이상 탐지(Anmoaly Dection)
- 정상적인 데이터 패턴을 학습하고, 학습된 패턴과 다르거나 예상치 못한 이벤트를 감지하여 이상으로 판단하는 기술
- 이상탐지는 주로 비지도 학습 기술을 활용하는 경우가 많음.
1. import
모델 학습 및 추론에 필요한 라이브러리들을 불러옴.
import pandas as pd
import numpy as np
import torch # 3
from torchvision import models, transforms # 4
from torch.utils.data import DataLoader, Dataset # 5
from PIL import Image # 6
from sklearn.ensemble import IsolationForest # 7
from tqdm import tqdm # 83,5. PyTorch(torch, torch.utils.data)
- 텐서 연산 및 자동 미분 기능을 제공하는 딥러닝 프레임워크
- torch.utils.data는 데이터 전처리 및 배치 관리를 지원함.
4. Torchvision (torchvision, torchvision.model, torchvision.transforms)
- PyTorch와 연동되는 이미지 처리 및 사전 훈련된 모델을 제공하는 라이브러리
- 이미지 데이터 전처리 및 변환에 사용되는 다양한 기능을 포함함.
6. Pillow (PIL)
- 이미지 파일 처리를 위한 라이브러리
- 이미지 열기, 조작, 저장 등의 기능을 제공함.
7. Sklearn (IsolationForest)
- 대표적인 머신러닝 라이브러리
- 머신러닝에 관련된 많은 기능들을 지원함.
- IsolationForest 이상 탐지를 수행할 수 있는 대표적인 모델들 중 하나
8. Tqdm(tqdm.auto)
- 진행 상태 표시줄을 쉽게 추가할 수 있는 유틸리티
- 반복 작업의 진행 상태를 시각적으로 표시하여 사용자 경험을 개선함.
GPU 사용 설정
# GPU 사용 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")2. Data Load
학습에 필요한 데이터를 불러오고, 전처리를 진행합니다.
# 데이터 로딩 클래스 정의
class CustomDataset(Dataset): # 1
def __init__(self, csv_file, transform=None): # 1-1
"""
Args:
csv_file (string): csv 파일의 경로.
transform (callable, optional): 샘플에 적용될 Optional transform.
"""
self.df = pd.read_csv(csv_file)
self.transform = transform
def __len__(self): # 1-2
return len(self.df)
def __getitem__(self, idx): # 1-3
img_path = self.df['img_path'].iloc[idx]
image = Image.open(img_path)
if self.transform:
image = self.transform(image)
return image
# 이미지 전처리 및 임베딩
transform = transforms.Compose([ # 2
transforms.Resize((224, 224)), # 2-1
transforms.ToTensor(), # 2-2
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]) # 2-3
train_data = CustomDataset(csv_file='./train.csv', transform=transform) # 3
train_loader = DataLoader(train_data, batch_size=32, shuffle=False) # 3-11. CustomDataset
- 이 코드에서 정의된 CustomDataset 클래스는 PyTorch의 Dataset 클래스를 상속받아 이미지 데이터 처리에 특화되어 있음. 주요 구성 요소는 다음과 같음.
1-1. init
- 이 생성자는 데이터셋을 초기화할 때 필요한 매개변수를 설정함.
- 여기에 경로 리스트(csv_file), 그리고 이미지 변환을 위한 transform 함수가 포함됨.
1-2. gettiem
- 이 메서드는 주어진 인덱스를 데이터셋에서 불러오고 처리함.
여기서 이미지는 PIL 라이브러리를 사용하여 불러오고, 필요에 따라 변환(transform)이 적용됨. - 레이블 리스트가 제공된 경우, 해당 인덱스의 레이블도 함께 변환됨.
1-3. len
- 이 메서드는 데이터셋의 총 데이터 개수를 반환함.
이는 csv_file의 길이에 해당함.
2. Transform
- transform은 이미지 데이터를 전처리하는 데 사용되는 함수의 집합
여기에는 주로 다음과 같은 작업이 포함됨.
2-1. Resize()
: 이미지의 크기를 조정함. 여기서는 224*2224 크기로 조정함.
2-2. ToTensor()
: 이미지를 PyTorch 텐서로 변환함.
2-3. Normalize()
: 이미지를 정규화함. 여기서 사용된 평균(mean)과 표준편차(std)는 일반적으로 상요되는 ImageNet 데이터셋의 통계를 기반으로 함.
이러한 변환은 모델 학습에 적합한 형식의 데이터를 생성하고, 다양한 이미지 소스로부터 일관된 입력을 보장하는 데 필수적임.
3. DataLoader
- DataLoader는 구축된 데이터셋에서 배치 크기(batch_size)에 맞게 데이터를 추출하고, 필요에 따라 데이터를 섞거나(shuffle=True) 순서대로 반환(shuffle=False)하는 역할을 합니다.
3-1. batch_size
: 한 번에 연산되는 데이터의 크기를 의미함.
이는 하이퍼파라미터로, 본 대회에서는 32이지만 자유롭게 설정할 수 있음.
이렇게 DataLoader를 사용함으로써, 효율적인 데이터 처리와 모델 학습 및 평가가 가능해짐.
3. Export Embedding Vector
ResNet-50 모델
- 50개 계층으로 구성된 컨벌루션 신경망
- ResNet-50은 이미지 분류, 객체 검출, 세분화 등 다양한 비전 태스크에 적용됨.
이미지 데이터를 머신러닝 데이터에서 활용하기 위해 임베딩 벡터를 추출합니다.
이를 위해서 저희는 ImageNet 분류를 위해 만들어진 사전학습 모델인 ResNet-50을 활용하겠습니다. 이런 ResNet-50 모델은 ImageNet에 존재하는 대량에 데이터로 학습되어 이미지에 존재하는 특정들에 대해서 잘 학습되어 있습니다. 이 모델을 원래 의도된 분류를 위해 사용하지 않고, 모델이 가진 정보만을 이용해서 원하는 작업에 활용하는 것도 가능합니다.
본 베이스라인의 경우 대회의 데이터셋에 대해서 ResNet-50 모델이 인식하는 정보를 추출하는 것이 목표이기 때문에, 해당 모델의 마지막 레이어(분류 레이어)를 제거하고 ResNet-50이 대회 데이터셋에 대해서 인식하는 임베딩 벡터를 추출하겠습니다.
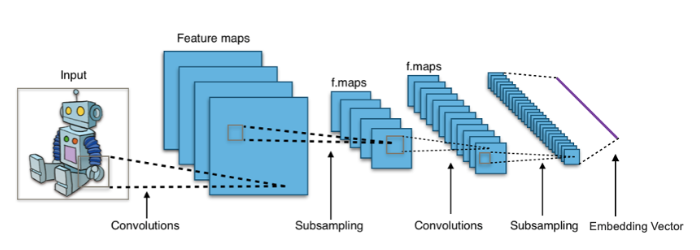
<출처 : Aphex34, CC BY-SA 4.0>
# 사전 학습된 모델 로드
model = models.resnet50(pretrained=True)
model.eval() # 추론 모드로 설정
# 특성 추출을 위한 모델의 마지막 레이어 수정
model = torch.nn.Sequential(*(list(model.children())[:-1]))
model.to(device)
# 이미지를 임베딩 벡터로 변환
def get_embeddings(dataloader, model):
embeddings = []
with torch.no_grad():
for images in tqdm(dataloader):
images = images.to(device)
emb = model(images)
embeddings.append(emb.cpu().numpy().squeeze())
return np.concatenate(embeddings, axis=0)
train_embeddings = get_embeddings(train_loader, model)Export Embedding Vector
이 코드 부분은 사전 학습된 딥러닝 모델을 사용하여 이미지 데이터셋의 각 이미지를 임베딩 벡터로 변환하는 과정을 설명함.
이 과정은 이미지의 특성을 고차원에서 저차원으로 압축하는 것을 목표로 함.
이러한 임베딩 벡터는 다양한 머신러닝 작업에 사용될 수 있음.
1. 사전 학습된 모델 로드
1-1. models.resnet50(pretrained=True)
- 사전에 훈련된 ResNet-50 모델을 로드함.
- ResNet-50은 이미지 인식 및 분류 작업에 널리 사용되는 딥러닝 모델
- pretrained=True는 모델이 이미 대규모 데이터셋에서 훈련되었음을 의미함.
1-2. model.eval()
- 모델을 추론 모드로 설정함.
- 이는 모델이 학습 모드기 아니라 추론(테스트) 모드에서 실행되어야 함을 나타냄.
- 이 모드에서는 드롭아웃과 같은 특정 레이어가 비활성화됨.
2. 모델의 마지막 레이어 수정
2-1. torch.nn.Sequential(*(list(model.children())[:-1]))
- 모델의 마지막 레이어(일반적으로 분류를 위한 레이어)를 제거하여 모델의 출력이 마지막 분류 레이어 전의 특성 맵이 되도록 합니다.
- 이를 통해 각 이미지의 특성을 나타내는 임베딩 벡터를 얻을 수 있습니다.
3. 임베딩 벡터 추출
3-1. get__embedings(dataloader, model)
- 이 함수는 dataloader에서 이미지 배치를 반복적으로 가져와서 주어진 모델을 사용하여 임베딩 벡터를 생성함.
3-2. with torch.no_grad()
- 이 코드는 자동 미분 기능을 비활성화하여 메모리 사용량을 줄이고 연산 속도를 높임.
- 추론 시에는 기울기 계산이 필요 없기 때문
3-3. images.to(device)
- 이미지 배치를 GPU(또는 CPU)로 이동시킴.
- 이는 모델 연산을 해당 디바이스에서 수행하기 위함임.
3-4. emb.cpu().numpy().sqeeze()
- 모델 출력(임베딩)을 CPU로 이동시키고, NumPy 배열로 변환한 다음, 불필요한 차원을 제거함.
3-5. np.concatenate(embeddings, axis=0)
- 모든 배치의 임베딩을 하나의 NunPy 배열로 결합함.
=> 최종적으로 train_embeddings에는 학습 데이터셋의 모든 이미지에 대한 임베딩 벡터가 저징됨. 이 과정을 통해 복잡한 이미지 데이터를 모델이 처리하기 쉬운 형태로 변환하여, 특정 작업에 적합한 특성을 추출하게 됨.
4. Anomaly Dection Model Fitting
본 베이스라인에서는 IsolationForest를 이용해서 이상 탐지를 진행함.
# Isolation Forest 모델 학습
clf = IsolationForest(random_state=42)
clf.fit(train_embeddings)Isolation Forest
- Isolation Forest는 이상치 탐지를 위해 설계된 트리 기반의 머신러닝 모델
- 여기서 이상치란 다른 데이터들과 큰 차이가 존재하는 데이터를 의미
- 본 대회처럼 데이터가 이상 데이터와 정상 데이터로 명확한 차이가 존재할 때, 이상 탐지를 위한 모델로도 활용 가능함.
- 이 모델은 분리를 기반으로 작동함.
- 이는 세부적으로 정상적인 데이터는 분리하기 위해 많은 분할이 필요하지만,
- 이상 데이터는 적은 분할로도 쉽게 분리된다는 원리를 기반으로 작동됨을 의미함.
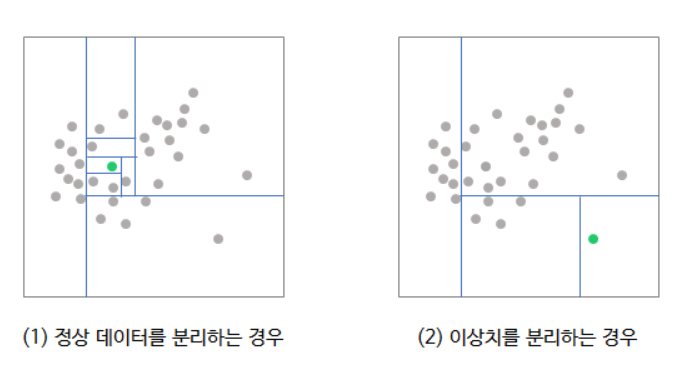
본 대회에서는 Isolation Forest의 하이퍼 파라미터로 random_state만을 42로 설정하고, 나머지는 기본값(default)을 활용했지만, 자유롭게 수정할 수 있음.
해당 모델의 주요 하이퍼 파라미터는 다음과 같음.
# Isolation Forest 모델 학습
clf = IsolationForest(random_state=42) # 4-4
clf.fit(train_embeddings)4-1. n_estimators
- Isolation Forest를 구성하는 트리(의사결정나무)의 수를 결정함.
- 해당 값이 커질수록 정확한 결과를 얻을 수 있지만, 연산속도가 증가하고 과적합의 위험이 증가함.
4-2. max_depth
- 트리가 성장할 수 있는 최대 깊이를 설정함.
- 해당 값을 낮출수록 단순한 트리를 생성할 수 있어, 과적합을 방지할 수 있음.
4-3. contamination
- 이상 데이터를 판단하는 임계값을 설정함.
- 해당 값이 높을수록 데이터에 이상 데이터가 많다고 간주하여,
- 정상 데이터를 이상 데이터로 판단할 위험이 있음.
-> 낮을수록 좋은 것으로,,!4-4. random_state
- 모델의 무작위성을 제어하여, 동일한 결과를 재현할 수 있음.
- 본 베이스라인에서는 42로 설정함.
5. Inference
테스트 데이터에 대해서도 학습 데이터와 동일한 전처리를 수행하고 학습된 모델로 추론합니다.
# 테스트 데이터에 대해 이상 탐지 수행
test_data = CustomDataset(csv_file='./test.csv', transform=transform) # 1-2
test_loader = DataLoader(test_data, batch_size=32, shuffle=False) # 1-3
test_embeddings = get_embeddings(test_loader, model) # 2
test_pred = clf.predict(test_embeddings) # 3
# Isolation Forest의 예측 결과(이상 = -1, 정상 = 1)를 이상 = 1, 정상 = 0으로 변환
test_pred = np.where(test_pred == -1, 1, 0) # 4테스트 데이터셋에 대한 추론은 다음 순서로 진행됨.
1) 테스트 데이터 준비
1-1) pd.read_csv('./test.csv')
- Pandas를 사용하여 테스트 데이터셋을 포함하는 CSV파일을 읽음.
1-2) CustomDataset(csv_file='./test.csv', transform=transform)
- CustomDataset 클래스를 사용하여 test.csv 파일을 불러와 테스트 데이터셋을 생성함.
- 이후 transform을 통해 이미지에 전처리를 수행함.
1-3) DataLoader(test_data, batch_size=32, shuffle=False)
- DataLoader를 사용하여 테스트 데이터셋을 배치 크기(32)에 맞게 로드함.
- shuffle=False는 테스트 데이터의 순서를 그대로 유지함.
2) get_embeddings
- 앞서 학습 데이터에서 임베딩 벡터를 추출하기 위해 사용한 코드를 그대로 테스트 데이터에 대해서도 적용함.
- 이를 통해서 테스트 이미지에서 임베딩 벡터를 추출하여 test_embeddings에 저장함.
3) predict
- 학습된 Isolation Forest모델인 clf를 이용해서 test_embeddings에 대해 예측을 수행함.
- 이는 이상을 -1로 정상을 1로 표기함.
4) np.where(test_pred == -1, 1, 0)
- 예측 결과가 저장된 test_pred에서, 이상 데이터인 -1을 1로 표기하고, 정상 데이터인 1을 0으로 표기함.
- 이는 Isolation Forest의 예측 결과를 대회 양식에 맞게 변환하는 과정임.
6. Submission
모델의 추론 결과를 제출 양식에 기입합니다.
submit = pd.read_csv('./sample_submission.csv')
submit['label'] = test_pred
submit.head()
submit.to_csv('./baseline_submit.csv', index=False)추론 결과를 제출 양식에 덮어 씌워 csv 파일로 생성하는 과정은 다음과 같습니다.
1. pd.read_csv('./sample_submission.csv')
- Pandas를 사용하여 제출을 위한 샘플 형식 파일('./sample_submission.csv')을 로드함.
- 이 파일은 일반적으로 각 테스트 샘플에 대한 id와 예측해야 하는 label이 존재함.
2. 예측 결과 할당
- submit['label'] = test_pred
- : 예측(predict)에서 반환된 예측 결과(test_pred)를 샘플 제출 파일의 label 열에 할당함.
3. 제출 파일 확인
- submit.head()
- : 수정된 제출 파일의 처음 몇 행을 확인하여, 예측 결과가 올바르게 들어갔는지 검토함.
- 이는 데이터가 올바른 형식으로 제출 파일에 저장되었는지 확인하는 단계임.
4. 제출 파일 저장
- submit.to_csv('./baseline_submit.csv', index=False)
- : 제출 파일을 baseline_submit이란 일므으로 저장하며,
- index=False를 통해 저장할 때 추가적인 index가 생기지 않도록 설정함.
