개요
Gram-Net제안- 이미지 편집에 더 강력하게 대응
- GAN 모델에서 가짜 얼굴을 감지할 때 훨씬 더 잘 일반화가 됨
인사이트
1. Introduction
Contribution1
- GAN에서 생성된 얼굴 이미지를 탐지하기 위해 CNN 모델이 연구되고 있음
- 가짜 얼굴 텍스처 통계는 자연스러운 얼굴과 다름
- 사람 → 색상, 모양에 집중
- CNN → 텍스처 감지는 중요한 단서
Contribution2
- CNN 기반 얼굴 탐지는 사람보다 성능이 좋음
- 현실에서 사용하기 견고하지 않음
- 견고성과 일반화 능력을 향상시키는
그램넷개발
Contribution3
그램넷은 편집된 가짜 얼굴을 탐지에 있어 강력함- 뛰어난 일반화 능력
일반화
- 한 데이터셋에서 훈련된 모델이 다른 데이터셋에 얼마나 잘 작동하는지를 나타냄
- 본 연구에서는 CelebA-HQ에서 훈련된 모델을 FFHQ에서 테스트하는 것과 같은 실험을 통해 데이터셋 간의 일반화 성능을 확인
2. Related work
GANs for human face generation
- 초기 연구는 고해상도 이미지 생성에서 문제가 발생
- PGGAN, StyledGAN : 사람을 속일 수 있는 고품질의 이미지 생성 가능
Fake GAN face detection
- 다양한 detection 방법 소개
- GAN이 이미지에 특정 지문을 남김, 이러한 이미지를 생성하는 소스를 식별 → 훈련 데이터에 존재하지 않는 GAN 모델에서 가짜얼굴 탐지하는 데 일반화 불가능
- 색상 동시 발생 행렬을 입력 → 수작업으로 입력하면 원본 훼손
- 얼굴 랜드마크의 정렬에 초점을 맞춰 확인
Textures in CNNs
- CNN 모델이 모양보다는 텍스처에 강하게 편향되어있음
- 텍스처 차이를 분석
3. Empirical Studies and Analysis
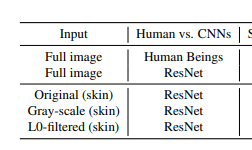
3.1 Human vs Cnn
- 결과적으로 CNN은 가짜 얼굴 탐지에서 높은 정확도를 보임
User study
- 참가자 20명에게 얼굴 이미지를 보여준 후 “진짜” “가짜” 버튼 클릭하도록 함 → 5.14초 소요
비대칭 눈불규칙한 치아불규칙한 글자를 알아봄 → 모양과 색상의 아티팩트를 증거로 삼는다
CNN study and result
- CNN 모델인 ResNet에 의해 평가
Analysis
- 왜 CNN이 가짜 얼굴 탐지에 뛰어난 성능을 보일까??
- 가짜 얼굴과 진짜 얼굴의 본질적인 차이는 무엇인가?
CNN이 가짜 얼굴 검출의 증거로 활용하는 영역은 ㅇㄷ일까!?
- 주로 피부와 머리카락 ⇒ 질감 영역(따뜻한 색상 영역) → CNN이 탐지
- 뚜렷한 아티팩트가 있는 영역 (파랑색 영역) → CNN에 기여 X
- 텍스처가 CNN이 가짜 얼굴 감지에 중요한 부분
- 이미지의 텍스처 : 이미지 상의 세부 패턴, 미세한 구조, 규칙성 또는 불규칙성

- 빨간색 상자 : 사람에게 잘 표시됨 → CNN에게는 파랑색 영역 약하게 활성화된 아티팩트
3.2 Is texture an important cue utilized by CNNs for fake face detecion?
- 텍스쳐에 더 풍부한 정보가 있음을 알기위해 피부 영역에서 실험을 함
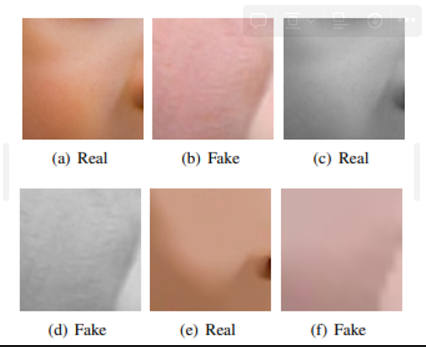
- 원본(skin) (a) (b) : 피부 영역에 유용한 정보가 있는지 확인
- gray-scale (c) (d) : 색상의 영향
- L0-filtered (e) (f) : 작은 텍스처를 부드럽게 하면서도 모양과 색상 정보를 유지
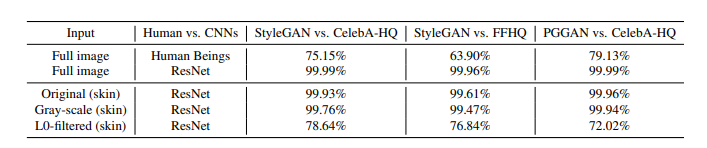
- Original, Gray-scale은 큰 영향 x
- L0 필터링은 약 20% 성능 저하 ⇒ 텍스처가 중요한지 보여줌
3.3 What are the differences between real & fake
faces in terms of texture?
-
텍스처 측면에서 실제 얼굴과 가짜 얼굴의 차이를 규명하는 것에 동기를 부여함
-
GLCM사용 Gray-Level Co-occurrence Matrix 해서 텍스처 차이를 분석 ****-
텍스처 분석 도구 셀에 값을 매기는 법
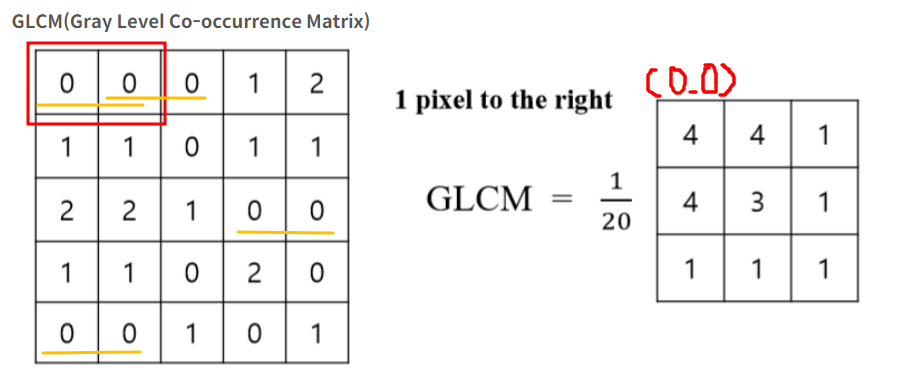
-
(0,0) → 총 4개 ⇒ 오른쪽 메트릭스의 (0,0) = 4
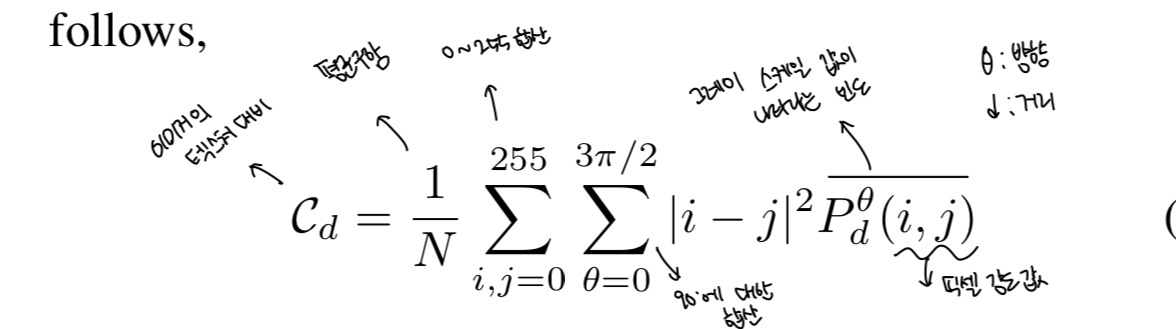
-
GLCM을 사용해서 질감의 동시 발생을 측정, 질감의 대비를 계산해서 선명도와 효과를 판별
-
GLCM의 주요 아이디어는 이미지 내에서 주어진 방향과 거리에서 함께 나타나는 픽셀 쌍의 빈도를 계산하는 것
-
Cd 가 클 수록 시각 효과가 선명 낮으면 흐릿
-
실제 데이터처럼 뚜렷한 질감 대비를 생성하기는 어려움
-
실제 얼굴 이미지가 더 강한 텍스처 대비를 가지고 있음
-
이러한 차이는 GAN이 생성한 이미지의 텍스처가 실제와 완전히 일치하지 않기 때문에 발생하며, 이를 이용하여 가짜 이미지와 실제 이미지를 구별하는 데 사용될 수 있음
-
4. Improved Model
- 일반화 능력과 견고성을 개선하려는 시도
- GAN 모델 간에 다르거나 이미지가 다운샘플링, JPEG 압축, 블러나 노이즈 추가와 같은 수정이 이루어진 경우
4.1 일반화 및 견고성 분석
- 이미지를 64x64로 다운샘플링 후 압축 → ResNet의 성능이 22% 감소
- 저해상도 GAN에서 평가될 때 성능이 약 64~75%까지 떨어짐
- 이 문제를 연구하기 위해 이미지 편집 시나리오에서의 원본과 수정된 이미지 간의 상관 관계를 분석
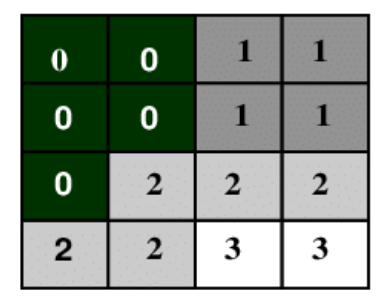
- 편집된 이미지와 원본 이미지 간의 텍스처 대비의 피어슨 상관 계수
- 거리가 커질 수록 1에 가까워짐 ⇒ 텍스처가 커지고 전역적
- 큰 이미지 텍스처는 이미지 편집에 대해 더 강인(영향을 덜 받는다)
- ex) 큰 건물 풍경 → 압축해도 손상될 가능성 적음/ 미세한 질감 → 압축하면 손상
- CNN의 한계 : 모델의 견고성과 일반화 능력을 향상시키기 위해서 장거리 정보를 포착할 수 있는 모델이 바람직
- CNN 모델은 장거리 정보를 통합할 수 없음 ⇒
Gram Block을 CNN 아키텍처에 도입
- CNN 모델은 장거리 정보를 통합할 수 없음 ⇒
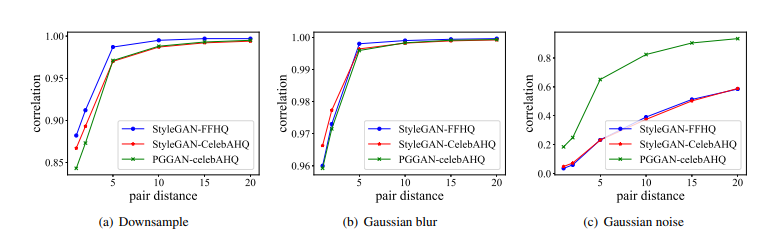
4.2 Gram-Net Architecture
- 전역 이미지 텍스처 정보를 다양한 의미적 수준에서 통합하기 위해
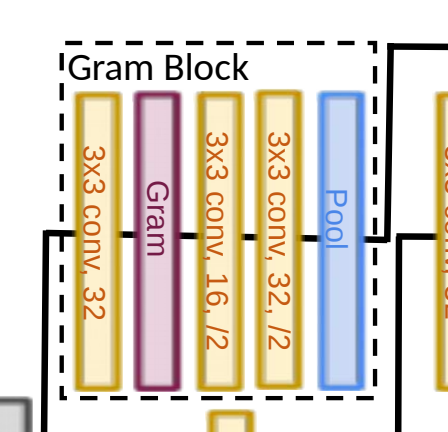
- Gram-Net은 ResNet 아키텍처에 Gram Block을 추가
- Gram 블록은 입력 이미지와 모든 다운 샘플링 계층 전에 블록이 추가
- Gram Block : 합성곱 계층 + Gram 매트릭스 계산 계층 + relu *2 + 풀링 계층
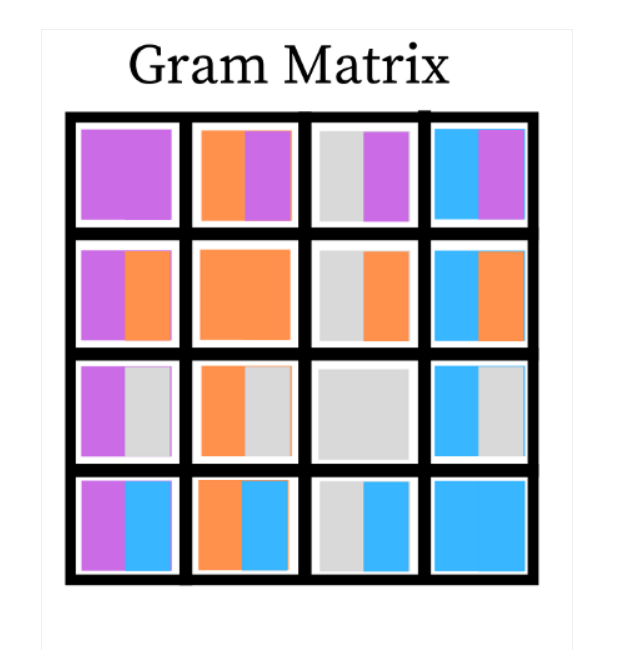
Gram matrix
- 텍스처와 스타일 정보를 캡처하는 데 사용
- 전역, 장거리 텍스처에게 좋음
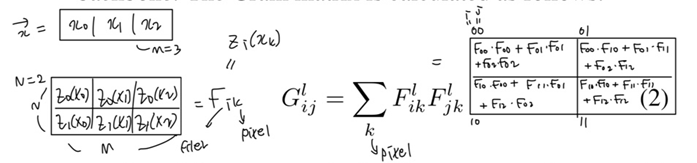
Can Gram matrix capture global texture information?
- F = 필터에 대한 응답 이미지의 집합
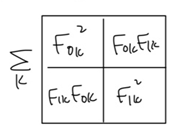
- CNN의 합성곱 계층에서, 각 필터는 이미지의 특정한 특징에 반응 ⇒ 특징 맵을 형성 ⇒ Gram 행렬은 이러한 특징 맵의 각 채널 간의 관계를 측정
- 대각선 항목 : 각 채널의 활성화 강도/ 그 외의 항목 : 다른 채널 간의 상호 관계
- G는 전체 특징 맵에 대한 설명자, CNN의 수용 필드에 제한받지 않음 ⇒ 특징 맵의 공간적 정보나 콘텐츠 정보를 무시하고, 텍스처 정보만을 포착
- 수용 필드 : CNN에서 필터(filter)나 커널(kernel)이 입력 이미지 또는 이전 레이어의 특징 맵에 적용되는 영역
- 3x3 크기의 필터 사용 ⇒ 한 번에 3x3 크기의 영역을 ‘보게’됨 ⇒ 수용 필드 : 3x3
- 장거리 텍스처 정보를 추출 가능
- 특징 맵 전체에 걸쳐 계산되므로, 지역적 특징만을 보는 것이 아니라 이미지의 넓은 영역에 걸친 텍스처 정보를 포착할 수 있음
- 패턴 포착에 유용
- 특징 맵 간의 내적을 통해 Gram 행렬은 각 특징이 어떻게 다른 특징들과 관련되어 있는지를 나타냄
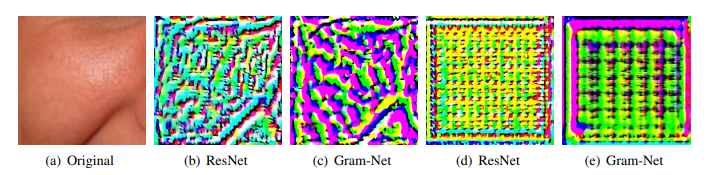
- 재구성된 입력의 시각화. 재구성된 이미지에는 보다 선명한 시각화를 위해 배율이 곱해짐
- (b)(c) ResNet과 GramNet에서 res-block2 특징을 재현하기 위해 재구성된 입력
- (d)(e) ResNet과 GramNet에서 평균풀을 재현하기 위해 재구성된 입력
- 그램넷에서 재구성된 이미지의 텍스처 크기는 ResNet보다 큼 ⇒ 장거리 텍스처 패턴을 Gram Net이 포착한다!
- 텍스처의 복잡도나 세부적인 특징을 파악 가능
5. Experiments
- 그램넷이 다양한 GAN 모델에 대해 보다 변하지 않는 특징을 추출하고 이미지 편집 작업에 보다 강력함
- 그램블록에 의해 이미지 텍스처 기능이 다양한 GAN에 걸쳐 더 변하지 않음을 보여주며 일반화 가능
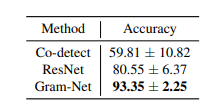
6. Conclusion
- 가짜 얼굴과 진짜 얼굴은 다른 텍스처를 갖는다
- 텍스처 정보가 클수록 이미지 편집에 더 강하고 다른 GAN 간에도 변하지 않음
- 텍스처 특징을 활용하여 가짜 얼굴 감지의 견고성과 일반화 능력을 향상하는 새로운 아키텍처인 그램넷을 제안
