이 글에서 사용되는 방법은 충분히 검증되지 않았고, DynamoDB의 특성상 추천하지 않는 방법입니다.
왜 자동 증분키?
DynamoDB
Dynamodb는 UUID 같은 유니크키를 파티션키로 하라고 추천하고 있으며 심지어 Amplify CLI를 사용시에는 데이터 삽입시 VTL에서 파티션키가 없으면 UUID 로 자동 생성해주기까지 합니다.
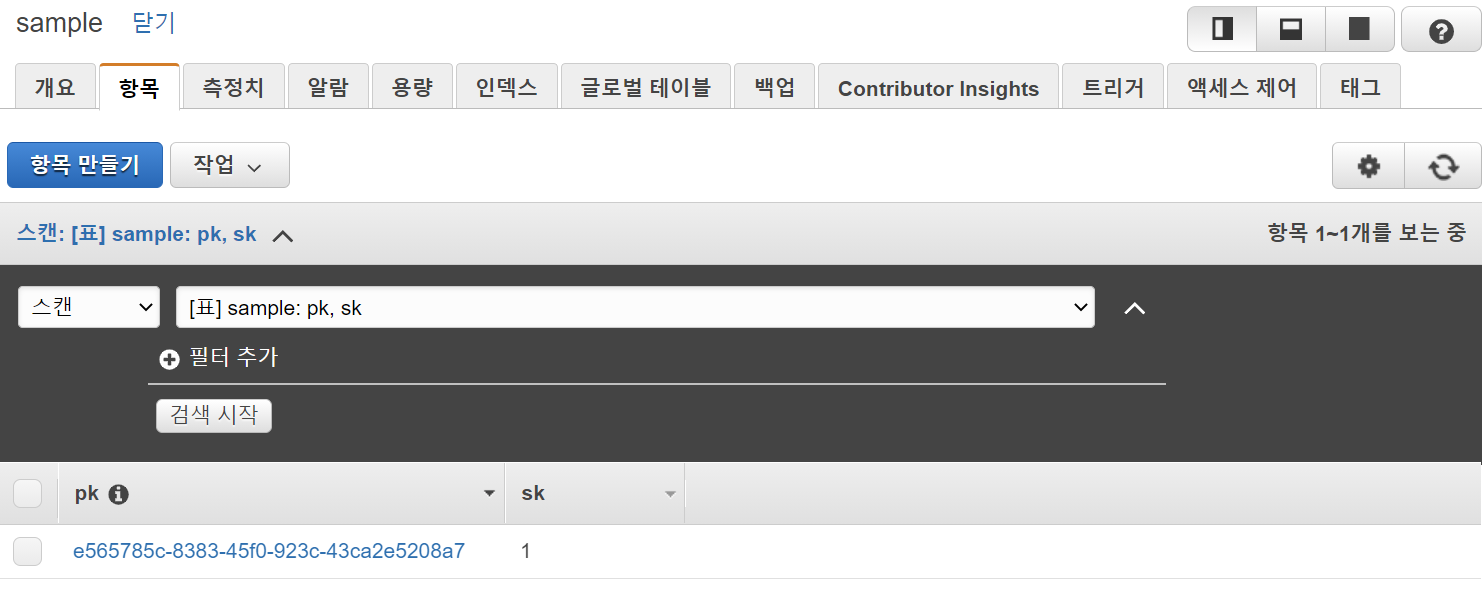
하지만 이런 UUID는 하나의 큰 문제가 있습니다.
그것은 바로 이쁘지 않다 는 문제입니다.

Mobile
일반적인 모바일 애플리케이션의 프론트 영역에서는 유저에게 라우팅 경로를 보여주지도 않고, 따로 사용자가 데이터를 입력해서 접근하지도 않습니다. (url 런쳐 케이스 제외)
하지만 모바일이 아닌 웹으로 가면 어떻게 보일까요?
웹에서 파티션키를 파라메터로 받아와서 쿼리를 해야한다면, 바로 여기서 이쁘지 않다라는 문제가 발생합니다.
Web

위의 사진을 보듯이 웹브라우져에서는 주소창이 존재하여 라우팅 경로를 알 수 있고 또한 직접적인 경로 수정이 가능합니다.
하지만 이러한 경로에 UUID가 들어가게 된다면?
단순 미관상의 이유 일 수도있고, 또한 유저입장에서는 다음 컨텐츠를 찿을 수 없는 문제일 수도 있습니다.
(물론 이걸 신경쓰는 사람이 있을지는 모르겠으나...)
여기서 이러한 UUID방식이 아닌 일반적으로 RDBMS에서 많이 사용되는 자동증분(AUTO_INCREMENT)방식이 필요하다는 니즈가 발생합니다.
방법론
이러한 문제를 해결하기 위한 방법은 여려가지가 있습니다.
-
현재 입력되있는 값을 쿼리 또는 스캔하여 최근 업로드 된 데이터의 파티션키를 가져와서 증분하여 사용한다.
-
키 테이블을 따로 만들어 데이터가 입력시 원자성 카운터(https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/WorkingWithItems.html#WorkingWithItems.AtomicCounters)를 사용하여 키 테이블의 값에서 증분하여 사용한다.
이외에 더 많은 방법이 있겠지만, 위와 같은 방법 중 이 글에서는 두번째 방법을 사용할 것입니다.
첫번째 방법의 경우 파티션키와 범위키로 기존 아이템이 특정이 되고 첫쿼리에 대한 데이터를 가지고 있을때 추가적인 쿼리가 필요 없다는것이 장점입니다. 하지만 이 방법의 문제는 쿼리가 명확하게 특정되지 않을시 스캔을 통하여 최근 업로드된 데이터를 특정해야 하는데 DynamoDB의 스캔의 경우 모든 데이터를 읽어오고 그 다음 불러온 데이터의 내부에서 처리를 하는것이기 때문에 데이터량이 많을수록 엄청난 비용이 청구될 확률이 높습니다.
두번째 방법은 기존 데이터가 없이 키값을 알아 데이터를 삽입할수 있으며 좀더 유연하게 사용이 가능합니다, 하지만 단점은 원자성이 보장이 안되며 쿼리를 2번 날려야 한다는것 이로인한 2배의 비용이 들어간다는것입니다.
또한 이런 방법에도 VTL을 사용하는 방법과 Function(Lambda)을 사용하는 방법으로 나눌수가 있는데
여기서는 상대적으로 amplify 기본 생성되는 템플릿을 건들지 않는 Function을 사용합니다.
물론 이 방법을 사용하면 function에 대한 추가적인 비용이 소모가 됩니다.
하지만 기본 생성되는 템플릿을 건들고 싶지가 않았습니다.
.gif)
해결
- DynamoDB에 파티션키를 table로 가지고 있는 Key 테이블을 생성
(amplify 의 model로 생성해도 상관없습니다.)
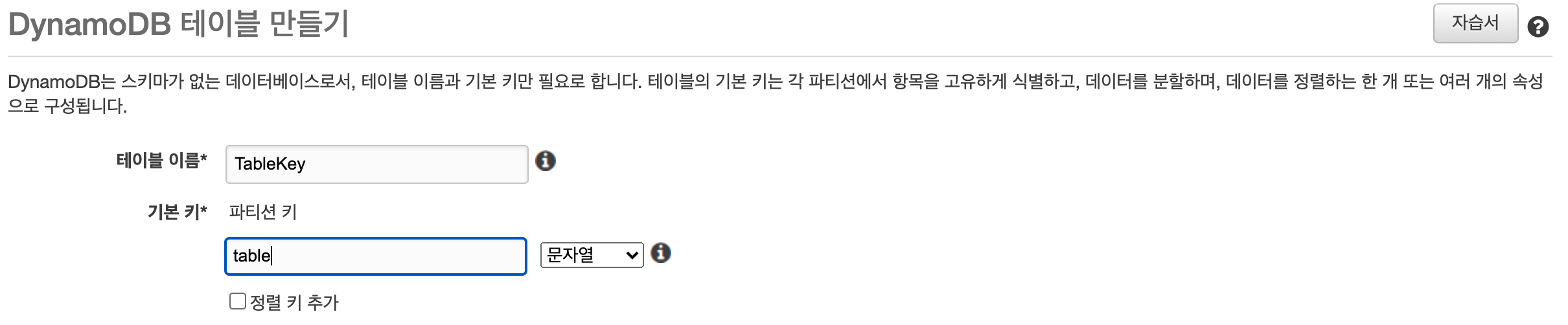
schema.graphql
// example
type TableKey
@model(queries: null, mutations: null, subscriptions: null, timestamps: null)
@key(fields: ["table"]) {
table: String!
count: Int!
updated_at: AWSDateTime!
}- Amplify Function 추가
본 글에서는 Golang 런타임을 사용하였으며, 오픈소스 DynamoDB ODM인 dynamo(https://github.com/guregu/dynamo)을 사용하였습니다.
amplify add function
package main
import (
"context"
"fmt"
"os"
"time"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/guregu/dynamo"
)
const region = "ap-northeast-2"
// request
type request struct {
Arguments arguments `json:"arguments"`
}
type arguments struct {
Table string `json:"table"`
}
// response
type response struct {
Table string `dynamo:"table" json:"table"`
Count int `dynamo:"count" json:"count"`
UpdatedAt time.Time `dynamo:"updatedAt" json:"updated_at"`
}
func HandleRequest(ctx context.Context, args request) (*response, error) {
resp, err := update(args.Arguments.Table)
if err != nil {
return nil, err
}
return resp, nil
}
func main() {
lambda.Start(HandleRequest)
}
func update(pk string) (*response, error) {
// amplify api @model로 생성시
env := os.Getenv("ENV") // amplify env
if env == "" {
env = "dev"
}
// 테이블 네임 설정
var tableName = fmt.Sprintf("%s-%s-%s",
"TableKey",
AMPLIFY_AUTO_GEN_KEY,
env,
)
// dynamo aws session 생성
db := dynamo.New(session.New(), &aws.Config{Region: aws.String(region)})
// 테이블 가져오기
table := db.Table(tableName)
var result response
// 테이블 데이터 업데이트(update-expression)
err := table.Update("table", pk).Set("updatedAt", time.Now()).Add("count", 1).Value(&result)
// 에러 핸들링
if err != nil {
return nil, err
}
return &result, err
}
- CloudForamtion Template 변경
Lambda에서 DynamoDB를 변경하기 위한 권한을 추가해줍니다.
amplify/backend/function/FUNCTION_NAME/FUNCTION_NAME-cloudformation-template.jspn
"PolicyDocument": {
"Version": "2012-10-17",
"Statement": [
...
{
"Sid": "ReadWriteTable",
"Effect": "Allow",
"Action": [
"dynamodb:BatchGetItem",
"dynamodb:GetItem",
"dynamodb:Query",
"dynamodb:Scan",
"dynamodb:BatchWriteItem",
"dynamodb:PutItem",
"dynamodb:UpdateItem"
],
"Resource": {
"Fn::Sub": [
"arn:aws:dynamodb:${region}:${account}:table/테이블명,
(ex. TableKey-AMPLIFY_AUTO_GEN_KEY-${env})"
{
"region": {
"Ref": "AWS::Region"
},
"account": {
"Ref": "AWS::AccountId"
}
}
]
}
}
]
}- 생성한 함수를 API에 연결
자동 증분된 결과가 반환되는 함수를 API에 연결해줍니다.
schema.graphql
type Query {
getTableKey(table: String!): TableKey
@function(name: "FUNCTION_NAME-${env}")
}- 증분 값 가져오기
// client
query getKey {
getTableKey(table: "TABLE_NAME") {
count
table
updated_at
}
}클라이언트에서 자동증분된 값을 원하는 원하는 테이블 이름을 쿼리로 함수에 전달할때마다
함수에서는 원자성 카운터를 통하여 증분된 값을 클라이언트로 반환해줍니다.
// response
{
"data": {
"getTableKey": {
"count": 1, // 증분된 값
"table": "TABLE_NAME",
"updated_at": "2021-00-00T00:00:00.000000000Z"
}
}
}테이블에 데이터 삽입의 과정은 클라이언트에서 비동기 방식을 통하여 먼저 입력될 데이터의 오류를 검증하고 오류가 없을때만 테이블 키를 요청,
이후 받아온 키값을 데이터에 포함해서 mutation 해주는 것이 혹시 모를 불필요한 증분 쿼리를 방지할 수 있습니다.
결론
람다와 DynamoDB의 기능을 사용하여 간단하게 자동 증분된 키를 가져와봤습니다.
단순 자동 증분 키를 위해서 사용하기에는 기본 사용보다 많은 자원이 필요함으로 나의 통장을 지키기 위해서, DynamoDB에서는 자동 증분 키가 꼭 필요한 경우가 아니면 UUID를 사용하는것을 권장합니다.
.gif)
