[논문리뷰] ORAK: A FOUNDATIONAL BENCHMARK FOR TRAINING AND EVALUATING LLM AGENTS ON DIVERSE VIDEO GAMES
Paper Review

Introduction
LLM을 활용한 play games 벤치마크 연구는 이전부터 지속되어 왔음.
하지만 기존 연구에는 3가지 한계가 존재함.
- 기존 연구는 실제 비디오 게임이 아닌 text-only games 혹은 2D grid simulater에 의존하는 경향이 큼
- self reflection, memory, tooluse 등 복잡한 게임 플레이를 위해 필수적인 agentic module에 대해 충분히 평가할 수 없음
- real world 비디오 게임에서 llm agents가 잘 동작하기 위해 pre trained LLM을 적응시킬 데이터셋이 필요한데 이것이 부족
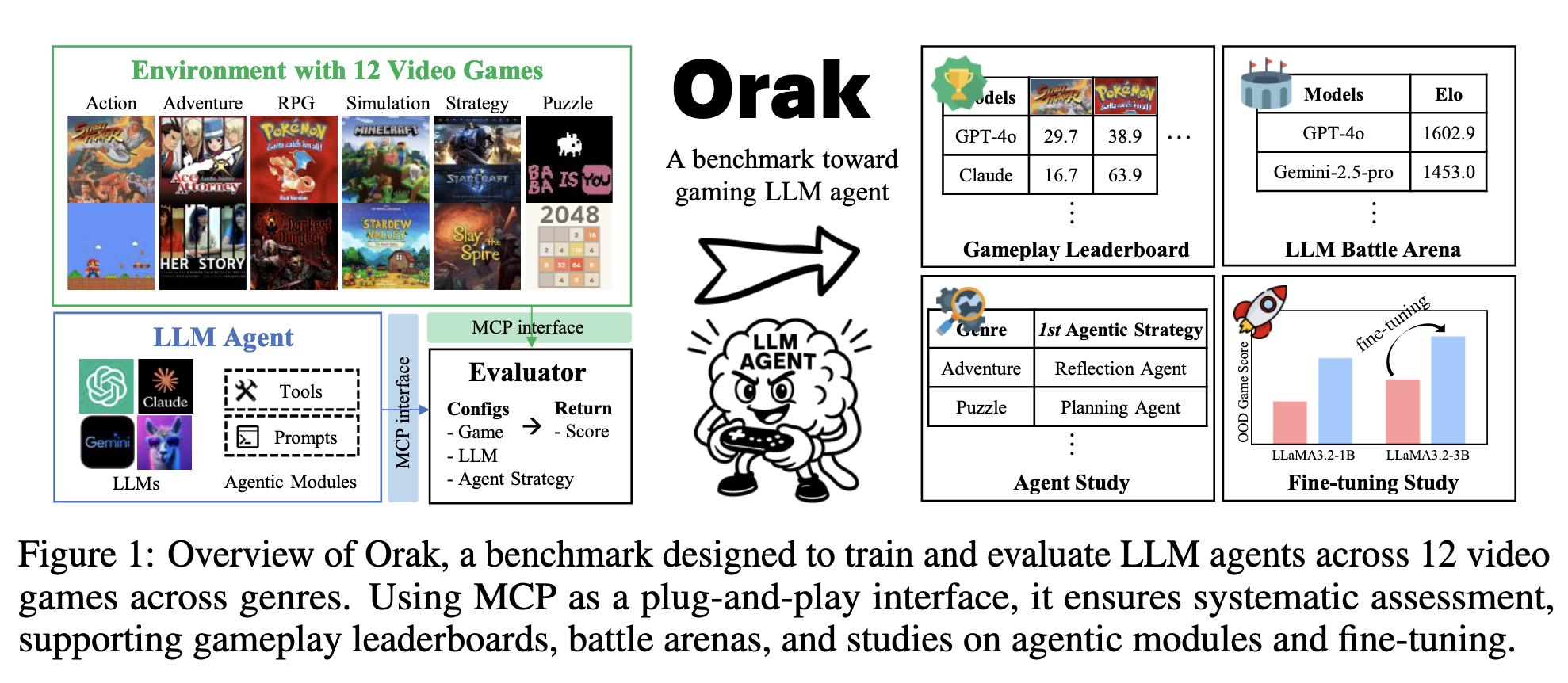
Orak은 다양한 게임 환경에서 LLM 에이전트를 평가하기 위해 설계된 벤치마크
다음과 같은 특징을 갖고 있음
-
12개의 비디오 게임으로 구성되어 있음
Street Fighter III, Super Mario, Ace Attorney, Her Story, Pok ́emon Red, Darkest Dungeon, Minecraft, Stardew Valley, StarCraft II, Slay the Spire, Baba Is You, and 2048
-
이 게임은 6개의 주요 장르가 있으며 이는 종합적인 게임 플레이의 능력을 평가할 수 있도록 함
“action, adventure, role-playing, simulation, strategy, and puzzle”
- 액션 게임은 세밀한 플레이어 제어를 테스트할 수 있고, 어드벤처 게임은 장기 기억력과 오류 처리에 도전하며, 전략/퍼즐 게임은 복잡한 논리적 추론과 다단계 계획이 필요함
- 액션 게임은 세밀한 플레이어 제어를 테스트할 수 있고, 어드벤처 게임은 장기 기억력과 오류 처리에 도전하며, 전략/퍼즐 게임은 복잡한 논리적 추론과 다단계 계획이 필요함
-
빠르게 발전하는 LLM을 일관적으로 평가하기 위해 MCP서버로 동작하는 plug and play 인터페이스를 도입해 LLM이 게임 환경에서 에이전트 모듈과 상호작용 할 수 있도록 함
-
각 게임 환경 및 에이전트 모듈 패키지는 독립적인 MCP 서버로 작동하여 게임 메커니즘(예: 게임 상태 검색, 게임 단계 실행) 또는 에이전트 전략(예: 반사, 계획)을 LLM에 호출 가능한 도구로 제공
-
평가 중에 LLM은 게임 상태를 순차적으로 검색하고, 에이전트 모듈을 사용하여 동작 추론을 수행하고, 게임 단계를 실행하여 이러한 서버와 상호 작용. 이를 통해 다양한 게임에 걸쳐 간소화된 평가가 가능하고 다양한 에이전트 모듈에 대한 제어된 연구를 지원
-
LLM을 효과적인 게임 에이전트로 전환하는 것을 목표로 하는 ft 데이터 셋을 공개. 데이터셋은 Orak의 모든 게임에 대한 핵심 에이전트 전략을 사용하여 전문 LLM(예: GPT-4o)에 의해 생성된 게임 상호 작용 궤적으로 구성. 이러한 궤적은 에이전트 전략을 사용하여 다양한 장르의 게임을 플레이하는 방법과 시기에 대한 메타 지식을 캡슐화하여 보다 자원 효율적이고 효과적인 게임 에이전트로 이어질 수 있음
벤치마크는 게임 점수 순위표, 경쟁력 있는 LLM 전투 경기장, 시각적 입력 상태, 에이전트 전략 및 미세 조정 효과에 대한 심층 분석을 포함한 포괄적인 평가 차원을 제공.
15개의 LLM을 사용한 Orak에 대한 광범위한 실험에서는 (1) 독점 LLM이 오픈 소스 LLM과 상당한 격차가 있는 게임 전반에 걸쳐 우수한 성능을 달성하고, (2) 전투 시나리오에서 성능 격차가 좁아지고, (3) 독점 LLM이 확장된 에이전트 작업 흐름의 이점을 얻는 반면, 오픈 소스 LLM은 제한적인 이득을 보이고, (4) 시각적 상태가 게임 플레이 성능을 방해하는 경우가 많으며, (5) sft 통해 게임 플레이 메타 지식을 더 큰 LLM에서 더 작은 LLM으로 효과적으로 transfer 할 수 있음을 발견.
이는 게임 내, 배포 외(OOD) 게임, 수학 및 웹 상호 작용과 같은 게임이 아닌 보이지 않는 시나리오의 일반화로 이어짐.
Method

ORAK 개요
ORAK는 다양한 비디오 게임 환경에서 LLM 기반 에이전트를 평가하기 위한 벤치마크
MCP 인터페이스를 통해 게임 환경과 에이전트 모듈을 결합하여, 백본 LLM + 에이전트 전략을 손쉽게 구성하고 점수를 측정할 수 있도록 설계되었음
평가 과정은 다음 루프로 진행:
- 게임 상태(observation) 가져오기
- 지정된 에이전트 전략을 LLM으로 실행
- LLM이 만든 액션을 게임에 적용
- 게임 종료 혹은 최대 스텝 도달 시 점수 기록
MCP를 활용해 단일 혹은 여러 에이전트 모듈을 순차적으로 호출하는 다양한 전략을 쉽게 구성할 수 있음
게임 환경 및 필요한 LLM capacity
ORAK는 총 12개 게임 환경을 포함
각 게임은 다음 7가지 능력의 요구 수준(1~3)을 기반으로 분석:
Rule Following (RF): 규칙 준수
Logical Reasoning (LR): 논리적 추론
Spatial Reasoning (SR): 공간 이해
Long-text Understanding (LTU): 긴 텍스트 이해
Long-term Planning (LP): 장기 계획
Error Handling (EH): 실수 수정
Odds Handling (OH): 확률·랜덤성 처리
예:
액션 게임(Street Fighter III, Super Mario) : SR, RF 요구 높음
스토리 및 추론 중심 게임(Ace Attorney, Her Story) : LTU, LR 요구 높음
12개 게임 요약
각 게임은 (1) 상태 정보, (2) LLM이 사용할 수 있는 액션, (3) 평가 방식으로 설명된다.
아주 간단히 핵심만 요약하면:
Street Fighter III – 격투; 상태는 체력/거리 등, 목표는 봇을 몇 단계까지 이기는지
Super Mario – 점프 결정; 얼마나 멀리 이동했는지
Ace Attorney – 법정 추리; 정답률과 스텝
Her Story – 영상 검색·추리; 얼마나 적은 클립으로 진실을 찾는지
Pokémon Red – RPG; 브록을 잡을 때까지의 진행도
Darkest Dungeon – 던전 탐사; 전투 성공/생존/스트레스 종합 점수
Minecraft – 샌드박스; 목표 아이템 제작 여부
Stardew Valley – 농사 시뮬; 13일간의 총 수익
StarCraft II – RTS; 봇 승률
Slay the Spire – 덱 빌딩; 도달 층수
Baba Is You – 규칙 퍼즐; 클리어 여부 및 부분 점수
2048 – 퍼즐; 2048 타일까지의 진행도
제출 가이드라인
모델 제출: 새로운 LLM/VLM 또는 파인튜닝 모델 제출 가능
기본 에이전트 전략(Section 5.1)에 따라 평가
에이전트 전략 제출: reasoning → planning → tool 등 일관된 구조의 모듈 조합 형태로 제출해야 함
FINE-TUNING: ALIGNING PRE-TRAINED LLMS INTO GAME AGENTS
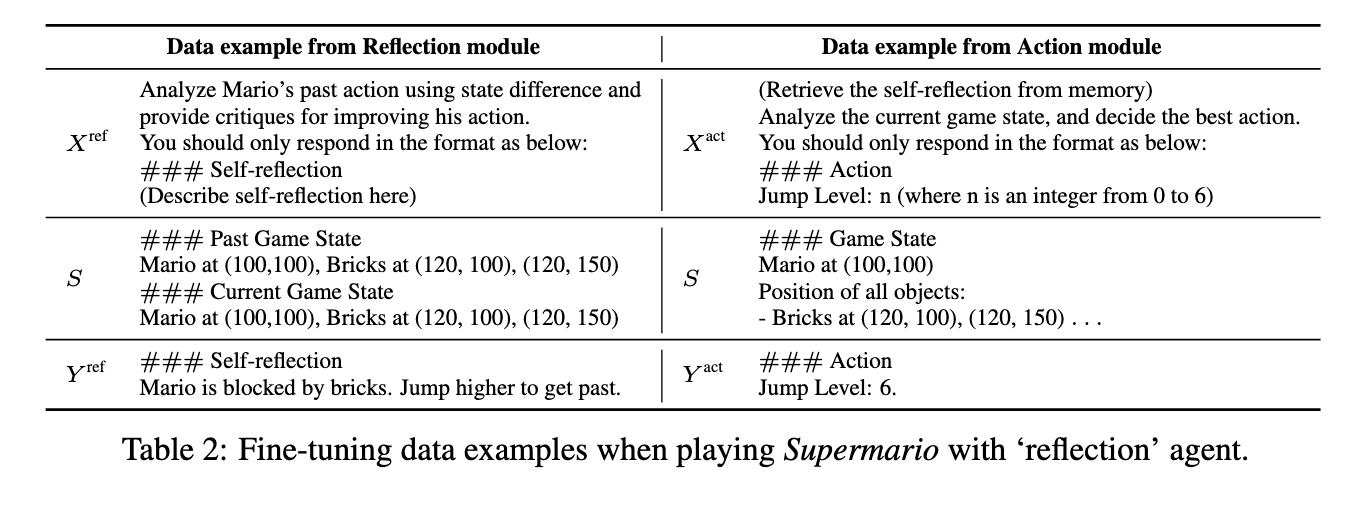
데이터 수집
- ORAK의 12개 게임을 전문 LLM(예: GPT-4o, o3-mini)이 여러 에이전트 모듈을 사용해 플레이하도록 하여 파인튜닝 데이터를 모음
- 이 데이터는 다양한 게임 장르를 해결하기 위한 에이전트 전략 사용 방법(메타 지식)을 포함
데이터 형식
- 각 플레이는 전체 게임 스텝 기준으로 T = {τ₁, …, τ_T} 의 형태로 기록
- 각 스텝 t에서의 LLM 추론 시퀀스 τ_t는 여러 에이전트 모듈 호출로 구성
각 τ는 아래 형태:
-
τ = { (Xᵃⁱ, S, Yᵃⁱ) }ᵢ₌₁ⁿ
- aᵢ: 사용된 에이전트 모듈 종류 (예: reflection, planning, action)
- Xᵃ: 모듈에 주어지는 프롬프트
- S: 게임 상태
- Yᵃ: LLM의 응답
데이터 선택
- 각 게임에 대해 전문가 LLM의 플레이 데이터(τ 시퀀스)를 충분히 모아,
전체 τ 수가 1000개 이상이 되도록 함 - 이후 각 게임 내에서 게임 점수 기준으로 상위 데이터를 선택하여
300개 이상의 τ를 확보 - 선택된 모든 데이터는 reflection → planning → action 순서의 에이전트 호출 구조를 가짐
- 최종적으로 12개 게임 전체에서 약 1.1만 개(11k)의 샘플로 구성된 파인튜닝 세트를 구축
Data Augmentation
- 언어적 다양성을 높이기 위해, 각 τ의 에이전트 프롬프트 Xᵃ를 GPT-4o로 패러프레이즈한다.
- 게임 정보는 그대로 유지한 채 표현만 다르게 생성하며,
각 τ당 10개의 증강 샘플을 만든다. - 증강 기법에 대한 자세한 프롬프트와 실험 영향은 Appendix O 참고.
파인튜닝 방식
- 본 데이터셋은 SFT(Supervised Fine-Tuning) 중심으로 설계됨.
- 환경과의 동적 상호작용을 이용한 강화학습 방식(RL Fine-tuning)도 가능하지만, 이는 후속 연구
Results
실험 세팅
15개의 LLM을 텍스트 기반 상태 입력으로 평가
오픈소스 8개(LLaMA-3.2-1B/3B, LLaMA-3.3-72B, Qwen-2.5-3B/7B/72B, Minitron-4B/8B)와
프라이빗 7개(GPT-5/4o/4o-mini, o3-mini, Gemini-2.5-pro, Claude-3.7-sonnet, DeepSeek-R1)를 포함
추가로 5개의 멀티모달 LLM(Qwen2.5-vl-7B/32B, GPT-4o, Gemini-2.5-pro, Claude-3.7-sonnet)에 대해 이미지 입력 효과도 분석
각 게임에는 GPT-4o 기준으로 가장 효과적인 기본 agentic strategy를 설정
게임별로 zero-shot, reflection, reflection-planning, skill-management 전략을 사용
점수는 최대 점수 기준으로 정규화해 보고했으며, 게임당 3~20회 평균을 사용하고 인간 초보자 3명의 평균도 함께 보고
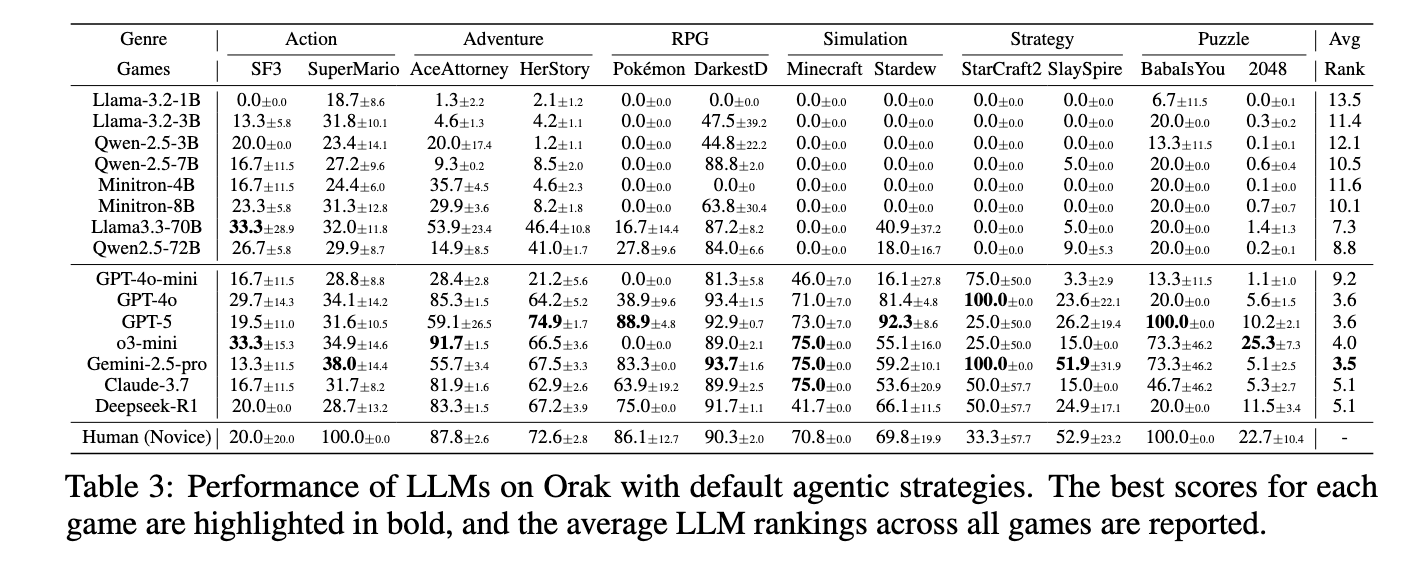
LLM 게임 플레이 성능
전체적으로 프라이빗 모델이 오픈소스 모델보다 우수한 성능을 보였음
Gemini-2.5-pro가 평균적으로 가장 높은 성능을 보였고, 12개 중 5개 게임에서 1위를 기록
GPT-5와 GPT-4o 계열이 그 뒤를 이었음
GPT-5는 Baba Is You, 2048과 같은 퍼즐·논리 기반 게임에서 강점
8B 이하의 소형 오픈소스 모델은 Pokémon Red, Minecraft, Stardew Valley, StarCraft II, Slay the Spire와 같은 복잡한 게임에서 거의 점수를 얻지 못했음
중형 모델(LLaMA3.3-70B, Qwen2.5-72B)은 중간 난이도 게임에서 일부 개선을 보였으나 프라이빗 모델에는 미치지 못했음
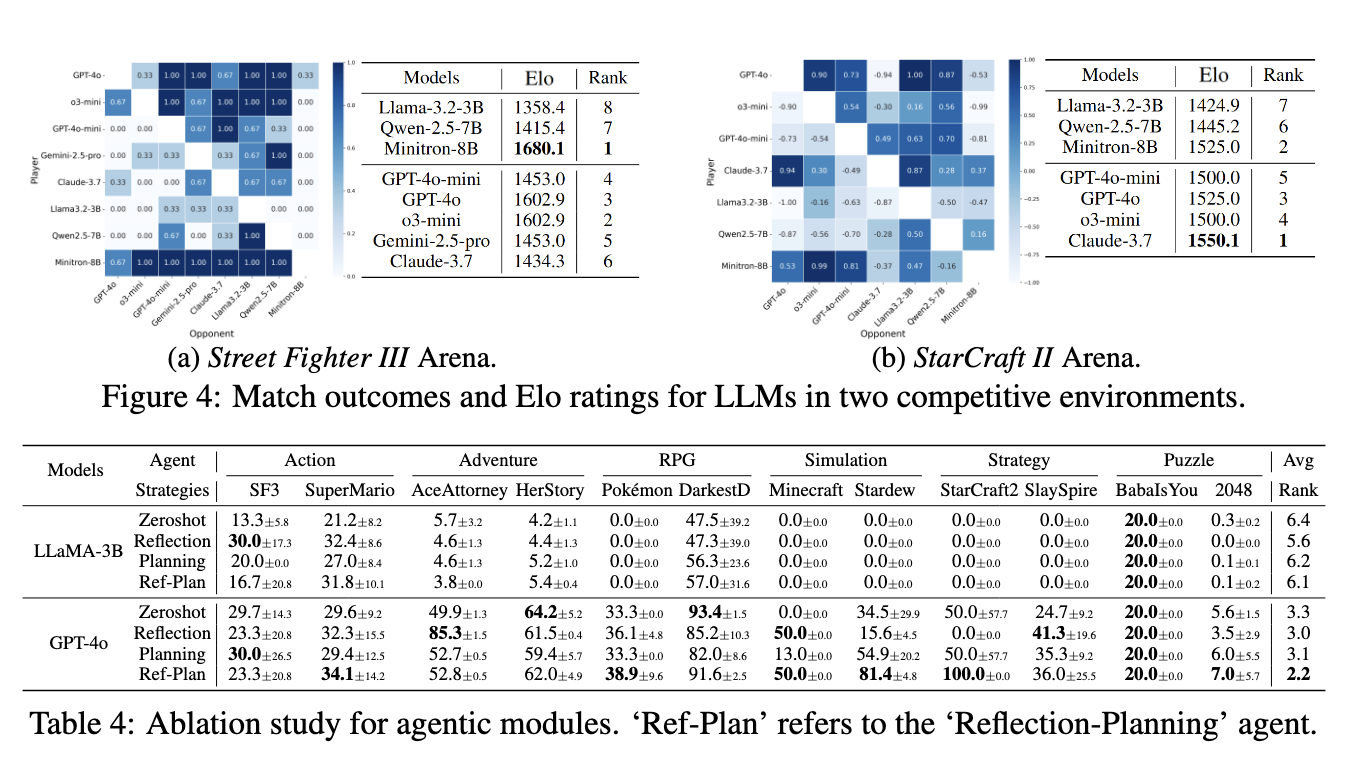
LLM Arena
Street Fighter III와 StarCraft II에서 LLM 간 대전 실험을 수행
Street Fighter III에서는 zero-shot 에이전트를 사용해 8개 모델의 쌍대 비교를 진행했으며, 동일 캐릭터(Ken)로 3전 2선승제를 수행
흥미롭게도 Minitron-8B가 모든 모델을 consistently 이기며 가장 높은 Elo를 기록
이는 대전 환경에서는 상호작용적 요소가 게임 역학을 변화시킬 가능성을 시사
StarCraft II에서는 Protoss 미러 매치로 7개 모델을 비교했으며, Claude-3.7-sonnet이 가장 높은 Elo를 기록했고, GPT-4o와 Minitron-8B가 그 뒤를 이었음
에이전트 모듈 제거 실험
LLaMA-3.2-3B와 GPT-4o를 대상으로 4가지 에이전트 전략의 효과를 분석
GPT-4o는 모듈이 추가될수록 성능이 안정적으로 향상되었으며,
reflection-planning > reflection > planning > zero-shot 순으로 좋은 결과가 나타남
반면 LLaMA-3.2-3B는 reflection이 가장 높고 reflection-planning은 오히려 하락
이는 소형 모델에서는 모듈 추가로 프롬프트 복잡도가 증가해 의사결정 정확도가 떨어질 수 있음을 시사
결과적으로 최적의 agentic 전략은 모델 용량에 따라 다를 수 있음을 보여줌
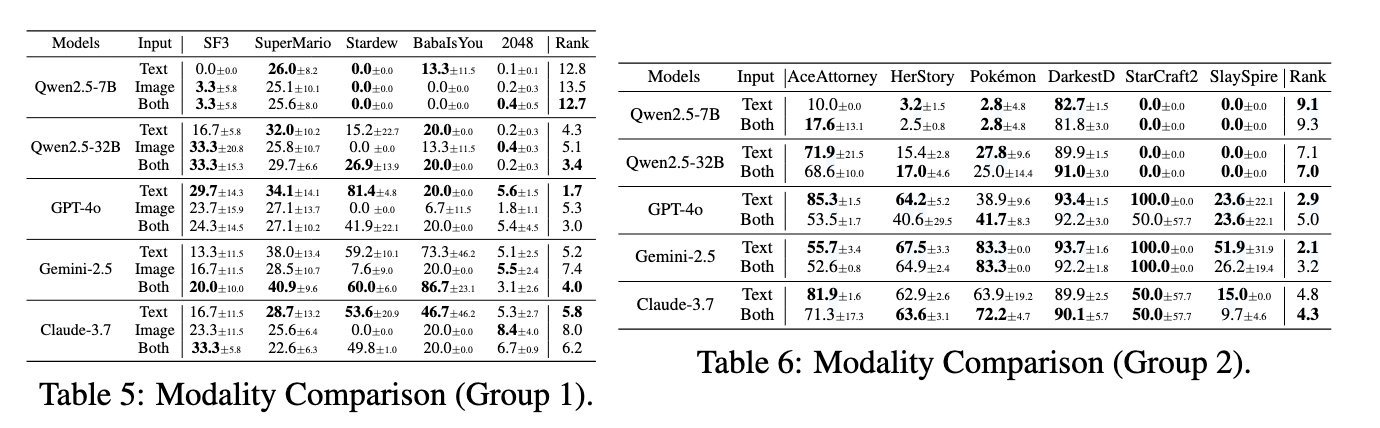
시각 정보 입력의 효과
게임을 두 그룹으로 나눠 텍스트 기반 정보가 시각적으로 완전히 복원 가능한 경우(Group 1)와 그렇지 않은 경우(Group 2)로 나누어 분석
Image-only 입력은 모든 모델에서 성능이 큰 폭으로 하락
텍스트-only 대비 평균 순위가 전반적으로 악화
Text+Image 입력은 게임에 따라 상반된 효과를 보였음
예를 들어 Street Fighter III와 같은 시각 정보가 중요한 게임에서는 시각 입력이 성능을 향상시켰으며, Claude는 16.6점 상승
반면 Ace Attorney와 같은 텍스트 중심 게임에서는 오히려 성능이 떨어졌으며, GPT-4o는 31.8 감소
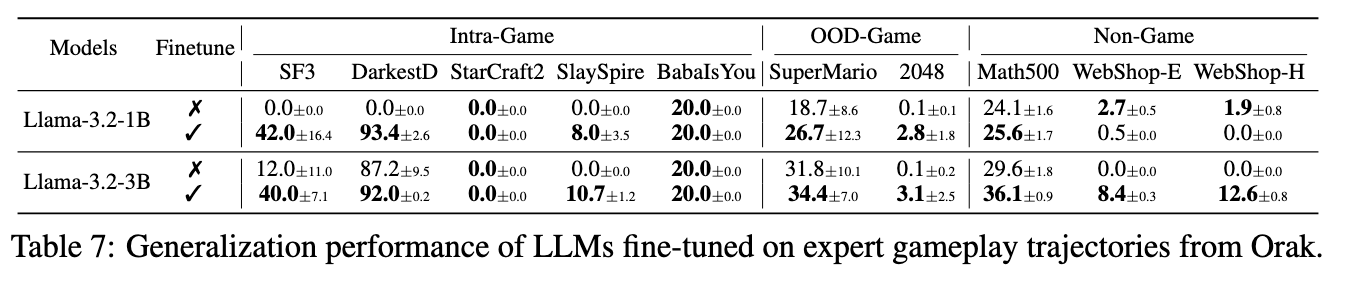
파인튜닝의 효과
파인튜닝의 일반화 효과를 Intra-game, OOD-game, Non-game 세 범주에서 분석
Intra-game generalization에서는 LLaMA-3.2-1B/3B가 미학습 시나리오에 대해 더 나은 행동을 보였으며, 특히 유효한 액션 생성 안정성이 개선
다만 Baba Is You와 같이 높은 공간 추론을 요구하는 환경에서는 소형 모델의 한계가 뚜렷했음.
OOD-game generalization에서는 Super Mario와 2048과 같은 훈련에 포함되지 않은 게임에서도 파인튜닝 모델이 향상된 성능
이는 reflection·planning 기반 결정 루틴이 게임 간 전이 가능함을 시사
특히 2048의 개선은 Baba Is You와의 구조적 유사성(up/down/left/right 기반 2D grid)이 도움이 되었을 가능성이 있음
Non-game generalization에서는 Math500과 WebShop과 같은 비게임 작업에서도 일부 모델이 향상
LLaMA-3.2-3B는 Math500과 WebShop-E/H에서 각각 0%에서 최대 12.6%까지 개선
이는 게임 기반 agentic trajectory가 의사결정 중심 작업 전반에 유효할 수 있음을 보여줌
반면 1B 모델에서는 비게임 일반화가 관찰되지 않았으며, 이는 모델 용량에 따라 일반화 가능성이 좌우됨을 의미함
