자, 전 포스트까지 읽었다면 질문이 들것이다.
아니 선생님, 그래서 어떻게 계산하는거죠?
Good Question!
좋은 질문이다.
사실 딥러닝을 활용하는 측면에 있어서는 이것에 대해서 수식까지 정확하게 알 필요는 없다고 생각한다.
오히려 특정 상황에 맞추어 각 변수들을 잘 조정하는 것이 훨씬 더 중요하다고 생각한다.
그러니 이해가 되지 않아도 그냥 눈으로 읽어보고 뭔지 모르겠으면 포스트의 마지막을 잘 기억하자
일단 loss function 에 대한 이해가 필요하다.
loss function = y - y'(y : 실제값, y' : 예측값)
loss function은 우리가 모델을 통해 예측한 값과 실제 값이 얼마나 떨어져 있는가? 에 대한 함수이다.
물론 정말로 그대로 빼기 연산을 하는 것은 아니고, 예를 들어 설명한 것이다.
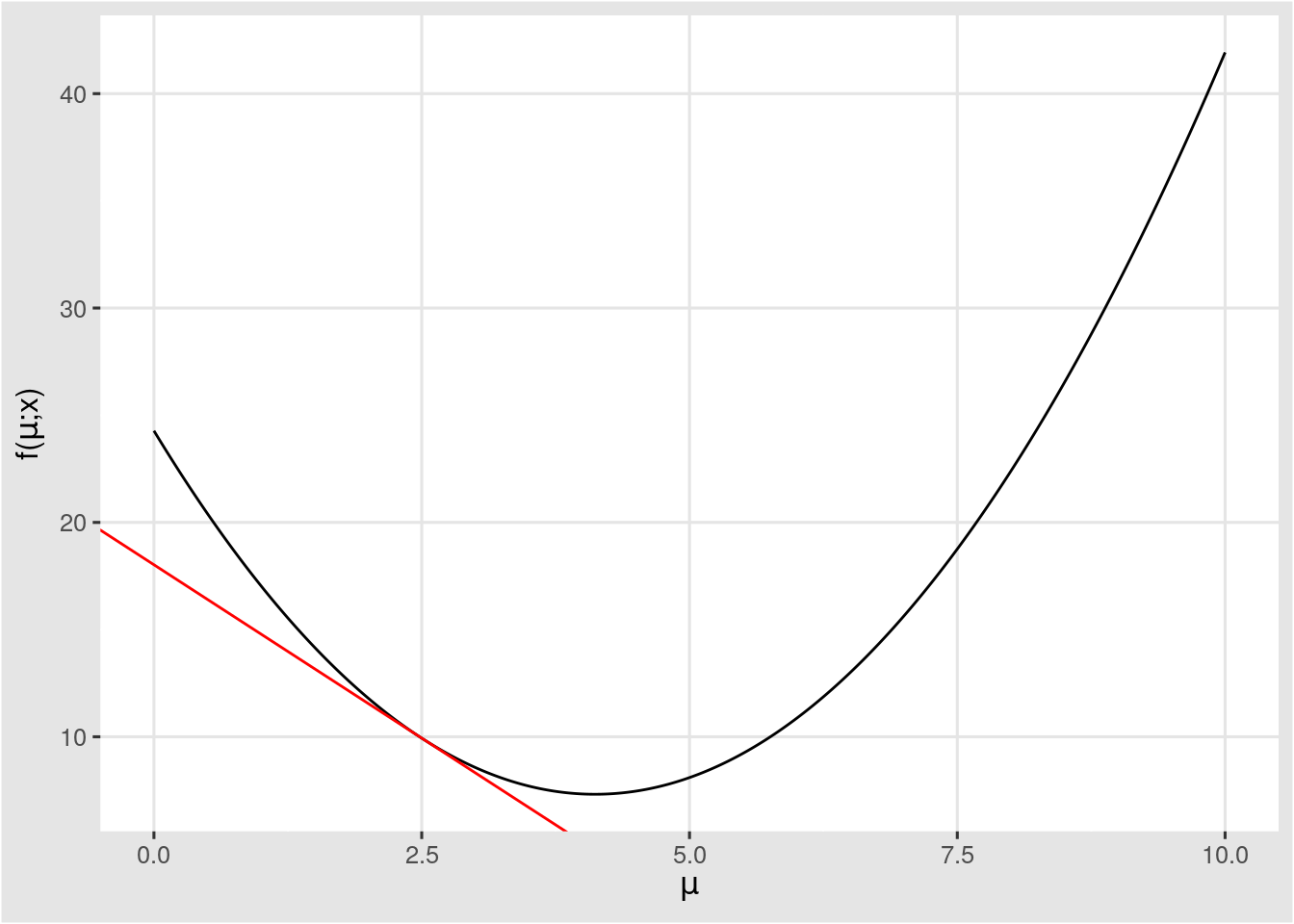
예를 들어, 위의 그림의 loss 값(y-y')이고, x 축이 parameter라고 해보자.
우리는 loss 값이 최소화 되는 것을 원하기 때문에 가장 작은 값을 찾아가려 한다.
어떻게 찾아가는 것이 좋겠는가?
Yes!
고등수학을 배우면 알 수 있다.
x에 대해서 미분하였을때 가장 낮은 값을 찾아가면 가장 최적의 parameter 값을 찾아갈 수 있다!
여기서 질문이 또 생길 수가 있다.
아니 선생님, 근데 저건 parameter가 하나밖에 없잖아요. 만약 parameter가 n개면 어떡합니까
그런 당신을 위해 준비했습니다!
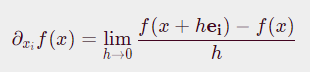
만약 parameter가 n개라면, ei(ei는 i번째만 1, 나머지 값은 0인 벡터)에 대해서 편미분을 해주면 해결이 가능하다.
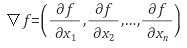
위 식을 옮겨서 nabla(역삼각형)를 z축으로, x는 parameter, y는 loss 로 3차원 그림을 그리면!
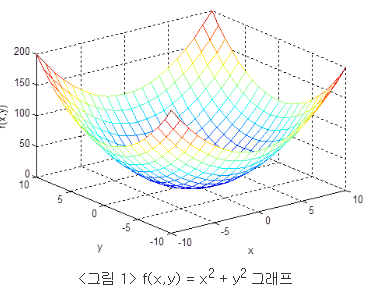
이런 아름다운 그림이 그려지게 되고, 우리는 저 가장 낮은 극값을 찾아가면 되는 것이다.
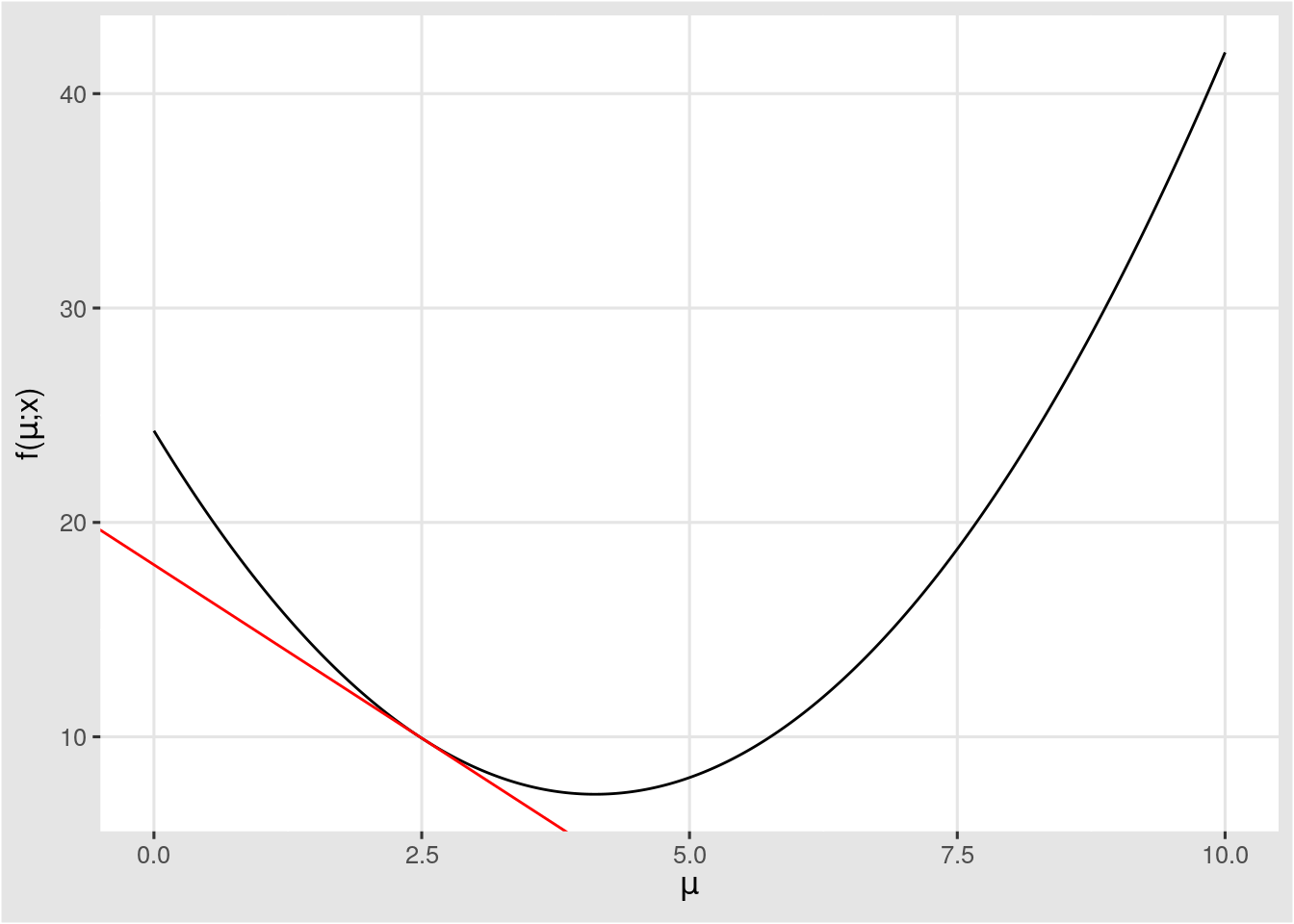
자 다시 이 그림으로 넘어와서, x에 대해서 미분하였을때 가장 낮은 값을 찾아가면 가장 최적의 parameter 값을 찾아갈 수 있다! 라는 것을 알았다.
아니 근데 다 일일히 계산해서 어떻게 찾아가나요;;
그리고 실제로 하다보면 저렇게 2차 곡선처럼 된게 아니라 울룩불룩하게 생겼는데 어떻게 계산하나요
그런 당신을 위해서 준비했습니다!
여기서 잠깐, Batch에 대해서 알아보고 가자.
Batch = (전체 test data를 쪼갠 것)
epoch = (반복횟수)
자 알았으면 됐다.
1. Batch Gradient Descent(BGD)
일명 BGD는 Train set 전체를 Batch로 쓰는 것이다.
모든 Train set에 대해서 error를 구하고 그 다음에 gradient를 업데이트 한다.
그렇기 때문에 업데이트를 자주 하지 않지만, 동시에 모든 Train data의 error값을 다 메모리에 저장해놔야하기 때문에 컴퓨터가 힘들어한다.
2. Stochastic Gradient Descent(SGD)
SGD는 Batch size = 1 이다. (batch size는 몇개씩 data를 자르는지)
즉 전체 Train data 중 1개만 가져와서 error를 계산한다.
그렇기 때문에 위에서 질문한 수많은 불룩한 부분(local minimum이라 부른다)에 빠질 가능성이 적다.
그렇지만 1개씩 찾아서 전체 데이터를 맞추려면 많은 epoch을 돌려야하고, 전체 중 가장 낮은 불룩한 부분(global minimum)을 찾기 힘들다.
3.Mini-batch Gradient Descent
그렇다. 위 2개를 읽다보면 도대체 어쩌라는 건지 모르겠다.
그런 당신을 위해 Mini-batch가 기다리고 있다.
mini batch 는 batch size를 일정량 만큼 정해서 쪼개서 사용하는 것이다.
예를 들어 100개의 train set, batch size를 5개 씩하면
20개의 batch들이 있고,
5번 error 계산하고 업데이트,
5번 error 계산하고 업데이트,
5번 error 계산하고 업데이트,
5번 error 계산하고 업데이트,
5번 error 계산하고 업데이트, ........를 반복한다.
따라서 batch size, epoch을 잘 설정해주면, local minimum에 빠지지 않고, 빠른시간내에 global minimum을 찾을 수 있다!
4.Momentum
아니 그래도 local minimum에 빠질 수 있는거 아닌가요?
맞다. 그래서 momemtum이 등장하였다.
momentum은 '관성'이라고 생각하면 쉽다.
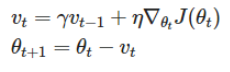
위와 같은 식을 더해줘서 현재 gradient가 0이더라도 관성때문에 밀려나게 되어 0이 되지 않게 한다.
5.adagrad
아니 그렇다고 다 더해버리면 어떡해요; 좀 적당히 더하면 더 좋지 않을까요?
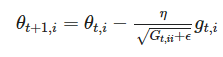
맞다. 그래서 adagrad는 learing rate을 지정하여 파라미터 업데이트가 빈번한 지점일수록 작게 더해준다.
6.adadelta
아니면 최근것만 더 하면서 최근것에 가중치를 둘 순 없나요?
물론 가능하다. 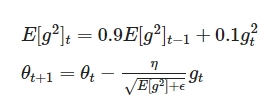
일반적으로 γ 값으로 0.9를, η값으로 0.001 지정하며, 최근것이 더 가중치를 가지게 된다.
7.Adam
음.. 알긴 하겠는데 그래서 뭘 쓰는게 일반적으로 좋나요..
그런 당신을 위해 준비했습니다!
잘 모르겠으면 그냥 Adam을 써라
adam은 위 (gradient에 제곱을 한것) + (gradient) 을 사용하여, momentum 까지 활용하였다.
다시 말하지만,
잘 모르겠으면 그냥 Adam을 써라
