📌 LinearRegression
✅ 개요
-
LinearRegression()- 예측값과 실제 값의 RSS를 최소화해 OLS(Ordinary Least Squares) 추정 방식으로 구현한 클래스
-
입력 파라미터
-
fit_intercept: 불린 값, intercept(절편) 값 계산 여부 지정 (default=True) -
normalize: 불린 값, 회귀를 수행하기 전에 입력 데이터 세트 정규화 여부 지정 (default=False)
(단,fit_intercept=False인 경우 파라미터 무시)
-
-
속성
-
coef_:fit()수행 시 회귀 계수를 배열 형태로 저장 -
intercept_: intercept 값
-
✅ 다중 공선성(multi-collinearity)
-
OLS 기반의 회귀 계수 계산은 입력 피처의 독립성에 많은 영향을 받는다.
-
피처 간의 상관관계가 매우 높은 경우 분산이 매우 커져서 오류에 매우 민감해지는 현상을 의미한다.
-
일반적으로 상관관계가 높은 피처가 많은 경우 독립적인 중요한 피처만 남기고 제거하거나 규제를 적용한다.
-
매우 많은 피처가 다중 공선성 문제를 가지고 있다면 PCA를 통해 차원 축소를 수행하는 것도 고려해 볼 수 있다.
✅ 평가
| 평가 방법 | 사이킷런 평가 지표 API | Scoring 함수 적용 값 |
|---|---|---|
| MAE | metrics.mean_absolute_error | 'neg_mean_absolute_error' |
| MSE | metrics.mean_squared_error | 'neg_mean_squared_error' |
| R² | metrics.r2_score | 'r2' |
-
위 표는 각 평가 방법에 대한 사이킷런의 API 및 cross_val_score나 GridSearchCV에서 평가 시 사용되는 scoring 파라미터 적용 값이다.
-
RMSE를 구하기 위해서는 MSE에 제곱근을 씌어서 계산하는 함수를 사용해야 한다.
-
사이킷런의 Scoring 함수는 score 값이 클수록 좋은 평가 결과로 자동 평가한다.
-
실제 값과 예측값의 오류 차이를 기반으로 하는 회귀 평가 지표의 경우 값이 커지면 오히려 나쁜 모델이라는 의미이므로 이를 사이킷런의 Scoring 함수에 일반적으로 반영하려면 보정이 필요하다.
-
따라서 -1을 원래의 평가 지표 값에 곱해서 음수(Negative)를 만들어 작은 오류 값이 더 큰 숫자로 인식하게 한다.
-
✅ 실습
-
사이킷런 내장: 보스턴 주택 가격 데이터
-
CRIM: 지역별 범죄 발생률
-
ZN: 25,000평방피트를 초과하는 거주 지역의 비율
-
NDUS: 비상업 지역 넓이 비율
-
CHAS: 찰스강에 대한 더미 변수 (강의 경계에 위치한 경우는 1, 아니면 0)
-
NOX: 일산화질소 농도
-
RM: 거주할 수 있는 방 개수
-
AGE: 1940년 이전에 건축된 소유 주택의 비율
-
DIS: 5개 주요 고용센터까지의 가중 거리
-
RAD: 고속도로 접근 용이도
-
TAX: 10,000달러당 재산세율
-
PTRATIO: 지역의 교사와 학생 수 비율
-
B: 지역의 흑인 거주 비율
-
LSTAT: 하위 계층의 비율
-
MEDV: 본인 소유의 주택 가격(중앙값)
-
PRICE: 주택 가격
<target>
-
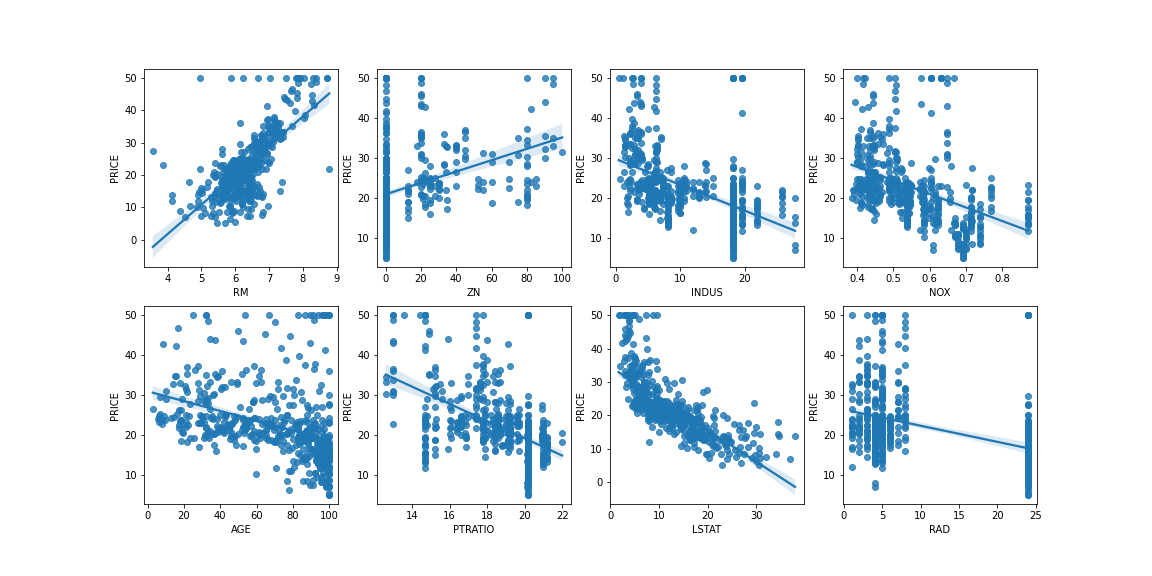
import numpy as np import matplotlib.pyplot as plt import pandas as pd import seaborn as sns from scipy import stats from sklearn.datasets import load_boston %matplotlib inline # boston 데이터 세트 로드 boston = load_boston() # boston 데이터 세트 -> DataFrame bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names) # boston dataset의 target array는 주택 가격, PRICE로 추가 bostonDF['PRICE'] = boston.target # 각 칼럼별 주택 가격에 미치는 영향도 조사 # 2개의 행과 4개의 열을 가진 subplots를 이용, axs는 4x2개의 ax fig, axs = plt.subplots(figsize=(16,8) , ncols=4 , nrows=2) lm_features = ['RM','ZN','INDUS','NOX','AGE','PTRATIO','LSTAT','RAD'] for i , feature in enumerate(lm_features): row = int(i/4) col = i%4 # 시본의 regplot을 이용해 산점도와 선형 회귀 직선을 함께 표현 sns.regplot(x=feature , y='PRICE',data=bostonDF , ax=axs[row][col])
RM, LSTAT의 PRICE 영향도가 가장 두드러지게 나타난다.
RM(방 개수): 양 방향의 선형성, 방의 크기가 클수록 가격이 증가
LSTAT(하위 계층의 비율): 음 방향의 선형성, 하위 계층의 비율이 적을수록 가격이 증가
from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error , r2_score y_target = bostonDF['PRICE'] X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False) X_train, X_test, y_train, y_test = train_test_split(X_data, y_target, test_size=0.3, random_state=156) # Linear Regression OLS로 학습/예측/평가 수행 lr = LinearRegression() lr.fit(X_train ,y_train) y_preds = lr.predict(X_test) mse = mean_squared_error(y_test, y_preds) rmse = np.sqrt(mse) print('MSE : {0:.3f}, RMSE : {1:.3F}'.format(mse, rmse)) print('Variance score : {0:.3f}'.format(r2_score(y_test, y_preds))) print('절편 값:',lr.intercept_) print('회귀 계수값:', np.round(lr.coef_, 1)) # 회귀 계수를 큰 값 순으로 정렬하기 위해 Series로 생성 coeff = pd.Series(data=np.round(lr.coef_, 1), index=X_data.columns) coeff.sort_values(ascending=False)
from sklearn.model_selection import cross_val_score y_target = bostonDF['PRICE'] X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False) lr = LinearRegression() # cross_val_score(): 5 Fold 셋으로 MSE를 구한 뒤 이를 기반으로 RMSE를 구함 neg_mse_scores = cross_val_score(lr, X_data, y_target, scoring="neg_mean_squared_error", cv=5) rmse_scores = np.sqrt(-1 * neg_mse_scores) avg_rmse = np.mean(rmse_scores) # cross_val_score(scoring="neg_mean_squared_error")로 반환된 값은 모두 음수 print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 2)) print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores, 2)) print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
