선행 이해:
1. mlp, nn 차이,개념
2. loss, activation, optimizer(SGD)
Gradient
learning rate 조절하는 기법
Annealing the learning rate (Decay)
1.
2.
3.
Regularization
목적: overfitting을 막기 위함(모델의 일반화성능을 높이는 것이 목적)
1. Data augmentation
2. Normalization, Standardization, Whitening
셋 다 입력값의 범위를 조정함으로써, 모델의 일반화성능을 높이기 위한 방법.
-
Normalization = 입력값(보통 픽셀값의 범위= 0~255)의 범위를 0~1로 조정.
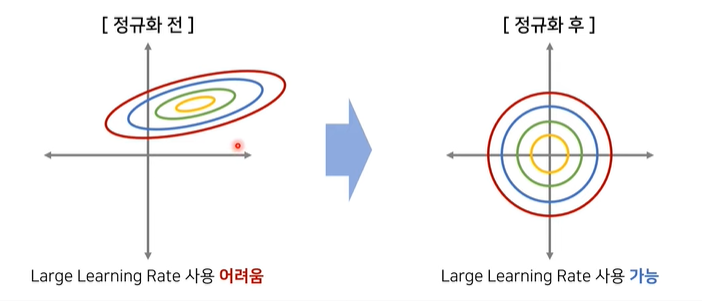
-
Standardization = 입력값의 범위가 가우시안 분포를 따르도록 조정.
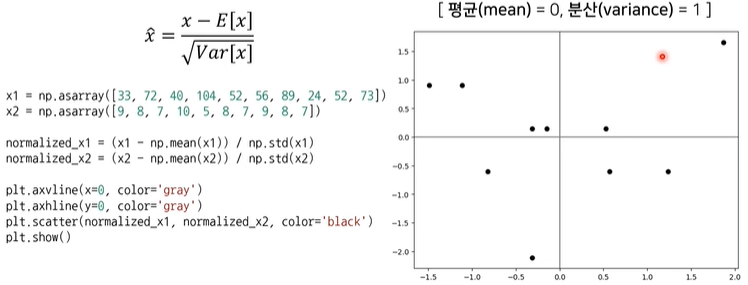
-
Whitening
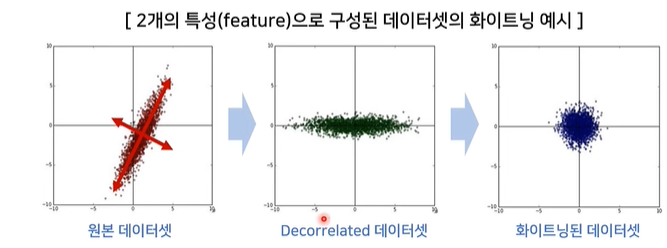
3. Dropout
4. Dropconnect
5. BatchNormalization **
Reference.
[paper]
1. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (https://arxiv.org/pdf/1502.03167.pdf, 2015)
2. How Does Batch Normalization Help Optimization ? (https://arxiv.org/pdf/1805.11604.pdf, 2018)
3. 배치 정규화(Batch Normalization) 꼼꼼한 딥러닝 논문 리뷰와 코드 실습
4. 배치 정규화 논문 리뷰 (Batch normalization)
(https://goodjian.tistory.com/entry/%EB%B0%B0%EC%B9%98-%EC%A0%95%EA%B7%9C%ED%99%94-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Batch-normalization?category=278632)
개념
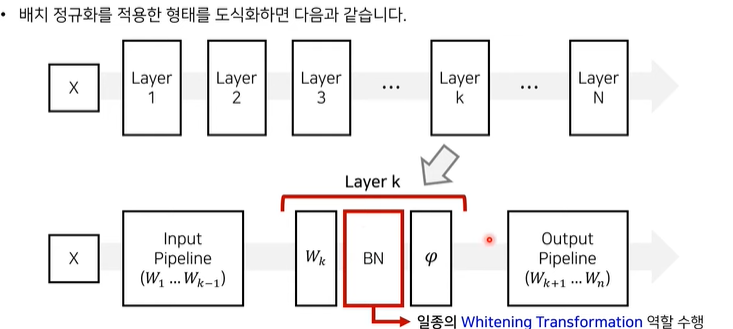
- 핵심 아이디어: Input layer의 입력값을 regularization하는 방법(Normalization, Standardization, Whitening) 외에도 Input layer 이후의 hidden layer의 입력값도 regularization할 수 있다면 어떻게 될까???
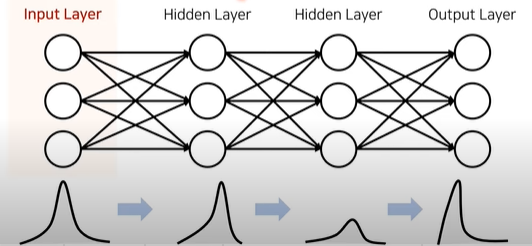
Input layer에서 데이터가 regularzation될 지라도, 그 다음 layer를 거쳐 형태가 달라질 수 있으므로 위와 같은 아이디어를 제안함.
장점
- 학습 속도를 빠르게
- 가중치 초기화(weight initialization)에 대한 민감도 감소 ?
- 모델의 일반화(regularization) 효과가 있음.
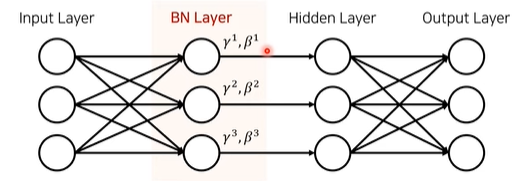
원리
- 한번 forward했을 때 이미지 64개를 이용했다고 하면, 그때 배치 사이즈 = 64
hidden layer의 dimension이 3이라 한다면, 각각의 dimension마다 파라미터를 가짐.
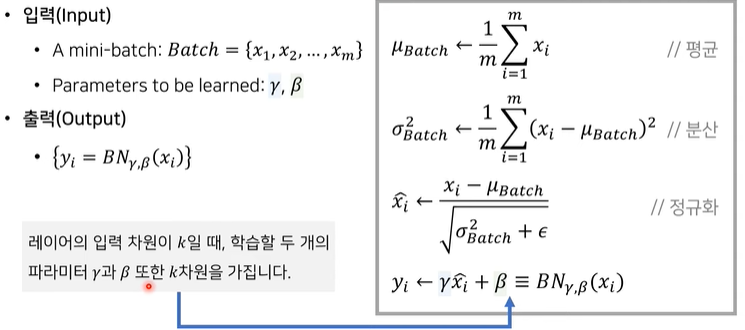
- 일반적인 normalization의 과정을 수행
- 평균을 구함.
- 분산을 구함
- 데이터에서 평균값을 빼고 분산과 입실론(0으로 나누는 것을 막기위해 임의로 더해주는 아주 작은 상수)로 나눠줌.
4. 중요 - 일반적으로 normalization이면 1~3과정에서 끝나지만, BatchNormalization은 학습할 때, 자동으로 데이터의 값을 조절해주는 감마와 베타를 사용함.
- 감마: scaling
- 베타: translation
- 감마, 베타를 사용하는 이유: 각 layer의 정규화로 activation function(ex. sigmoid function)의 영향력이 감소될 수 있는데, 이로 인해 모델이 선형적으로 데이터를 학습할 수 있는 문제를 방지함.
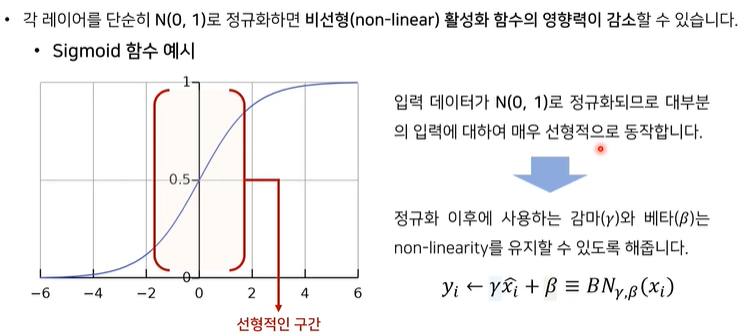
sigmoid = -2~2의 범위에서는 linear 한 형태에 가까움,
따라서 입력값의 범위가 0~1로 정규화되었다 가정할 때, 이 범위에선, 모델이 굉장히 선형적으로 동작할 수 있음.
결과
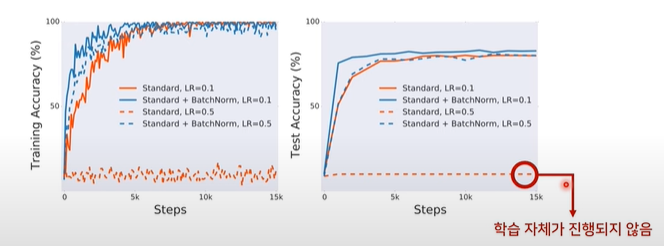
관련 용어
-
internal covariance shift
특정 layer를 거치며 input 값의 분포가 바뀌는 현상 -
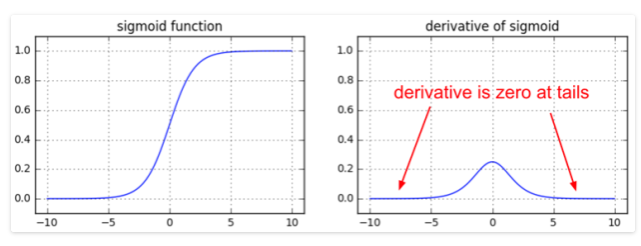
saturation ?
Weight 파라미터가 더 이상 학습되지 않는 현상
forward로 학습 후 back propagation단계에서, weight를 업데이트가 이뤄지는데, 이때 weight의 미분값이 0이 되면서 더 이상 업데이트가 이뤄지지 않을 때, saturation되었다고 한다.
아래 그림 참고.
6. Early stopping
7. Weight decay
8. Multi-Task Learning
9. L1, L2 Regularization **
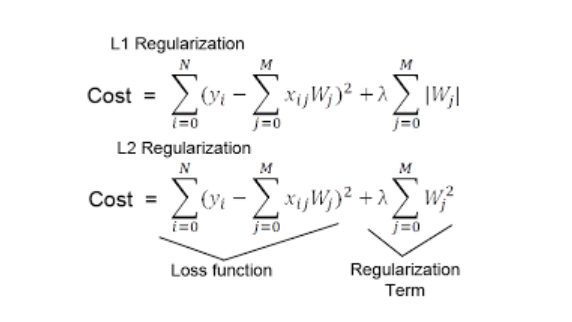
10. Ensemble model
