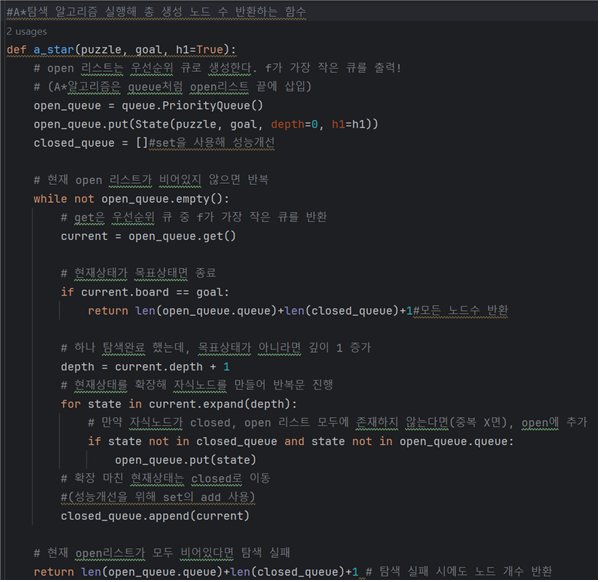
(단계1) A* Search 알고리즘 실행
1. 교재 77쪽 파이썬 프로그램 실행과정
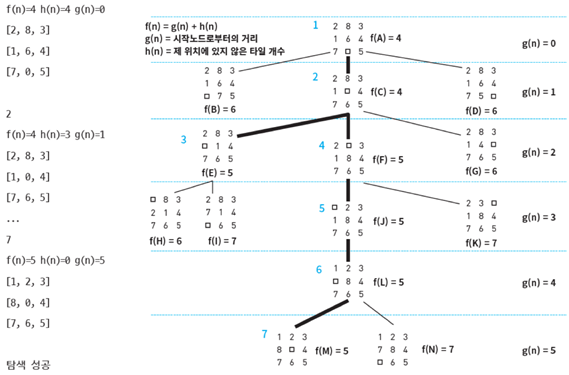
2. 실제 소스코드 및 주석 (파이참 사용)
코드를 입력하세요3. 실행결과
(단계2) 교재 77쪽의 프로그램 상에서 휴리스틱 함수 h1을 다음과 같이 h2로 수정하여 프로그램 실행
h1(N) = 목표상태와 비교하여 잘못 놓여진 타일의 개수
h2(N) = 각 타일의 현재위치와 목표위치 사이의 맨하탄 거리의 합
1. h2 메소드를 생성해 f 메소드를 h2+g로 수정
=> h2 메소드
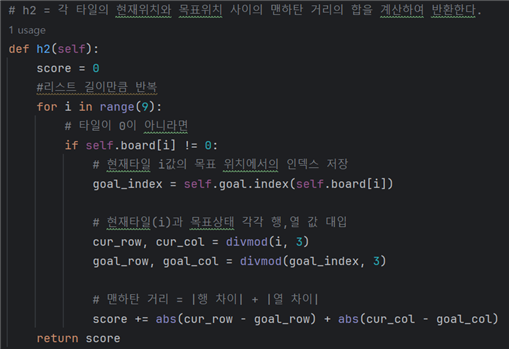
- 맨해튼 거리는 각 타일의 현재 행,열과 목표위치의 행,열의 차이 차이값의 합이다.
- 빈칸이 아닌 타일에 대해서만 반복한다.
- divmod() 메소드는 몫, 나머지를 동시에 반환해주는 내장함수다. 3*3 타일이므로 3으로 나눠주면, 각 인덱스의 몫이 행값, 나머지가 열값이 된다.
- 만약 divmod(5,3)이면 (1, 2) 결과를 반환해 타일5(i=5)가 1행 2열에 있음을 알 수 있다.
# h2 = 각 타일의 현재위치와 목표위치 사이의 맨하탄 거리의 합을 계산하여 반환한다.
def h2(self):
score = 0
#리스트 길이만큼 반복
for i in range(9):
# 타일이0이 아니라면
if self.board[i] != 0:
# 현재타일i값의 목표 위치에서의 인덱스 저장
goal_index = self.goal.index(self.board[i])
# 현재타일(i)과 목표상태 각각 행,열 값 대입
cur_row, cur_col = divmod(i, 3)
goal_row, goal_col = divmod(goal_index, 3)
# 맨하탄 거리= |행 차이| + |열 차이|
score += abs(cur_row - goal_row) + abs(cur_col - goal_col)
return score
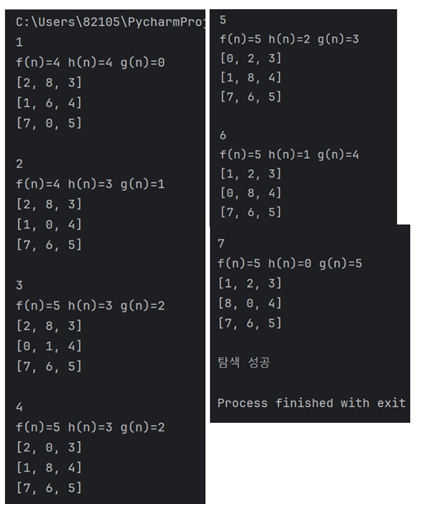
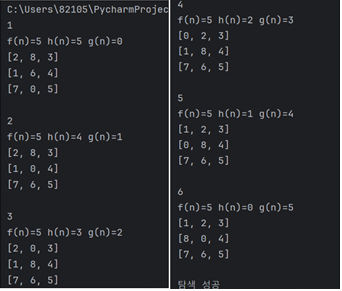
2. h2로 실행결과
- h1을 사용했을 때보다 깊이가 6으로 1줄어든 것을 볼 수 있다.
- 이 초기상태에 대해서는 h2가 h1보다 더 효율적인 휴리스틱 함수다.
(단계3) h1과 h2 각각에 대해 탐색 알고리즘의 효율성을 비교
랜덤하게 설정된 10가지의 서로다른 초기상태 각각에 대해 h1을 사용한 탐색비용과 h2를 사용한 탐색 비용을 비교
탐색비용은 탐색과정에서 생성된 모든 노드의 개수
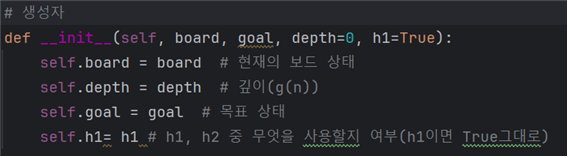
1. boolean형 h1 필드를 추가해 h1을 사용하면 True, h2면 false로 동작하게 한다.
- 객체 생성 시 생성자에 인자를 전달해 h1, h2를 선택해 사용할 수 있도록 해준다.
- get_new_board 메소드의 State생성사 호출 부분에도 self.h1을 추가해 해당 휴리스틱 함수로 객체를 생성하도록 해준다.
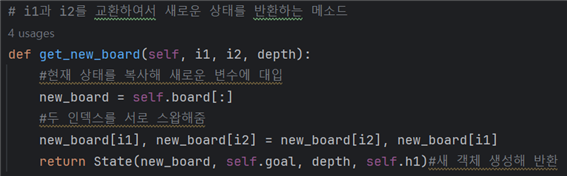
- 이때 h1 메소드의 이름을 필드 h1과 중복되지 않도록 h1_heuristic으로 변경해준다.
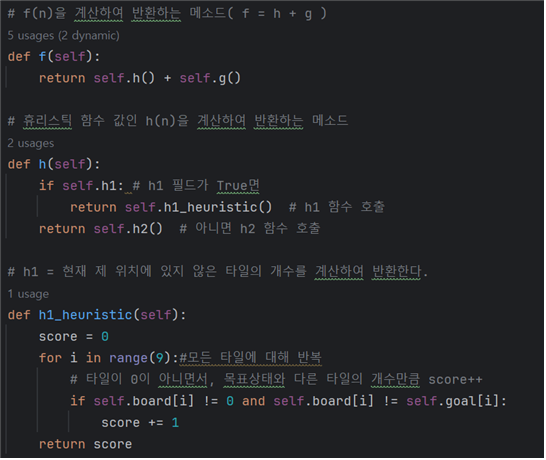
- h 메소드를 생성해 if 문으로 h1의 값에 따라 h1_heuristic(), h2() 메소드를 호출해주도록 한다.
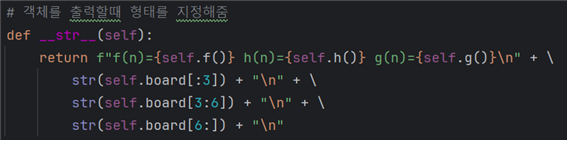
- str 메소드 또한 h를 호출하도록 변경해준다.
2. A* 알고리즘을 사용해 탐색과정에서 생성된 전체노드 수 반환하는 메소드 a_star() 메소드 생성
- open_queue의 개수 + closed_queue의 개수 + 최종 노드 1개를 더해 return 해준다.
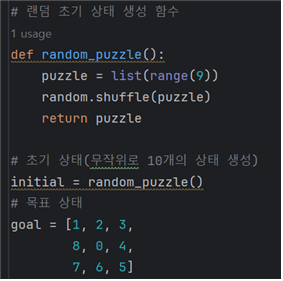
3. 초기 상태를 랜덤하게 반환해주는 random_puzzle() 메소드 생성
- random.shuffle() 메소드로 0~9를 섞어 리스트를 생성해 initial 변수에 대입한다.
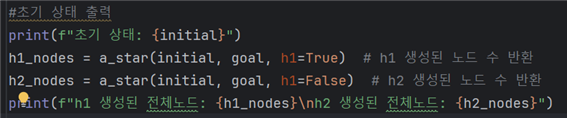
4. 각 초기상태에 대해 h1, h2를 각각 실행한 결과를 출력해준다.
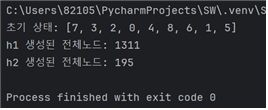
5. 실행 결과(총 10개의 case)
- h1보다 h2의 탐색비용이 확연히 낮아 더 효율적이었다.
case1
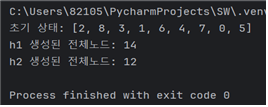
case2
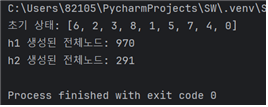
case3
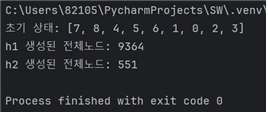
case4
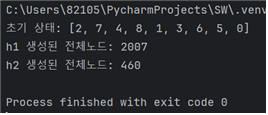
case5
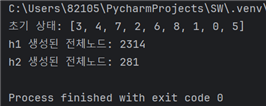
case6
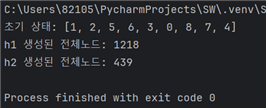
case7
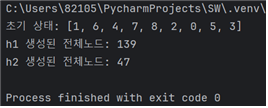
case8
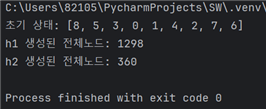
case9
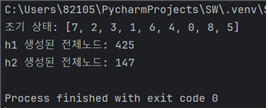
case10

하