"문자열 압축"
문제 설명
데이터 처리 전문가가 되고 싶은 "어피치"는 문자열을 압축하는 방법에 대해 공부를 하고 있습니다. 최근에 대량의 데이터 처리를 위한 간단한 비손실 압축 방법에 대해 공부를 하고 있는데, 문자열에서 같은 값이 연속해서 나타나는 것을 그 문자의 개수와 반복되는 값으로 표현하여 더 짧은 문자열로 줄여서 표현하는 알고리즘을 공부하고 있습니다.
간단한 예로 "aabbaccc"의 경우 "2a2ba3c"(문자가 반복되지 않아 한번만 나타난 경우 1은 생략함)와 같이 표현할 수 있는데, 이러한 방식은 반복되는 문자가 적은 경우 압축률이 낮다는 단점이 있습니다. 예를 들면, "abcabcdede"와 같은 문자열은 전혀 압축되지 않습니다. "어피치"는 이러한 단점을 해결하기 위해 문자열을 1개 이상의 단위로 잘라서 압축하여 더 짧은 문자열로 표현할 수 있는지 방법을 찾아보려고 합니다.
예를 들어, "ababcdcdababcdcd"의 경우 문자를 1개 단위로 자르면 전혀 압축되지 않지만, 2개 단위로 잘라서 압축한다면 "2ab2cd2ab2cd"로 표현할 수 있습니다. 다른 방법으로 8개 단위로 잘라서 압축한다면 "2ababcdcd"로 표현할 수 있으며, 이때가 가장 짧게 압축하여 표현할 수 있는 방법입니다.
다른 예로, "abcabcdede"와 같은 경우, 문자를 2개 단위로 잘라서 압축하면 "abcabc2de"가 되지만, 3개 단위로 자른다면 "2abcdede"가 되어 3개 단위가 가장 짧은 압축 방법이 됩니다. 이때 3개 단위로 자르고 마지막에 남는 문자열은 그대로 붙여주면 됩니다.
압축할 문자열 s가 매개변수로 주어질 때, 위에 설명한 방법으로 1개 이상 단위로 문자열을 잘라 압축하여 표현한 문자열 중 가장 짧은 것의 길이를 return 하도록 solution 함수를 완성해주세요.
제한사항
- s의 길이는 1 이상 1,000 이하입니다.
- s는 알파벳 소문자로만 이루어져 있습니다.
입출력 예
s result "aabbaccc" 7 "ababcdcdababcdcd" 9 "abcabcdede" 8 "abcabcabcabcdededededede" 14 "xababcdcdababcdcd" 17
입출력 예에 대한 상황
입출력 4번을 예로들면
문자열을 2개 단위로 자르면 "abcabcabcabc6de" 가 됩니다.
문자열을 3개 단위로 자르면 "4abcdededededede" 가 됩니다.
문자열을 4개 단위로 자르면 "abcabcabcabc3dede" 가 됩니다.
문자열을 6개 단위로 자를 경우 "2abcabc2dedede"가 되며, 이때의 길이가 14로 가장 짧습니다.
문제 풀이
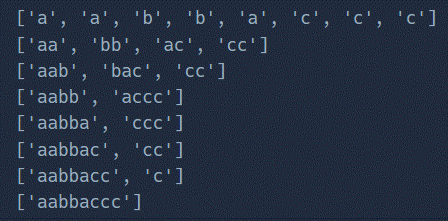
입력예시의 1번예시에서 aabbaccc는 다음과 같이 쪼갤 수 있습니다.
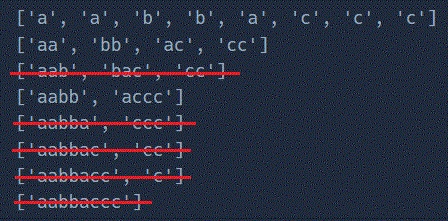
하지만 문자열 길이의 반 보다 큰 개수로 쪼갤시에 짝이 안맞는 경우가 생깁니다. 그래서 아래 사진과 같이 반 이상의 개수로 잘랐을때는 모두 의미가 없기에 그 전까지만 리스트에 넣어 확인하는 것이 효율적입니다.
코드
import re
def solution(s):
resultCount = [] # 압축한 사이즈 리스트
if len(s) <= 2: return len(s) # 문자열이 2이하일 때 문자길이 그대로 출력
for i in range(1,len(s)//2 + 1) : # 절반까지만 배열에 담기 위함
reList = re.sub('(\w{%i})'%i, '\g<1> ', s).split() # i만큼 단어 분리
count = 1 # 단어의 개수를 세기 위한 변수
result = [] # 최종적으로 모두 분리되어 개수처리 된 [2a,2b,a,3c]와 같은 형식인 리스트
for j in range(len(reList)):
if j<len(reList)-1 and reList[j] == reList[j+1]:
count += 1 # 현재 단어와 다음 단어가 같을 때 count증가
else:
if count == 1: # j>=len(reList) 일때
result.append(reList[j])
else: # 이미 중복된 값이 계속 나오다가 같지 않을 때
result.append(str(count) + reList[j])
count = 1 # 개수 초기화
resultCount.append(len(''.join(result))) # 개수화되어 분리된 단어를 합친후 길이 출력
return min(resultCount) 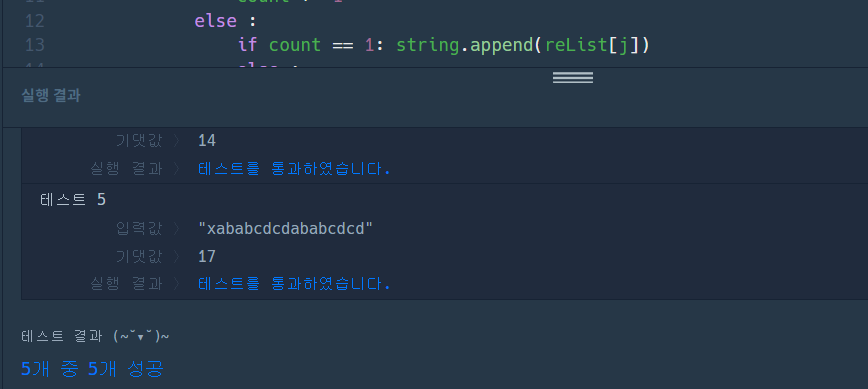
이 문제에서 가장 오래 고민했던 부분은 특정 개수만큼 단어를 분리시켜 리스트에 담는 부분이었습니다. 하지만 정규화 처리를 사용함으로써 코드가 매우 깔끔해졌습니다.
평소 사용하지 않던 Python으로 알고리즘 문제를 풀려하다보니 역대급으로 많은 시간이 소모됐네요.. 정규화 표현을 조금 더 공부해야겠습니다. 😥😣
-
re.sub('(\w{%i})'%i, '\g<1> ', s).split()
w->글자 i개를 하나의 g(group) 만들고'\g<1> '의 오른쪽에있는 띄어쓰기를 기준으로해서 문자를 나눠주기. -
re.sub
🔗 link ▼

참고
참고한 유튜브 링크 ▼
🎥 우리밋_woorimIT