1. 목표
sklearn 라이브러리의 Iris data를 기반으로 한 인공 신경망 모델을 구축해야 한다. 이때 Iris data에는 샘플이 3가지 클래스에 대해서 각 50개씩으로, 총 150개의 샘플이 포함되어 있다.
그리고 4개의 실수값으로 구성된 4차원 벡터인 샘플과 3개의 클래스(품종)를 가지고 있다. 따라서 최종적으로 3개의 클래스를 분류하는 다층 퍼셉트론(Multi-Layer Perceptron, MLP)을 구현하여 이를 학습하고, 결과를 분석해야 한다.
2. 기존 XOR 분류 신경망
1. 소스코드 분석에 관한 주석
import numpy as np
# 시그모이드 함수를 그대로 풀어놓은 것
def actf(x):
return 1 / (1 + np.exp(-x))
# 미분된 시그모이드 함수, 시그모이드 함수 출력값 f(x)를 입력(out)으로 가짐
def actf_deriv(out):
return out * (1 - out)
# 입력유닛의 개수, 은닉유닛의 개수, 출력유닛의 개수(튜플), 학습률=0.2
inputs, hiddens, outputs = 2, 2, 1
learning_rate = 0.2
# 훈련 샘플 X와 정답 T
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
T = np.array([[0], [1], [1], [0]])
W1 = np.array([[0.10, 0.20], [0.30, 0.40]])#x1, x2의 가중치
W2 = np.array([[0.50], [0.60]])#z1, z2의 가중치
B1 = np.array([0.1, 0.2])#입력층 바이어스
B2 = np.array([0.3])#은닉층 바이어스
# 순방향 전파 계산(학습된 가중치와 편향을 활용해 입력에 따른 정답 예측)
def predict(x):
layer0 = x #입력을 layer0에 대입한다.
# W1(2*2)와 입력L0(2*1)의 행렬곱으로 은닉층의 출력 계산
# z1=f1(w11x1 + w21x2 + b1),f2(w12x1 + w22x2 + b2) 구함
Z1 = np.dot(layer0, W1) + B1
layer1 = actf(Z1) #그리고 z1에 대해 활성화 함수를 적용한다.
# W2(1*2)와 입력L1(2*1) 행렬곱으로 출력층의 출력 계산
# z2=f3(w13y1 + w23y2 + b3) 구함
Z2 = np.dot(layer1, W2) + B2
layer2 = actf(Z2) #그리고 활성화 함수를 적용한다.
return layer0, layer1, layer2 #L2가 결국 최종 출력값이다.
# 역방향 전파 계산(데이터와 정답을 이용한 학습)
def fit():
global W1, W2, B1, B2 # 우리는 외부에 정의된 변수를 변경해야 한다.
for i in range(90000): # 9만번 반복한다.(모든 데이터가 1회 학습=1epoch, 90000epoch 의미)
# 한번에 1개 데이터 연산한 후 가중치를 변경 = 배치크기 1(1개 연산하고 w변경하는, 그때그때 변경)
for x, y in zip(X, T):
x = np.reshape(x, (1, -1)) # 2차원 행렬로 만든다. ①[0,0]->[[0,0]]으로
y = np.reshape(y, (1, -1)) # 2차원 행렬로 만든다. [0]->[[0]]으로
layer0, layer1, layer2 = predict(x) # 입력x에 대한 순방향전파 계산해서 대입
#출력층<->은닉층간의 출력층 델타 계산
# 오차(델타)={예측값(L2)-정답(y)}f'()
layer2_error = layer2 - y # 실제값(L2)-정답(y) 계산
layer2_delta = layer2_error * actf_deriv(layer2) # f'()곱해 출력층의 델타 계산
#은닉층<->입력층간의 은닉층 델타 계산
layer1_error = np.dot(layer2_delta, W2.T) # 은닉층의 오차 계산 ②
layer1_delta = layer1_error * actf_deriv(layer1) # 은닉층의 델타 계산 ③
#가중치W 갱신
#델타가 (1*1)이므로, L1(2*1)을 .T사용해 전치행렬(1*2)로 변경,
#그래서 델타(1*1)*L1(1*2)가 가능해짐
#갱신된 W(t+1)는 기존 W(t) - (학습률 * 델타 * 출력값)로 구한다.
W2 += -learning_rate * np.dot(layer1.T, layer2_delta) # ④
W1 += -learning_rate * np.dot(layer0.T, layer1_delta) #
#바이어스b 갱신(기존 출력값이 1이므로, 그냥 sum으로 해도 된다.)
B2 += -learning_rate * np.sum(layer2_delta, axis=0) # ⑤
B1 += -learning_rate * np.sum(layer1_delta, axis=0) #
# 모든 데이터에 대해 predict() 실행 테스트
def test():
for x, y in zip(X, T):#zip에는 입력X(00,01,10,11), 출력T(0,1,1,0)가 존재
#연산을 위해 입력을 [0,0](1*2행렬)을 2차원 행렬[[0,0]](2*1행렬)로 만든다.
x = np.reshape(x, (1, -1))
layer0, layer1, layer2 = predict(x)
print(x, y, layer2) # 출력층의 값을 출력해본다.
fit()
test()2. 해당 다층 퍼셉트론 구조 시각화
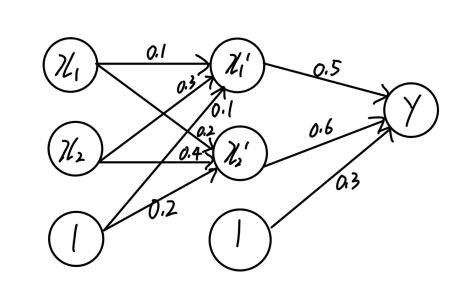
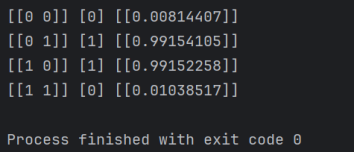
3. 실행결과
입력, 정답, 출력 순으로 결과가 나오고, 90000 epoch로 학습하니 확실히 정답에 거의 근접한 수치가 나오는 것을 볼 수 있다.
3. iris data 분류 신경망 코드 분석
1. 사용된 라이브러리
- numpy: 수학적 계산 및 행렬 연산을 위한 라이브러리
- scikit-learn: iris data를 사용하기 위한 라이브러리
- Matplotlib: 손실 함수의 변화를 보다 직관적인 그래프로 시각화하기 위한 라이브러리
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
import matplotlib.pyplot as plt2. 데이터 로드 및 전처리
2.1 데이터 로드
- iris 데이터셋에서 4개의 실수 특성을 x에, 3개의 클래스(품종)을 y에 저장한다.
# 데이터 로드 및 전처리
iris = load_iris()
X = iris.data # 특성 4개 (입력 데이터)
y = iris.target.reshape(-1, 1) # 레이블 (클래스)2.2 원-핫 인코딩(One-Hot Encoding)
- 원-핫 인코딩은 클래스 레이블을 신경망 모델에서 처리할 수 있는 형식으로 변환해 준다.
- fit_transform() 메소드로 y배열을 원-핫 벡터로 변환한다.
# 원-핫 인코딩
encoder = OneHotEncoder(sparse=False)
y = encoder.fit_transform(y)2.3 훈련 데이터와 테스트 데이터 분리
- train_test_split() 메소드로 훈련데이터(80%)와 테스트데이터(20%)로 분할해 준다. (random_state=42는 랜덤 시드 값이다.)
# 훈련 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)3. 신경망 초기화
3.1 네트워크 구조
- 입력층=4, 은닉층=5, 출력층=3, 학습률=0.01, epoch=50으로 각각 명시해준다.
# 파라미터 설정
input_nodes = 4 # 입력층 노드 수
hidden_nodes = 5 # 은닉층 노드 수
output_nodes = 3 # 출력층 노드 수
learning_rate = 0.01 # 학습률
epochs = 503.2 가중치 및 편향 초기화
- np.random.uniform(-1,1,size)를 사용해, 가중치 및 편향을 –1과 1 사이의 랜덤값으로 초기화해준다.
# 가중치와 편향 초기화 (랜덤 값)
W1 = np.random.uniform(-1, 1, (input_nodes, hidden_nodes)) # 입력층 -> 은닉층 가중치
B1 = np.random.uniform(-1, 1, (1, hidden_nodes)) # 은닉층 바이어스
W2 = np.random.uniform(-1, 1, (hidden_nodes, output_nodes)) # 은닉층 -> 출력층 가중치
B2 = np.random.uniform(-1, 1, (1, output_nodes)) # 출력층 바이어스4. 시그모이드 함수 메소드
- 기존 XOR때와 같이 시그모이드 함수를 활성화 함수로 사용한다.
- 시그모이드 함수는 0~1 사이의 값을 출력하는 함수이다.
# 시그모이드 함수를 그대로 풀어놓은 것
def actf(x):
return 1 / (1 + np.exp(-x))
# 미분된 시그모이드 함수, 시그모이드 함수 출력값 f(x)를 입력(out)으로 가짐
def actf_deriv(out):
return out * (1 - out)5. 순방향 전파 메소드
- 주어진 입력 x에 대해 신경망을 통과시켜 각 층의 출력을 반환하는 메소드다.
- 이때 행렬곱을 이용하여 각 층의 출력 Z를 계산한다.
# 순방향 전파 계산(학습된 가중치와 편향을 활용해 입력에 따른 정답 예측)
def predict(x):
layer0 = x #입력을 layer0에 대입한다.
# W1(4*5)와 입력L0(4*1)의 행렬곱으로 은닉층 Z1계산
Z1 = np.dot(layer0, W1) + B1
layer1 = actf(Z1) #그리고 z1에 대해 활성화 함수를 적용한다.
# W2(5*3)와 입력L1(5*1) 행렬곱으로 출력층 Z2계산
Z2 = np.dot(layer1, W2) + B2
layer2 = actf(Z2) #그리고 활성화 함수를 적용한다.
return layer0, layer1, layer2 #L2가 결국 최종 출력값이다.
6. 역방향 전파 및 학습 메소드
- 예측값과 실제값의 차이(layer_error)에 시그모이드 함수의 미분을 곱해 그래디언트를 구했다.
- 그래디언트 기반의 경사 하강법(Gradient Descent)으로 가중치와 편향을 업데이트하며 학습을 진행한다.
- 각 epoch마다 손실값을 계산하고 이를 기록하도록 했다. 그리고 학습 과정 중에 손실값을 출력하여 학습 상태를 확인할 수 있게 했다.
#손실값 기록
losses = []
# 역방향 전파 계산(데이터와 정답을 이용한 학습)
def fit():
global W1, W2, B1, B2, losses # 우리는 외부에 정의된 변수를 변경해야 한다.
for epoch in range(epochs): #50 epoch 반복
epoch_loss = 0
# 한번에 1개 데이터 연산한 후 가중치를 변경 = 배치크기 1
for x, y in zip(X_train, y_train):
x = np.reshape(x, (1, -1)) # 2차원 행렬(4*1)로 만든다. ①
y = np.reshape(y, (1, -1)) # 2차원 행렬(3*1)로 만든다.
# 각 층별순방향 계산
layer0, layer1, layer2 = predict(x)
#출력층<->은닉층간의 델타 계산
# 오차(델타)={예측값(L2)-정답(y)}f'()
layer2_error = layer2 - y # 예측값(L2)-정답(y) 계산
layer2_delta = layer2_error * actf_deriv(layer2) # f'()곱해 출력층의 델타 계산
#은닉층<->입력층간의 델타 계산
layer1_error = np.dot(layer2_delta, W2.T) # 은닉층의 오차 계산 ②
layer1_delta = layer1_error * actf_deriv(layer1) # 은닉층의 델타 계산 ③
#가중치W 갱신
#(갱신된 W(t+1)는 기존 W(t) - (학습률 * 델타 * 출력값)로 구한다.
W2 += -learning_rate * np.dot(layer1.T, layer2_delta) #④은닉층->출력층
W1 += -learning_rate * np.dot(layer0.T, layer1_delta) #입력층->은닉층
#바이어스b 갱신
#(기존 출력값이 1이므로, 그냥 sum으로 해도 된다.)
B2 += -learning_rate * np.sum(layer2_delta, axis=0) #⑤출력층
B1 += -learning_rate * np.sum(layer1_delta, axis=0) #은닉층
#손실 계산
epoch_loss += np.mean((y - layer2)**2)
# 매 epoch마다 손실 출력
losses.append(epoch_loss / len(X_train))
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {epoch_loss / len(X_train):.4f}")7. 테스트 메소드
- 이 함수는 테스트 데이터를 순방향 전파에 입력하여 예측을 수행하고, 예측값과 실제값을 비교해 정확도를 계산해준다.
- 이 과정을 통해 모델이 얼마나 잘 학습되었는지 확인할 수 있게 된다.
# 모든 데이터에 대해 predict() 실행하여 테스트
def test():
predictions = [] # 예측값과 실제값을 저장할 리스트
for x, y in zip(X_test, y_test): # X_test와 y_test의 데이터를 한 쌍씩 처리
#연산을 위해 입력 데이터를 (1*4) 모양의 2차원 배열로 변환
x = np.reshape(x, (1, -1))
#순방향 전파를 통해 예측값 계산
layer0, layer1, layer2 = predict(x)
# 예측값 중 가장 큰 값의 인덱스를 예측 클래스로 선택
predicted_label = np.argmax(layer2)
true_label = np.argmax(y)# 실제 클래스 레이블을 인덱스로 변환 (one-hot 인코딩 해제)
# 입력값, 실제 레이블, 예측 레이블을 저장
predictions.append((x, true_label, predicted_label))
print(f"Input: {x}, True Label: {true_label}, Predicted Label: {predicted_label}")
# 정확도 계산(실제 레이블과 예측 레이블이 일치하는 비율을 계산)
accuracy = np.mean([true == pred for _, true, pred in predictions])
print(f"\nTest Accuracy: {accuracy * 100:.2f}%")8. main 코드
- 학습 전 weight와 bias를 출력하고, fit()을 통해 50 epoch만큼 학습한 뒤의 weigth와 bias를 출력하도록 했다.
- 최종적으로 test() 메소드를 호출해 해당 신경망이 잘 훈련되었는지 검사해준다.
# 가중치와 편향 초기화 선언
print(f"초기 은닉층 가중치 W1: {W1}")
print(f"초기 출력층 가중치 W2: {W2}")
print(f"초기 은닉층 편향 B1: {B1}")
print(f"초기 출력층 편향 B2: {B2}")
print("\n")
#학습 시작
fit()
# 훈련 후 업데이트된 가중치와 편향 값 출력
print("\n훈련 후 업데이트된 가중치와 편향 값:")
print(f"최종 은닉층 가중치 W1: {W1}")
print(f"최종 출력층 가중치 W2: {W2}")
print(f"최종 은닉층 편향 B1: {B1}")
print(f"최종 출력층 편향 B2: {B2}")
print("\n")9. 손실 그래프
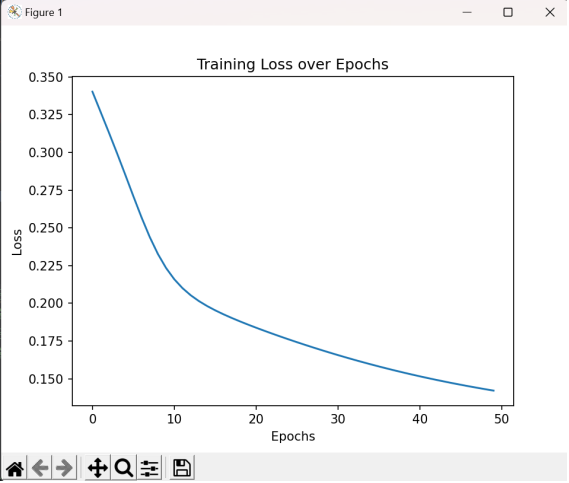
- Matplotlib 라이브러리를 사용해 x축을 epoch, y축을 loss로 설정하여, 학습 과정에서 epoch에 따라 loss가 어떤 형태를 갖는지 출력한다.
- 결론적으로 학습이 진행될수록 loss가 감소해야 하므로 우하향하는 그래프가 잘 나오는지 확인한다.
# 손실 그래프 시각화
plt.plot(losses)
plt.title("Training Loss over Epochs")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()4. 실행 결과 분석
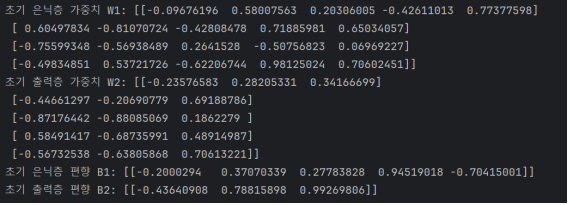
1. 학습 전 초기 가중치(w)와 편향(b)출력
- 모델이 처음 시작할 때의 가중치와 편향 값들이다. 이 값들은 랜덤으로 초기화된다. W1은 입력층->은닉층으로 가는 가중치 행렬이고, B1은 은닉층의 편향 벡터다.
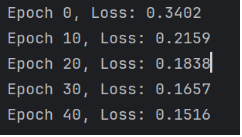
2. 학습 중 epoch가 10씩 증가할 때마다 손실(Loss) 출력
- 총 50 epoch동안의 Loss 변화를 보이기 위해 10마다 Loss값을 출력했다.
- 학습이 진행될수록 점점 Loss가 줄어드는 것으로 보아 학습이 진행될수록 더 정확하게 학습하고 있다는 증거이다.
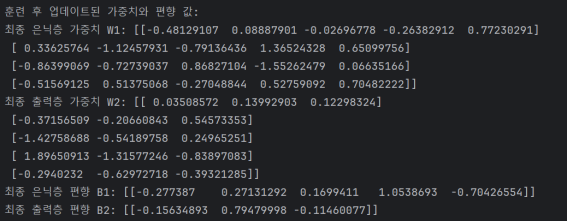
3. 학습 후 초기 가중치(w)와 편향(b)출력
- 학습이 끝난 후 보다 더 정확해진 모델의 가중치와 편향값을 출력한다.
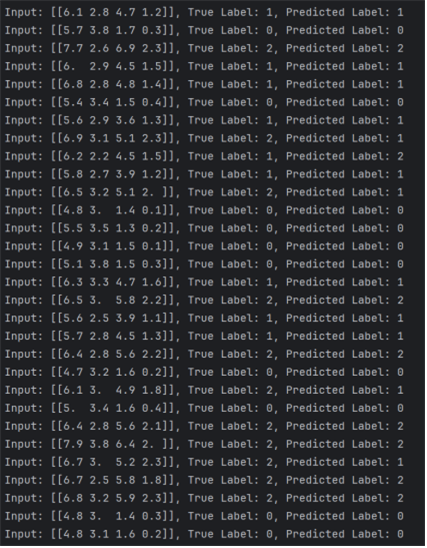
4. 테스트 데이터 30개에 대한 예측 결과 출력
- 각 입력값에 대해 모델이 예측한 클래스와 실제 정답을 비교한 결과를 각 데이터마다 총 30회 출력한다.
- 첫번째 입력을 예로 보면 모델이 결과를 1로 예측했으며, 실제 정답도 1로 일치하는 결과를 보인다.
5. 테스트 정확도 출력
- 모델이 테스트 데이터들에 대해 얼마나 정확하게 예측했는지를 %로 출력한다.
- 이 정확도 값은 매 실행 시마다 달라졌으며, 최저 60%에서 크게는 83%정도를 보였다.
- 이 예시에서는 모델이 83.33%의 정확도를 달성했으며 좋은 정확도를 보였다.

6. epoch에 따른 Loss변화를 그래프로 출력
5. 개선 방안 및 고찰
1. 다른 활성화 함수 사용
현재 시그모이드 함수를 사용하면 출력 범위가 0~1로 제한되어 기울기가 매우 작아지는 경우가 많다. 따라서 시그모이드 함수 대신 ReLU를 활성화 함수로 사용한다면, 학습 속도를 개선하고 성능을 크게 향상시킬 수 있을 것이다.
2. 학습률 조정
현재는 0.01로 고정된 학습률을 사용하고 있는데, 이런 경우 모델이 최적의 최소값에 수렴하는데 어려움을 겪을 수 있다.
따라서 학습률을 감소시켜 더 정밀한 파라미터 업데이트를 할수 있게 한다면 더 좋을 것이다.
3. 훈련 데이터에 대한 검증
훈련 데이터만으로 모델을 학습하고 성능을 평가하는 것은 과적합(overfitting)을 유발할 수 있다. 따라서 데이터를 분류할때 훈련데이터 80%, 검증데이터 10%, 테스트 데이터 10%처럼 분류 한 후, 모델을 훈련할 때마다 검증 데이터를 통해 성능을 평가하는 것이 좋다.
4. 모델 구조 변경(더 나은 파라미터값)
현재는 매우 작은 노드 수와 epoch를 사용하고 있기에 아무래도 학습의 정확도가 조금은 떨어질 수 있다. 그래서 은닉층의 노드 수나 층수, epoch값 등을 조정한다면 더 정확하고 정밀한 학습을 통해 성능을 향상시킬 수 있다.
5. 고찰
우선 코드를 구현할 때 최대한 딥러닝 프레임워크나 라이브러리(TensorFlow, pyTorch 등)의 도움 없이 구현하려고 노력했다.
수학적 계산과 원리를 기반으로 밑바닥부터 다층 퍼셉트론(MLP)의 모든 구성 요소(가중치 초기화, 순방향, 역방향 전파, 경사 하강법 등)들을 구현해보면서, 모델을 더 자세히 이해할 수 있었다.
또한 앞서 말한 개선 방안들을 적용한다면, 현재 정확도인 83.33%보다 훨씬 높은 정확도를 가진 모델을 만들 수 있을 것이라고 생각한다.
