이번에 공부할 주제는 Redis 입니다.
Redis 프로젝트 때 다뤄보긴 했으나 이미 세팅이 되어 있는것을 하였기 때문에 실질적으로 아는게 없습니다. 이참에 Redis를 공부하고자 합니다.
그리고 [우아한테크세미나] 191121 우아한레디스 by 강대명님 기반으로 공부를 했기 때문에 많은 내용들이 참고 되고 있습니다.
전 Redis를 심도 있게 다루지 않았으므로 자세한 내용을 듣고 싶다면 링크 로 들어가주시면 보다 설명을 잘 해주실겁니다.
또한 한번만 작성하고 말것이 아니라 공부하면서 해당 정보를 업데이트 해볼 생각입니다.
NoSQL
Redis를 공부하는데 앞서서 NoSQL의 한 종류 입니다.
NoSQL이란 무엇일까?
NoSQL(원래 의미: non SQL 또는 non relational)[1] 데이터베이스는 전통적인 관계형 데이터베이스 보다 덜 제한적인 일관성 모델을 이용하는 데이터의 저장 및 검색을 위한 매커니즘을 제공한다. NoSQL 데이터베이스는 단순 검색 및 추가 작업을 위한 매우 최적화된 키 값 저장 공간으로, 레이턴시와 스루풋과 관련하여 상당한 성능 이익을 내는 것이 목적이다.
출처: https://ko.wikipedia.org/wiki/NoSQL
기존 관계형 데이터베이스 시스템인 RDBS와 반대되는 개념으로 비관계형 데이터베이스 입니다.
데이터베이스 분산처리, 빠른쓰기, 데이터의 안정성등 빠른 퍼포먼스를 내기 위해 사용되는 것이다.
NoSQL 종류
key-Value 형
- 특정 데이터에 대해서 key/value 형태로 저장하는 데이터로 구현하기 쉬우나 value의 일부를 읽거나 업데이트에는 비효율적이다.
- 종류 : Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB, Amazon SimpleDB, Riak
Column family 형
- 여러 서버에 분산된 수많은 데이터를 저장,처리 하기위해 만들어짐
- key-value형 처럼 Key를 사용하지만 key-value형과 다르게 여러개의 컬럼을 가리키고 있고
컬럼은 컬럼 패밀리에 따라 정렬된다. - 종류 : Cassandra, HBase
Document DB 형
- 기본적으로 key-value와 비슷함
- document : 많은 key-value collection들의 collection
- 반 정형화된 document들이 JSON과 같은 포멧으로 저장
- 종류 : CouchDB, MongoDb
Graph 형
- SQL은 Row, Column 기반의 테이블과 정형화된 구조를 가짐
- SQL 대신 유연한 graph model을 여러 서버들에 확장할 목적으로 사용 가능
- DB 조회는 데이터 모델에 기반함
- 종류 : Neo4J, InfoGrid, Infinite Graph
참조 : https://subokim.wordpress.com/2011/05/31/nosql-db-four-type/
Redis?
이중 우리가 공부할 redis는 key-value 형태이다.
Redis의 설명은 다음과 같다.
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
출처 : https://redis.io/
in-memory 데이터 구조 , cache와 message 브로커등 특정 몇개의 단어가 눈에 띕니다.
특징
-
In-Memory Data Structure Store
- 디스크가 아닌 메모리 기반
- In-Memory Cache: 캐시 방식을 통해 DB Read의 부하를 감소시키는 방식
-
Open 소스 (BSD 3 License)
-
NoSQL & Cache 솔루션이며 메모리 기반으로 구성
-
여러대의 서버 구성 가능
-
지원되는 데이터 구조
- Strings, sets, sorted-set, hashes, list
- Hyperloglog, bitmap, geospatial index,
-
성능은 서버에 따라 다르나 초당 2만 ~ 10만회 수행
참조 : https://www.youtube.com/watch?v=mPB2CZiAkKM / https://goodgid.github.io/Redis/
Cache를 왜 사용하는가?
Cache : 나중의 요청에 대한 결과를 미리 저장하였다가 빠르게 서비스를 해줄수 있음
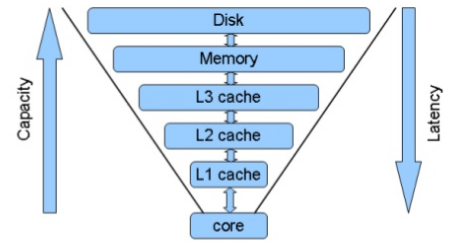
보통 DB들은 CRUD시 DISK에 저장이 되고 있습니다. 많은 용량을 저장할수 있다라는 장점이 있으나 그만큼 소요시간이 많이 걸립니다. 그에 반해 Cache는 메모리를 이용하므로 결국 Cache는 빠른 속도를 위해서 사용하게 되는겁니다
Collection
- Redis 는 기본 형태로 key-value로 데이터를 저장함
- key와 관련된 커멘트
- EXIST <key] : 해당 key가 존재하는지 확인
- DEL <key1]<key2]..... : key 삭제
- TYPE <key] : key의 value가 어떤 데이터 타입을 사용하는지를 반환
- SCAN <crusor] <match patten] <count] : key의 목록을 커서 단위로 가져옴
참조 : https://sjh836.tistory.com/178
사용가능한 데이터 구조

- Strings : key-value형 구조
- 단일 key
- Set : <key> <value>
- Get : <key> <value>
- 멀티 key
- mset <key1> <value1> <key2><value2> ...
- mget <key1> <key2> .....
- 단일 key
- List
-
기본 사용법 (insert)
- Lpush <key> <A>
-> Key : (A) - Rpush <key> <B>
-> Key : (A,B) - Lpush <key> <C>
-> Key : (C,A,B) - Rpush <key> <D,A>
-> Key : (C,A,B,D,A)
- Lpush <key> <A>
-
기본 사용법 (pop)
-
Key : (C,A,B,D,A)
-
LPOP <key>
-> POP : C, key: (A,B,D,A) -
RPOP <key>
-> POP : A, key: (A,B,D)
-
-
blpop, brpop
- 데이터가 없는 경우누가 데이터를 push하기 전까지 계속 대기
-
- Set
- 기본 사용법
- SADD <Key> <value>
-> 해당 key에 대한 value가 이미 존재하는 경우 추가되지 않는다. - SMEMBERS <key>
-> 모든 value를 돌려줌 - SISMEMBER <Key><value>
-> value가 존재하면 1, 없으면 0을 리턴
- SADD <Key> <value>
- 기본 사용법
- Sorted-set
- 기본 사용법
- ZADD <key> <score><value>
-> Key에 대한 value가 이미 존재하면 Score로 변경된다. - ZRANGE <Key> <StartIndex>
-> 해당 index 범위 값을 모두 돌려줌 ex) Zrange testkey 0-1 -> 모든 범위를 가져옴
- ZADD <key> <score><value>
- 특이사항
- 유저 랭킹보드로 사용할수 있음
-> select from rank order by score limit 50,20 = zrange rank 50,70
-> select from rank order by socre desc limit 50,20 = zrevrange rank 50,70
- 유저 랭킹보드로 사용할수 있음
- 기본 사용법
- hash : Key 밑에 sub key로 해서 존재하는 형태
- 기본 사용법
- Hmset <key> <subkey1><value1><subkey2><value2>
- Hgetall <key>
-> 해당 key의 모든 subKey,value 를 가져옴 - Hget <key> <subkey>
- Hmget <key><subkey1><subkey2>......
- 기본 사용법
- 특이사항 : 하나의 컬랙션에 너무 많은 아이템을 담으면 좋지 않음
=> 10000개 이하 몇천개 수준으로 유지하는 것이 좋음
Expire
- 메모리는 한정적인 경우가 많으므로 대부분 key에 Expire를 설정할것을 권장
- 동일한 key가 들어오는 경우 timeout이 재설정이 됨
- Expire는 collection의 각 item에 개별적으로 걸리지 않고 전체 Collection에 대해서만 걸림
-> 즉 해당 10000개에 아이템을 가진 collection이 expire이 설정되어 있다면 해당 시간 이후에 10000개의 아이템이 모두 삭제됨
Redis 운영
- 메모리 관리를 잘하자
- Redis는 In-Memory Data Store
- Physical Memory를 사용할 경우 문제가 발생할수 있음
-> swap이 있다면 swap 사용으로 해당 메모리 page 접근시 마다 latency가 발생
-> swap이 없다면 Max memory를 설정하도 이보다 더 사용할 가능성이 큼 - Rss값을 주기적으로 모니터링 해야함
- 많은 업체가 현재 메모리를 사용해서 swap을 하고 있다는 것을 모르는 경우가 많음
- 큰 메모리를 사용하는 instance 하나 보다는 여러개의 적은 메모리를 사용하는 instance 가 안전함
- Redis는 메모리 파편화가 발생할수 있음
-> 4.xx 부터 메모리 파편화를 줄이도록 jelloc에 힌트를 주는 기능이 추가 되었으나 jemalloc 버전에 따라서 다르게 동작할수 있음
-> 3.xx 인경우 실제 사용되는 메모리는 2GB로 보고 되지만 11G의 RSS를 사용하는 경우가 자주 발생할수 있음 - 메모리가 부족하는 경우 다음과 같이 조치 할수 있음
- Cache in Cash !!!
-> 좀더 메모리 많은 장비로 Migration
-> 메모리가 빡빡하면 Migration 중에 문제가 발생할수도 ...... - 있는 데이터 줄이기
-> 데이터를 일정 수준에서만 사용하도록 특정 데이터를 줄임
-> 다만 이미 swap을 사용중이라면 프로세스를 재시작 해야함 - 기본적으로 Collection 들은 다음과 같은 자료 구조를 사용
- Hash -> hashTable을 이용
- Sorted set -> Skiplist, HashTable을 이용
- set -> HashTable 이용
- 해당 자료구조들은 기본적으로 메모리를 많이 사용함
-> Ziplist를 이용할 것 (단 속도는 느려짐)
- Cache in Cash !!!
- O(N) 관련 명령어는 주의하자
- Redis 는 Single Threaded 임 (Redis Server는 multi Thread)
- (질문) 그러면 Redis는 동시에 여러 개의 명령을 처리할수 있을까?
- 참고로 단순한 get/set의 경우 초당 10만 tps 이상 가능 (cpu 속도에 영향을 받음)
- Packet으로 하나의 Command가 완성되면 process Command에서 실제로 실행됨
- 대표적인 O(N) 명령어
- Keys
- FLUSHALL , FLUSHDB
- Delte Collections
- Get All Collections
- 대표적인 사례
- key가 백만개 이상인데 확인을 위해 Keys 명령어를 사용하는 경우
-> 모니터링 스크립트가 1초에 한번씩 Key를 호출하는 최악의 상황 발생 ... - 아이템이 몇만개가 든 hash, sorted set, set에서 모든 데이터를 가져오는 경우
-> 예전의 Spring security oauth Redis TokenStore
- key가 백만개 이상인데 확인을 위해 Keys 명령어를 사용하는 경우
- keys 는 어떻게 대체할 것인가?
- Scan 명령을 사용하는 것으로 하나의 긴 명령을 짧은 여러번의 명령으로 대체 가능
- Collection의 모든 item들을 가져와야 할 때?
- Collection의 일부만 가져 오거나 ....
- 큰 Collection을 작은 여러개의 Collection으로 나누어 저장
-> ex) Userranks -> Userrank1, Userrank2, Userrank3
-> 하나당 몇천개 안쪽으로 저장하는게 좋음
- Spring security oauth RedisTokenStore 이슈
- Access Token의 저장을 List(O(N)) 자료구조를 통해서 이루어짐
- 검색, 삭제시에 모든 item을 매번 찾아봐야 함
- 검색, 삭제시에 모든 item을 매번 찾아봐야 함
-> 100만개쯤 되면 전체 성능에 영향을 미침
-> 현재는 Set(0(1))을 이용해서 검색, 삭제를 하도록 수정되어 있음
- Redis 는 Single Threaded 임 (Redis Server는 multi Thread)
- Replication
- 기본적으로 master / slave 구조
- Async Replication
-> Replication Lag가 발생할수 있음 - 'Replicaof' 명령어 이용 가능 (5.x 이상) or 'slaveof' 명령으로 설정 가능
- DBMS으로 보면 statement replication이랑 유사
- Replication 설정 과정
- Secondary에 replicaof or slaveof 명령 전달
- Secondary는 Primary에 sync 명령을 전달
- Primary는 현재 메모리 상태를 저장하기 위해 fork
- Fork 한 프로세스는 현재 메모리 정보를 disk에 dump
- 해당 정보를 Secondary에 전달
- Fort 이후의 데이터를 secondary에 계속 전달
- 주의점
- Replication 과정에서 fork 가 발생하므로 메모리 부족이 발생할수 있음
- Redis-cil --rab 명령은 현재 상태의 메모리 스냅샷을 가져오므로 같은 문제를 발생시킴
- AWS 나 클라우드 Redis 는 좀 더 다르게 구현되어서 좀 더 해당 부분이 안정적임
- 많은 대수의 Redis 서버가 Replica를 두고 있다면
- 네트워크 이슈, 사람의 작업으로 인해 동시에 Replication이 재시도 되도록 하면 문제 발생
- ex) 같은 네트워크 30GB를 사용하는 Redis master 100대 정도가 리플리케이션을 동시에 재시작하는 경우 어떤 문제가 발생할까?
- 권장 설정 TIP!!!!
- MaxClient 설정 50000
- ROB/AOF 설정 off -> 성능 / 안정성이 높아짐
- 특정 commands disable (Keys 등)
-> AWS의 ElasticCache는 이미 하고 있음 - 전체 장애의 90% 이상이 keys와 save 설정을 사용해서 발생
-> 적절한 Ziplist 설정 필요 - Redis 데이터 분산
- 데이터의 특성에 따라서 선택할수 있는 방법이 달라짐
Redis 데이터 분산 방법
- Application
- Consistent hasing -> twemproxy를 사용하는 방법 (쉽게 사용 가능)
- 서버가 추가 되거나 빠지더라도 해당 서버에 있는 데이터들만 리벨런싱이 일어남
- 1,2,3번 서버 중에 2번이 죽는 경우 2번에 있는 데이터들만 이용
- Sharding
- Range
- 특정 범위를 정하고 해당 Range에 속하면 해당 부분에 저장
- 서버의 상황에 따라서 노는 서버가 발생
- 범위로 지정되어 있기 때문에 한번 설정시 바꾸기 어려움
- 확장은 쉬움
- Modular
- N % K (서버 수) 로 서버의 데이터를 결정
- Range보다 균등하게 분배할 가능성이 높다
- 서버를 증설시 배수로 증설해야 하는 단점이 있음
- indexed
- 해당 key가 어디에 저장되어야 할지 관리 하는 서버가 따로 존재
- 상대적으로 제일 균등하게 분배할 가능성이 높음
- 관리서버가 죽을 경우 모든 서버에 장애 발생
- Range
- Consistent hasing -> twemproxy를 사용하는 방법 (쉽게 사용 가능)
- Redis Cluster
- Hash 기반으로 slot 16384로 구분
- Hash 알고리즘은 CRC16을 사용
- 특정 Redis 서버는 이 slot range를 가지고 있고, 데이터 마이그레이션은 이 slot 단위의 데이터를 다른 서버로 전달하게 된다.(migrateCommand 사용)
- 장점
- 자체적인 Failover 기능
- slot 단위의 데이터 관리
- 단점
- 메모리 사용량이 많아짐
- 마이그레이션 자체는 관리자가 시점을 결정 해야 함
- 라이브러리 구현 필요
- Hash 기반으로 slot 16384로 구분
Redis FailOver
- coordinator 기반
- Zookeeper, etcd, consul 등의 Coordinator 사용
- health checker
- Coordinator가 api서버에 Primary notify 해중
- 해당 기능을 이용하도록 개발이 필요하다.
- VIP 기반
- API 서버는 가상 IP만 접속하고
- health checker는 가상 IP를 가지고 1번서버에 부여한 후 1번 서버가 죽으면 2번 서버에 할당함
- DNS 기반
- VIP 기반과 비슷함
- VIP/DNS 특징
- 클라이언트에 추가적인 구현 필요
- VIP 기반은 외부로 서비스를 제공하는 서비스 업체에 유리
- DNS 기반은 DNS Cache를 관리해야함
Monitor Factor
- Redis info를 통한 정보
- RSS
- Used Memory
- Connection 수
- 초당 처리 요청 수
- System
- CPU
- Disk
- Network rx/tx
- cpu가 100% 인경우
- 처리량이 많다면
- cpu 좋은 서버로 이전
- 실제 cpu 성능에 영향을 받음
- 그러나 단순 get/set은 초당 10만번 이상 처리 가능
- O(N) 계열의 특정 명령이 많은 경우
- Monitor 명령을 통해 특정 패턴을 파악하는 것이 필요
- Monitor를 잘못 쓰는 경우 부하로 해당 서버에 더 큰 문제 발생 야기
- 처리량이 많다면
결론
- Redis는 기본적으로 매우 좋은 툴
- 그러나 메모리를 빡빡하게 쓰는 경우 관리 어려움
- ex) 32GB장비에 24G이상 사용하는 경우 장비 증설을 고려 하는 것이 좋음
- Write가 Heavy한 경우 마이그레이션 또한 주의해야함
- Redis를 Cache로 쓰는 경우
- 레디스가 문제가 있을때 DB등의 부하가 어느 정도 증가하였는지 확인 필요
- Consistent Hasing도 부하를 아주 균등하게 나누지는 않음
- Redis를 Persistent Store로 쓰는 경우
- 무조건 Primary / Secondary 구조로 구성이 필요함
- 메모리를 절대로 빡빡하게 사용하지 말것
- 정기적인 마이그레이션 필요
- ROB/AOF가 필요하는 경우 Secondary에서만 구동
