[D+3] 2025-09-22 (월요일) 회고록
😊 Liked (좋았던 점)
- 소프트웨어 공학에 대해서 공부했던 내용들이 다 잊혀졌거나 드문드문 기억 나는 수준이었는데, 오늘 관련 여러 이론들을 다시 배우면서 기억을 한번 상기하게 되어 좋았다.
- 마찬가지로 UML도 공부를 했었지만 기억이 잘 나지 않았었는데 오늘 실습과 함께 개념을 다시 잡으면서 기억을 강화할 수 있어 뿌듯했다.
- whimsical 웹사이트에서 유스케이스 다이어그램을 직접 그려보니 방향성을 더 잘 잡을 수 있었다.
💡 Learned (배운 점)
<<include>>와<<extend>>의 자세한 쓰임을 배웠다.<<include>>는 특정 유스케이스를 실행하기 위해 반드시 먼저 수행되어야 하는 필수 관계를 나타내고,<<extend>>는 특정 조건 하에서만 선택적으로 실행할 수 있는 확장 기능을 나타낸다.- 유스케이스 다이어그램을 그릴 때, 시나리오상 일련의 행위가 된다고 하더라도 일직선으로 그리지는 않아야겠다는 것을 배웠다.
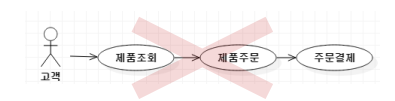
또한, Single Responsibility Principle(SRP)를 근거로 하나의 유스케이스에서는 하나의 기능만 작동해야 함을 강조해야한다.
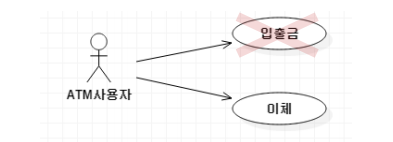
이처럼 입금과 출금 두개의 기능이 있음에도 '입출금'으로 묶는 건 해당 원칙에 위반된다.
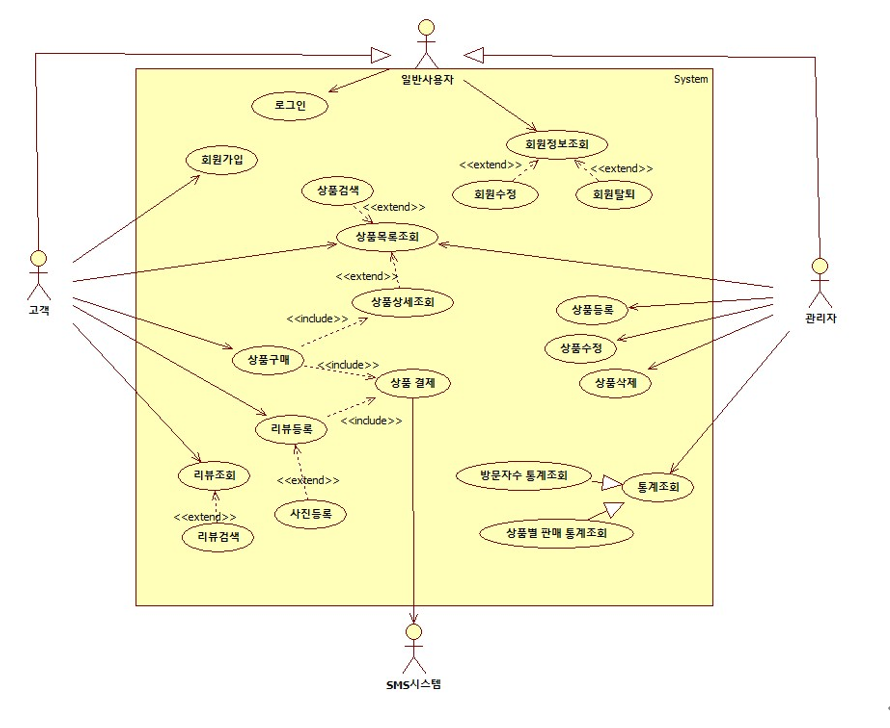
- 이 UML과 유스케이스에서, 액터는 총 고객, 관리자, 사용자 세 가지가 된다. 처음에 고객과 관리자 두 개인줄 알았지만, "사용자는 로그인을 통해 쇼핑몰을 이용할 수 있다" 라는 구문을 통해 세 가지가 된다는 것을설명을 듣고 알았다. 그리고 고객과 관리자는 모두 사용자로 로그인을 해야지만이 기능을 수행할 수 있다. 이는 부모 액터인 사용자의 기능을 자식 액터인 관리자와 고객이 물려받는 것으로 이해하였다. 고객과 관리자의 화살표가 왜 사용자로 향하는지 그런 이유들로 깨달았다.

🤔 Lacked (부족했던 점)
- 오늘 '사용자' 액터를 놓쳤듯이, UML에서 액터와 유스케이스를 구분할 때 더 집중해서 구분해야겠다.
- 월요일이라 그런지 피곤함이 몰려 집중력이 조금 떨어졌다. 다음부터는 커피를 마시거나 그래도 너무 졸리면 서서 수업을 듣는 것도 생각해봐야겠다.
- 이론 수업을 들을 때 다 아는 것이라고 생각해서 조금 흘려 들은 것도 있다. 하지만 책 한권만 읽은 사람이 더 무섭듯이, 조금 더 메타인지를 키워 부족한 부분을 채워나가야겠다고 생각했다.
🚀 Longed for (바라는 점)
- 유스케이스 다이어그램을 작성할 때, 헷갈린 부분 없이 명확히 작성했으면 좋겠다.
[D+4] 2025-09-23 (화요일) 회고록
😊 Liked (좋았던 점)
- ACID 속성에 대해 예시를 들어서 설명해주셔서 이해하기가 쉬웠다. 특히 Atomicity와 Consistency가 유사한 내용이라 다소 헷갈렸지만, 은행의 예시를 빗대어 생각해보니 쉽게 알 수 있었다.
- SQL 쿼리를 짜는 법은 알고 있었지만 실제로
MariaDB나MySQL을 다뤄본적은 없기에 미숙하였지만 설치법부터 사용법까지 상세히 알려주어서 지금은 원하는대로 쿼리를 잘 짤 수 있게 되었다. - SQL 쿼리 예제를 보고 하나하나 설명을 해주신 덕분에 쿼리 안 내용이 어떠한 기능을 하는지 알게되었고(
CREATE USER 'swcamp'@'%' IDENTIFIED BY 'swcamp';) 스크립트 파일로 저장하여 복습하기에 좋았다.
💡 Learned (배운 점)
-
ACID트랜잭션 원칙에 대해서 개념을 상기하게 되었다.Atomicity(원자성)은 모든 작업이 전부 성공하거나 전부 실패함을 뜻한다. 은행으로 예시를 들자면, 백만 원을 출금해서 완료 메시지가 떴지만 기기에서 출금이 되지 않을 때 다시 출금 이전으로 돌아가야한다. 이처럼 단위별로 연산을 하여 모든 작업이 성공적으로 연산이 되면 반영이 됨을 뜻한다.Consistency(일관성)은 트랜잭션이 성공적으로 완료된 후에도 데이터베이스가 항상 일관된 상태를 유지해야 함을 뜻한다. 방금 전 백만 원 출금 전으로 돌아갔다면, 데이터베이스에는 여전히 백만 원이 반영되어 있어야 한다.Isolation(고립성)은 여러 트랜잭션이 동시에 실행될 때, 각 트랜잭션이 서로에게 영향을 주지 않고 독립적으로 실행되는 것을 보장함을 의미한다. A가 계좌에서 10만원을 뺀다고 했을 때, 그 연산이 이루어지는 순간에 계좌조회나 송금 연산은 막아주어야 한다.Durability(지속성)은 트랜잭션의 결과는 시스템에 장애가 발생하더라도 영구적으로 저장되고 손실되지 않아야 한다는 원칙이다. 커밋이 완료 되면 그 변경 사항은 불변해야 하며 변경 사항을 볼 수 있게 해야한다.
-
CREATE USER 'swcamp'@'%' IDENTIFIED BY 'swcamp';는 새로운 사용자를 생성하겠다는 명령어인CREATE USER로 시작되어,swcamp는 그 사용자의 ID이며,@는 접속 위치인 호스트를 가리키고,%는 모든 곳에서 접속을 허용한다는 의미이다. (192.0.0.1이나 localhost 등 옵션이 다양) 그리고IDENTIFIED BY 'swcamp';는 비밀번호를swcamp로 설정한다는 의미이다. -
GRANT ALL PRIVILEGES ON menudb.* TO 'swcamp'@'%';에서GRANT ON TO구문은 알고 있었지만ALL PRIVILEGES에 대해 새롭게 알게 되었다.SELECT,INSERT,UPDATE,DELETE,CREATE,DROP등의 모든 권한을 부여함과 같은 의미이다. 그리고'swcamp'@'%';역시 모든 위치에서 접속하는swcamp사용자에게 권한을 부여한다는 의미이다. -
DBeaver에서 쿼리를 드래그한 뒤
Alt+x로 스크립트 모드에 진입 후 실행하면 한번에 모든 쿼리가 실행이 된다. -
SELECT문은 기본적으로
SELECT FROM의 형식을 따른다.- 단독으로
select 7 + 3;을 사용 가능, select now() as '현재 시간';이나select now() as "현재 시간";처럼as로 컬럼의 이름을 설정할 수도 있다.
- 단독으로
-
ORDERBY문은 기본적으로
SELECT FROM후에 후순위에 사용된다.order by후에 컬럼을 정렬하고 그 정렬된 순서에서 중복된 값이 있다면 추가적으로 컬럼을 정렬할 수도 있다.
select
menu_code
, menu_name
, menu_price
from tbl_menu
order by menu_price desc, menu_code; 🤔 Lacked (부족했던 점)
- MariaDB를 처음 사용했던지라 초기 설정에서 강사님이 하시는대로 따라하였지만 처음에는 조금 서툴렀던 것 같다.
- 오늘도 조금 피곤했다 .. 전날 일찍 자는 습관을 들여야겠다고 생각했다.
🚀 Longed for (바라는 점)
- DB를 가지고 백엔드와 어떻게 연계하는지가 궁금했기에, 이번 주에 구글링하여 간단한 객체를 가지고 여러 데이터들을 가지고 쿼리를 짜보는 연습을 해보고싶다.
- 기본적인
SELECT구문이나GROUPBY구문은 익혔지만, 여전히 초기 설정(계정 설정, 권한 부여)에 대해는 모호하기 때문에 여러 계정을 만들고 계정마다 데이터베이스를 꾸리는 연습을 하고싶다.
[D+5] 2025-09-24 (수요일) 회고록
😊 Liked (좋았던 점)
ORDER BY,WHERE,DISTINCT,LIMIT을 배웠는데, 그동안 이론으로만 알고 있었던 내용들을 실제로 실습하면서 다시 깨우치니 이해가 빨랐다.- 실제 데이터베이스를 넣고 그 DB를 토대로 여러 쿼리들을 실습하면서 헷갈렸던 (
WHERE,ORDER BY등의 위치 등) 내용들을 바로잡을 수 있었다. - 어제 헷갈렸었던 계정 생성 및 권한 부여에 대한 내용들을 실습하면서 이제 갈피를 잡고 혼자서도 진행할 수 있던 점이 흡족했다.
💡 Learned (배운 점)
field는 첫번째 인자가 몇 번째에 있는지 알려주는 쿼리문이다.select field('A', 'A', 'B', 'C');는1이 반환된다.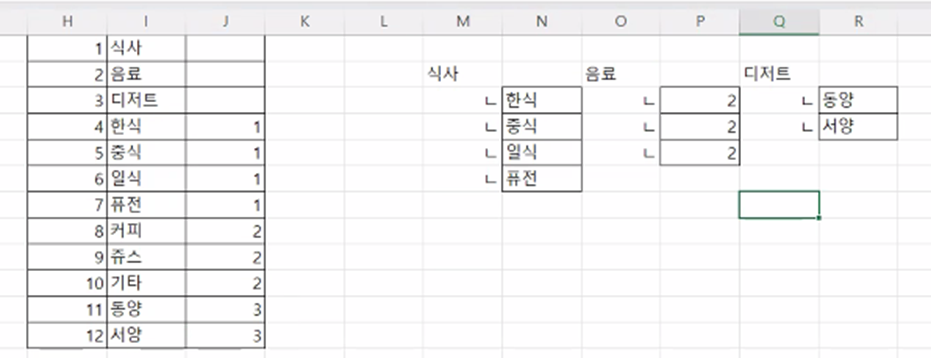
해당 테이블인tbl_category에서category_code에서null이면 그것이 최상위이다. 그리고 그 최상위를 참조하는 행이 있다.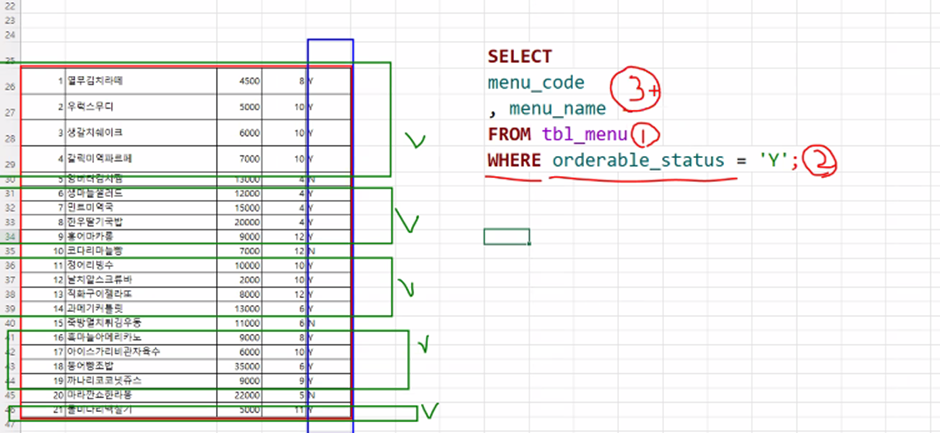
보통 순서가 1.from, 2.select, 3.order by였다면where절에서는 순서가 사진 처럼 진행된다. 2번을 거쳐 3번으로 갈 때는SELECT된 내용을 전달하는 것이 아닌 컬럼 전체 내용을 들고 간다. 아래는 기본 순서이다.
SELECT
컬럼명
, 컬럼명
... (3)
FROM 테이블명 (1)
WHERE 컬럼명(조건식) 값 (2)
ORDER BY 컬럼명 asc(desc), ...; (4) - and, or 연산자 중 우선순위가 높은 연산자는 and 연산자이다.
SELECT
*
FROM tbl_menu
WHERE category_code = 4
OR menu_price = 9000
AND menu_code > 10;먼저 menu_price = 9000와 menu_code > 10 인 것을 먼저 찾는다. 그 and 결과와 category_code=4를 OR 연산하여 결과를 도출한다.
즉, AND 조건 처리는 menu_price가 9000이면서 menu_code가 10을 초과하는 모든 메뉴를 먼저 찾고, OR 조건 처리는 그 결과에 category_code가 4인 모든 메뉴를 추가로 포함하여 최종 결과를 보여준다.
-
distinct는 중복된 내용이 없게끔 뽑겠다는 의미이고 뒤에 오면 안되고, 맨 앞에 와야한다.
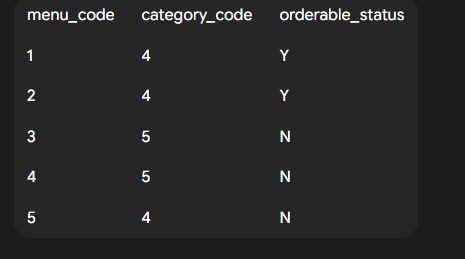
이 테이블에SELECT DISTINCT category_code, orderable_status FROM tbl_menu;쿼리를 실행하면, 시스템은(category_code, orderable_status)조합의 중복을 찾는다.
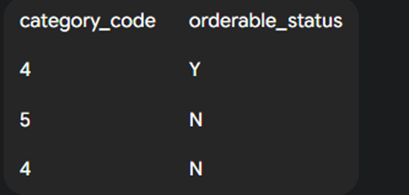
-
LIMIT는 정렬된 결과로부터 첫번째 인덱스에서 숫자만큼 보여주는 쿼리이다.
SELECT
menu_code
, menu_name
, menu_price
FROM tbl_menu
ORDER BY menu_price
LIMIT 1, 4;이는 첫번째 인덱스(실제로는 두번째에 위치한 값)에서 4개까지 보여준다. 결과는 4개가 나오게 된다.
- 이는 계정 생성 및 권한 부여 쿼리이다. 반드시 root 계정에서 진행할 것.
>>>> 무슨계정에서 실행(root)
root
mariadb1 >>> use mysql
1. 데이터베이스 생성
데이터베이스명 : ott_platform
create database ott_platform;
2. 계정 생성 :
아이디 : 'ott_admin'@'%'
비밀번호 : admin
create user 'ott_admin'@'%' identified by 'admin';
3. 권한 전부 제공
grant all privileges on ott_platform.* to 'ott_admin'@'%';🤔 Lacked (부족했던 점)
- 오늘 수업 폴더를 PR 하는 과정에서, 조금 버벅여 동기분의 도움을 받았다. 이는
github의 학습이 다소 미흡하다는 것의 방증이라고 생각한다. - 쿼리문 작성이 생소하다보니 강사님처럼 깔끔하게 들여쓰기 하는 것을 익히는 데에 조금 시간이 걸렸지만 이내 적응하여 깔끔한 쿼리문을 만들어냈다.
🚀 Longed for (바라는 점)
github포크나 PR 관련 수업 자료들을 찾아보고 혼자서 계정을 만들어 PR하는 연습을 해보고싶다는 생각을 하였다.- 오늘 쿼리문으로 문제를 20개 풀어보았는데 난이도가 다소 쉬웠었기에 조금 복잡한 쿼리문도 잘 풀어내고싶다.
[D+6] 2025-09-25 (목요일) 회고록
😊 Liked (좋았던 점)
- 오늘도 역시 여러 문법들을 배우고 익힐 수 있게 여러 실습문제들을 풀 수 있어서 이해가 잘 되었다. 혼자 풀고 틀린 문제들도 강사님과 다시 돌아보니 이해가 잘 안 갔던 부분도 해결되었다.
- 이론을 듣는 것에서 그치지 않고 사례별로 여러가지 문법을 배우니 다양한 쿼리문을 혼자 짤 수 있을 것 같은 자신감이 생겼다.
💡 Learned (배운 점)
-
모든 테이블에는 식별자인 주키(#)가 있다. 누군가가 그 주키를 참조를 하면 외래 식별자이다.
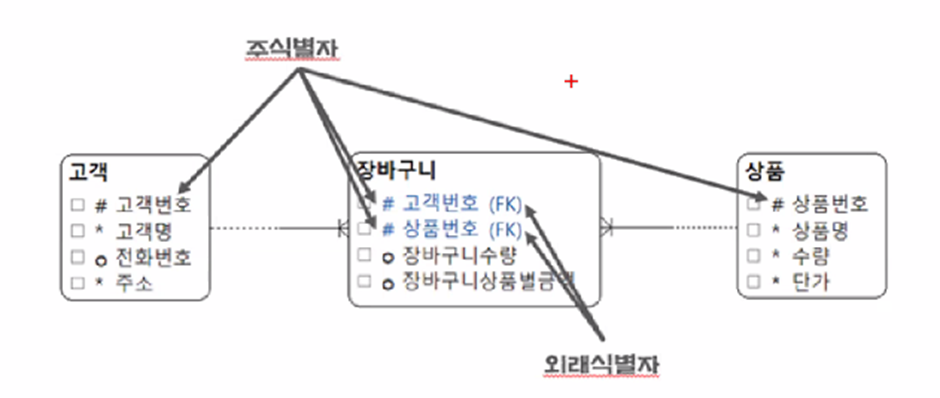
이 사진처럼 복합되면, 고객이 상품을 일대다로 담을 수 있는 관계가 된다. -
JOIN을 할 때USING과ON의 차이점을 알게 되었다.ON을 사용할 때는a.category_code = b.category_code처럼 조인할 컬럼을 직접 지정한다. 이처럼 두 컬럼의 이름이 달라도 사용할 수 있다.USING(category_code)를 사용하면 조인할 컬럼의 이름이 두 테이블에서 모두 같을 때만 사용할 수 있다. -
INNER JOIN과LEFT(RIGHT) JOIN를 사용하여 쿼리문을 직접 써보는 실습을 하였다.INNER JOIN은 교집합으로 두 테이블에 모두 존재하는 데이터, 즉 짝이 맞는 데이터만 보여준다. 이는 실제로 주문한 고객의 정보를 찾거나 댓글이 달린 동영상만 보고 싶을 때 사용한다. 양쪽 테이블에 모두 정보가 있는 확실한 데이터만 필요할 때 사용한다.LEFT(RIGHT) JOIN은 왼쪽 혹은 오른쪽 테이블의 모든 데이터를 기준으로 그 반대편의 데이터를 찾아와 붙인다. 주로 모든 고객 목록을 보고 고객이 주문을 했는지 안 했는지, 동영상 목록에서 댓글이 없는 게시글도 보고 싶을 때 사용한다. 짝이 없는 데이터는NULL로 표시된다.
SELECT a.emp_name , b.DEPT_TITLE , c.JOB_NAME FROM employee a LEFT JOIN department b ON a.DEPT_CODE = b.DEPT_ID JOIN job c ON a.JOB_CODE = c.JOB_CODE;이 쿼리에서 기준이 되는 베이스테이블은
employee테이블이다. -
CROSS JOIN은 두 테이블의 모든 가능한 조합을 반환하는 JOIN이다. 첫번째 테이블의 행 개수와 두 번째 테이블의 행 개수를 곱한 조합이 결과로 나온다.ON이나USING과 같은 연결조건이 필요 없다. -
SELF JOIN은 하나의 테이블에 두 개의 다른 별명을 부여해서 마치 서로 다른 두 개의 테이블인 것처럼 다루는 것이다.
SELECT
a.emp_name 사원명
, b.emp_name 관리자명
FROM employee a
JOIN employee b ON a.MANAGER_ID = b.EMP_ID;🤔 Lacked (부족했던 점)
- 처음
LEFT JOIN문제를 풀었을 때INNER JOIN과 혼동하였다. 그래서 처음에는 조금 버벅였다. - 데이터베이스의 테이블 컬럼을 유심히 보지 않아서 어떤 컬럼을 베이스테이블로 두어야 할지 헷갈렸다.
🚀 Longed for (바라는 점)
- 오늘 문제 풀이로 조금 자신감을 얻어서 이제는 내일 배울 서브쿼리와 결합하여 더욱 고난이도 문제를 풀어보고 싶다.
- 이번주 SQL 수업이 모두 마치면 주어진 데이터베이스를 가지고 혼자 여러 상황에 쓸 수 있는 쿼리를 만들어보고 싶다.
[D+7] 2025-09-26 (금요일) 회고록
😊 Liked (좋았던 점)
- 오늘도 실습문제 풀 시간이 주어졌는데, 오늘은 다소 난이도가 좀 있어서 생각할 시간이 많이 필요했는데 강사님께서 충분한 시간을 주어 여유롭게 생각하며 문제를 풀 수 있어서 좋았다.
- 서브쿼리 문제를 풀 때, 바로 답으로 가는 것이 아닌 답을 찾기 까지 서브쿼리와 메인쿼리가 어떻게 도출될 수 있는지 엑셀로 컬럼을 조작하여 설명해주셔서 시각적으로도 이해하기가 상당히 편했다.
- 항상 찍어놓으시는 강의 영상들이 집에서 혼자 복습할 때 큰 도움이 되었다.
💡 Learned (배운 점)
- 서브쿼리에는 결과가 몇 개인지에 따라서 연산자가 필요하다.
WHERE
category_code = (SELECT category_code
FROM tbl_menu
WHERE menu_name = '민트미역국'
);
이는 결과가 하나이기 때문에 다른 연산자가 필요 없지만,
WHERE
category_code IN (SELECT category_code
FROM tbl_category
WHERE ref_category_code = 1
);
ref_category_code가 가리키는 category_code는 4개 나오므로 IN, NOT IN, ANY, ALL의 연산자가 필요하다.
- 서브쿼리를 배우기 전,
IN의 기본 사용법은OR을 반복해서 써야하는 것을 대체하는 것이라고 배웠다. 그러나IN의 진짜 힘은 서브쿼리와의 조합에서 드러난다. 만약 '식사' 카테고리의 코드를 찾는다면,ref_category_code를 찾아야 한다.
SELECT
menu_name
FROM tbl_menu
WHERE category_code IN (SELECT category_code
FROM tbl_category
WHERE ref_category_code = 1);처럼 IN은 정적인 값 목록을 비교하는 용도를 넘어서 WHERE절의 조건으로 사용된다. 이 때, WHERE category_code IN (SELECT category_code .... 처럼 IN 앞의 컬럼과 서브쿼리 SELECT 뒤에 오는 컬럼은 서로 비교할 대상이기 때문에 같은 종류의 데이터여야 한다. 즉, 논리적으로 의미가 연결 되어야 한다 (이름은 다를지언정)
EXISTS는 '하나라도 있는 것을 뽑아줘' 처럼 존재여부를 확인해주는 서브쿼리이다.
SELECT
a.category_name, a.category_code
FROM
tbl_category a
WHERE EXISTS (SELECT 1 -- 행이 존재하냐?의 의미의 1
FROM tbl_menu b
WHERE b.category_code = a.category_code
);이 코드에서, 바깥쿼리가 카테고리를 선택하고 서브쿼르가 실행된다. tbl_menu의 카테고리 코드가 tbl_category의 카테고리 코드 (4부터 시작 됨)와 동일한지 tbl_menu 안에서 찾는다. 한 건이라도 찾으면 즉시 TRUE를 반환하고 4를 결과에 포함시킨다.
- 스칼라 서브쿼리에 대해서도 배웠다.
SELECT
a.menu_name
, (SELECT b.category_name
FROM tbl_category b
WHERE b.category_code = a.category_code
) category_name
FROM tbl_menu a결과값이 단일값 (1개의 행이나 1개의 열)인 상관 서브쿼리의 한 종류이다. 주로 SELECT절이나 WHERE절에 위치한다.
FROM절에 위치한 서브쿼리로, 인라인 뷰라고도 하는 것을 배웠다.
SELECT -- 인라인뷰에 존재하는 컬럼만 참조할 수 있다.
v.menu_name
, v.category_name
, v.menu_price
FROM (SELECT a.menu_name
, (SELECT category_name
FROM tbl_category b
WHERE b.category_code = a.category_code
) category_name
, a.menu_price
FROM tbl_menu a
) v -- 별칭을 붙여줘야함인라인 뷰는 반드시 가상 테이블에 별칭을 붙여줘야한다.
tbl_menu 테이블의 각 메뉴에 대해 SELECT절 안의 스칼라 서브쿼리가 실행된다. (순서가 FROM -> SELECT이기 때문) 이 스칼라 서브쿼리는 해당 메뉴의 category_code와 일치하는 category_name을 tbl_category에서 찾아와 붙여준다 (JOIN과 비슷할듯) 결과적으로 menu_name, category_name, menu_price 컬럼을 가진 테이블 v가 만들어진다. 이제 이 v를 실제 테이블처럼 사용하여 최종 결과를 조회한다.
🤔 Lacked (부족했던 점)
-
많은 종류의 서브쿼리를 한번에 배우다보니 각자의 쓰임새와 문법에 대해 많이 헷갈리는 부분들이 있었다. 스칼라 서브쿼리와 인라인뷰를 합쳐서 사용하는 서브쿼리는 복잡하여 이해하는 데에 시간이 걸렸던 것 같다.
-
서브쿼리의 양이 많아지다보니 순서 매커니즘을 잊고 무작정 쿼리를 작성하는 데에 급급했던 것 같다.
🚀 Longed for (바라는 점)
-
문제를 풀 때
주제 : 인라인 뷰를 사용하여..등 어떻게 하라는 지시가 있어서 감이 잡혔지만, 그런 주제들이 주어지지 않고 문제만 보고 풀었다면 더욱 헷갈렸을 것 같다. 그래서 단순히 문제만 보고 어떤 서브쿼리를 대입하여 풀어야하는지 많은 연습을 해야겠다고 생각했다. -
프로그램이 순서를 읽는 기초부터 다시 천천히 공부하고 그 순서에 따라서 천천히 문제를 해석하고 풀어야겠다는 생각이 들었다
