Introduce
안녕하세요 자르반입니다.
오늘은 저번 포스팅에 이어 추천시스템에 관련된 내용인데요,
앞으로 실제 추천시스템을 적용하기 위해 알아본 3가지를 포스팅할 계획입니다.
- content-based에서 어떤 기준으로 content를 추천할 것인지.
- 나중에 Hybrid로 가기 위해 어떤 사전 데이터가 필요할 것이며,
- content-based를 personalization하기 위해 필요한 것은 무엇일까?
오늘은 그 중에서도 1번에 관련해 포스팅하겠습니다.
오늘의 목표는 첫 장에서 말한 추천시스템 적용을 위해 필요한 첫 관문인 컨텐츠 기반 필터링을 이해하고 어떤 기준으로 처음에 적용할지 감을 잡는 것 입니다.
Content-based 기준
- 컨텐츠 기반의 추천시스템중 하나로, 해당 컨텐츠와 비슷한 다른 컨텐츠들을 추천해주는 시스템입니다.
먼저 컨텐츠에 대한 정보를 벡터화 시키고 벡터들간의 유사도를 계산하는 방식을 말합니다.
컨텐츠 벡터화 기법

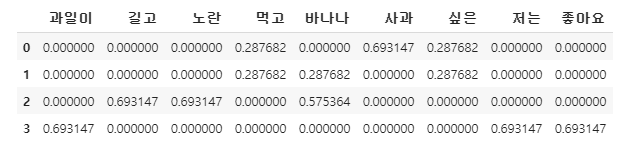
위 사진 처럼, 각 가중치들을 토대로 단어를 벡터화 시킬 수 있음.
1. TF-IDF
-
특정 문서 내에 특정 단어가 얼마나 자주 등장하는지(TF), 전체 문서에서 특정단어가 등장한 문서수(DF): 다른 문서에서는 등장하지 않지만 특정 문서에서만 자주 등장하는 문서를 찾아서 유사도 검사를함.
장점: 직관적인 해석
단점: Sparse한 형태라 메모리를 많이 먹음.
2. Word2Vec
-
단어간의 유사도를 반영해 단어를 벡터로 바꿔주는 임베딩 방법
-
TF-IDF의 단점을 해결하기 위해 사용하는 것으로, 단어를 의미기반으로 바꾸고 배치기반으로 학습을 통해 TF-IDF의 단점을 해소함.
어떻게?
추론기반의 방법으로 주변 단어 즉, 맥락을 통해 어떤 단어가 들어갔는지 추측할 수 있다.
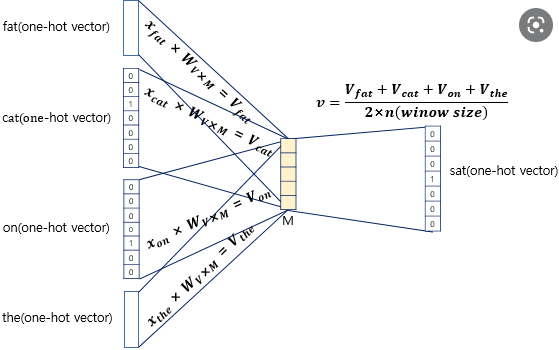
Word2Vec의 방법 두 가지
1) CBOW
- 주변에 있는 단어를 가지고 단어를 예측
2) Skip-Gram
-
중간에 있는 단어로 주변 단어를 에측함.
-
실제로, CBOW보다 성능이 좋고 실제로 Skip-Gram 방법을 많이 씀.
https://wikidocs.net/50739 예시
https://www.kaggle.com/chocozzz/00-word2vec-1
유사도 계산
-
유클리디안 유사도(거리)
-
코사인 유사도(내적)
-
피어슨 유사도(상관관계)
-
자카드 유사도(공통 부분의 수)
etc..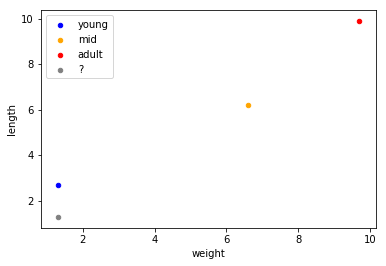
위 사진은, 유사도에 대한 그래프 인데, 만약 유클리디안으로 하게 된다면 adult와 ?은 많은 차이가 나겠지만 코사인으로 하면 1과 비슷한 숫자가 나올 것이다. 이 처럼 유사도 계산에서도 어떤 방법을 택하냐에 따라 결과가 많이 달라질 수 있다.
https://kh-kim.gitbook.io/natural-language-processing-with-pytorch/00-cover-4/07-similarity
적용결과
간단하게 검색해서 찾을 수 있는 TF-IDF와 코사인 유사도 기법을 통해
우리 프로젝트의 유사 강의를 찾아본 결과이다.
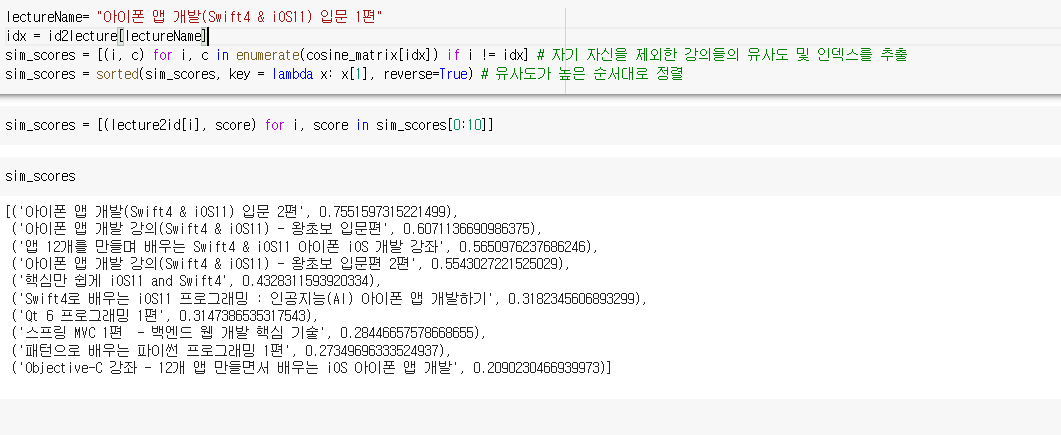
위 방법은 불용어를 제거하지 않은 상태에서의 결과이다. 따라서 불용어를 제거하면 더 좋은 성능을 가지고 있을지도 모른다.
하지만, 직접적으로 학습을 통해 결과값이 나오는 형태가 아니라 단어의 유사도를 통해 결과값이 나오는 형태이므로 학습보다는 안좋은 결과값이 나올 확률이 크다.
실제로 사진의 데이터만 봐도 아이폰 앱 개발이지만 qt에 관련된 내용이 나오는 것을 볼 수 있다. 물론 이에 대한 스코어가 낮은 것도 볼 수 있는데, 만약 해당 방법으로 실 서비스에 적용한다면 스코어에 대한 threshold가 필요할 것 같다.
아직까지는 사용자에 따라 계속 똑같은 정보가 발생할 확률이 높다.
따라 다음 글부터 이를 어떻게 해결하면 좋을지에 대해 포스팅해보겠다.
[ Reference ]
