Learning rate
Gradient

Good and Bad Learning rate
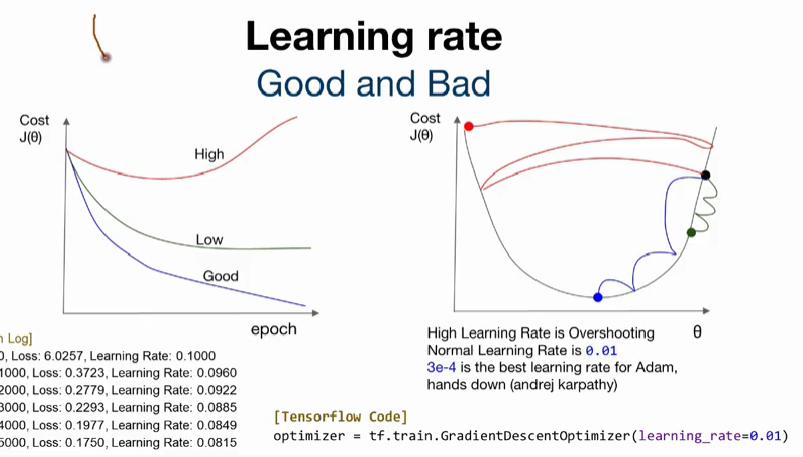
너무 높은(큰) Learning rate는 overshooting을 초래한다.
Annealing the learning rate (Decay) ***
learning rate를 조절하는 기법임. 여기엔 3가지 방법이 있음
- Step decay : N epoch or validation loss
- Exponential decay :
- 1/t decay :
[code]
learning rate = tf.train.exponential_decay(starter_learning_rate, global_step, 1000, 0.96, staircase)
tf.train.exponential_dacay / tf.train_inverse.time_decay
tf.tain_natural_exp_decay / tf.train.piecewise_constant
tf.train.polynomial_decay
Data preprocessing
= Feature Scaling
: 데이터의 값의 범위를 일정한 수준으로 맞추는 작업.
Standardization / Normalization

- Standardization
:서로 다른 범위의 변수들을 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 작업. - Normalization
: 서로 다른 범위의 변수들의 크기를 통일하기 위해 이를 변환하는 작업. 일반적으로 [0, 1] 범위의 분포로 조정.
Overfitting
학습하는 데이터에만 최적화된, 새로운 데이터가 입력되었을 때 올바르게 학습하지 못하는 현상.
해결방법
- 더 많은 학습 데이터 수집
커피(=변화량)를 물(=데이터)에 타는 상황을 가정했을 때, 물의 양을 더 많이 할 수록, 커피가 희석되는 것처럼
more data will helps to fix hugh variance.
- Feature 집합을 더 작게(=균일한 범위에 위치하도록)
학습에 의미없는(ex. 이상치 데이터)데이터를 제외.
데이터의 변량이 보다 밀집해 있는 데이터를 입력하거나, 데이터의 범위를 보다 의미있는 범위에 밀집하도록 함으로써, 모델이 학습을 좀 더 잘 할 수 있게 해줌.
- Feature 를 더 많이 두기.(단, 적절하게. 너무 늘리면 x)
1,2와 반대되는 방법으로, 모델이 너무 간단할 때, 학습의 의미가 없으므로 모델을 좀더 구체적으로 변형하는 방법.
hypothesis is too simple, make hypothesis more specefic (fixes hugh bias)
- Regularization
L2 Norm
