
Keep을 한 문장으로 정의하면 다음과 같습니다.
Keep은 alert ingestion, 정규화, deduplication, enrichment, correlation,
workflow automation, notification/UI를 하나의 파이프라인으로 묶은
AIOps 및 alert management 플랫폼입니다.
공식 README도 Keep을 "open-source AIOps and alert management platform"으로 소개하고,
single pane of glass, alert deduplication, enrichment, filtering, correlation, workflow,
dashboard를 핵심 가치로 제시합니다.
이 글에서는 제품 기능을 나열하기보다 alert 하나가 들어와서 저장되고, 줄여지고,
incident로 묶이고, workflow를 실행하고, UI에 보이기까지의 흐름을 코드와 문서 기준으로 따라가겠습니다.
이 글의 독자는 Keep 도입 여부를 검토하거나, 사내 alert pipeline과 비교하거나,
custom provider/workflow 확장 포인트를 확인하려는 백엔드/플랫폼 엔지니어로 가정합니다.
따라서 UI 기능 소개보다 backend pipeline, 데이터 흐름, 운영 리스크를 우선합니다.
| 구분 | 이 글의 기준 |
|---|---|
| 분석 범위 | Keep OSS v0.52.1 기준 alert ingestion부터 workflow/UI notify까지 |
| 재현 기준 | 로컬 compose 실행 후 /alerts/event로 넣은 alert 하나를 계속 추적 |
| 코드 설명 방식 | 파일명 나열보다 alert event가 이동하는 경로 중심 |
| 다루지 않는 것 | 모든 provider 구현 상세, frontend 내부 구현, Cloud/Enterprise 전용 AI correlation 상세 |
| 목표 | 글을 읽은 뒤 alert 하나의 end-to-end 경로와 운영상 위험 지점을 설명할 수 있게 하는 것 |
글이 길기 때문에 목적에 따라 읽는 경로를 나눠도 됩니다.
| 독자 목적 | 먼저 볼 섹션 |
|---|---|
| Keep이 무엇을 해결하는지 빠르게 파악 | §1, §2, §15 |
| alert 하나의 backend 흐름 추적 | §4, §5, §6, §7, §10 |
| dedup/correlation/workflow 차이 이해 | §7, §8, §9 |
| 운영 도입 전 리스크 검토 | §9, §13, §14 |
| custom provider 확장 검토 | §3, §11 |

1. 왜 Keep인가: Alert Fatigue를 플랫폼 관점에서 보기
모니터링 시스템이 많아질수록 문제는 "alert를 받을 수 있는가"보다
"받은 alert를 운영 가능한 단위로 줄이고, 묶고, 자동화할 수 있는가"로 이동합니다.
Prometheus Alertmanager는 routing과 silence에 강하고,
PagerDuty나 Opsgenie는 on-call escalation에 강합니다.
BigPanda류 제품은 correlation과 noise reduction을 전면에 둡니다.
GitHub Actions는 범용 workflow automation의 좋은 mental model입니다.
Keep은 이 요소들을 monitoring 도메인 안에서 다시 조합합니다.
Provider로 외부 도구와 연결하고, alert를 공통 모델로 정규화하고,
fingerprint와 deduplication으로 noise를 줄입니다.
그 다음 rules/topology/AI correlation으로 incident 후보를 만들고,
workflow로 후속 조치를 실행합니다.
| 도구 | 중심 역할 | Keep과 비교할 지점 |
|---|---|---|
| Alertmanager | Alert routing, grouping, silence | Keep의 Provider, fingerprint, workflow와 비교하기 좋습니다. |
| Grafana OnCall | On-call, escalation | Keep은 on-call 자체보다 alert pipeline과 automation 쪽이 더 넓습니다. |
| PagerDuty/Opsgenie | Incident response, escalation | Keep은 이들과 연동되는 upstream alert intelligence layer로 볼 수 있습니다. |
| BigPanda | Event correlation, noise reduction | Keep의 correlation/incident 모델과 비교하기 좋습니다. |
| GitHub Actions | Declarative automation | Keep Workflow를 이해하는 가장 쉬운 비유입니다. |
| Keep | AIOps pipeline + integration hub | Alert 수신부터 workflow 실행까지 한 backend 안에서 연결합니다. |
여기서 중요한 점은 Keep을 단순한 alert table UI로만 읽으면 안 된다는 것입니다.
Keep의 핵심은 backend pipeline입니다.
UI는 DB/Search API를 조회하고 Soketi/Pusher 이벤트를 받아 다시 poll하는 운영 콘솔에 가깝습니다.
2. 저장소와 런타임 지형도
저장소 루트는 크게 keep/, keep-ui/, docs/, examples/, tests/,
docker-compose*, keycloak/, oauth2proxy/, elk/, prometheus/ 같은 축으로 나뉩니다.
Backend는 Python/FastAPI, UI는 Next.js, WebSocket은 Soketi,
비동기 queue는 Redis + ARQ 조합을 사용합니다.
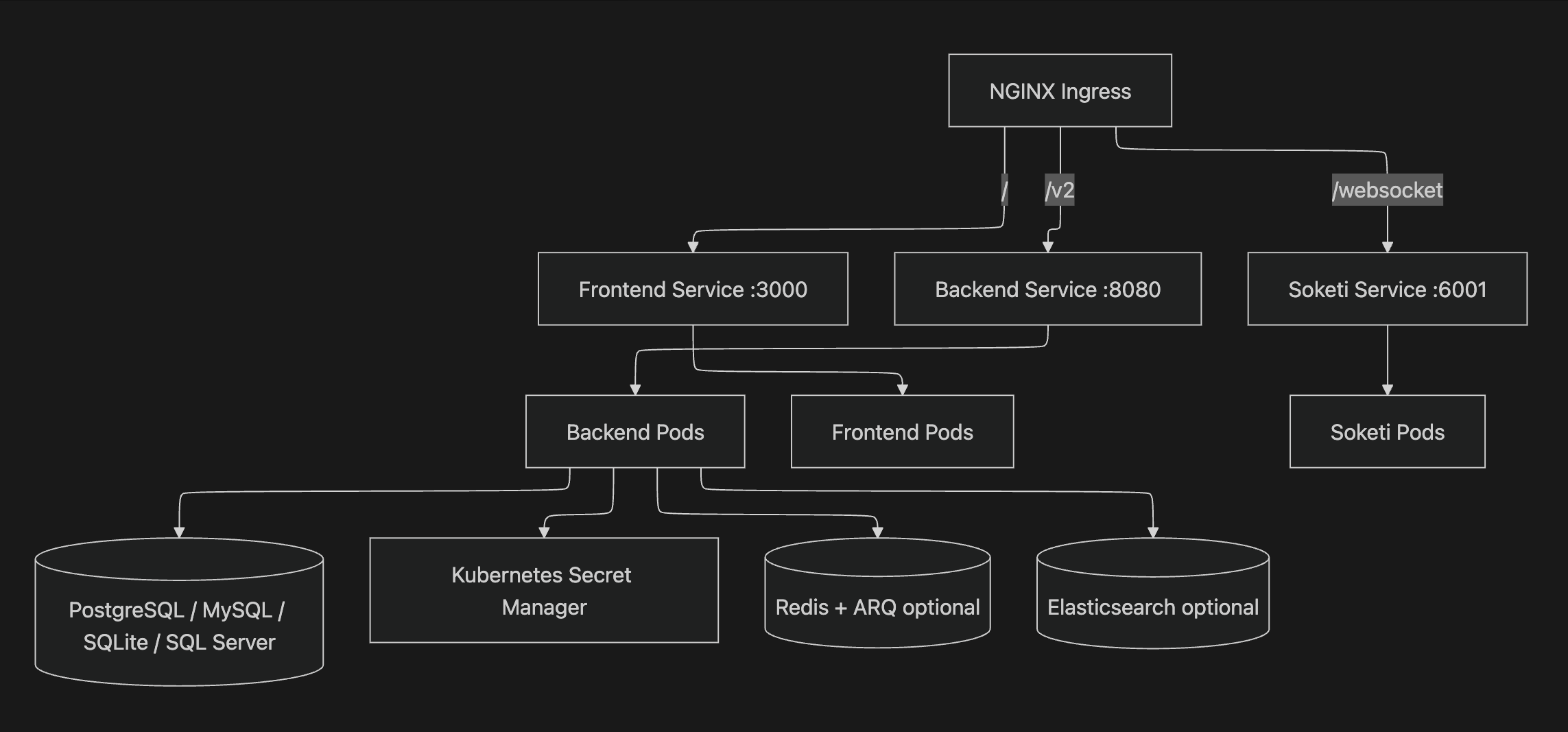
공식 Kubernetes Architecture 문서는 핵심 컴포넌트를 Keep API, Keep Frontend,
WebSocket Server, Database Server로 설명합니다.
Ingress는 /, /v2, /websocket을 각각 frontend, backend, websocket으로 라우팅합니다.
/v2는 FastAPI 백엔드의 API 버전 prefix이며, Ingress는 이 prefix를 포함한 경로를 backend Service로 라우팅합니다.
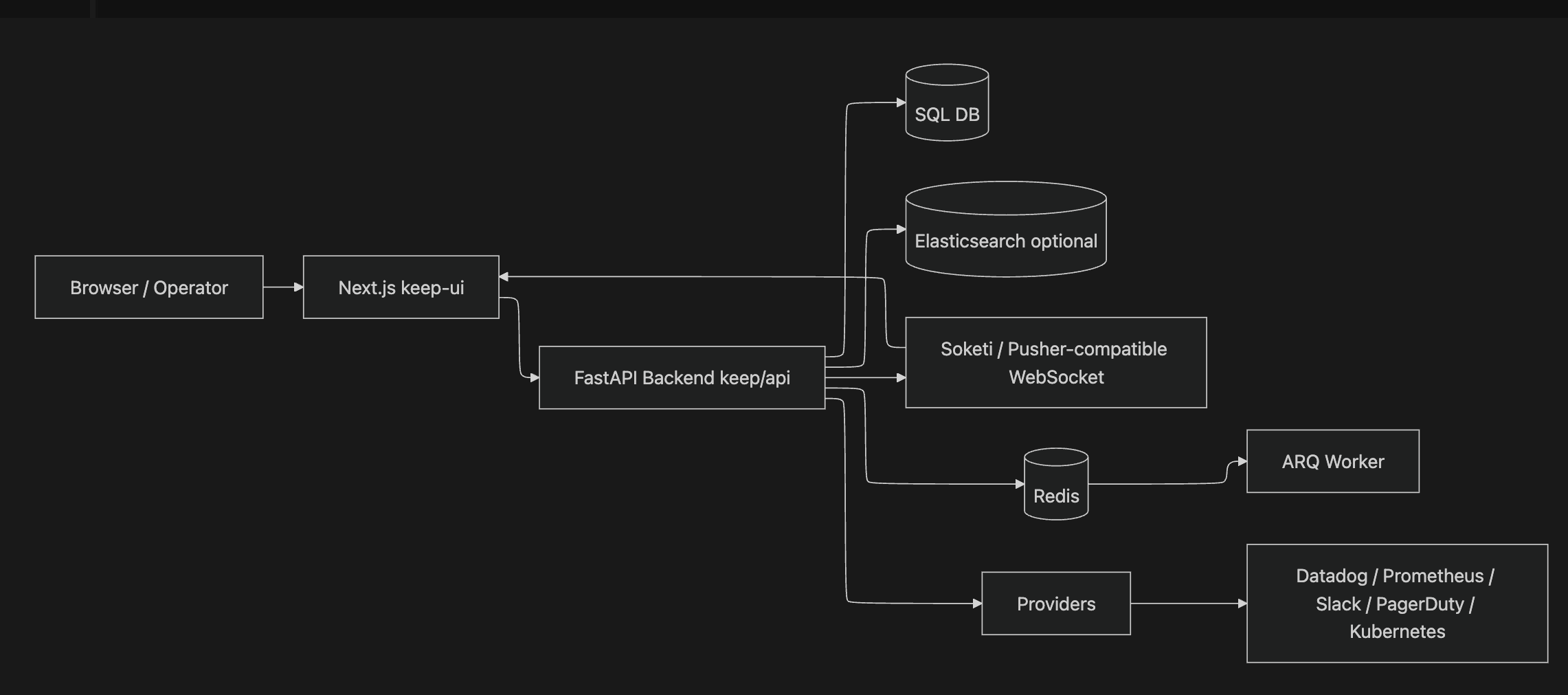
이 그림에서 API가 가장 중요한 중심입니다.
Alert 수신, dedup, enrichment, workflow trigger, rules engine,
WebSocket notification이 모두 backend 쪽에서 이어집니다.
Redis + ARQ는 alert ingestion job에 적용됩니다.
workflow 이벤트 큐는 별도로 in-memory WorkflowScheduler에서 관리되며, Redis/ARQ를 켜도 자동으로 이전되지 않습니다(자세한 내용은 §9 참고).
Redis/ARQ와 Elasticsearch는 기본 개발 환경의 필수 구성이라기보다
scale과 search 성격이 강한 선택 구성으로 보시는 편이 정확합니다.
공식 Docker 배포 문서의 빠른 실행 경로는 start.sh가 docker-compose.yml과
docker-compose.common.yml을 내려받은 뒤 docker compose up -d를 실행하는 방식입니다.
반면 저장소 안의 docker-compose.dev.yml은 소스 체크아웃 후 개발용 이미지를 빌드하는 경로입니다.
두 compose 파일 모두 공통 서비스 정의는 docker-compose.common.yml을 base로 포함합니다.
기본 포트 구성은 frontend 3000, backend 8080, Soketi 6001입니다.
docker-compose-with-arq.yml에서는 REDIS=true, REDIS_HOST=keep-arq-redis가 붙고
Redis stack과 ARQ dashboard가 추가됩니다.
이 차이가 alert ingestion의 동기성, 장애 유실, backpressure 분석으로 이어집니다.
3. Keep의 핵심 도메인 모델
Keep을 읽을 때 가장 먼저 고정해야 할 용어는 Alert, Provider, Fingerprint,
Deduplication Rule, Incident, Workflow, Topology입니다.
다만 코드 분석에서는 Alert라는 단어 하나로는 부족합니다.
같은 alert라도 들어온 직후, 정규화된 뒤, enrichment가 붙은 뒤,
DB에 저장된 뒤의 표현이 다릅니다.
| 표현 | 위치 | 의미 |
|---|---|---|
| Raw payload | 외부 provider 또는 /alerts/event request body | Datadog, Prometheus, Sentry 등 원본 형태입니다. |
AlertDto | keep/api/models/alert.py | Keep 내부 API/처리 흐름에서 쓰는 공통 alert DTO입니다. |
| Enriched alert | process_event_task.py, EnrichmentsBl 처리 이후 | extraction, mapping, 수동 enrich, workflow enrich 등이 반영된 표현입니다. |
| DB alert row | keep/api/models/db/alert.py | 영속 저장된 alert event입니다. fingerprint와 alert hash가 중요합니다. |
Provider는 단순 datasource가 아닙니다.
공식 Providers 문서는 provider를 외부 제품과 상호작용하는 Python extensible component로 설명합니다.
코드 기준으로도 BaseProvider는 _format_alert, _get_alerts, _query, _notify,
setup_webhook, pull_topology 같은 계약을 갖습니다.
즉 Provider는 ingestion, pull-query, notification-action, topology discovery를 모두 포괄하는 확장 경계입니다.
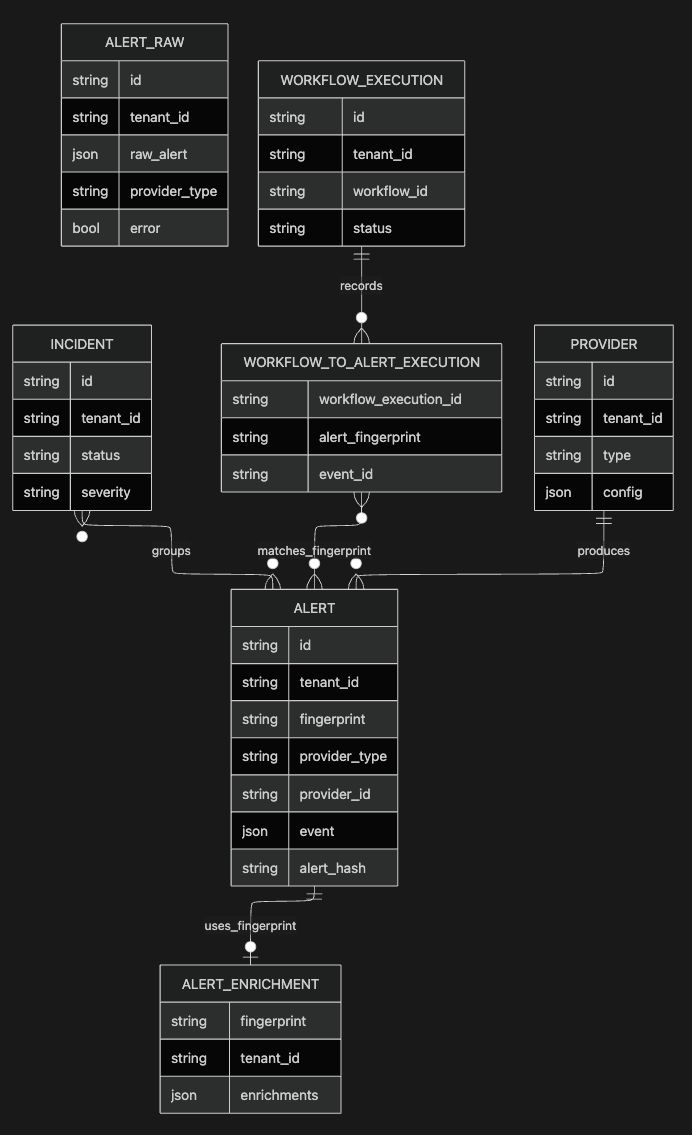
이 ERD는 실제 DB 스키마 전체를 재현하려는 목적이 아니라 개념 모델입니다.
PROVIDER 필드 보충: 실제 keep/api/models/db/provider.py에는 config 필드가 없습니다.
configuration_key는 secret manager 참조 키(문자열)이며, 실제 credential은 secret manager에 저장되고 DB에는 이 키만 저장됩니다.
provider_metadata는 provider 종류별 메타데이터 JSON입니다. ERD의 config는 개념 표기이며 실제 필드명과 다릅니다.
예를 들어 AlertRaw는 KEEP_STORE_RAW_ALERTS=true일 때 raw payload를 별도 저장하는 테이블이며
Alert와 직접 FK로 연결된다고 보면 안 됩니다.
ALERT_RAW는 선택 구성이며 기본 실행 환경에서는 생성되지 않습니다.
WorkflowExecution도 fingerprint를 직접 들고 있기보다
WorkflowToAlertExecution.alert_fingerprint 같은 연결 테이블을 통해 alert 실행 이력을 표현합니다.
AlertEnrichment는 이름과 달리 alert뿐 아니라 incident 같은 entity enrichment로 확장되는 방향의 테이블입니다.
코드 기준으로 AlertEnrichment 모델의 docstring에는 "we need to rename this table to EntityEnrichment since it's not only for alerts anymore"라고 명시되어 있습니다.
실제 모델 파일은 keep/api/models/db/alert.py, incident.py, workflow.py,
provider.py, secret.py, mapping.py, extraction.py 등을 확인하시면 됩니다.
4. 로컬 실행으로 분석 기준점 만들기
공식 Docker 문서 기준으로 Keep을 가장 빨리 띄우는 명령은 다음과 같습니다.
mkdir keep-docker
cd keep-docker
curl https://raw.githubusercontent.com/keephq/keep/main/start.sh | sh이 스크립트는 state/ 디렉터리를 만들고, main 브랜치의 docker-compose.yml과
docker-compose.common.yml을 내려받은 뒤 docker compose up -d를 실행합니다.
공식 문서가 설명하는 목적도 "latest images" 기반 실행입니다.
분석할 때는 최신 main을 계속 따라가기보다 tag를 고정하는 편이 좋습니다.
이 글의 작성 시점 최신 릴리스는 v0.52.1입니다.
소스 코드와 컨테이너 빌드를 같은 tag에 맞춰 재현하려면 공식 빠른 실행 스크립트 대신
저장소를 checkout한 뒤 개발용 compose를 사용합니다.
git clone https://github.com/keephq/keep.git
cd keep
git checkout v0.52.1
docker compose -f docker-compose.dev.yml up -d --build즉 단순 실행 확인은 공식 Docker 문서의 start.sh 경로를 쓰고,
코드 리딩과 로컬 수정까지 같이 보려면 docker-compose.dev.yml 경로를 쓰는 식으로 구분하시면 됩니다.
기본 실행 시 SQLite로 동작합니다. 공식 인증 문서는 no-auth 실행을 위해 AUTH_TYPE=NOAUTH를 안내합니다.
다만 v0.52.1의 docker-compose.yml에는 AUTH_TYPE=NO_AUTH가 들어 있고,
코드의 backward compatibility mapping을 통해 내부적으로 noauth로 변환됩니다.
개발용 compose에서 AUTH_TYPE을 별도로 주지 않아도 Keep의 인증 기본값은 noauth입니다.
환경변수 전체 목록은 저장소의 .env.example 또는 공식 configuration 문서를 참고하세요.
로컬 실행에서 가장 먼저 확인할 것은 기능 탐색이 아니라 연결 구조입니다.
| 컴포넌트 | 기본 포트 | 확인할 것 |
|---|---|---|
| Frontend | 3000 | NEXT_PUBLIC_API_URL, Pusher 설정 |
| Backend | 8080 | FastAPI API, /alerts/event, /healthcheck |
| Soketi | 6001 | Pusher-compatible WebSocket |
| SQLite | /state/db.sqlite3 | 개발 기본 DB |
| Redis/ARQ | 6379, 8081, 8082 | docker-compose-with-arq.yml 사용 시 Redis API, Redis Stack UI, ARQ dashboard |
이제 기준 alert를 하나 넣습니다.
# /alerts/event 경로는 X-API-KEY 헤더 자체가 없으면 요청이 실패할 수 있습니다.
# NOAUTH 로컬 구성에서는 값 검증을 하지 않으므로 임의의 값(local-dev-key 등)을 넣어도 됩니다.
# 인증이 켜진 구성에서는 Keep UI에서 발급한 실제 API key를 넣으세요.
curl -X POST http://localhost:8080/alerts/event \
-H "Content-Type: application/json" \
-H "X-API-KEY: local-dev-key" \
-d '{"name":"High CPU","status":"firing","severity":"critical","source":["manual"],"service":"payment"}'이 alert는 이후 장에서 계속 따라갈 기준 이벤트입니다.
이 시점의 상태는 "FastAPI가 요청을 받아 background task 또는 ARQ job으로 넘기는 대상"입니다.
재현성을 위해서는 요청 성공만 보지 말고 다음 세 가지를 같이 확인하는 편이 좋습니다.
| 확인 지점 | 확인할 내용 |
|---|---|
| API 응답 | HTTP 2xx가 반환되는가? 실패한다면 X-API-KEY 헤더 누락, JSON schema, backend log를 먼저 확인합니다. |
| UI Alerts 화면 | High CPU, critical, payment 값이 alert table에 나타나는가? |
| backend 처리 로그 | ThreadPool 또는 ARQ worker 경로로 process_event가 실행됐는가? |
같은 payload를 한 번 더 보내면 full deduplication 경로를 확인할 수 있습니다.
반대로 severity, description, pod 같은 값을 바꿔 보내면 같은 fingerprint 안에서 partial duplicate로 남는지 확인할 수 있습니다.
이 차이를 봐야 이후 §7의 fingerprint/hash 설명이 실제 동작과 연결됩니다.
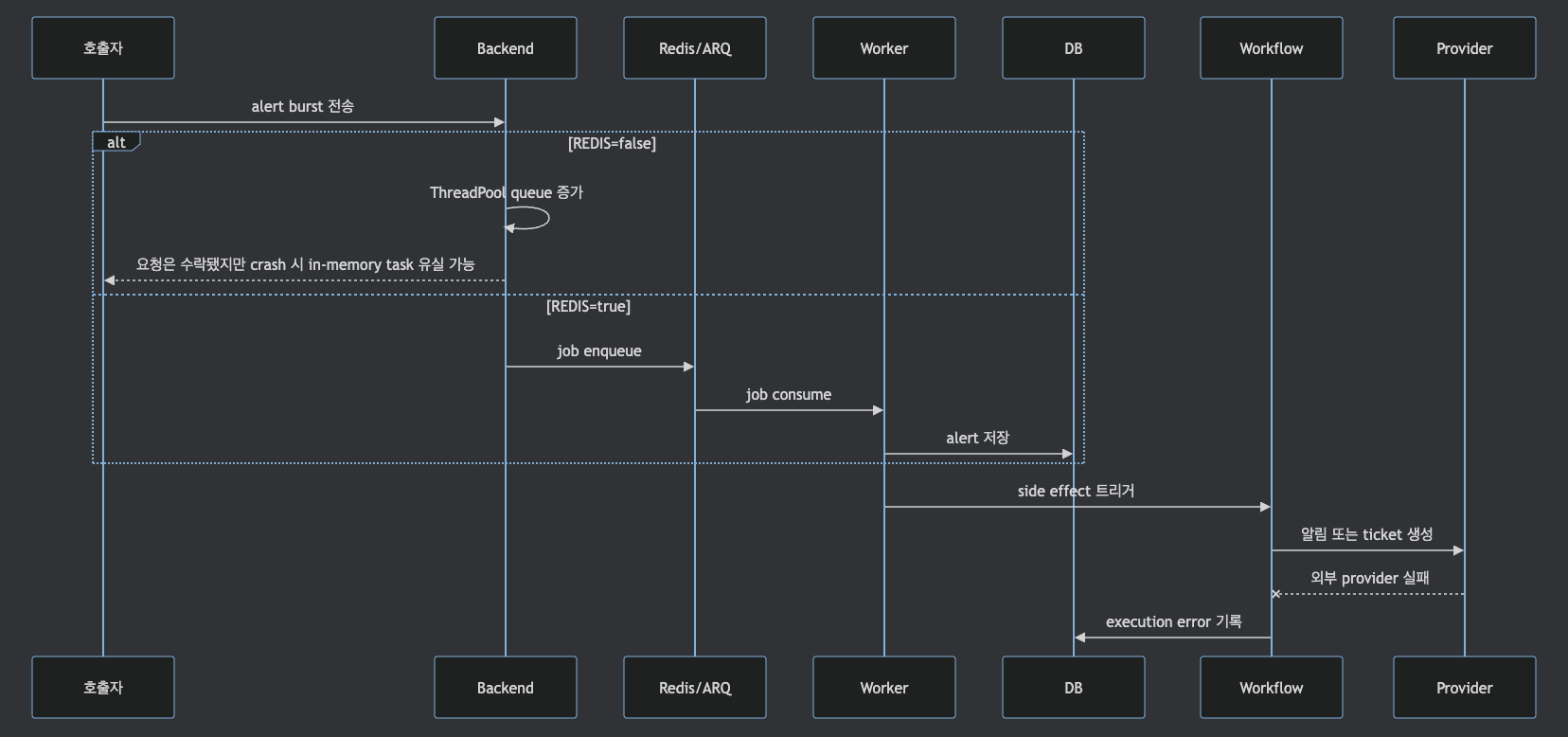
5. Alert Ingestion 파이프라인
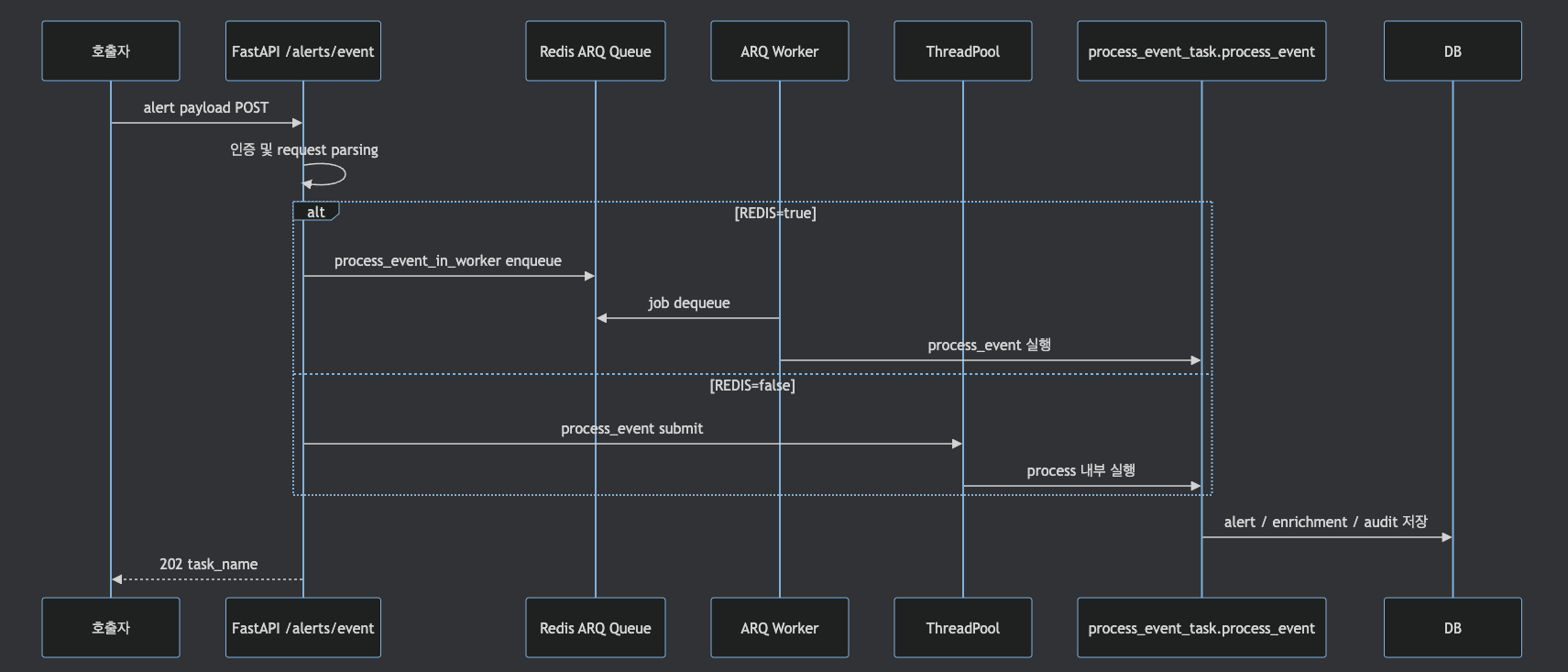
코드 기준으로 push alert의 대표 진입점은 keep/api/routes/alerts.py입니다.
일반 payload는 POST /alerts/event로 들어오고,
provider별 webhook payload는 POST /alerts/event/{provider_type} 경로를 탑니다.
두 경로 모두 REDIS 환경변수에 따라 처리 방식이 나뉩니다.
| 모드 | 코드 흐름 | 운영 의미 |
|---|---|---|
| Redis/ARQ 없음 | ThreadPoolExecutor.submit(process_event) | 단순하지만 프로세스 장애 시 in-memory task 유실 가능성이 있습니다. |
| Redis/ARQ 사용 | ARQ pool의 enqueue_job("process_event_in_worker", ...) | queue 기반으로 분리되지만 Redis와 worker 운영이 필요합니다. |
process_event_in_worker는 keep/api/arq_worker.py에 정의된 async wrapper 함수입니다.
내부적으로 functools.partial로 process_event_task.process_event를 감싸 thread pool executor에서 실행합니다.
코드를 추적할 때는 process_event_task.py와 arq_worker.py를 함께 확인하세요.
Keep에는 push webhook만 있는 것이 아닙니다.
Provider가 _get_alerts()를 구현하면 pull 방식으로 외부 시스템에서 alert를 가져올 수 있습니다.
Alert Evaluation Engine도 공식 문서상 datasource query와 rule evaluation으로 alert를 생성할 수 있는 별도 축입니다.
따라서 ingestion은 세 가지 진입점이 process_event 계열 처리로 합류하는 구조로 보시는 편이 좋습니다.
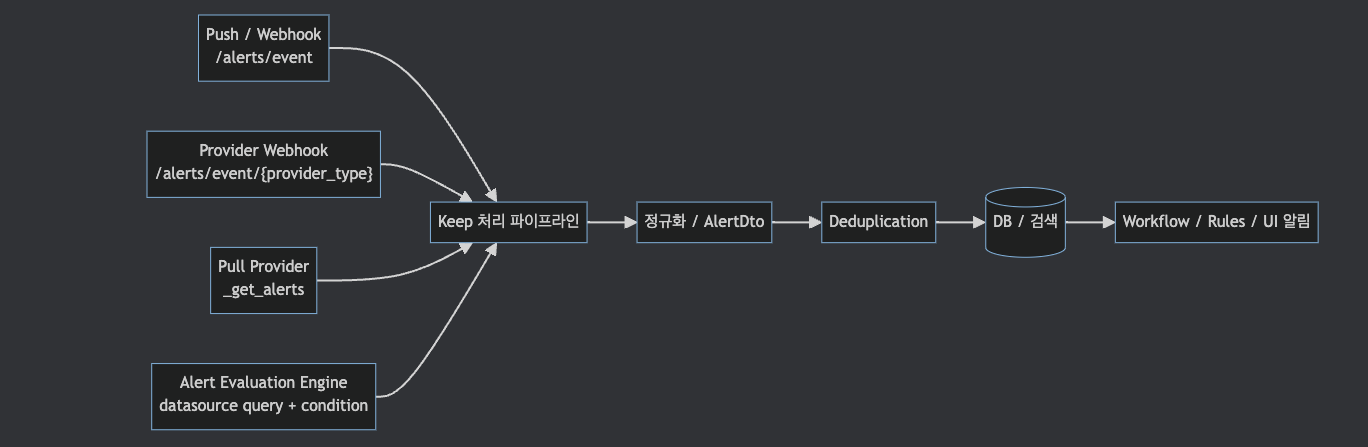
각 경로마다 확인할 질문은 다릅니다.
Push/Webhook은 요청 실패 시 재전송 책임을 봐야 합니다.
재전송 시 Keep의 full deduplication이 같은 fingerprint+hash 이벤트를 무시하므로, 정확히 동일한 payload 재전송은 DB 저장을 건너뜁니다.
Pull Provider는 polling 주기와 중복 처리 기준을 봐야 합니다.
Pull Provider의 _get_alerts() 호출은 Keep 내부 polling 스케줄러가 담당하며, polling 주기는 provider 설정으로 제어합니다.
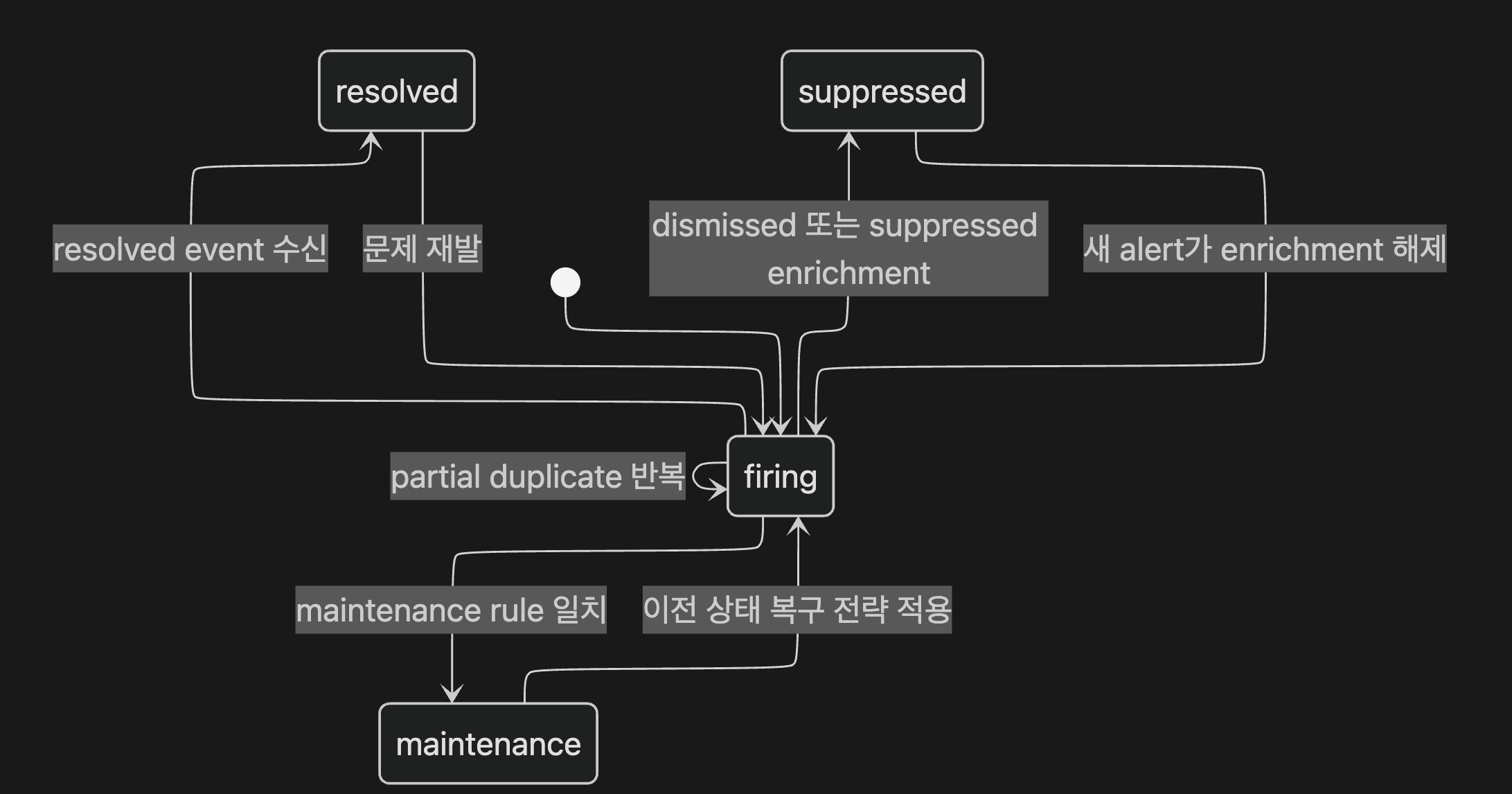
Alert Evaluation Engine은 pending/firing/resolved 상태 전이 위치를 확인해야 합니다.
process_event_task.py의 __handle_formatted_events()는 Keep alert 처리의 중심입니다.
코드 주석 기준으로 이 함수는 deduplication, DB 저장, Elasticsearch push,
workflow 실행, rules engine, preset update, client notify를 담당합니다.
실제 코드에서도 maintenance window 확인, deduplication 적용, DB 저장, mapping,
incident resolution, Elasticsearch index, workflow queue insertion,
KEEP_CORRELATION_ENABLED가 켜진 경우의 rules engine,
Pusher trigger가 한 흐름에 들어 있습니다.
6. 정규화, Extraction, Mapping, Enrichment
외부 alert는 공급자마다 모양이 다릅니다.
Keep은 provider의 _format_alert() 또는 generic AlertDto 생성을 통해 내부 공통 모델로 맞춥니다.
process_event()는 provider type이 있으면 ProvidersFactory.get_provider_class(provider_type)로 provider class를 찾고,
format_alert()를 호출합니다.
provider type이 없고 dict payload라면 AlertDto(**event)로 공통 DTO를 만듭니다.

공식 Extraction 문서는 regex 기반으로 alert 속성에서 구조화된 값을 추출한다고 설명합니다.
Mapping 문서는 CSV 또는 topology data와 alert attribute를 매칭해서 alert를 보강한다고 설명합니다.
코드 기준으로 process_event()는 pre-format extraction을 먼저 실행하고
provider formatting 또는 AlertDto 생성을 수행합니다.
이후 __handle_formatted_events()에서 maintenance window와 deduplication을 통과한 이벤트만
DB 저장 경로로 들어갑니다.
__save_to_db() 안에서는 post-format extraction을 실행한 뒤 alert row를 저장하고,
그 다음 mapping rule을 적용해 enrichment를 붙인 DTO를 다시 구성합니다.
CEL은 이 과정의 공통 조건 언어입니다.
공식 CEL 문서는 Keep이 alert를 predefined rule에 대해 평가하고 필터링하기 위해 CEL을 사용한다고 설명합니다.
Workflow trigger에서도 CEL을 사용하고, extraction rule 조건이나 search/facet 쪽에서도 CEL이 등장합니다.
본문에서는 CEL을 "workflow 전용 문법"이 아니라 "alert 조건 평가의 공통 언어"로 보시는 편이 맞습니다.
| 기능 | 역할 | 실패 시 확인할 지점 |
|---|---|---|
| Extraction | alert 문자열에서 필드 추출 | regex 문법, named group, CEL condition |
| Mapping | CSV/topology data와 매칭해 필드 보강 | matcher, data source, overwrite 여부 |
| Enrichment | alert/incident에 운영 컨텍스트 추가 | disposable enrichment, audit, workflow trigger 여부 |
| CEL | 조건 평가 | 실패 시 동작은 사용 위치마다 다릅니다. extraction rule 경로는 enrichments_bl.py의 try/except 존재 여부에 따라 예외가 상위로 전파될 수 있습니다. workflow trigger 경로(workflowmanager.py)와 search facet 경로는 별도로 확인하세요. 위치별로 skip/전파 여부를 코드에서 직접 검증하는 것이 안전합니다. |
이 단계의 샘플 alert는 AlertDto로 정규화되고, extraction/mapping/enrichment의 대상이 됩니다.
7. Noise Reduction: Maintenance, Suppression, Fingerprint, Deduplication
Noise reduction은 하나의 기능이 아닙니다. Keep에서는 최소 세 계층으로 나눠 볼 수 있습니다.
v0.52.1 코드 기준으로 __handle_formatted_events() 내 처리 순서는
(1) Maintenance Window 확인 → (2) Deduplication 순으로 실행되며,
Suppression은 enrichment 단계에서 별도로 적용됩니다.
| 계층 | 질문 | 예시 |
|---|---|---|
| Maintenance Window | 지금 알려도 되는가? | suppress=false → events 리스트에서 제거(처리 중단). suppress=true → MAINTENANCE/SUPPRESSED 상태 enrich 후 처리 계속. 반환값 의미가 직관과 역전되어 있음 (코드 확인 기준: process_event_task.py의 check_if_alert_in_maintenance_windows 반환값 로직). |
| Suppression | 정책상 숨길 alert인가? | dismissed/suppressed 상태 enrich |
| Deduplication | 같은 문제인가, 같은 이벤트인가? | fingerprint, alert hash, full/partial duplicate |
공식 Fingerprints 문서는 provider가 fingerprint 계산 필드를 선언하고,
필드가 없으면 alert name을 기본값으로 삼는다고 설명합니다.
코드 기준으로 이 설명은 provider 경로와 generic DTO 경로를 나눠 봐야 합니다.
BaseProvider의 get_alert_fingerprint()는 FINGERPRINT_FIELDS가 비어 있으면 alert.name을 반환하고,
필드가 지정되면 해당 값들을 SHA-256으로 hash합니다.
반면 generic /alerts/event payload가 AlertDto로 직접 만들어질 때는
fingerprint validator가 name 또는 전체 payload 기반 값을 SHA-256으로 hash해 fingerprint를 채웁니다.
custom dedup rule이 있으면 provider formatting 뒤에 fingerprint를 다시 계산합니다.
| 경로 | 기본 fingerprint 동작 | 확인할 코드 |
|---|---|---|
| Provider formatting | FINGERPRINT_FIELDS가 없으면 alert name, 있으면 지정 필드 hash | BaseProvider.get_alert_fingerprint() |
Generic /alerts/event | AlertDto validator가 name 또는 payload 기반 hash 생성 | AlertDto.get_fingerprint() |
| Custom dedup rule | 선택 필드 기준으로 fingerprint 재계산 | AlertDeduplicator.apply_deduplication() |
운영 주의: 두 경로는 동일한 alert name을 갖더라도 서로 다른 fingerprint를 생성할 수 있습니다.
Prometheus webhook과 generic/alerts/event를 동시에 수신하는 환경에서는 같은 alert가 다른 fingerprint를 가져 dedup이 실패할 수 있습니다.
여러 ingestion 경로를 혼용할 때는 fingerprint 일관성을 명시적으로 검증하세요.
공식 Deduplication 문서는 partial deduplication과 full deduplication을 구분합니다.
코드 기준으로 AlertDeduplicator는 ignore field를 제거한 alert hash를 계산하고,
같은 fingerprint의 마지막 hash와 비교합니다.
hash까지 같으면 full duplicate,
fingerprint는 같지만 hash가 다르면 partial duplicate로 표시합니다.
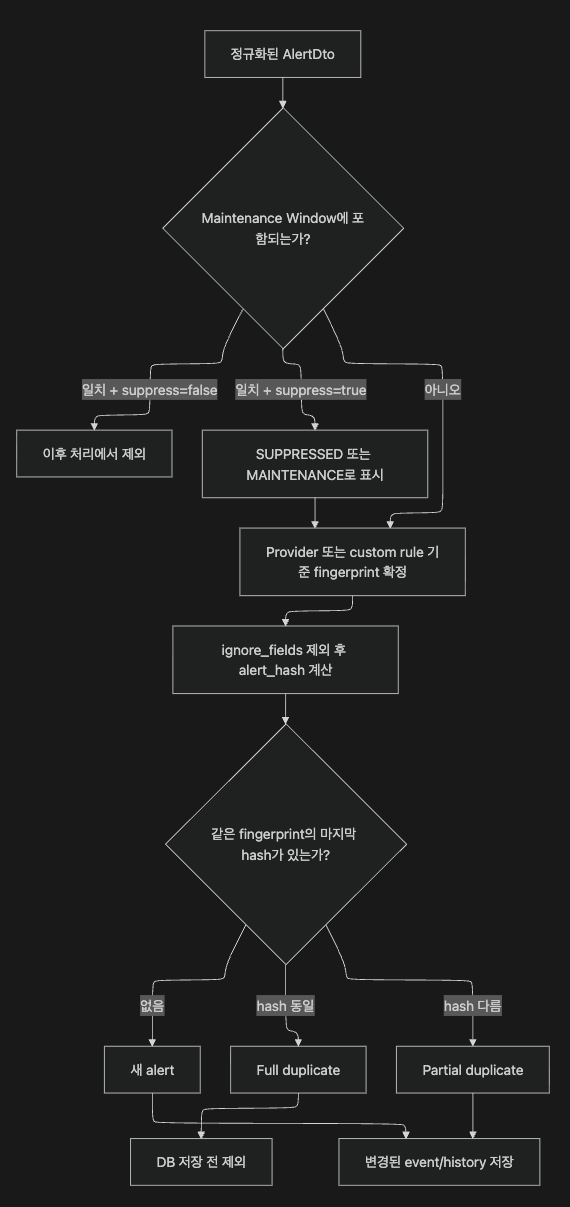
이 단계에서 샘플 alert는 fingerprint와 dedup rule에 의해
"새 alert", "partial duplicate", "full duplicate" 중 하나로 분류됩니다.
full duplicate는 DB 저장 전에 걸러질 수 있고,
partial duplicate는 같은 문제의 새 instance로 남을 수 있습니다.
8. Correlation과 Incident 생성
Dedup과 correlation은 서로 다른 문제입니다.
Dedup은 "같은 alert인가"를 줄이는 문제이고,
correlation은 "서로 다른 alert들이 같은 incident로 묶일 수 있는가"를 판단하는 문제입니다.
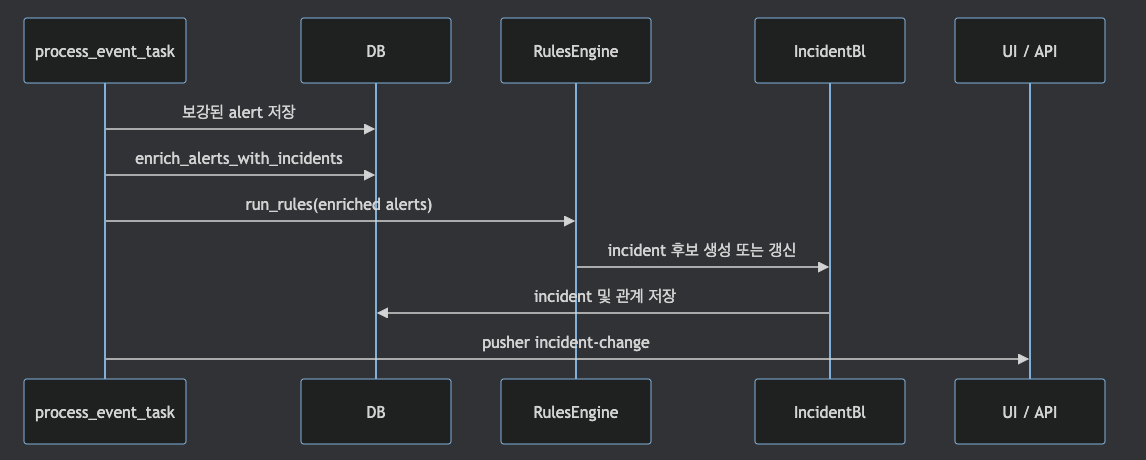
process_event_task.py는 alert 저장과 enrichment 이후,
KEEP_CORRELATION_ENABLED가 켜진 경우
RulesEngine(tenant_id).run_rules(events, session=session)를 호출합니다.
이 흐름이 rules engine 기반 incident 생성의 코드 진입점입니다.
KEEP_CORRELATION_ENABLED의 기본값은 true입니다 (코드 확인 기준: consts.py의 os.environ.get('KEEP_CORRELATION_ENABLED', 'true')).
로컬 실습에서 rules engine 흐름은 기본적으로 활성화되어 있습니다.
비활성화가 필요한 경우에만 KEEP_CORRELATION_ENABLED=false로 설정하세요.
다만 전체 alert 처리 순서에서는 alert-trigger workflow insertion이 rules engine보다 먼저 호출됩니다.
이 순서의 운영 함의는 §9에서 workflow 설계 관점으로 이어집니다.
즉 correlation 장에서는 rules engine 흐름을 따로 떼어 보되,
workflow까지 함께 추적할 때는 alert-trigger workflow와 incident-trigger workflow를 분리해야 합니다.
또 저장 직후 enrich_alerts_with_incidents()와 incident resolve check가 호출되므로,
alert와 incident의 관계는 저장 이후에도 계속 보강됩니다.
Topology correlation과 AI correlation은 기능 경계를 나눠야 합니다.
공식 문서에는 AI correlation이 별도 기능으로 설명되어 있지만,
공식 AI Correlation 문서는 Keep Open Source에서 사용할 수 없고
Keep Cloud 또는 Enterprise On-Prem 기능이라고 명시합니다.
Topology processor 역시 기본 활성 기능으로 가정하면 안 됩니다.
문서 기준으로 topology processor는 KEEP_TOPOLOGY_PROCESSOR=true 같은 명시 설정이 필요합니다.
따라서 OSS 코드 분석 글에서는 rules engine과 수동/topology 기반 흐름을 중심으로 설명하고,
AI correlation은 기능 경계 표로 분리하는 편이 안전합니다.
| 기능 | OSS 코드 분석 대상으로 다루기 | 비고 |
|---|---|---|
| Rules Engine correlation | 예 | keep/rulesengine/, routes/incidents.py, incidents_bl.py |
| Topology correlation | 일부 확인 | topology provider/model과 processor 활성화 설정 확인 |
| AI correlation | 문서 기능으로 분리 | Cloud/Enterprise On-Prem 기능 경계 명시 |
이 단계에서 샘플 alert는 단독 alert로 남거나, rules/topology 조건에 의해 incident 후보 또는 related alert로 묶일 수 있습니다.
9. Workflow Engine 분석
공식 README는 Keep Workflow를 "monitoring tools를 위한 GitHub Actions"로 설명합니다.
이 비유는 꽤 정확합니다.
Workflow는 YAML로 선언되고, trigger가 alert/incident/schedule/manual 이벤트를 보고,
step/action이 provider를 호출합니다.
WorkflowManager와 WorkflowScheduler 역할 분리 (코드 확인 기준):
| 컴포넌트 | 파일 | 담당 역할 |
|---|---|---|
WorkflowManager | keep/workflowmanager/workflowmanager.py | 이벤트 수신, workflow 선별, CEL trigger 평가, WorkflowScheduler 위임 |
WorkflowScheduler | keep/workflowmanager/workflowscheduler.py | 실행 큐 관리, background loop, ThreadPool 실행, execution 이력 기록 |
코드 기준으로 alert 처리 후 WorkflowManager.insert_events()가 호출됩니다.
이 함수는 workflow store에서 workflow를 가져오고, trigger filter 또는 CEL을 평가하고,
조건을 통과하면 WorkflowScheduler.workflows_to_run에 실행 대상을 넣습니다.
구식 filters가 있으면 _convert_filters_to_cel()로 CEL로 변환되는 호환 경로가 있고,
filters가 존재하면 cel보다 우선하여 변환된 값이 CEL 평가에 사용됩니다 (코드 확인 기준: workflowmanager.py _convert_filters_to_cel()).
§8에서 언급한 것처럼, alert-trigger workflow queue insertion은 rules engine 실행보다 먼저 호출됩니다.
따라서 alert-trigger workflow는 incident 생성 이전의 alert 상태를 기준으로 실행됩니다.
incident 상태나 연결된 incident 정보를 workflow 조건으로 사용하려면 incident-trigger workflow를 사용해야 합니다.
incident-trigger workflow는 incident 생성/변경 경로에서 별도로 평가됩니다.
Scheduler는 background loop에서 queue를 비우고 ThreadPool로 workflow를 실행합니다.
Workflow YAML 의사 예시 (구조를 설명하기 위한 축약본이며, 그대로 실행하는 예제가 아닙니다):
workflow:
id: alert-to-slack-example
description: Critical alert → Slack 알림 (구조 예시)
triggers:
- type: alert
filters:
- key: severity
value: critical
steps:
- name: notify-slack
provider:
type: slack
config: "{{ providers.slack-prod }}"
with:
message: "Alert: {{ alert.name }} | Service: {{ alert.service }}"실제 workflow YAML은 사용 중인 Keep 버전의 workflow syntax와 provider method schema를 확인한 뒤 작성하세요.
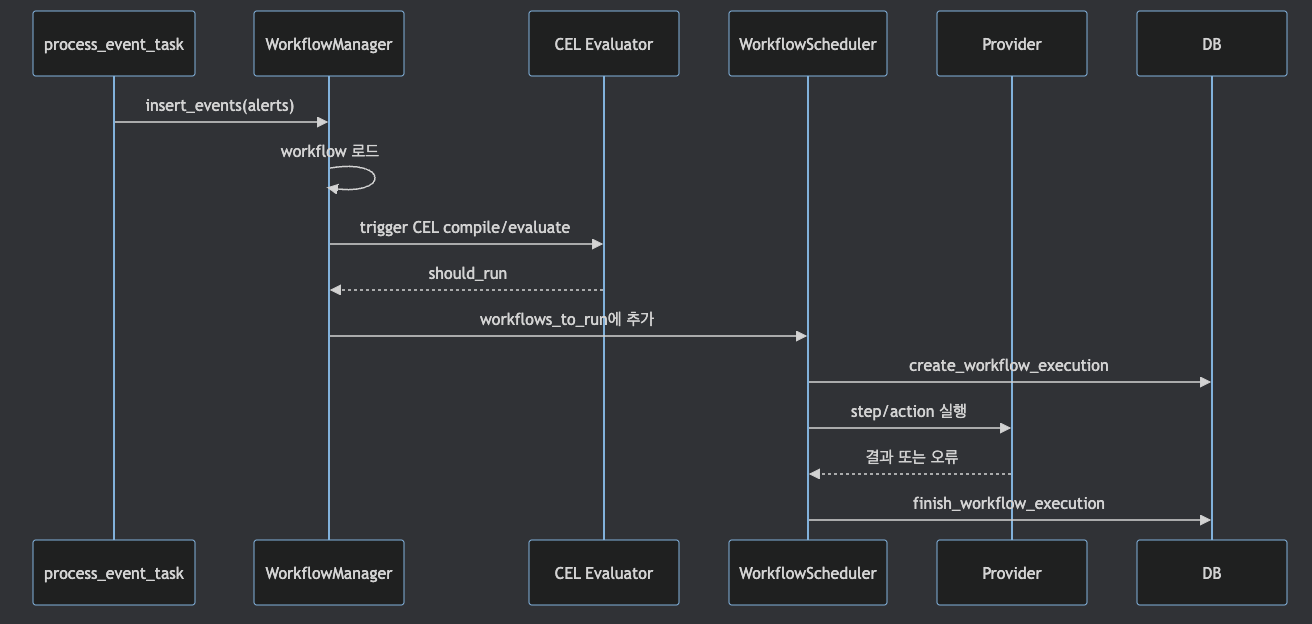
운영 관점에서 중요한 부분은 event workflow queue가 현재 process memory에 있다는 점입니다.
workflowscheduler.py에도 event workflows should be in DB to avoid state problems라는 TODO가 있습니다.
실행 이력은 DB에 만들지만, event queue 자체는 scheduler memory list로 운영됩니다.
Redis/ARQ를 켜면 alert ingestion job은 queue 기반으로 분리되지만,
event-trigger workflow queue가 자동으로 Redis queue로 이전되는 것은 아닙니다.
운영 위험: Backend를 여러 replica로 운영할 때 각 인스턴스의
WorkflowScheduler가 동일한 event를
독립적으로 처리할 수 있습니다.IntegrityError기반 중복 방지가 있지만, 이는 DB write 시점의
race condition만 커버하므로 Slack 메시지, Jira 티켓 등 side effect는 중복 실행될 수 있습니다.
Backend replica를 늘릴 때는 이 위험을 반드시 확인해야 합니다(§13 확장성 항목과 연결).
Workflow failure model은 다음처럼 정리할 수 있습니다.
| 항목 | 코드에서 확인되는 방향 | 운영 질문 |
|---|---|---|
| 실행 이력 | create_workflow_execution, finish_workflow_execution | 실행 상태를 UI/API에서 추적할 수 있는가? |
| 동시 실행 | workflow strategy와 IntegrityError 처리 | 같은 fingerprint로 중복 실행되는가? |
| retry | nonparallel with retry에서 queue 재삽입 | side effect가 idempotent한가? |
| timeout | timeout workflow execution detection | worker crash 후 상태가 error로 마감되는가? |
| on_failure | _run_workflow_on_failure() — workflowmanager.py에 위치 | 실패 알림이 또 다른 장애를 만들지 않는가? |
이 단계에서 샘플 alert는 workflow trigger 조건 평가 대상이 되고, 조건을 통과하면 workflow execution으로 기록됩니다.
10. UI에 보이기까지: 저장, 검색, 실시간 Push
Alert가 처리됐다는 것과 사용자가 UI에서 봤다는 것은 다른 문제입니다.
Keep은 alert를 DB에 저장하고, 필요하면 Elasticsearch에 index합니다.
API 조회는 DB/search layer에서 읽고,
UI는 Pusher/Soketi 이벤트를 받아 다시 poll합니다.
process_event_task.py는 alert 저장 후 Elasticsearch client가 enabled이면 index를 수행합니다.
Elasticsearch를 활성화하려면 ELASTICSEARCH_HOST 등 관련 환경변수를 설정해야 합니다.
구체적인 설정은 저장소의 elk/ 디렉터리 또는 공식 stress testing 문서를 참고하세요.
이후 Pusher client가 있으면 tenant private channel에 poll-alerts, incident-change,
poll-presets 이벤트를 보냅니다.
즉 WebSocket payload가 alert 전체를 싣는 방식이라기보다,
UI에 "다시 조회하라"고 알려주는 신호에 가깝습니다.
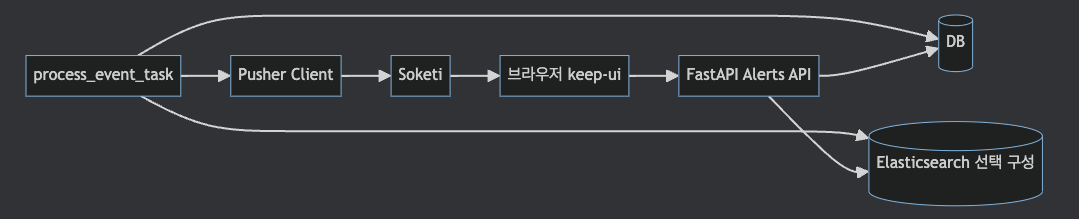
공식 stress testing 문서는 alert 수가 커질수록 Elasticsearch와 Redis+ARQ를 고려하라고 설명합니다.
특히 100,000개 이상의 alert 또는 매우 높은 ingestion volume에서는
Elasticsearch와 Redis+ARQ가 성능 축으로 등장합니다.
따라서 "UI에서 검색이 느리다"는 문제는 단순 frontend 문제가 아니라
DB index, Elasticsearch 사용 여부, alert 보관 정책과 연결해서 봐야 합니다.
11. Provider 구조와 Custom Provider 확장
Provider는 Keep 확장성의 핵심입니다.
공식 문서상 provider는 third-party product와 상호작용하는 Python extensible component입니다.
코드 기준으로도 BaseProvider는 ingestion formatting, pull/query,
notification/action, topology/incident라는 네 가지 capability 축을 갖습니다.
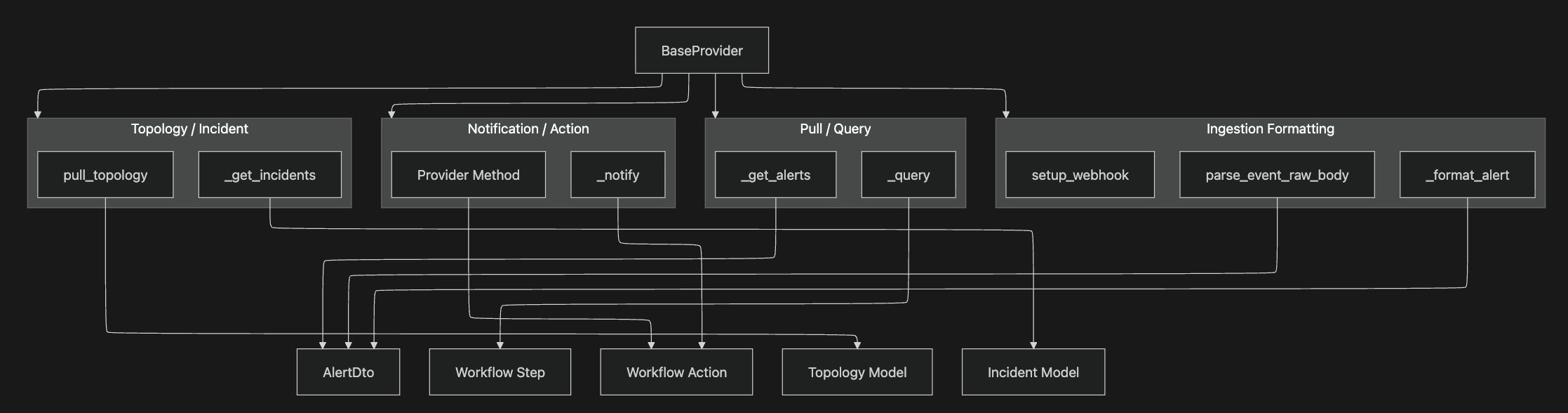
Custom Provider를 추가할 때는 "파일 하나 추가"보다 계약을 먼저 봐야 합니다.
provider discovery는 providers_factory.py와 *_provider 네이밍 관례에 기대고,
provider class는 config validation, fingerprint fields, format/query/notify contract를 구현해야 합니다.
provider method를 UI/API에 노출해야 한다면 expose decorator와 ProviderMethod metadata도 같이 확인해야 합니다.
webhook을 받는 provider라면 setup_webhook()과 parse_event_raw_body() 계약도 봐야 합니다.
최근 코드 기준으로 pulled alerts에도 custom dedup rule을 적용하는 로직이
BaseProvider.get_alerts()에 들어 있습니다.
이는 webhook과 pull 경로의 fingerprint 일관성을 맞추는 중요한 포인트입니다.
Credential은 secretmanager와 deployment secret store를 같이 봐야 합니다.
코드 기준으로 keep/secretmanager/의 SecretManagerTypes enum은
FILE, GCP, K8S, VAULT, AWS, DB 6개를 모두 포함합니다.
AWS는 AWS Secrets Manager를 사용하는 정식 지원 backend입니다.
| Secret Manager backend | 지원 여부 |
|---|---|
FILE | 정식 지원 (OSS) |
GCP | 정식 지원 (OSS) |
K8S | 정식 지원 (OSS) |
VAULT | 정식 지원 (OSS) |
AWS | 정식 지원 (OSS) — AWS Secrets Manager |
DB | 정식 지원 (OSS) |
코드와 문서가 다를 경우 코드가 우선합니다.
keep/secretmanager/ 디렉터리에서 실제 구현된 backend와 enum 값을 확인하세요.
Kubernetes 배포에서는 integration credential을 Kubernetes Secret Manager에 저장하는 구조도 문서화되어 있습니다.
12. 관통 실습: 실제 장애 시나리오 자동화
관통 실습은 Kubernetes OOMKilled 또는 CrashLoopBackOff 시나리오로 잡는 것이 좋습니다.
이 시나리오는 alert ingestion, dedup, incident grouping, workflow, provider action을 모두 사용하게 만듭니다.
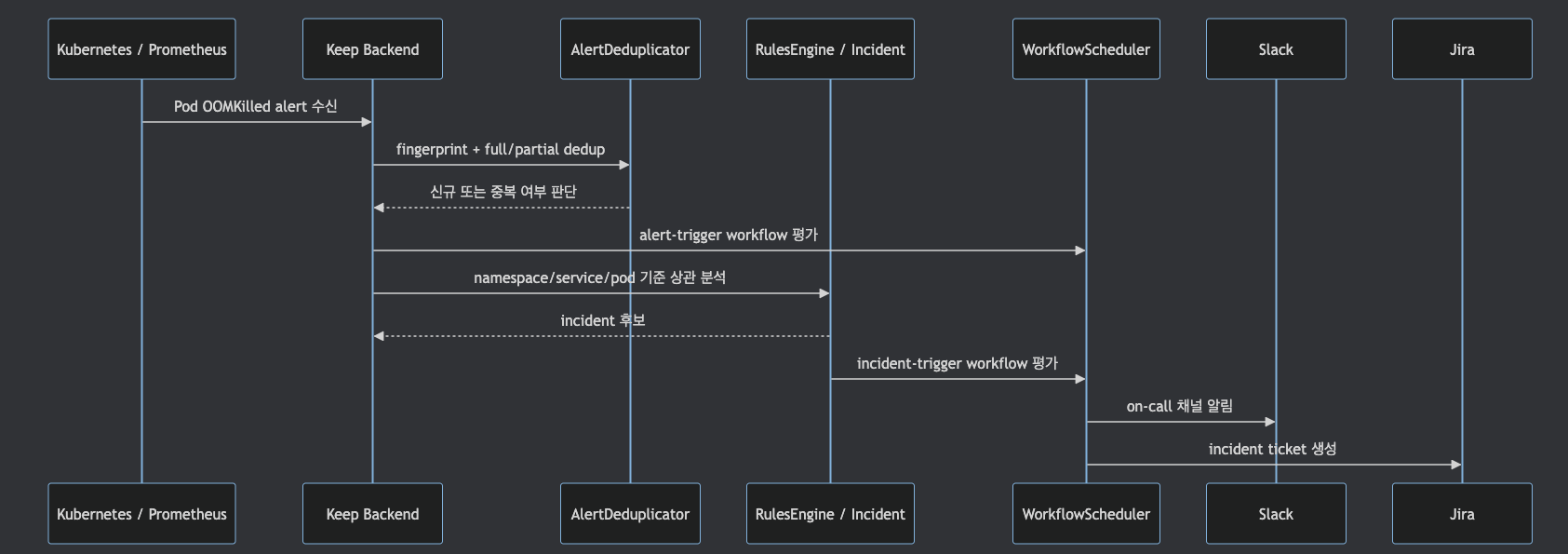
이 실습의 핵심은 YAML 문법이 아닙니다.
Slack/Jira/PagerDuty 같은 provider action은 provider config 이름, provider method schema,
template 문법, credential 등록 상태에 따라 달라집니다.
따라서 블로그 본문에 실행 가능한 것처럼 보이는 workflow YAML을 싣기보다,
다음 검증 항목을 기준으로 실습을 설계하는 편이 안전합니다.
| 검증 항목 | 확인할 질문 |
|---|---|
| Alert 수신 | Kubernetes OOMKilled 또는 CrashLoopBackOff alert가 Keep의 어떤 ingestion 경로로 들어오는가? |
| Fingerprint | namespace, service, pod, container 중 어떤 필드가 같은 문제를 대표하는가? |
| Dedup | 같은 fingerprint가 반복될 때 full duplicate와 partial duplicate가 어떻게 구분되는가? |
| Incident | namespace/service 기준으로 alert가 같은 incident 후보로 묶이는가? |
| Workflow | alert-trigger workflow와 incident-trigger workflow 중 어느 쪽이 적합한가? |
| Side effect | Slack/Jira/PagerDuty action이 중복 실행되지 않도록 idempotency를 어떻게 확보할 것인가? |
| Resolve | resolved event가 들어왔을 때 기존 incident, ticket, enrichment 상태가 어떻게 바뀌는가? |
| Credential | provider credential이 어떤 secret backend에 저장되고 audit trail이 남는가? |
최소 smoke test는 실제 Kubernetes provider나 Slack/Jira 연동 없이도 만들 수 있습니다.
먼저 같은 장애를 대표하는 alert를 두 번 넣고, 두 번째 요청에서 dedup 동작을 확인합니다.
curl -X POST http://localhost:8080/alerts/event \
-H "Content-Type: application/json" \
-H "X-API-KEY: local-dev-key" \
-d '{"name":"Kubernetes Pod CrashLoopBackOff","status":"firing","severity":"critical","source":["manual"],"namespace":"payments","pod":"payment-api-7d9f","container":"api","service":"payment-api"}'
curl -X POST http://localhost:8080/alerts/event \
-H "Content-Type: application/json" \
-H "X-API-KEY: local-dev-key" \
-d '{"name":"Kubernetes Pod CrashLoopBackOff","status":"firing","severity":"critical","source":["manual"],"namespace":"payments","pod":"payment-api-7d9f","container":"api","service":"payment-api","description":"restart count increased"}'이때 X-API-KEY 값은 로컬 NOAUTH 구성에서는 임의 값이어도 되지만, 헤더 자체는 넣어야 합니다.
첫 번째 alert는 새 이벤트로 저장되고, 두 번째 alert는 fingerprint와 hash 계산 결과에 따라
full duplicate 또는 partial duplicate로 분류되는지 확인합니다.
그 다음 rules/correlation 설정을 추가해 같은 namespace/service의 alert가 incident 후보로 묶이는지 보고,
마지막으로 Slack/Jira 대신 side effect가 작은 provider action 또는 테스트용 workflow로 실행 이력만 검증하는 순서가 안전합니다.
실제 workflow YAML은 사용 중인 Keep 버전의 workflow 문서와 provider method schema를 확인한 뒤 작성하시는 편이 좋습니다.
이 글에서는 실행 가능한 튜토리얼보다,
어떤 질문을 던져야 Keep의 C~F 경로를 강제로 깊게 보게 되는지를 기준으로 삼습니다.
13. 운영 도입 전 체크
운영 검토는 "잘 뜨는가"보다 "문제가 생겼을 때 어디서 유실되고 어디가 병목이 되는가"를 묻는 단계입니다.
| 축 | 확인할 질문 |
|---|---|
| 인증 | 개발 환경의 no-auth 설정과 운영 인증/API key 경계를 분리했는가? |
| 확장성 | Backend replica를 늘릴 때 scheduler/consumer가 중복 실행되지 않는가? IntegrityError가 DB write race condition만 커버하므로 side effect(Slack, Jira 등) 중복 실행 위험을 별도로 검토했는가? (§9 참고) |
| 신뢰성 | Redis 없이 ThreadPool 모드에서 프로세스가 죽으면 task가 유실되는가? |
| 성능/용량 | alert volume, total alerts, workflow count 중 무엇이 병목인가? |
| 검색 | DB query로 충분한가, Elasticsearch가 필요한가? |
| 보관 정책 | raw alert, alert history, Elasticsearch index lifecycle을 어떻게 관리할 것인가? |
| 보안 | provider credential은 어떤 secret backend에 저장되는가? |
| 관측성 | /healthcheck 외에 Keep 자체 SLI/SLO와 production health monitoring을 어떻게 보강할 것인가? |
| 데이터 관리 | KEEP_STORE_RAW_ALERTS를 켜면 PII와 스토리지 비용을 감당할 수 있는가? |
| 업그레이드 | Alembic migration과 rollback 전략은 있는가? |
공식 Monitoring 문서는 backend /healthcheck, frontend /api/healthcheck를 제시합니다.
다만 Prometheus metrics는 TBD라고 설명하고,
/api/metrics는 production health monitoring 목적이 아니라 tenant usage monitoring 목적이라고 명시합니다.
따라서 Keep 자체의 관측성은 운영 도입 전 별도 보강 대상입니다.
공식 stress testing 문서는 작은 환경은 기본 RDBMS로 충분할 수 있지만,
alert volume이 커질수록 Elasticsearch와 Redis+ARQ를 고려하라고 설명합니다.
특히 total alert 수, alert ingestion rate, workflow count가 스펙 요구를 결정하는 핵심 변수입니다.
의사결정 기준은 다음처럼 잡을 수 있습니다.
| 상황 | 우선 선택 | 이유 |
|---|---|---|
| 로컬 분석, 소규모 PoC | 기본 DB + ThreadPool | 구성 요소가 적어 코드 흐름을 추적하기 쉽습니다. |
| alert ingestion rate가 높거나 burst가 잦음 | Redis + ARQ | 요청 처리와 background processing을 분리해 backpressure를 다룰 수 있습니다. |
| alert 총량이 커지고 검색/필터가 느림 | Elasticsearch | UI 검색과 facet 조회가 DB query 병목에서 분리됩니다. |
| workflow side effect가 많음 | workflow idempotency 설계 우선 | Redis/ARQ는 alert ingestion queue를 분리하지만 event workflow queue 중복 실행 문제를 자동으로 해결하지 않습니다. |
| raw alert 저장 필요 | KEEP_STORE_RAW_ALERTS + 보관/마스킹 정책 | 원본 payload에는 credential, PII, 고객 식별자가 섞일 수 있습니다. |
14. Provisioning/GitOps와 기능 경계
운영 환경에서는 UI에서 클릭해 만든 provider나 workflow만으로는 변경 이력을 관리하기 어렵습니다.
Keep은 provisioning 문서에서 provider, workflow, dashboard, mapping rule 같은 리소스를
환경변수 또는 파일 경로로 provision하는 전략을 제공합니다.
GitOps 관점에서는 이 기능을 사용해 UI 설정과 선언형 설정의 경계를 정리해야 합니다.
| 대상 | 선언형 운영 검토 포인트 |
|---|---|
| Provider | KEEP_PROVIDERS JSON 또는 파일 경로, credential secret backend |
| Workflow | env/file 기반 provisioning, GitHub Action sync 가능성 |
| Mapping Rule | CSV/topology 기반 enrichment rule 관리 |
| Dashboard/Preset | 운영자별 UI 상태를 코드로 관리할지 결정 |
| Dedup Rule | provisioned rule은 UI 수정/삭제 제한 여부 확인 |
| Auth/Secret | 인증 방식과 secret backend를 환경별로 고정 |
기능 경계도 분명히 해야 합니다.
| 기능 | OSS 코드 분석 | 문서상 Cloud/Enterprise 경계 |
|---|---|---|
| Basic alert ingestion/dedup/workflow | 예 | OSS 중심 |
No Auth (AUTH_TYPE=NOAUTH) | 예 | OSS |
DB auth (AUTH_TYPE=DB) | 예 | OSS — username/password 기반 로컬 DB 인증 |
| OAuth2 Proxy | 예 | OSS |
| Auth0 | 코드에 enum 존재 (auth0) | 공식 인증 문서 기준 EE(Enterprise) |
| Azure AD | EE 모듈 경로 확인 필요 | 공식 인증 문서 기준 EE(Enterprise) |
| Okta / OneLogin | 예 | 공식 인증 문서 기준 OSS |
| Keycloak | 저장소에 keycloak/ 디렉터리 존재 | 공식 인증 문서 기준 EE(Enterprise) |
| AI correlation | 아니오 | Keep Cloud / Enterprise On-Prem 문서 기능 |
| Topology processor | 일부 가능 | 명시 env와 provider/topology data 준비 필요 |
| Secret Store | 예 | backend별 운영 책임 다름 |
이 글에서는 공식 문서로 확인한 내용, v0.52.1 코드에서 확인한 내용,
운영 관점의 추론을 의도적으로 구분했습니다.
그래야 OSS 코드 분석과 제품 문서 기능 소개가 섞이지 않습니다.
15. 정리: Keep을 이해했다는 기준
Keep을 한 번 훑어본 것과 운영 가능한 수준으로 이해한 것은 다릅니다.
이 글의 기준으로는 다음 질문에 답할 수 있어야 합니다.
- Alert 하나가
/alerts/event로 들어와 UI에 보이기까지의 코드 경로를 설명할 수 있습니까? AlertDto, enriched alert, DB alert row의 차이를 설명할 수 있습니까?- Fingerprint와 alert hash가 partial/full dedup에서 어떻게 쓰이는지 설명할 수 있습니까?
- Maintenance Window, Suppression, Dedup, Correlation의 차이를 설명할 수 있습니까?
- Workflow trigger가 CEL로 평가되고 scheduler queue로 넘어가는 흐름을 설명할 수 있습니까?
- Workflow side effect가 중복 실행될 수 있는 조건을 검토할 수 있습니까?
- Custom Provider를 만들 때
_format_alert,_get_alerts,_query,_notify, secret 처리 중
무엇을 구현해야 하는지 판단할 수 있습니까? - Kubernetes 운영 시 Backend, Redis/ARQ, DB, Elasticsearch, Soketi를 어떻게 분리할지 설명할 수 있습니까?
- OSS 코드로 확인 가능한 기능과 Cloud/Enterprise 문서 기능을 구분할 수 있습니까?
Keep의 좋은 점은 alert management를 여러 컴포넌트의 느슨한 조합이 아니라
하나의 파이프라인으로 보여준다는 점입니다.
동시에 운영자는 그만큼 질문을 촘촘히 던져야 합니다.
alert를 받는 것, 줄이는 것, 묶는 것, 자동화하는 것, 사용자에게 보여주는 것은
각각 다른 실패 모드를 갖기 때문입니다.
참고 자료
- Keep GitHub Repository
- Keep Documentation Index
- Docker Deployment
- Kubernetes Architecture
- Alert Evaluation Engine
- Fingerprints
- Deduplication
- Extraction
- Mapping
- CEL
- Providers Overview
- Adding a new Provider
- Provider Methods
- Workflows Overview
- Secret Store
- Authentication Overview
- Monitoring
- Stress Testing
- Provisioning Overview
