https://zero123.cs.columbia.edu/
Abstract
-
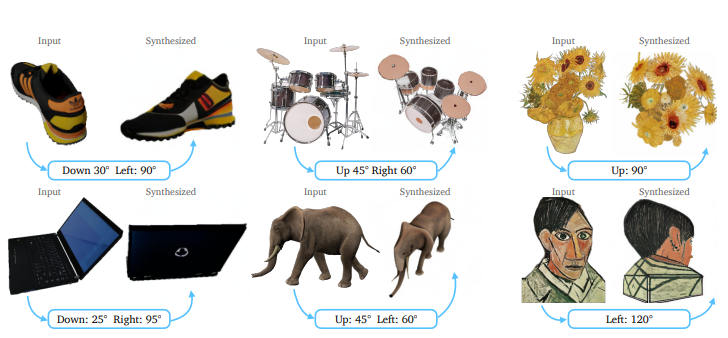
Zero-1-to-3는 단일 RGB 이미지 하나를 가지고 여러 시점 이미지 생성 가능함 -
기존에는 새로운 시점 합성을 수행하기 위해, 기하학적 사전 지식을 활용함
-
본 연구에서는 diffusion model이 합성 데이터를 사용해서 상대적 카메라 시점을 학습할 수 있으며 강력한 제로샷 일반화 능력을 유지함
-
단일 이미지에서 3D 재구성 작업에도 사용 가능함
1. Introduction
-
사람은 물체의 3D 모양과 외형을 상상할 수 있음
-
일반화 능력으로 실제로 물리적 세계에 존재하지 않는 객체의 3D 모양을 예측 가능
1) 사람은 일반화를 달성하기 위해 시각적 탐색을 통해 축적된 사전 지식에 의존 -
반면, 3D 이미지 재구성을 위핸 대부분의 접근 방식은 비싼 3D 주석에 의존함
1) stero view 혹은 camera pose와 같은 학습용 기하학적 정보가 필요
본 논문에서는 zero-shot 새로운 합성과 3D 형상 재구성을 수행하기 위해 Stable Diffusion과 같은 diffusion model에서 카메라 시점을 조작하는 메커니즘을 학습함
- 카메라 대응없이 2D 이미지에 대해 학습했고, 상대적인 카메라 회전과 translation에 대해 학습하도록 모델을 fine-tuning 가능함
대규모 diffusion model이 2D 이미지로만 훈련되었음에도 불구하고 풍부한 3D 사전 지식을 학습함을 보여줌
2. Related Work
2.1 3D generative models
-
이미지 생성 아키텍처와 대규모 image-text dataset의 결합으로 다양한 장면과 객체의 합성을 가능하게 함
1) 3D 도메인으로 확장하려면 비싸고 대량의 3D 데이터가 필요 -
NeRFs와 같은 기술은 고도로 실감 나는 장면 인코딩을 가능하게 하여, 단일 장면의 재구성 뿐만 아니라, 텍스트 입력으로부터 3D 객체와 장면을 생성하는 데 사용될 수 있음
-
본 연구는 viewpoint-conditioned(시점 조건부) image-to-image 변환 작업으로 모델링함
viewpoint-conditioned : 특정 시점, 관점을 조건으로 사용하여 다른 각도에서 본 것처럼 이미지를 생성함
- 또한 3D distillation과 결합하여 3D 모델링이 가능함
3D distillation : 2D, 저차원 데이터를 3D 생성하는 프로세스. 대규모 데이터를 사용해 3D 생성에 유용한 정보를 증류해서 3D 구조를 추출
- 따라서 본 연구는 학습된 언어 지식과 textual inversion을 이용해 image-to-3D 생성을 수행함
기존에 볼 수 없던 이미지에 대해서도 일반화하는 능력, 즉 제로샷 일반화를 실현
2.2 Single-view object reconstruction
-
단일 시점에서 3D 객체를 재구성하는 것은 해결할 문제
-
기존 방법들은 3D 형태를 메쉬, 복셀, 또는 포인트 클라우드와 같은 3D 기본 요소들로부터 구축하고, 이미지 인코더를 사용하여 이러한 3D 형태에 조건을 부과
1) 전역적인 조건부 설정 때문에 일반화 능력 제한
2) 포즈 추정도 필요 -
지역적으로 조건부된 모델은 더 넓은 범위의 일반화 능력을 보여줌
최근 연구인 MCC는 대규모 객체 중심 비디오 데이터셋에서 훈련되어, RGB-D 시점에서 3D 재구성을 위한 일반적인 표현을 학습
본 연구는 Stabel Diffusion 모델로부터 기하학적 정보를 직접 추출해서 3D 객체 재구성 문제에 대한 접근법 제시
3. Method
- Goal : 를 학습시키는 것
- : rotation / : translation
- 단일 RGB 이미지 와 relative camera rotation , translation 를 통해 새로운 이미지 생성
- 기존 diffusion은 viewpoint간의 correspondency를 명시적으로 인코딩하지 않음, 인터넷에 반영된 viewpoint bias가 존재

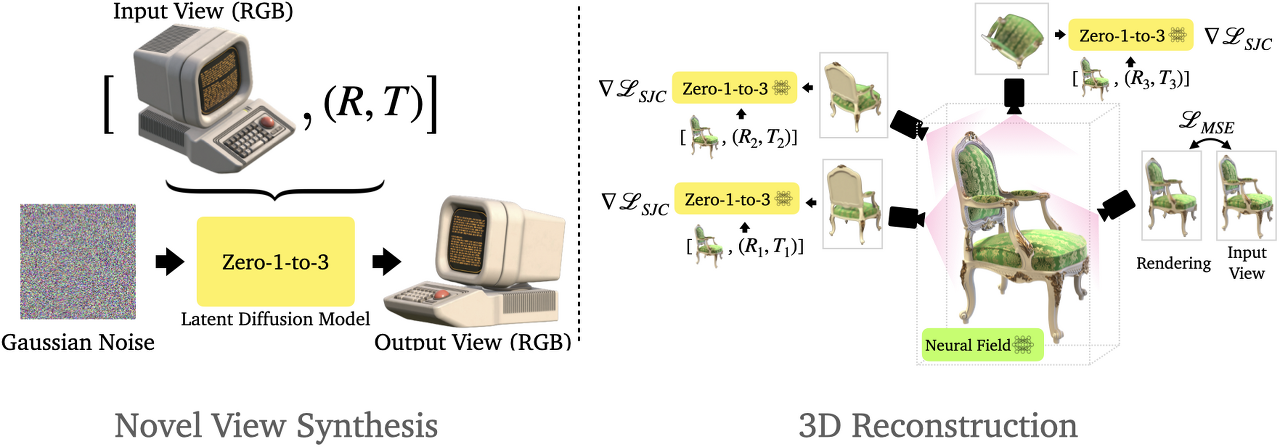
3.1. Learning to Control Camera Viewpoint
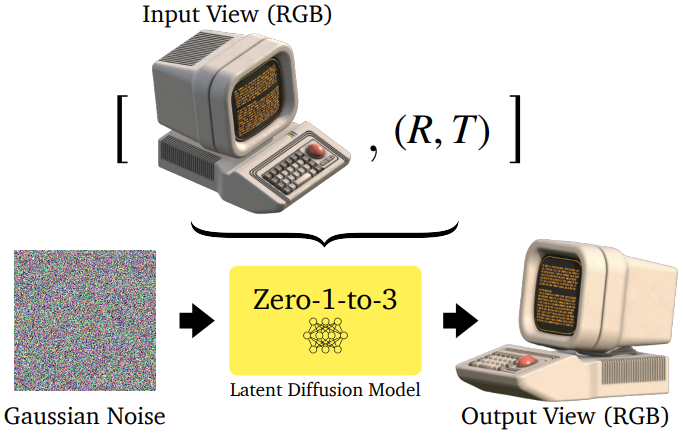
-
diffusion은 인터넷 대규모 데이터로 학습되어 시점은 사전 학습된 모델에서 제어할 수 없음
-
camera extrinsics 메커니즘을 모델에 학습할 수 있으면 새로운 view 합성이 가능함
-
: input image / : x 이미지에 대응하는 image pair / : camera otation, translation images
-
데이터셋이 주어지면 pre-ttrained diffusion model에 대해 fine-tuning 진행
-
latent diffusion 목적 함수 사용
- pose CLIP embedding
1) 를 CLIP에 태워 나온 CLIP feature에 camera transpose matrix를 concat한 결과
diffusion model를 fine-tuning하여 camera viewpoint에 대한 mechanism을 학습
3.2. View-Conditioned Diffusion
- 3D 재구성을 위해 고수준(유형, 기능, 구조), 저수준(깊이, 그림자, 텍스처)의 이해가 모두 필요
- Hybrid conditioning mechanism 제시
1) input image의 CLIP embedding + camera 를 concatenate하여 인 posed CLIP 형성 => 고수준의 semantics부여
2) denoising process에 channel concatenate => 정체성과 세부사항 유지
3.3. 3D Reconstruction
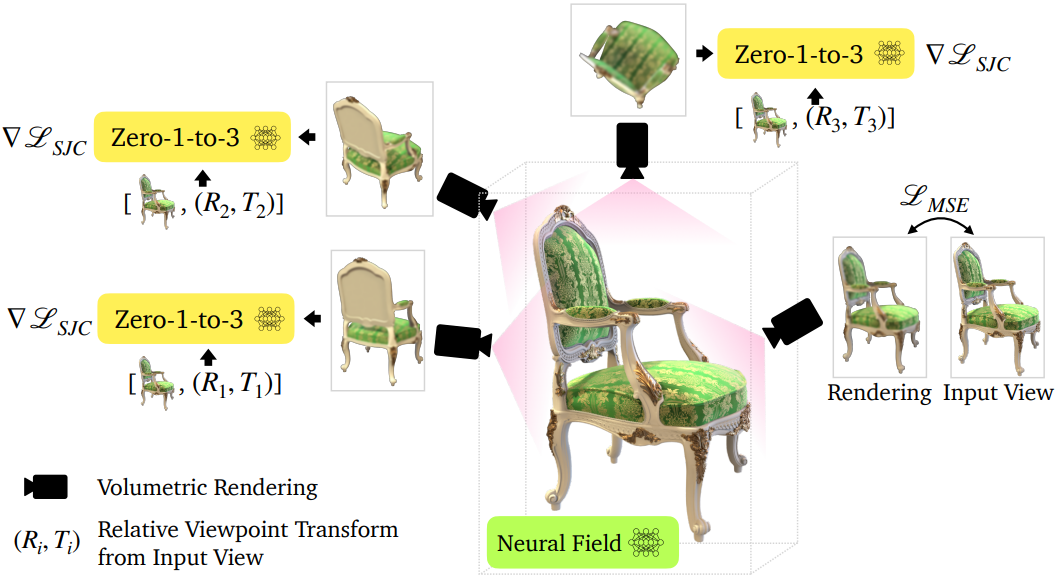
-
Score Jacobian Chaining (SJC) framework를 적용
1) random한 viewpoint에 volumetric rendering
2) Gaussian noise
3) Applying the U-Net denosier해서 denoise -
PAAS score : SJC에서 도입된 score
-
depth smoothness loss와 near-view consistency loss 추가
3.4. Dataset
- High-quality 3D model로 구성된 Objaverse dataset 이용
4. Experiments

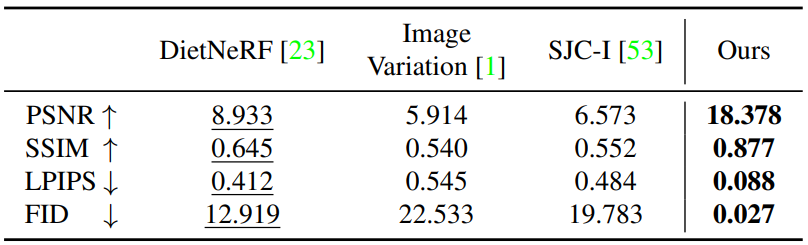
- 이하 생략
Summary
Pre-trained diffusion model을 의 데이터셋으로 fine-tuning하여 카메라 뷰를 새로 합성하고 SJC로 3d 생성