정식연재 웹툰의 수가 비정식연재 웹툰의 수에 비해 매우매우 적어, 정확도만으로는 정확한 분류와 예측이 힘들었다. 따라서 분류의 명확성을 나타내는 AUC를 모델의 성능으로 선택하였다.
import
!pip install imbalanced-learn
import numpy as np
import pandas as pd
import sklearn
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score, roc_auc_score, roc_curve
import statsmodels.api as sm
import matplotlib.pyplot as plt
import time
from collections import Counter
from imblearn.under_sampling import RandomUnderSampler🔎 데이터 확인

# class imbalance 확인
y.sum()/len(y)
## 0.07203389830508475데이터 불균형이 매우 심한 것을 알 수 있다.
# titleId 칼럼 제거
webtoon.drop(["titleId"], axis=1, inplace = True)🌏 모델링
원핫인코딩
# contentGenre, typeGenre : one-hot encoding
webtoon = pd.get_dummies(data = webtoon, columns=['contentGenre'], prefix='contGenre')
webtoon = pd.get_dummies(data = webtoon, columns=['typeGenre'], prefix='typeGenre')언더샘플링 + 랜덤포레스트분류
accList = []
aucList = []
# X,y dataset 분리
X, y = webtoon.iloc[:,:-1], webtoon['isPublic']
# 4:3 언더샘플링
undersample = RandomUnderSampler(sampling_strategy=0.7, random_state=121818)
X_under, y_under = undersample.fit_resample(X, y)
for i in range(50): # 50번 수행
## train, test split
X_train_under, X_test_under, y_train_under, y_test_under = train_test_split(X_under, y_under, stratify=y_under, test_size=0.2, random_state=121818)
## 랜덤포레스트분류
rf = RandomForestClassifier(random_state=121818)
rf.fit(X_train_under, y_train_under)
## 정확도 acc
accList.append(rf.score(X_test_under,y_test_under))
## 오차행렬
y_pred = rf.predict(X_test_under)
cfmat = confusion_matrix(y_test_under, y_pred)
## auc
y_pred_proba = rf.predict_proba(X_test_under)[:,1] # -> 정식연재 승격 확률
auc = roc_auc_score(y_test_under, y_pred_proba)
aucList5.append(auc)
- 모델 성능 확인
AUC : 0.9285
ACC : 0.7812
confusion matrix :
-> 정식연재를 정식연재로 판단 10개, 정식연재를 비정식연재로 판단 8개, 비정식연재를 정식연재로 판단 1개, 비정식연재를 비정식연재로 판단 13개
변수 중요도
#변수 중요도 확인
feature_df = pd.DataFrame()
feature_df['feature'] = X.columns
feature_df['importance'] = rf_under.feature_importances_
feature_df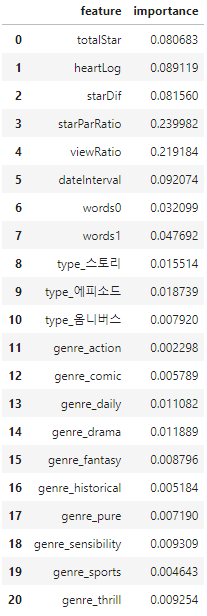
장르 변수들이 중요도가 매우 낮다. 그러나, 장르 변수를 제외하고 모델링한 결과는 성능이 더 안좋았다.
❗ 별점참여자수의 비율과 조회수의 비율이 타 변수들에 비해 중요도가 크게 나왔다. 정식연재로 승격될 확률은 유입독자들을 잘 유지하면 높아질 것으로 예상할 수 있었다.
🥂 느낀점
데이터 수집부터 전처리, 모델링을 직접 하려니 며칠을 밤을 샜는지 모르겠다..ㅠ 많이 부족한 실력으로 욕심은 많아서 고생을 좀 했지만, 모든 과정들을 이해하고 적용하는 것이 큰 공부가 되었다. 스스로 처음부터 끝까지 해냈다는 것이 뿌듯하다.
중간중간 생각만 하고 진행하지 못했던 부분들(ex. 댓글분석에서 단어 선택, 변수의 상관관계 확인)을 더 보완하여 더 멋진 프로젝트를 진행할 것이다!

열심히 노력하는 학생!