주간 학습 정리 목표
- 주간 학습 정리의 목표는 한 주간 공부했던 내용을 까먹지 않기 위함
- 주차별 내용에 있어 좋았던 부분과 어려웠던 부분을 위주로 정리하기
- 최대한 강의에 나의 생각 넣어 이해하기
Pytorch
페이지가 좀 길어 2개로 나눠 작성했습니다. 이전 내용이 궁금하시다면 해당 링크를 참조해주세요. 링크
Pytorch에 대한 전반적인 방식이 이해되었다면 사용자입장에서 공부를 시작하기 전 알아두면 좋을게 있을까요?
💡Pytorch 특징
🔫 모듈은 CamelCase 함수는 소문자로 구성
파이토치 예제를 많이 읽다보면 똑같은 함수 같은데 다른 경우가 많습니다.
이는 함수와 객체에 대한 차인데 간단한 예제를 보여드리겠습니다.
import torch
from torch import nn
# 본 구문은 실행 시키는 것에 큰 의미가 없습니다. 읽어만 봐주셔도 아래 내용이 이해가 됩니다.
torch.tensor(10)
torch.Tensor()
case_a = nn.Linear()
case_b = nn.functional.linear(INPUT_SIZE)보시는 것과 같이 똑같이 구현됨에도 불구 하고 왜 같은 함수를 여러개 구현했을까?
명확한 이유를 알 수는 없었으나 큰 차이점은 존재했습니다.
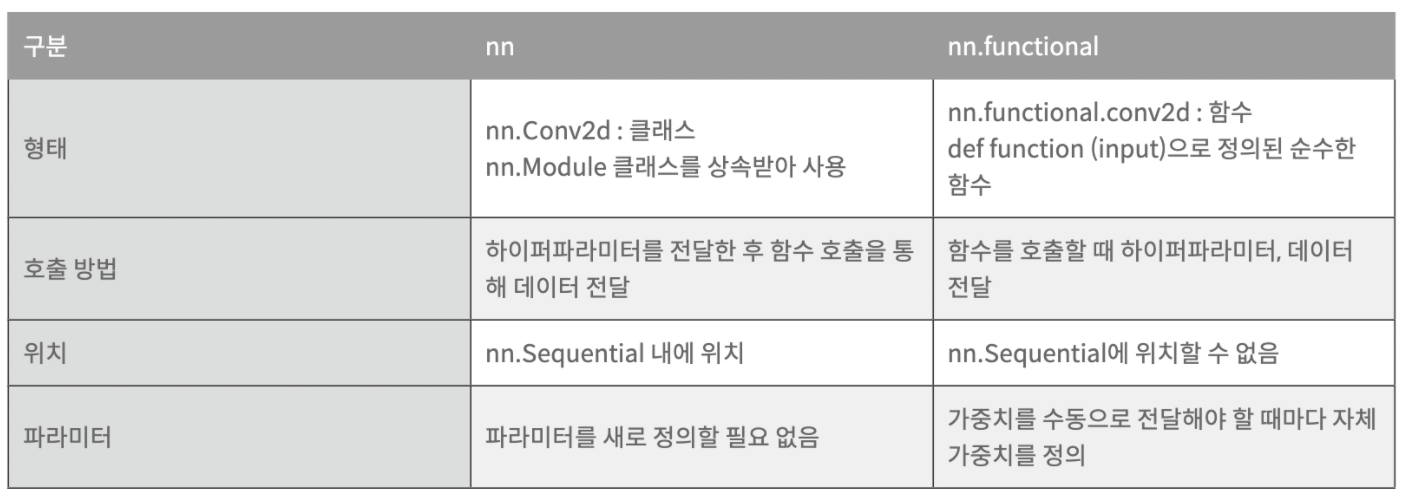
1. 자동미분을 지원하기에 Class형태로 Layer구성시 파라미터 관리가 편하다.
2. 하지만 호출 방법과 메모리 차지라는 단점이 존재하기 때문에 Grad가 필요한 파라미터를 효율적으로 관리할 필요가 있습니다.
# requires_grad : 그래프의 값을 history에 저장하는 법, 즉 미분에 대상이 되는 텐서인지
# 입력하면 된다.
import torch
a = torch.arange(10,requires_grad=True)
a>>>tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])💡Module Architecture
Overview : Pytorch 모델 예제마다 조금씩 다르겠지만 Pytorch프로젝트를 한다고 가정하면 아래와 같은 5가지의 개념만 잘 인지하고 있으면 모두 이해 할 수 있습니다.
🔫 Dataset
- 데이터 입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따른 다른 입력 정의
유의점
- 데이터 형태에 따라 각 함수를 다르게 정의함
- 모든 것을 데이터 생성 시점에 처리하지 않는다.(전처리를 말함)
- Tensor 변환 같은 경우도 학습에 필요한 시점(transform에서)에 변환 한다.
- 데이터 셋에 대한 표준화된 처리방법 제공할 필요가 있다.
- 후속 연구자 혹은 동료에게 빛과 같은 존재가 된다.
- (NLP한정)HuggingFace등 표준화된 라이브러리를 사용할 수 있다.
import torch
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self,text, labels) -> None:
super().__init__()
self.labels = labels
self.data = text
def __len__(self):
return len(self.labels)
def __getitem__(self, index):
label = self.labels[index]
text = self.data[index]
sample = {'Text':text,'Class':label}
return sample
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)# __getitem__ 함수는 []이걸 말한다.(이런 걸 매직 매서드라 한다.)
# 매직 매서드 : __add__ 'a+b'-> __sub__(a,b) 'a-b'
MyDataset[1]
>>>
{'Text': 'Amazing', 'Class': 'Positive'}🔫 DataLoader
- 데이터의 Batch를 생성해주는 클래스
- 학습직전(GPU feed전) 데이터의 변환을 책임
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민이 필요
# generator
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
>>>
{'Text': ['Amazing', 'Unhapy'], 'Class': ['Positive', 'Negative']}
# 참고로 DataLoader도 오버라이딩 가능하다잉
MyDataLoader = DataLoader(MyDataset, batch_size=3, shuffle=True)
for dataset in MyDataLoader:
print(dataset)
>>>
{'Text': ['Glum', 'Sad', 'Happy'], 'Class': ['Negative', 'Negative', 'Positive']}
💡 데이터로더는 generator랑 동일하게 보되 여러 파라미터로 학습용으로 데이터를 불러오고 싶을때(배치 단위 혹은, shape조정, random sampling 등) 효과적이다.
따라서 다양한 파라미터를 알면 좋기에 데이터로더의 파라미터를 정리한 좋은 글이 있어 첨부합니다. https://subinium.github.io/pytorch-dataloader/
그중 sampler와 collate_fn은 기억해두는 것이 좋습니다.
- sampler : 데이터 인덱스 처리 방법
- collate_fn : 가변길이가 많은 텍스트 데이터 처리시 필요한 패딩 함수 넣는 곳
🔫 transform
- 입력받은 데이터를 변환 또는 증강하는 곳
- 대부분 데이터 셋의 self.transform으로 함수를 활성화 시키는 구조
# 앞선 예시에 transform을 추가 해봤습니다.
import torch
from torch.utils.data import Dataset, DataLoader
import albumentations as A # transform 모듈
img_transform = A.Compose([
A.Resize(CFG['IMG_SIZE'],CFG['IMG_SIZE']),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, always_apply=False, p=1.0),
ToTensorV2()
])
class CustomDataset(Dataset):
def __init__(self,img, labels,transform) -> None:
super().__init__()
self.labels = labels
self.data = img
# 앞서 정의한 함수 적용
self.transform = img_transform
def __len__(self):
return len(self.labels)
def __getitem__(self, index):
# 매직 매서드 []를 호출할 때 transform도 같이 호출 되게끔
label = self.labels[index]
img = self.data[index]
# transform 이 존재한다면
if self.transform:
img = self.transform(image = img)
sample = {'img':img,'Class':label}
return sample
img = None # 해당 부분에 matrix형태의 이미지 값을 넣어 주세요
labels = ['cat', 'dog', 'lion']
MyDataset = CustomDataset(text, labels,img_transform)# __getitem__ 함수는 []이걸 말한다.(이런 걸 매직 매서드라 한다.)
# 매직 매서드 : __add__ 'a+b'-> __sub__(a,b) 'a-b'
MyDataset[1]
>>>
{'Text': #transform 된 이미지,
'Class': 'cat'}🔫 model
- pytorch는 nn.Module을 상속받아 내장되어 있는 파라미터나 Neural Network등을 사용합니다.
- Input, Output, Forward, Backward 을 정의하게 되는데 pytorch의 tensor가 자동미분(AutoGrad)를 지원하기 때문에 Backward는 오버라이딩 하지 않는 경우가 많습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class Mylinear(nn.Module):
def __init__(self,in_features,out_features,bias = True) -> None:
super(Mylinear,self).__init__() self.parameters
self.in_features = in_features # 7
self.out_features = out_features # 12
self.weights = nn.Parameter(torch.randn(in_features,out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self,x):
# 사용자 정의 함수 But : 동적 프로그래밍이다 보니 선언시 바로 실행되는 특징이 존재
return torch.mm(x,self.weights)+self.bias
X = torch.randn(5,7) # input :X : (5,7)
linear = Mylinear(7,12) # parameter :W : (7,12) :weight의 차원이 된다.
# output :Y : (5,12)
for value in linear.parameters():
print(value)
>>>
Parameter containing:
tensor([[ 1.2205, -0.0115, 1.0301, -1.9342, 0.0499, 0.3176, 0.2620, 0.1608,
-1.0611, -0.1616, -0.8317, 0.1801],
....
[ 0.7492, -2.7902, -0.5989, 1.1190, -0.5898, 1.0021, 0.2523, -0.7510,
-0.9999, -0.7355, -1.7158, 0.7850]], requires_grad=True)
Parameter containing:
tensor([-1.4946, 1.4046, 0.1370, 0.0220, 0.1063, -0.1623, 0.2309, -0.0128,
-0.9325, 0.7159, 0.8920, -0.3990], requires_grad=True)
💡참고로
super().init()
- super 명령어는 이런 상속 관계에서 상속의 대상인 부모 클래스를 호출하는 함수입니다.
super()의 인자로는 두 개가 전달되며, 하위클래스의 이름과 하위클래스의 객체(object)가 필요합니다.
→ 부모 클래스의 init을 참조하고 싶을때
layer에 들어갈 Linear를 직접 만들어 본것 해당 코드에 Parameter는 최적화 할때 선언하다 보니 표현법만 잘 알아 두자.
🔫 train
- 데이터 셋과 모델 작업이 완료 했으면 애지중지 만든 모델을 한번 실행해 보고 싶다고 많이 느끼실 겁니다.
- train은 지정한 epoch를 batch만큼 부르면서 모델에 적용해 보게 되는데 아래와 같이 5가지만 명심하면 진행할 수 있습니다.
- grad 초기화 : optimizer에 지정된 값을 epoch 마다 초기화 해야합니다.
- yhat 생성 : 만든 모델로 예측값 계산
- loss 값 계산 : yhat과 y를 비교해가며 차이를 계산
- loss 미분 : 최적 방향 계산입니다.
- loss 업데이트 : 경사하강법으로 쉽게 말하면 최적값을 찾도록 step을 밟는 과정이라 이해하시면 됩니다.
from torch.autograd import Variable
inputs = Variable(torch.from_numpy(x_train)).to(mps_device)
labels = Variable(torch.from_numpy(y_train)).to(mps_device)
## Train 실행
for epoch in range(epochs):
optimizer.zero_grad() # 1. grad 초기화
outputs = model(inputs) # 2. yhat 생성
loss = criterion(outputs,labels) # 3. loss값 계산 criterion:사용자 정의 함수
# print(loss)
loss.backward() # 4. loss미분
optimizer.step() # 5. loss업데이트 weight 갱신
print(f'epoch : {epoch}, loss : {loss.item()}')회고
두런두런
이번 주차에서는 두런두런이라는 클래스를 처음 시작했다.
💡두런두런 이란?
Do learn Do run 으로 러닝마스터이신 변성윤 마스터님께서 학습을 하는데 있어 페이스 메이커 처럼 동기부여를 해주는 자리였습니다.
두런두런을 회고하는데 값자기 왜 말하냐 난데 없을 수도 있겠지만 이번 주차 많은 생각을 하게 한 것은 강의 내용이 아니라 두런두런이라 생각해서 입니다.
💡Gap year : 휴직을 하면서 커리어에 대한 또는 진로에 대한 고민을 가지는 시간
군 전역 후 인공지능에 관심이 많이 생겨 Gap year없이 무턱대고 달렸습니다. 그럼에도 불구하고 이번 부스트캠프AI를 하면서 내가 그동안 아무것도 몰랐구나도 느끼는 시간이었습니다. 내가 인공지능을 왜 좋아했고 어떤 커리어를 원하는지 항상 애매했었는데. 마스터님께서 완벽하게 정리해주시고 인공지능에 관심있는 분이라면 가졌을 고민들을 공유해주시는 시간이 길게 보면 나를 더 나아가게 한다고 느꼈던 시간이었습니다.
물론 많이 바쁘지만 주말을 활용해 인공지능에 대한 내 생각도 정리해 보면서 어떤 직무가 어떤 특색이 있는지 정리해보고 공유하는 시간을 가져볼까 합니다. 늦어질수도 있겠지만 반드시 공유해 같이 고민하는 시간을 가져보아요.
긴 글 읽어 주셔서 감사합니다.
