::Error::msg("Value is not an object"))?;
let (timestamp, has_valid_timestamp) = match local_val.get(TIMESTAMP_COL_NAME) {
Some(v) if !v.is_null() => parse_timestamp_micro_from_value(v)?, // 파싱 실패 시 거부
_ => (Utc::now().timestamp_micros(), false), // _timestamp 없으면 수집시각(micros) 주입
};
if timestamp < min_ts { return Err(get_upto_discard_error()); } // 과거 거부
if timestamp > max_ts { return Err(get_future_discard_error()); } // 미래 거부
if !has_valid_timestamp {
local_val.insert(TIMESTAMP_COL_NAME.to_string(), json::Value::Number(timestamp.into()));
}
Ok(timestamp)
}service/logs/ingest.rs:602-637
세 가지 사실이 코드로 확정됩니다.
- ①
_timestamp가 없거나 null이면 수집 시각(마이크로초) 을 주입합니다. 그래서 모든 스트림이_timestamp(i64 micros)를 1급 컬럼으로 갖습니다. - ②
min_ts = now - ingest_allowed_upto_micro,max_ts = now + ingest_allowed_in_future_micro범위 밖 데이터는 폐기됩니다. 에러 메시지는ZO_INGEST_ALLOWED_UPTO/ZO_INGEST_ALLOWED_IN_FUTURE환경변수를 안내합니다. - ③ OTLP/metrics/traces는 프로토콜별 진입점에서 각자 ts를 만든 뒤 공통 경로로 합류합니다. 즉 "프로토콜별 처리"와 "공통 funnel"은 충돌이 아니라 상보 관계입니다.
근거: ingest.rs:98-99, schema.rs:57-69, logs/otlp.rs:142-143, traces/mod.rs:462
공식 문서도 _timestamp injection, field limit을 명시합니다 (docs).
정규화된 레코드는 write_logs()로 들어가 스키마 확인·실시간 알림 평가·distinct 추출·WAL 쓰기를 한 루프에서 처리합니다. 데이터 한 줄이 여러 신호로 갈라지는 첫 갈림목이죠. 이때 _original/_record_id(원본 보존), _all_values(FTS용), schema_key(저장 분기), partition_key가 차례로 붙습니다(logs/mod.rs:302,377, ingest.rs:287-296,322, ingestion/mod.rs:364).
→ 증식 1단계.
한 줄의 raw 로그가
_timestamp·_original·_all_values·schema_key·partition_key를 단 정규화 레코드로 갈라지기 시작합니다.근거:
ingest.rs:602,logs/mod.rs:302
3-2. 변환·분기 — Pipeline / VRL / Enrichment
수집 직후 데이터는 선택적으로 파이프라인 DAG를 통과합니다. 소스는 두 종류 — 수집 즉시 처리하는 Realtime과 주기 쿼리 결과를 재적재하는 Scheduled(DerivedStream)입니다. 노드는 RemoteStream·Stream·Query·Function·Condition 다섯에, trace span을 head-sampling해 LLM으로 평가하는 신규 LlmEvaluation까지 여섯 종입니다(config/.../pipeline/components.rs:35-42, :223-229, :265).
실행 엔진 ExecutablePipeline은 생성될 때 노드를 위상정렬하고 함수를 미리 컴파일합니다. 말하자면 파이프라인의 '실행 설계도'예요 — 노드 순서를 미리 정렬해 두고(sorted_nodes) 변환 함수도 컴파일해 둡니다(function_map).
// src/service/pipeline/batch_execution.rs:172
pub struct ExecutablePipeline {
id: String,
name: String,
source_node_id: String,
sorted_nodes: Vec<String>, // topological sort 결과
function_map: HashMap<String, CompiledFunctionRuntime>,
node_map: HashMap<String, ExecutableNode>,
}service/pipeline/batch_execution.rs:172
process_batch()는 노드마다 tokio task를 띄우고 mpsc 채널로 이어, 레코드를 DAG를 따라 흘려보냅니다. Condition 노드는 flatten 뒤 조건을 평가해 통과한 것만 내려보내고, Function 노드는 VRL이면 apply_vrl_fn·JS면 apply_js_fn을 적용하며 결과가 배열이면 fan-out하죠. 한 가지 못이 박혀 있는데, 파이프라인에선 JS 함수가 전 조직(_meta 포함)에서 금지되고 VRL만 허용된다는 점입니다(batch_execution.rs:288,332-392, :53,622, pipeline/mod.rs:38-57).
Enrichment는 필드가 늘어나는 자리입니다. VRL을 컴파일할 때 vector_enrichment::TableRegistry를 런타임 config에서 꺼내 finish_load()하므로, enrichment-table lookup이 VRL 함수 안에서 동작합니다. GeoIP가 대표적인데, MaxMind DB로 city/country/timezone/위경도를 채우고 그 DB는 부팅 때 mmdb_downloader job이 받아 둡니다(batch_execution.rs:152-154, enrichment_table/geoip.rs).

마지막으로 Scheduled(DerivedStream)은 검색 결과를 다시 ingest하는 브리지인데, 여기에도 가드레일이 있습니다 — 저장하려는 SQL이 _timestamp를 select하지 않으면 거부합니다.
// src/service/alerts/derived_streams.rs:52
if !is_timestamp_selected(sql).map_err(|e| anyhow::anyhow!("Invalid SQL: {}", e))? {
// "SQL for scheduled pipeline must include _timestamp, or aliased as _timestamp."
}service/alerts/derived_streams.rs:34 save(), 가드 :52
이 derived stream이 알림 스케줄러와 같은 인프라(TriggerModule)를 공유한다는 점은 §3-6의 복선으로 남겨 둡니다. 공식 문서도 scheduled pipeline의 Query 노드가 SQL/PromQL을 주기 실행해 derived stream으로 재적재하며 _timestamp는 VRL로 보존한다고 설명합니다. 참고로 이 파이프라인·VRL·enrichment는 전부 OSS입니다.
→ 증식 2단계.
변환·enrichment 단계에서 telemetry는 GeoIP 같은 파생 필드가 더해지고, derived stream으로 분기·재적재됩니다.
한 줄이 여러 갈래로 늘어나는 지점입니다.
근거:
batch_execution.rs:152-154,derived_streams.rs:52
3-3. 저장과 스키마, 그리고 저장 이후의 삶
저장 경로는 이 글에서 코드로 가장 또렷하게 짚이는 흐름입니다 — WAL → memtable → immutable → .par→.parquet rename → object store. write_logs가 만든 ingester::Entry에서 출발해, Writer가 WAL 바이트와 Arrow batch를 큐에 넣고 WAL을 먼저 쓴 뒤 memtable에 반영합니다. memtable이 임계를 넘으면 rotate되어 IMMUTABLES로 넘어가고, immutable persist는 memtable dump → .lock 생성 → WAL 삭제 → .par→.parquet rename → lock 삭제 순서를 정확히 지킵니다(ingester/writer.rs:389, :551, immutable.rs:92-127).
이 순서가 곧 crash recovery의 토대입니다. WAL을 먼저 남기고 persist가 끝난 뒤에야 지우니까, persist 도중 죽어도 WAL이 남아 재기동 때 replay되고 rename까지 끝난 .parquet만 object store로 올라갑니다 — 기본값이 "유실 없이 재처리"인 셈이죠. (다만 노드 다운 시 리밸런싱 같은 HA 장애 전이는 코드가 한곳에 모여 있지 않아 "구현상 불명확"으로 비워 둡니다.)
| 단계 | 트리거 / 조건 | 산출 | 근거 |
|---|---|---|---|
| WAL write | wal_write_queue_size bounded 큐 | .wal(magic OPENOBSERVEV2/V3) | wal/lib.rs:31-32, writer.rs:310,389 |
| MemTable | org/stream 단위 Arrow batch | 메모리 누적 | ingester/memtable.rs:38,62 |
| rotate→Immutable | WAL 크기·age·memtable 크기 | immutable 전환 | writer.rs:551,666-681 |
| parquet | immutable persist | min_ts.max_ts.<rnd>_<id>.parquet | config/.../parquet.rs:301 |
| object store | compactor file push(10s 주기) | S3호환/멀티account | infra/storage/mod.rs:155 |
이 표에서 볼 것은 하나입니다. O2는 쓰기 안정성을 WAL에 맡기고, 검색 효율을 parquet 파일명과 메타데이터에 남깁니다.
parquet 파일명에는 min_ts.max_ts 시간 범위가 박혀 있는데(parquet.rs:301 generate_filename_with_time_range), 이게 나중에 검색 프루닝의 토대가 됩니다. 임계·주기 기본값은 공식 문서가 채워 줍니다 — rotate는 ZO_MAX_FILE_SIZE_IN_MEMORY=256MB/ON_DISK=128MB, dump는 ZO_MEM_PERSIST_INTERVAL=5s, push는 ZO_FILE_PUSH_INTERVAL=10s고요. 한 가지 덧붙이면 "S3"는 표기일 뿐 실제 provider는 AWS/GCP/Azure이며 org별 account 매핑(멀티 account)을 둡니다(infra/storage/mod.rs:48-176; ZO_S3_ACCOUNTS·BYOB).
백프레셔는 4종으로 확정됩니다.
- memtable 총량 초과:
mem_table_max_size,:72 - 메모리 서킷브레이커:
check_memory_circuit_breaker,:80-88 - 디스크 서킷브레이커:
check_disk_circuit_breaker,:100-116 - write-queue full reject:
wal_write_queue_full_reject,:413
근거: ingester/writer.rs
스키마는 쓰기 시점 확정(schema-on-write)이 기본이고 일부만 읽기 때 캐스팅합니다. write path는 저장 전 check_for_schema로 최신 스키마와 hash를 정하고 변화가 없으면 fast-path로 바로 반환하며, 병합은 get_merge_schema_changes가 맡습니다 — 신규 필드는 추가, 타입 충돌은 widening이면 교체하고 narrowing이면 메타로 표시해 쿼리 때 캐스팅하죠. 이 모든 정책을 담는 1급 개념이 StreamSettings인데, 스트림마다 '이 데이터를 어떻게 쪼개 저장하고 무엇을 색인할지'를 정하는 설정 묶음입니다.
근거: service/schema.rs:81-110, infra/src/schema/mod.rs:688
// src/config/src/meta/stream.rs:922
pub struct StreamSettings {
pub partition_keys: Vec<StreamPartition>, // 파티셔닝(Value/Hash(n)/Prefix)
pub full_text_search_keys: Vec<String>, // FTS 대상
pub index_fields: Vec<String>, // secondary index 대상
pub bloom_filter_fields: Vec<String>, // parquet bloom filter 대상 컬럼
pub data_retention: i64, // 보존(일)
pub flatten_level: Option<i64>,
pub defined_schema_fields: Vec<String>, // UDS
pub store_original_data: bool, // _original 저장
pub index_all_values: bool, ... // _all_values
}config/src/meta/stream.rs:922-963
공식 문서는 data_retention 최소·글로벌 기본일, FTS 인덱스 저장 오버헤드, distinct values flush 주기를 보강합니다.
공식 문서: docs — Streams/StreamSettings
저장 이후의 삶 — Compaction·Merge·Retention·Downsampling. 저장된 데이터는 가만히 있지 않습니다. compactor 노드가 current/historical merge job 생성, merge 실행, retention, delay deletion, offset sync 같은 주기 작업으로 라이프사이클을 계속 돌립니다(job/compactor.rs).
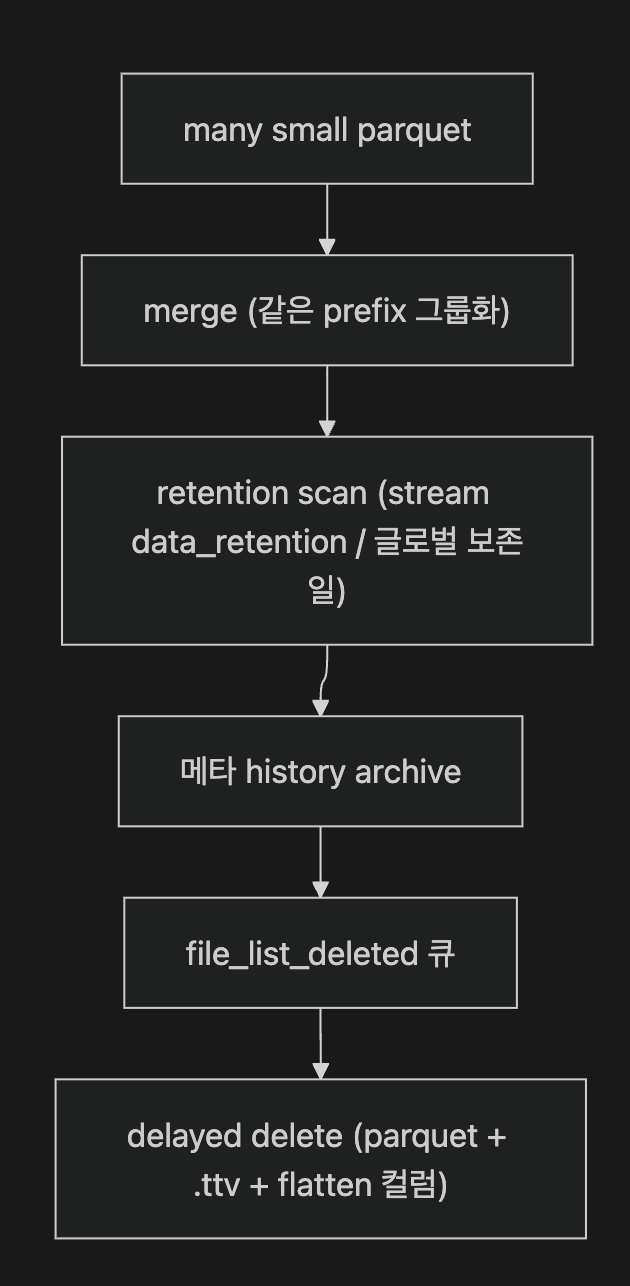
| 작업 | 핵심 함수 | 동작 | edition |
|---|---|---|---|
| small-file merge | compact/merge.rs:395 merge_by_stream, :656 merge_files | 같은 파티션 prefix 파일을 큰 parquet로 병합 | OSS |
| retention 삭제 | compact/retention.rs:227 generate_retention_job, :398 delete_by_date | stream별 data_retention이 글로벌 값 덮어씀 | OSS |
| delay deletion | compact/deleted.rs:25 delete() | 지연 큐(file_list_deleted) 배치로 실제 스토리지 삭제 | OSS |
| downsampling | compact/merge.rs:278(rule gate :50-51) | 메트릭 전용, day-level 지연 | Enterprise |
이 표에서 중요한 경계는 downsampling입니다. merge·retention·delay deletion은 OSS이고, downsampling은 Enterprise입니다.
merge할 때 parquet writer는 bloom_filter_fields 컬럼에 parquet 내장 row-group bloom filter를 켜서 씁니다. 그러니까 O2의 bloom은 따로 .bf 파일이 아니라 parquet 포맷 안에 들어 있는 컬럼 bloom filter이고, 검색 때 DataFusion이 이걸 읽어 row-group을 통째로 건너뜁니다(compact/merge.rs:753,849, config/.../parquet.rs:92-101).
retention은 "삭제 표시 → 지연 삭제" 2단계입니다. 메타(schema 버전·file_list 엔트리)를 history로 archive해 두고 실제 삭제는 지연 큐로 미루는데, 이게 §6의 거부·스킵 규칙으로 이어집니다. 예를 들어 compliance storage_type은 retention 최소 30일을 강제하고 업로드 때 put_with_compliance를 고릅니다(service/stream.rs:613-616,874-885, compact/merge.rs:914-915,960-961).
downsampling만은 Enterprise 전용이고 메트릭에만 적용됩니다. OSS 레포에서는 룰 게이트와 호출 지점, "메트릭 전용·day-level 지연"까지만 보이고 집계 알고리즘 자체는 o2_enterprise::enterprise::common::downsampling에 숨어 있어 구현상 불명확입니다(merge.rs:50-51, :278; docs — Downsampling).
→ 증식 3단계.
저장 단계에서 한 레코드는 parquet 파일 + 시간 범위 인코딩 파일명 + 컬럼 bloom filter로 물질화됩니다.
이후 merge·retention을 거치며 검색이 스킵·프루닝할 수 있는 형태로 정리됩니다.
근거:
parquet.rs:301,compact/merge.rs:753
3-4. 검색 — SQL·PromQL, 분산검색과 Arrow Flight
검색 경로는 한 줄로 줄일 수 있습니다 — SQL 파싱 → 플랜 → 파티션 프루닝 → parquet 통계/bloom → 캐시 → DataFusion 실행.
파싱 단계에서 HTTP search가 Sql::new_from_req로 쿼리를 파싱·리라이트하고(dialect는 PostgreSQL), Sql 객체가 stream 이름·equality 항목·time range·histogram interval을 담습니다(search/mod.rs:129, :200, sql/mod.rs:68,73,75,82,85). 다음 파티션 프루닝에서는 histogram query면 aligned partition, 복잡한 query면 mini-partition으로 쪼개고, 그 위에서 parquet bloom filter 프루닝이 equality 조건의 row-group을 건너뜁니다(DataFusion 세션이 parquet.bloom_filter_on_read를 켜는 식; bloom_filter_enabled/bloom_filter_disabled_on_search로 on/off, partition.rs:56,153, datafusion/exec.rs:96-102). 마지막 결과 캐시는 from=0일 때만 동작하는데, cached delta를 계산해 모자란 부분만 병렬로 조회합니다(search/cache/mod.rs:75 CACHE_VERSION="v3", :94).
멀티노드 검색은 router의 consistent-hash + leader querier + Arrow Flight 분산 구조입니다.
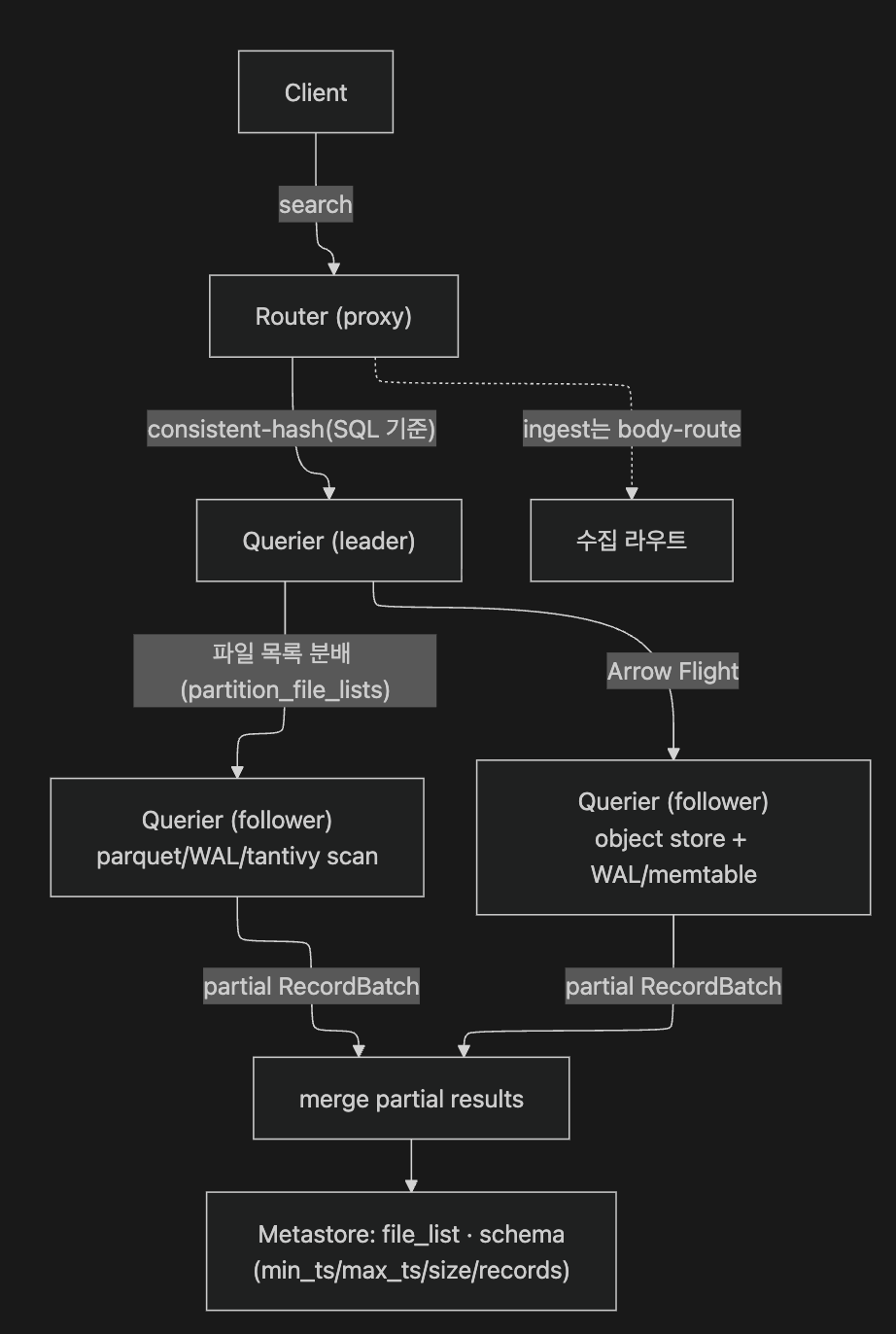
- Router: search는 SQL을 라우팅 키로 consistent-hash해 querier/ingester가 분담합니다(
router/http/mod.rs). - Flight leader: online querier를 고르고 work-group/admission control을 거쳐 파일 목록을 분배합니다(
search/cluster/flight.rs:84 search,:164online querier,:213work-group lock). - Flight follower: 직렬화된 physical plan을 받아 object storage·WAL memtable·WAL parquet scan으로 실행합니다(
search/grpc/flight.rs:77,101).
아래는 검색 엔진(DataFusion) 세션을 띄울 때 거는 옵션들이에요 — PostgreSQL 문법, pushdown 필터, 그리고 parquet bloom filter 읽기 스위치를 켜는 자리입니다.
// src/service/search/datafusion/exec.rs:69
pub fn create_session_config(sorted_by_time: bool, target_partitions: usize) -> Result<SessionConfig> {
// … (target_partitions 보정 생략, exec.rs:74-79)
let mut config = SessionConfig::from_env()?
.with_batch_size(get_batch_size())
.with_target_partitions(target_partitions)
.with_information_schema(true);
config.options_mut().sql_parser.dialect = Dialect::PostgreSQL; // SQL은 PostgreSQL dialect (exec.rs:90)
config.options_mut().execution.parquet.pushdown_filters = ...; // pushdown filter (exec.rs:92)
if cfg.common.bloom_filter_enabled { // parquet bloom filter read (exec.rs:96-98)
config.options_mut().execution.parquet.bloom_filter_on_read = true;
}
}service/search/datafusion/exec.rs:69-110
여기서 edition 경계가 둘 갈립니다. super_cluster(멀티 리전) 분산검색은 전부 #[cfg(feature="enterprise")]이고, 비동기 search job 워커도 Enterprise입니다 — search_jobs 테이블의 오래된 job을 잡아 partition별 gRPC search → 결과 저장 → merge를 돌리는데, alert-manager job이 enterprise feature로 주기 실행하죠(search/super_cluster/{leader,follower}.rs, search_jobs.rs:52, job/alert_manager.rs:71-83). 반대로 DataFusion 기반 SQL/PromQL·parquet bloom·tantivy·result cache는 전부 OSS입니다(docs — Federated Search). 참고로 자주 인용되는 "inverted index ~1000× 가속" 같은 수치는 공식 문서가 아니라 벤더 블로그 출처라 (벤더 주장)으로만 둡니다.
→ 증식 4단계.
검색 단계에서 telemetry는 partition·bloom·캐시·인덱스를 거치며 부분 RecordBatch들로 갈라졌다가 다시 병합됩니다.
한 줄의 로그가 분산 쿼리 결과로 재구성되는 지점입니다.
근거:
search/cluster/flight.rs:84
3-5. 인덱싱 — tantivy·Puffin 디렉터리·Secondary index
O2의 인덱싱은 무엇을 색인하는가와 어떤 파일 포맷으로 패키징하는가 두 질문으로 나뉩니다.
이 표에서 볼 것은 두 가지입니다. full-text는 별도 .ttv 인덱스를 만들고, secondary index는 parquet 컬럼과 Flight 필터 경로를 활용합니다.
| 인덱스 종류 | 대상(StreamSettings) | 저장 포맷·파일 | 근거 |
|---|---|---|---|
| full-text / inverted | full_text_search_keys | tantivy → Puffin 디렉터리 → .ttv | tantivy/mod.rs:77-211 |
| secondary index | index_fields | parquet 컬럼 + Flight 필터 | search/grpc/flight.rs:77-101 |
(참고: bloom_filter_fields는 별도 인덱스 파일을 만들지 않고 §3-3·§3-4에서 본 대로 parquet 컬럼 자체의 row-group bloom filter로만 쓰입니다.)
인버티드 인덱스는 tantivy를 Puffin 디렉터리(Iceberg 호환)로 패키징해 .ttv로 업로드하는 방식입니다. Puffin 디렉터리에는 .term/.idx/.pos/.fast와 meta.json만 들어 있고, reader는 Puffin blob 메타에서 파일 핸들을 복원합니다. parquet 경로 files/{org}/{type}/{stream}/...는 인덱스에서 files/{org}/index/{stream}_{type}/...ttv로 바뀌며, FTS 필드는 raw tokenizer를·_timestamp는 항상 i64 FAST 필드를 씁니다(puffin_directory/mod.rs:37,39, reader.rs:39-58, inverted_index.rs:23-25, tantivy/mod.rs:196,207).
아래는 tantivy 인덱스를 만들어 Puffin 디렉터리로 포장하는 입구입니다.
// src/service/tantivy/mod.rs:77
pub(crate) async fn create_tantivy_index(...) -> Result<...> {
let dir = PuffinDirWriter::new(); // tantivy → Puffin (mod.rs:88)
// … fields: raw tokenizer (mod.rs:196), _timestamp = i64 FAST (mod.rs:207)
}service/tantivy/mod.rs:77-211
공식 문서가 두 가지를 더 알려 줍니다 — 응답에 idx_took>0이면 인버티드 인덱스가 쓰인 것이고, FTS는 match_all(인덱스) 대 str_match/re_match(필드) 연산자로 갈린다는 점입니다. 이 인덱싱 스택은 통째로 OSS입니다.
→ 증식 5단계.
인덱싱 단계에서 telemetry는 본문 parquet와 별개로 tantivy 인버티드 인덱스(
.ttv) + secondary index 컬럼이라는 부수 산출물로 증식합니다.원본을 읽지 않고도 검색되는 길을 만드는 단계입니다.
근거:
tantivy/mod.rs:77
3-6. AIOps로의 증식 — 이상탐지·Service Graph·Self-reporting·AI/MCP
드디어 데이터가 운영 신호로 증식하는 마지막 단계입니다. O2는 스스로 데이터를 만들어 자기 자신에게 다시 ingest하는데, 크게 두 부류입니다 — 시스템이 자동 생성하는 metadata stream·self-reporting, 그리고 Enterprise AIOps 파생 신호죠.
Google SRE Book의 한 문장을 빌립니다.
"Potential-cause alerts have poor correlation to real problems, but symptom-of-user-pain alerts better allow you to understand user impacts."
이 철학이
service/alerts/*의 구조로 어떻게 굳어졌는지를 아래에서 코드로 봅니다.
여기서 분명히 해 둘 게 있습니다. 알림의 dedup/grouping/incident 상관은 전부 Enterprise이고, 핵심 알고리즘은 비공개 크레이트 o2_enterprise에 들어 있습니다. OSS에서는 평가 후 곧장 알림을 보내고 그 통계만 아래 triggers 스트림에 남죠(service/alerts/mod.rs:48-55의 deduplication·grouping·incidents 모듈이 #[cfg(feature="enterprise")]로 게이트).
| 파생 신호 | 입력 | 산출 | edition |
|---|---|---|---|
distinct_values_* | 수집 중 누적 | _timestamp,count,<fields> 메타스트림 | OSS |
trace_list_index | trace 수집 | _timestamp,stream_name,service_name,trace_id | OSS |
usage / triggers / errors | self-reporting | 운영 관측 스트림(self-ingest) | OSS |
_o2_service_graph | traces self-join | client/server edge·요청수·error_rate·p50/95/99 | Enterprise |
_anomalies | 시계열 집계점 | anomaly_score·is_anomaly·deviation | Enterprise |
| audit | 감사 이벤트 | audit 스트림 | Enterprise |
| AI Chat / MCP | 프롬프트 / MCP 요청 | LLM 응답 / 도구 호출 | Enterprise(+Cloud 과금) |
Self-reporting(OSS)은 usage를 _meta org의 usage 스트림(StreamType::Logs)에 쓰고, 옵션에 따라 각 org 스트림에도 복제합니다. ingester 노드에서는 이걸 IngestionRequest::Usage로 내부 logs ingest 경로에 다시 밀어 넣는데, self-ingest 증식의 가장 깔끔한 예입니다. triggers 스트림 자체는 OSS이지만, 그 안의 dedup_suppressed/grouped/group_size 필드는 Enterprise dedup/grouping이 돌 때에만 값이 찹니다(self_reporting/ingestion.rs:196-197,220-260,285).
Service Graph(Enterprise)는 이 증식 루프의 정점입니다. trace ingestion은 서비스 그래프를 그 자리에서 만들지 않고, 별도 daemon이 trace를 SQL로 self-join·집계해 _o2_service_graph 스트림에 다시 적재합니다. 이 job은 alert-manager 노드에서만 돕니다(traces/mod.rs:54, service_graph/processor.rs:38, :134, :165-167, job/service_graph.rs:19-24, :20, :36).

Anomaly Detection(Enterprise)은 config를 만들 때 스케줄러에 TriggerModule::AnomalyDetection 트리거를 등록해 두고, 탐지 시점에 OSS search 서비스로 시계열을 읽어 detector를 돌린 뒤 scored points를 _anomalies 스트림에 씁니다. 코드 주석을 보면 모델은 RCF(Random Cut Forest)이고 shingle(기본 4, O2_ANOMALY_RCF_SHINGLE_SIZE)로 여러 time-bucket 문맥을 줍니다. 다만 알고리즘 본체는 o2_enterprise::enterprise::anomaly_detection::Detector 위임이라, 코드로는 _anomalies 스키마와 트리거 등록까지만 확정되고 임계 산정 같은 모델 세부는 "구현상 불명확"입니다(anomaly_detection.rs:136,390, :901, :328-329, :917, :914).
AI Chat / MCP(Enterprise, 일부 Cloud 과금)는 둘로 나뉩니다. AI Chat은 ai.enabled·agent_url을 확인해 외부 o2-sre-agent로 포워딩하고(Cloud는 여기에 AI credit 검사를 더함), MCP는 enterprise가 아니면 404, enterprise면 protocol version(MCP 2025-11-25) 검증·notification 202·JSON/SSE를 지원합니다. 공식 문서는 O2 자체가 MCP 서버(/api/{org}/mcp)라는 점을 덧붙입니다(ai/chat.rs:146,179,183,190, mcp/mod.rs:22,32-33,46-54; docs — MCP). 끝으로 service graph self-ingest가 단일노드에서 루프백하는지 분산 라우팅을 타는지는 확인하지 못해 "구현상 불명확"으로 남겨 둡니다.
→ 증식 6단계(최종).
여기서 telemetry는 자기 자신을 입력으로 되먹여 usage·
trace_list_index·_o2_service_graph·_anomalies같은 운영 신호로 증식합니다.출력이 다시 입력이 되는 self-ingest 루프가 이 글 제목 "증식"의 실체입니다.
근거:
self_reporting/ingestion.rs:196,service_graph/processor.rs:38
4.OpenObserve vs Coroot
마지막으로 같은 관측가능성 문제를 정반대 입구로 푸는 도구, Coroot를 옆에 세워 봅니다.
한쪽은 "무엇이든 받아 싸게 저장·검색하는 데이터 플랫폼"입니다. 다른 한쪽은 "eBPF로 알아서 계측하고 원인까지 짚는 APM"입니다.
표기 기준: O2 주장은 코드 file:line, Coroot 주장은 (coroot docs), 홍보 수치는 (coroot 주장)
| 축 | OpenObserve | Coroot |
|---|---|---|
| 포지셔닝 | telemetry 저장·검색 플랫폼(수집→증식) | eBPF 자동계측 APM(분석·RCA 우선) |
| 수집 | push 다중 프로토콜(OTLP/HEC/Loki/Bulk/Kinesis/GCP/RUM/Prom) | eBPF zero-instrumentation node-agent + OTLP |
| 서비스 그래프 | traces self-join 파생, Enterprise | eBPF 커넥션 추적으로 자동 생성, OSS 기본 |
| 저장 | 자체 스택: WAL→parquet→object store + tantivy/parquet-bloom | 외부 위임: Prometheus + ClickHouse |
| 상관·AIOps | dedup/grouping/incident·이상탐지, Enterprise(o2_enterprise 위임) | SLO 알림 + AI RCA, OSS 기본 |
| 라이선스 | Rust / AGPLv3(+enterprise) | Go+Vue / Apache 2.0(+enterprise) |
결국 한 도구가 다른 도구를 대체한다기보다, 선택 기준이 다릅니다.
저장·수집의 폭(O2) 이 더 중요한가, 무계측 자동 분석의 깊이(Coroot) 가 더 중요한가의 문제입니다.
5. 한 줄 요약
세 문장 요약.
① O2는 다양한 수집 프로토콜을 입구에서 흡수해 단일 funnel(
logs::ingest())로 정규화하고, WAL→memtable→parquet→object store로 저장한다.② 저장된 데이터는 compaction·검색을 거쳐, 출력이 다시 입력으로 돌아가는 self-ingest로 운영 신호(usage·service graph·anomaly)로 증식한다.
③ 이 골격은 OSS로 코드 검증되지만, dedup/incident·이상탐지/서비스그래프/연합검색/다운샘플링은 모두 Enterprise이며 핵심 알고리즘은
o2_enterprise에 위임돼 "구현상 불명확"으로 남는다.
6. 참고 자료
6-1. 종합 레퍼런스 표
① 데이터 vs 메타데이터 이원 분리. O2는 두 저장소를 명확히 가릅니다 — parquet/인덱스는 object store(S3호환/멀티account)에, 파일 목록·스키마·스케줄러 메타는 메타스토어에 둡니다.
// src/config/src/meta/meta_store.rs:20
pub enum MetaStore { Sqlite, Nats, PostgreSQL }| 구분 | 저장 대상 | 백엔드 | 근거 |
|---|---|---|---|
| 데이터 | parquet · .ttv | ObjectStore(S3/local, org별 account) | §3-3, infra/storage |
| 메타데이터 | file_list(min/max ts·records·size) · schema 버전 · scheduler/search_jobs 트리거 큐 | sqlite(단일)/postgres(HA)/nats | service/db/{file_list,schema,scheduler}.rs |
공식 문서가 이를 "SQLite single-node, PostgreSQL HA; HA requires NATS as cluster coordinator"로 확증합니다 (docs).
dedup 상태 alert_dedup_state·alert_incidents도 sea_orm 테이블로 메타스토어에 상주합니다. 다만 file_list/scheduler와 동일 백엔드 인스턴스를 공유하는지는 추정입니다(구현상 불명확).
② Guardrail(거부·스킵 규칙).
글 전체에서 본 가드레일을 모읍니다.
_timestamp가 ingest window 밖이면 거부합니다. derived stream SQL에 _timestamp가 없으면 저장도 거부합니다.
retention 범위 밖 데이터는 compaction에서 스킵·삭제됩니다. compliance storage_type은 retention 최소 30일을 강제합니다.
// src/service/logs/ingest.rs:602 (요지)
if timestamp < min_ts { return Err(get_upto_discard_error()); } // 과거 폐기
if timestamp > max_ts { return Err(get_future_discard_error()); } // 미래 폐기
// src/service/alerts/derived_streams.rs:52
if !is_timestamp_selected(sql)? { /* derived stream 저장 거부 */ }③ 수집·생성 데이터 종합표(사용자 vs 시스템).
| 구분 | 단계/스트림 | 추가·생성 필드 | edition |
|---|---|---|---|
| 사용자 | 수집 직후 | 원본 JSON | OSS |
| 사용자 | flatten | a.b.c→a_b_c 평탄화 키 | OSS |
| 사용자 | _timestamp | i64 micros(없으면 주입) | OSS |
| 사용자 | _original,_record_id,_all_values | 보존 옵션·FTS용 | OSS |
| 사용자 | schema_key,partition_key | 저장 분기·파티션 경로 | OSS |
| 시스템 | distinct_values_* | _timestamp,count,<fields> | OSS |
| 시스템 | trace_list_index | _timestamp,stream_name,service_name,trace_id | OSS |
| 시스템 | usage/triggers/errors | 운영 관측 스트림(self-ingest) | OSS |
| 시스템 | triggers의 dedup_suppressed/grouped/group_size | dedup·grouping 통계(Enterprise 동작 시에만 채워짐) | Enterprise |
| 시스템 | _o2_service_graph | client/server edge·요청·지연 분위수 | Enterprise |
| 시스템 | _anomalies | actual_value·anomaly_score·is_anomaly | Enterprise |
| 시스템 | 메타스토어 | file_list·schema 버전·scheduler 트리거 | OSS |
6-2. 이 글의 작성 방법
이 글의 신뢰 근거는 AI들의 합의가 아니라 검증 가능성입니다.
본문의 모든 file:line은 고정 태그(v0.90.3)의 permalink로 누구나 원본 소스를 직접 열어 재확인할 수 있습니다.
작성 공정에서는 여러 도구(codex·cursor·claude CLI)로 레포를 독립 정독했습니다. 이후 라인 충돌·edition 경계를 실제 소스로 재판정하고, 공식 문서(openobserve.ai/docs)를 병렬 분석해 합본했습니다.
다중 작성은 누락을 줄이기 위한 절차일 뿐입니다. 주장의 근거는 어디까지나 코드 permalink와 (docs)입니다.
출처 표기는 다음 기준을 따릅니다.
- 코드:
file:line - 공식 문서:
(docs) - 벤더 벤치마크:
(벤더 주장) - 검증 불가 항목: "구현상 불명확"
Coroot 비교(§4)만은 코드 정독이 아닌 공식 문서·리포지토리 기반입니다. 그래서 (coroot docs) / (coroot 주장)으로 따로 표기했고, 근거 비대칭이 커서 상세 비교는 다음 편으로 분리했습니다.
v0.90.3 고정)
본문 file:line은 아래 베이스에 경로를 붙여 그대로 검증할 수 있다.
https://github.com/openobserve/openobserve/blob/v0.90.3/<path>#L<line>
handle_timestamp(§3-1): ingest.rs#L602StreamSettings(§3-3): stream.rs#L922- immutable persist (§3-3): immutable.rs#L92
- parquet bloom filter writer (§3-3): parquet.rs#L92
- tantivy 경로 변환 (§3-5): inverted_index.rs#L25
- tantivy → Puffin (§3-5): tantivy/mod.rs#L77
- alert 모듈 enterprise 게이트 (§3-6): alerts/mod.rs#L48
- DataFusion 세션 (§3-4): exec.rs#L69
- Architecture: https://openobserve.ai/docs/architecture/
- Ingestion: https://openobserve.ai/docs/ingestion/
- Streams/StreamSettings: https://openobserve.ai/docs/user-guide/data-processing/streams/streams-in-openobserve/
- Downsampling: https://openobserve.ai/docs/user-guide/data-exploration/metrics/downsampling-metrics/
- Federated Search: https://openobserve.ai/docs/user-guide/data-exploration/federated-search/
- MCP: https://openobserve.ai/docs/integration/ai/mcp/
