[PINTOS-KAIST] project. 2-0 WIL syscall에 의한 user-kernel context switching과 부모-자식 프로세스 생성에 대한 이해과 구현
PINTOS

PROJECT 1-2 GIT is here
MY NOTION is here
PROJECT 1: THREADS (2023 4/26 수요일 밤까지) - 1주
PROJECT 2: USER PROGRAMS (2023 5/8 월요일 밤까지) - 1.5주
Browsing about the theme...
이번 주차가 첫 주차보다 내용이 훨씬 많다고 느꼈다... SYSCALL의 개념과 fork, wait, interrupt_frame에 대한 이해가 핵심이다. 이를 위해선 가상메모리의 유저영역과 커널영역에 대한 이해 역시 배경으로 필요하다.
프로젝트 1에서 우리가 Pintos 안에서 돌린 모든 코드는 OS 커널의 일부이다. 예를 들어, 지난 과제에서의 테스트 코드는 커널의 일부로서 동작한 것이다(당연). 즉, system의 특권 명령에 대한 모든 접근 권한을 가진 상태이다. 이번 프로젝트에서는 사용자 프로그램을 OS에서 돌리는 상황인 것이다.
📌 이번에도 역시 길어져서 글을 나누어 발행했다.
Project 2 도입 (2-1) | 개념 - Dual-mode,Pintos 코드에서의 interrupt와 콘텍스트 저장과 복원, 시스템 콜의 호출과 실행
따지자면 모든 프로젝트가 그러했겠으나 Project 2는 하나의 사용자 프로그램이 메인 메모리에 불러와 져 실행되기까지의 흐름을 이해하는 것이 매우 중요한 것 같았다. 전체적인 흐름을 먼저 알고 들어갔다면 훨씬 수월하게 느꼈을 것 같으나 그럴 수 없었으니 처음에는 이를 이해하기가 너무 어려웠다...
한 사용자 프로그램이 실행되기까지의 흐름
아래는 처음 핀토스 OS가 실행되어지며 하나의 프로세스(== 스레드, 프로그램 in Pintos)가 초기화되어 생성되고 실행되기까지의 흐름이다. int main(void)는 모든 핀토스 운영체제 내 함수 중 가장 먼저 실행이 되는 기본 프로세스라 할 수 있고, 앞서 살펴보았듯이 최종적으로는 do_iret()의 최하단에서 어셈블리어 iretq가 실행되며, 스레드가 launch된다. 아래의 코드들은 구현 과제가 완료된 시점에서의 코드이다.
아래의 코드들은 구현 과제가 완료된 시점에서의 코드이다.
1️⃣ init.c의 int main(void)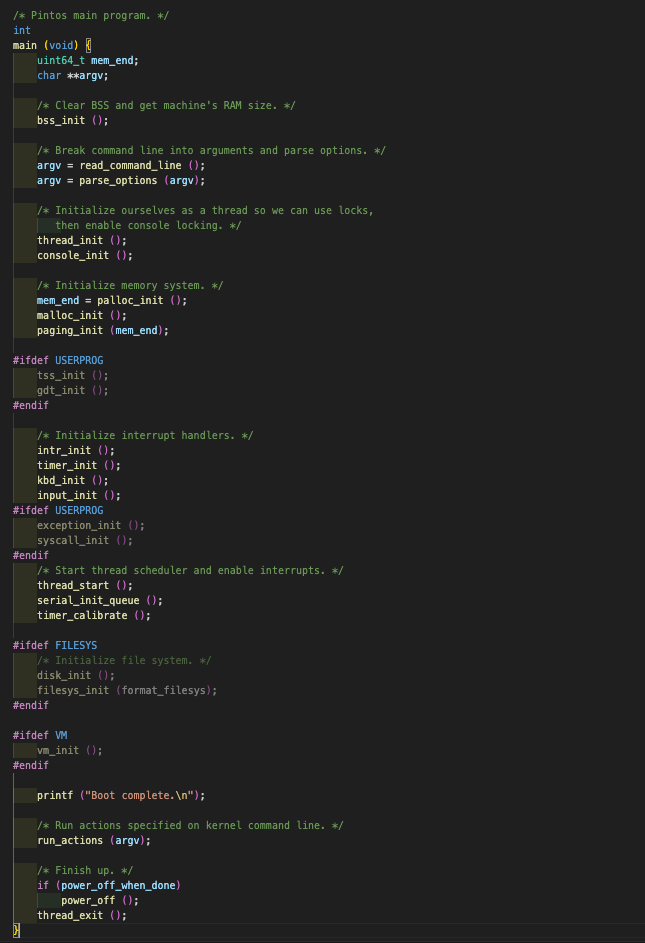
Pintos의 main program이다. 즉, pintos가 시작이 되면 init.c의 main()함수가 실행이 된다고 보면 된다. int main ()이 실행되며, kernel command line에 정의된 action을 실행한다. 여기서 argv를 action의 인자로 받는다.
int main ()이 실행되며, kernel command line에 정의된 action을 실행한다. 여기서 argv를 action의 인자로 받는다.
argv는 read_command_line()으로 읽은 후 parse_options()로 해당 line을 parsing한 string이다. 사용자 프로그램이 어떠한 action을 할지에 대한 명령을 argv에 담아 인자로 넘기는 것이다.
2️⃣ run_actions(argv)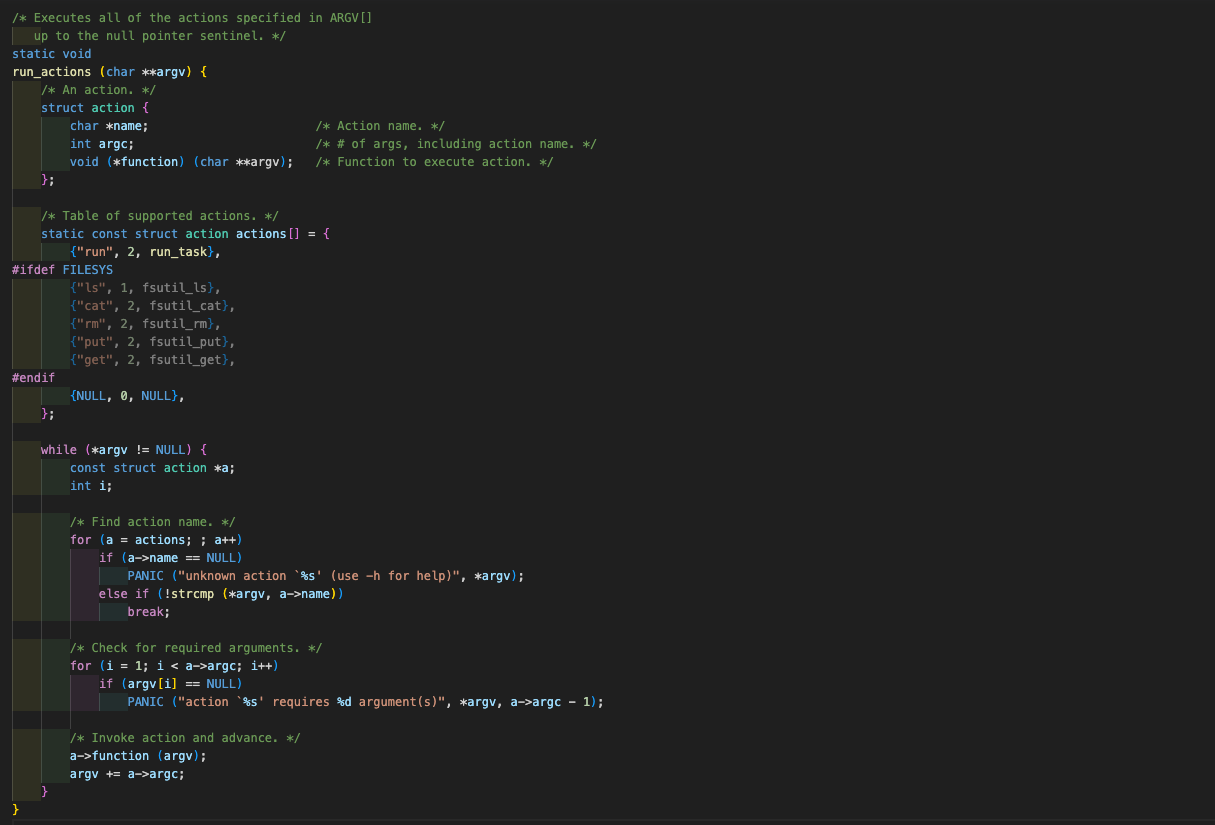
action이라는 구조체가 하나 생성된다. action 구조체 안에서는 실행할 액션의 이름, 받아온 인자의 갯수, 매개변수로 받아온 인자 argv를 인자로 받는 void funtion을 정의하고 있다. 이후 "actions"라는 이름의 배열, 즉 action 구조체로 이뤄진 배열을 만들어 내고 있다.  while문을 돌며, while문 안에서 생성하는 새로운 action 구조체 a에 아까 생성했던 action 구조체 actions를 넣는다.
while문을 돌며, while문 안에서 생성하는 새로운 action 구조체 a에 아까 생성했던 action 구조체 actions를 넣는다.
run_task() 함수는 while문의 마지막 순회 회차 때 a->function (argv);에 담기며 비로소 실행된다. run_task()의 실행이 끝나고 run_task()가 return 되면 마지막 arguv += argc 회차를 수행한 뒤 run_actions의 수행이 비로소 끝난다.
3️⃣ 4️⃣ run_task (char **argv) { process_wait (process_create_initd (task)) } 중 process_create_initd (task)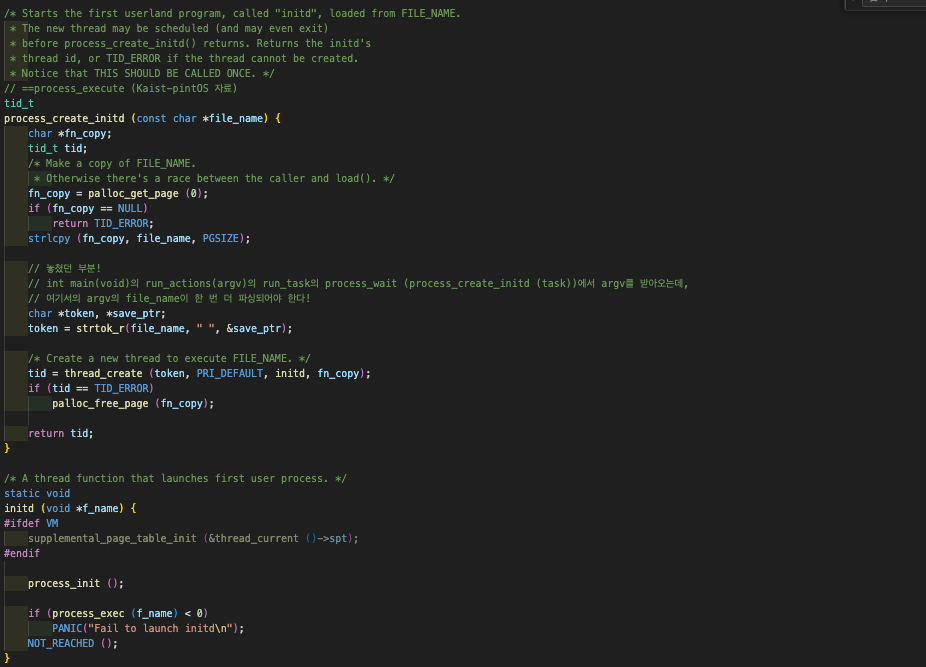
해당 스레드가 테스트 스레드가 아니라면, process_wait (process_create_initd (task)); 한다. task는 아까 argv에서 받아온 인자. 참고로 여기서의 순서는... process_create_initd (task); 가 실행 완료된 뒤 그 리턴값을 매개변수로써 process_wait()가 실행된다.
구현 과제 중 내가 놓쳤던 부분이 있는데 이는 int main(void)의 run_actions(argv)의 run_task의 process_wait (process_create_initd (task))에서 argv를 받아온 뒤, 받아온 argv에서 한 번 더 파싱되어야 한다는 점이었다. argv의 file_name을 추출해야하기 때문이다.
tid = thread_create (token, PRI_DEFAULT, initd, fn_copy); 이 실행된다. 주어진 초기 우선순위를 가진 NAME이라는 이름의 새 커널 스레드를 생성하고, 이 스레드는 AUX를 인수로 전달하는 FUNCTION인 initd()을 실행한 이후, 본격적으로 레디 큐 (내 코드에서의 변수 이름: ready_list)에 추가된다. 최종적으로 thread_create()가 새 스레드의 스레드 식별자를 반환하게 된다. 만약 여기서 thread_create() 성공적인 스레드 생성에 실패하면, 변수 tid에는 TID_ERROR가 반환된다.
5️⃣ 6️⃣ thread_create (token, PRI_DEFAULT, initd, fn_copy) / kernel_thread (initd, fn_copy) / initd(fn_copy);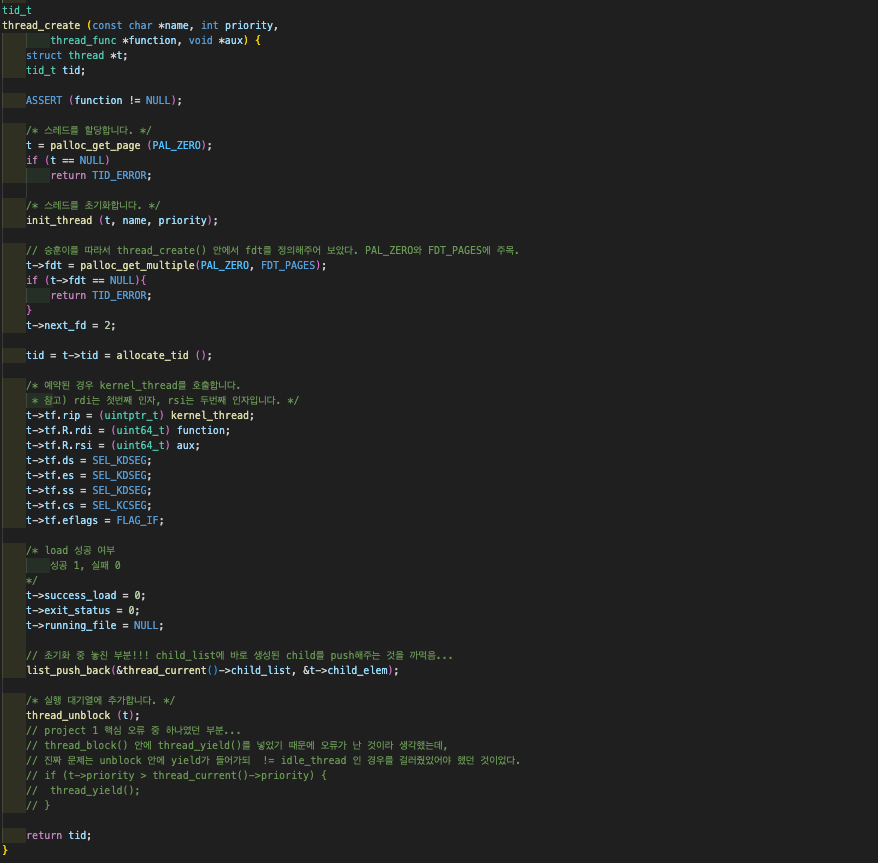 thread_create()의 세 번째 매개변수였던 인자 initd는
thread_create()의 세 번째 매개변수였던 인자 initd는
이 곳에 담기게 된다. thread_create()의 맨 상단에서 처음 생성된 스레드 구조체 t의 맴버 레지스터 구조체 R의 rdi, t->tf.R.rdi에 담김으로써, initd는 kernel_thread()의 첫 번째 매개변수가 된다.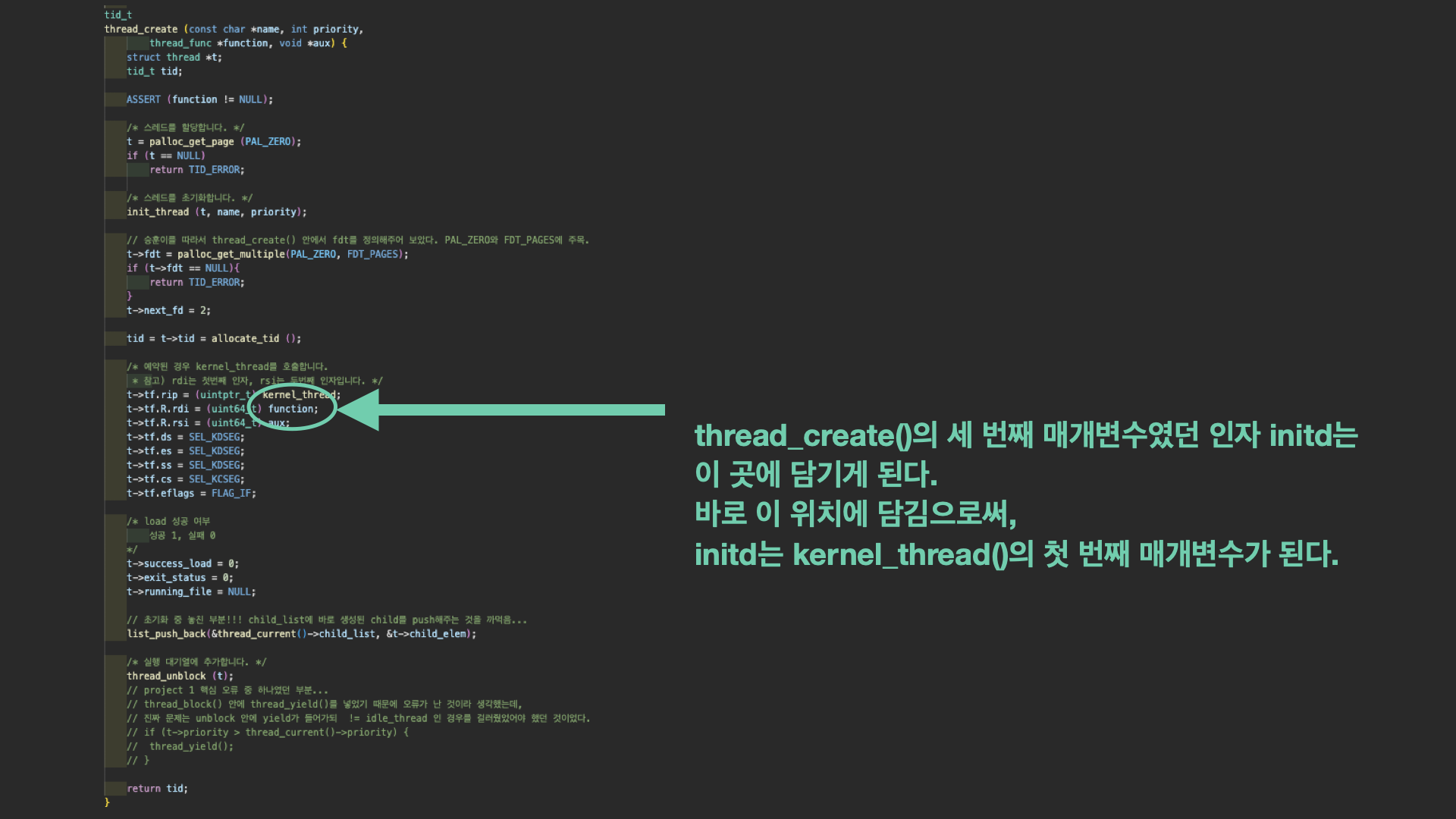 kernel_thread() 함수는 새로운 스레드를 생성하고 해당 스레드의 실행을 시작하는 역할을 한다.
kernel_thread() 함수는 새로운 스레드를 생성하고 해당 스레드의 실행을 시작하는 역할을 한다.
kernel_thread()는 여기서 매개변수로서 받아온 kernel_thread (initd, fn_copy)를 실행시킨다.  kernel_thread는 위와 같이 생겼다. 즉 initd(fn_copy);를 실행시킨 뒤 initd(fn_copy)가 리턴되면 "현재 실행되고 있는 스레드"를 thread_exit()해버린단 말이다. "우리가 생성하고자 하는 스레드에 대한 초기화를 수행하고 있는" 스레드가 현재 스레드다. 현재 스레드는 이 새 스레드에 대한 여러 초기화의 과정과 load()와 do_iret() 등을 마친 뒤 종료한다는 뜻이다.
kernel_thread는 위와 같이 생겼다. 즉 initd(fn_copy);를 실행시킨 뒤 initd(fn_copy)가 리턴되면 "현재 실행되고 있는 스레드"를 thread_exit()해버린단 말이다. "우리가 생성하고자 하는 스레드에 대한 초기화를 수행하고 있는" 스레드가 현재 스레드다. 현재 스레드는 이 새 스레드에 대한 여러 초기화의 과정과 load()와 do_iret() 등을 마친 뒤 종료한다는 뜻이다.
initd()는 저기 위에서 봤다시피 process_init (); 후 (process_exec (f_name);을 한다. 여기서 바로 f_name이 fn_copy가 된다.
5️⃣ 6️⃣ process_exec(fn_copy)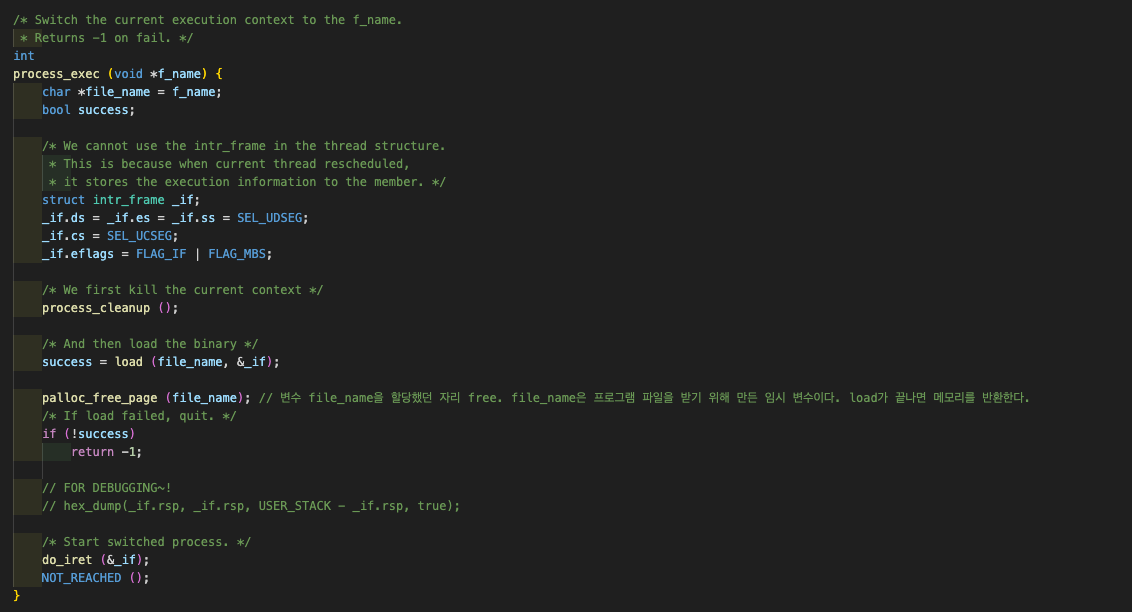
process_exec() 안에서는 인터럽트 프레임 _if 를 생성하여 초기화하고, 현재 실행 중인 스레드의 자원을 free시키는 process_cleanup()을 실행한다. 이후 load (file_name, &_if);와 do_iret (&_if);을 실행한다.
process_exec()이 진정으로 우리가 만드려고 하고 있는 스레드를 "실행"시키는 함수이다.
user program의 입력값에 대한 parsing, passing 구현
아래는 load() 함수 중 입력값에 대한 파싱을 수행하는 상단부이다. 커맨드 라인의 맨 앞대가리 즉 "파일명"에 대한 주소값을 별개로 담아두는 동시에 커맨드 라인 전체를 공백 기준으로 잘라 배열로 담는다. 둘러보니 load() 함수의 전후에 파싱과 패싱을 하는 팀들이 많은 것으로 보였는데, 우리 팀의 경우 load() 함수 내에서 모든 수행을 하도록 설계했다. 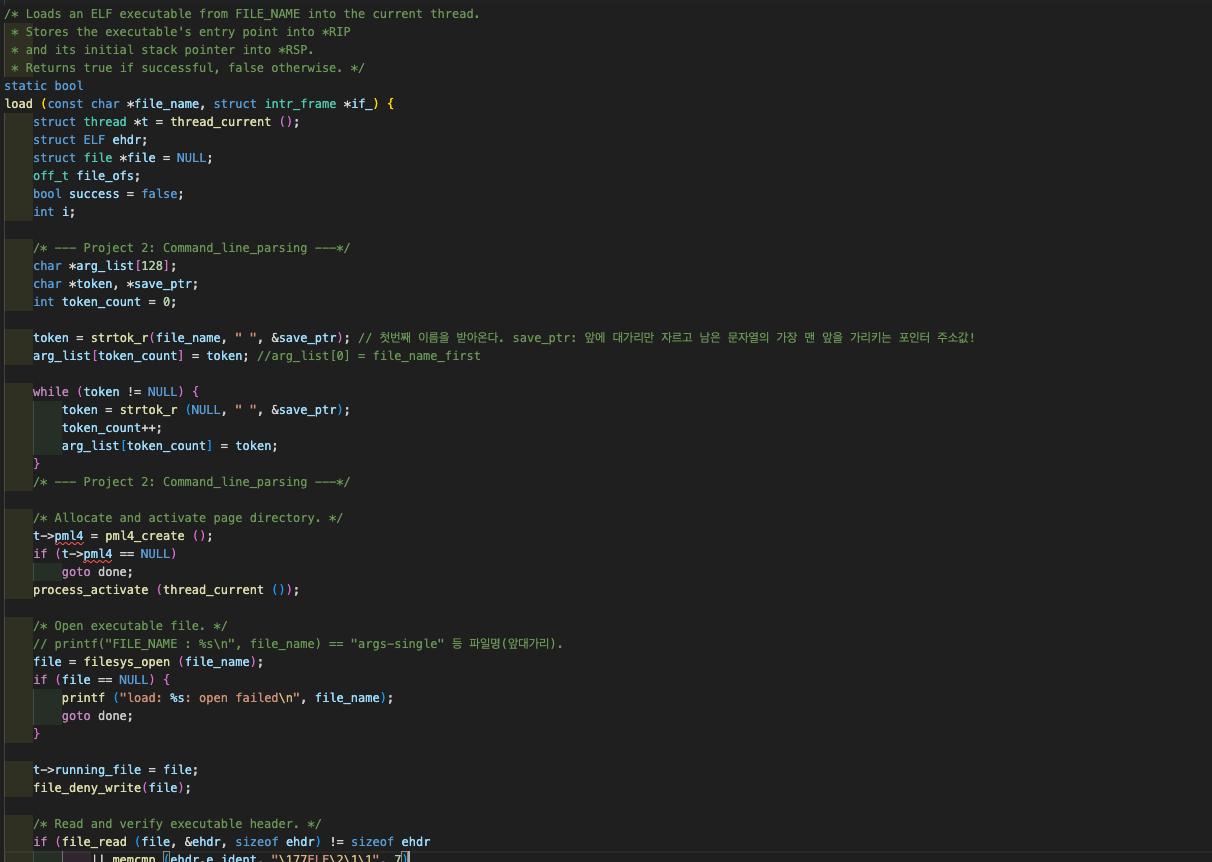 load() 내 하단부의
load() 내 하단부의 argument_stack()에서, 받아온 인자들을 배열로 만들어 놓은 arg_list를 패싱한다.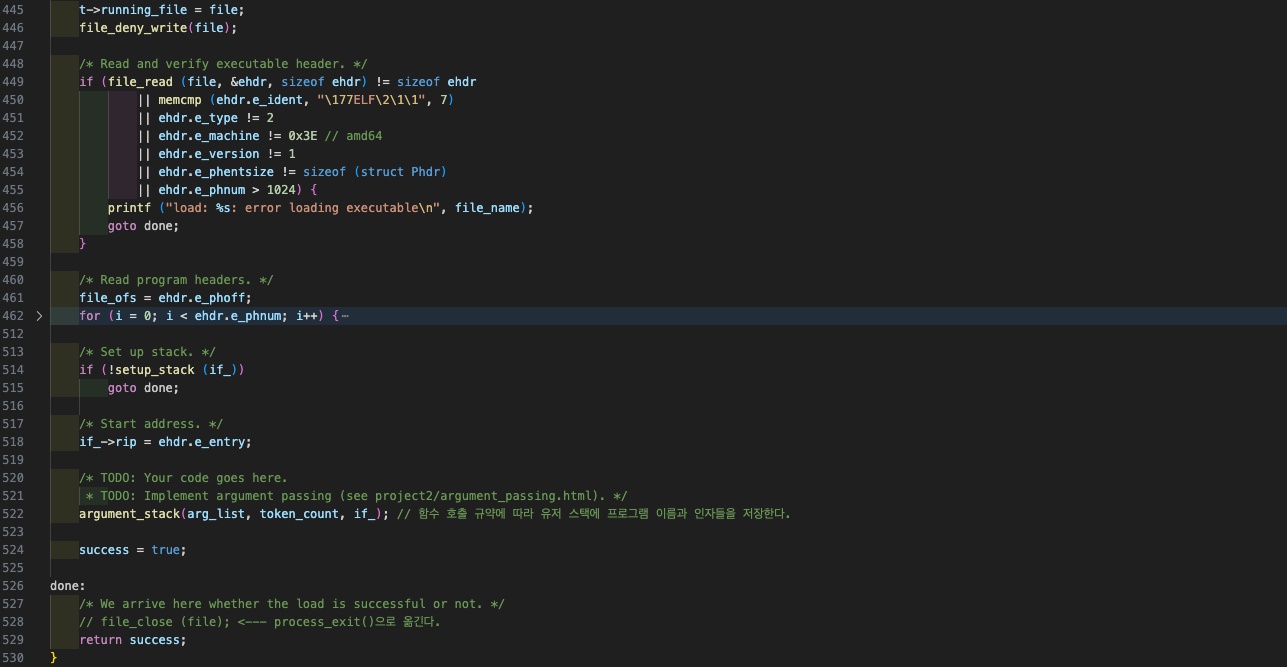
다음은 argument_stack() 함수의 코드이다. 어렵다....
이 코드에 대해 이해하려면 가장 우선 인터럽트 프레임if_의 맴버, if_->rsp이 뭔지 이해할 필요가 있다.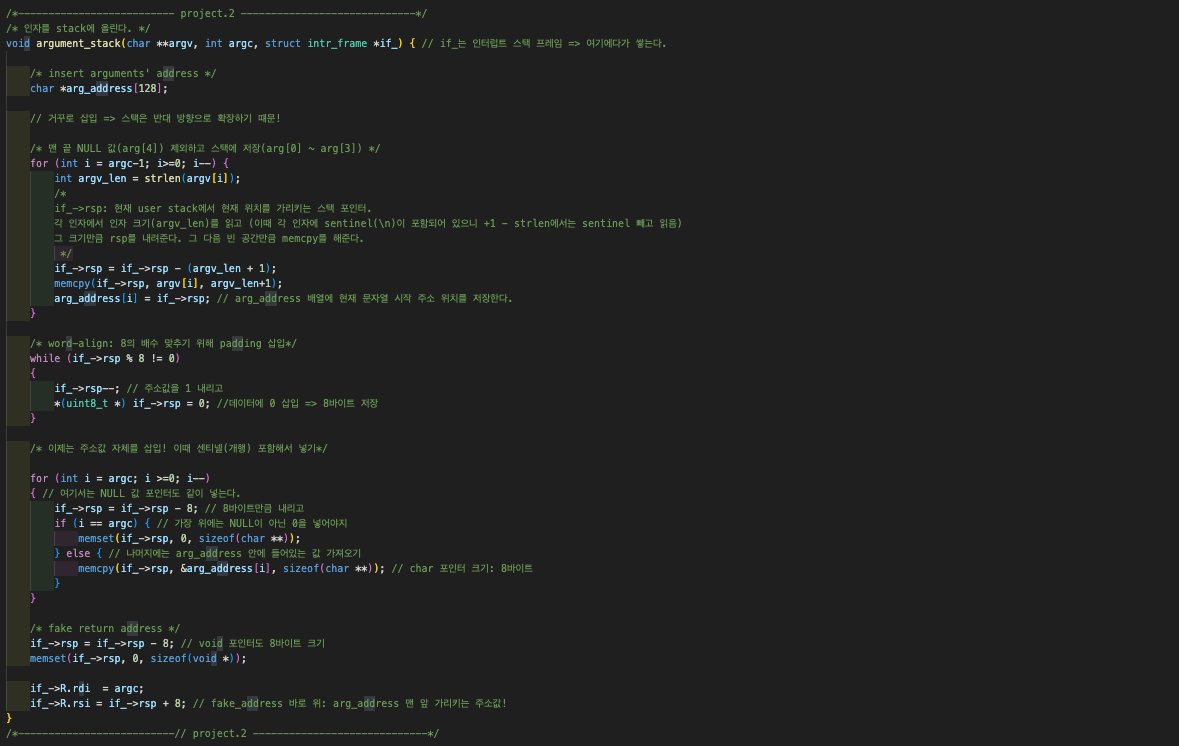 ✅ 여기서
✅ 여기서 if_->rsp ?:
인터럽트 프레임 내 멤버로, "user stack에서, 현재 CPU가 가리키고 있는 위치를 담은 스택 포인터"이다.
아래의 내용은 Pintos-Kaist 과제에 대한 Docs에 안내되어 있는 내용이다. 프로그램 실행 명령에 대한 인자가
프로그램 실행 명령에 대한 인자가 /bin/ls -l foo bar의 형태로 들어온다면, 이 string을 공백 단위로 자른 뒤, 사용자 프로세스(==프로그램)에 대한 메모리의 스택 영역에 위!에!서! 부터 쌓는다.
위 코드 진행 과정을 대강 살펴본다.
- 먼저 스택 포인터를 넣어줄 공간만큼 쭉~ 내린다.
if_->rsp = if_->rsp - (argv_len +1) - 그 다음, 해당 공간에 인자값을 복붙한다.
memcpy(if_->rsp, argv[i], argv_len+1)) arg_address배열에 인자값이 위치한 주소를 저장하는 반복문을 돌린다.arg_address[i] = if_->rsp- 맨 아래의 return address 영역에 fake address를 넣어준다. 해당 영역의 메모리는 0으로 초기화해준다. 이는 처음 프로세스가 생성되는 특수한 경우이고 이 경우 entry 함수는 절대 리턴되지 않겠지만, 해당 스택 프레임은 다른 스택 프레임들과 같은 구조를 가져야 하기에 x86-64 Calling Convention을 맞춰준, 쉽게 말해 calling 구색을 맞춰준.... 개념이라고 볼 수 있다.
프로그램 실행 명령에 대한 인자가 /bin/ls -l foo bar인 경우 사용자 프로그램 시작 직전 스택 및 관련 레지스터의 상태를 보여주고 있다. 데이터와 그 주소값들이 담기는 모습을 확인할 수 있고, 스택이 아래로 늘어남을 확인할 수 있다.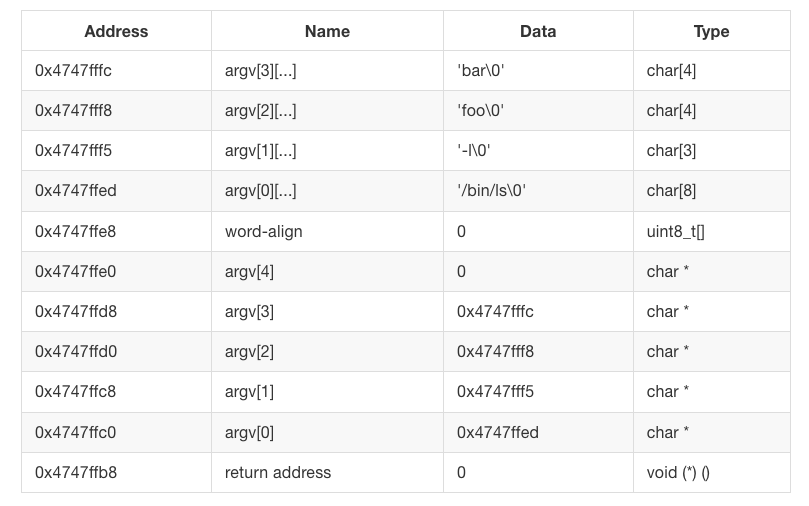
do_iret (struct intr_frame *tf)은 일전에 언급했으므로 넘어간다.
이 함수는 새 스레드를 launch하지는 않는다. 인터럽트 프레임을 읽어서 가져와, 중단된 프로세스 또는 스레드의 상태를 복원하여 중단 지점에서 실행을 계속할 수 있도록 하는 역할의 함수이다.
스택에 인자가 쌓이고 유저 스택이 커널 영역의 반대방향 자라는 모습을 참고로 하기 위해, 여기서 가상메모리에 대한 개념을 짧게 소개한다.
가상메모리 (Virtual Memory) (VM)
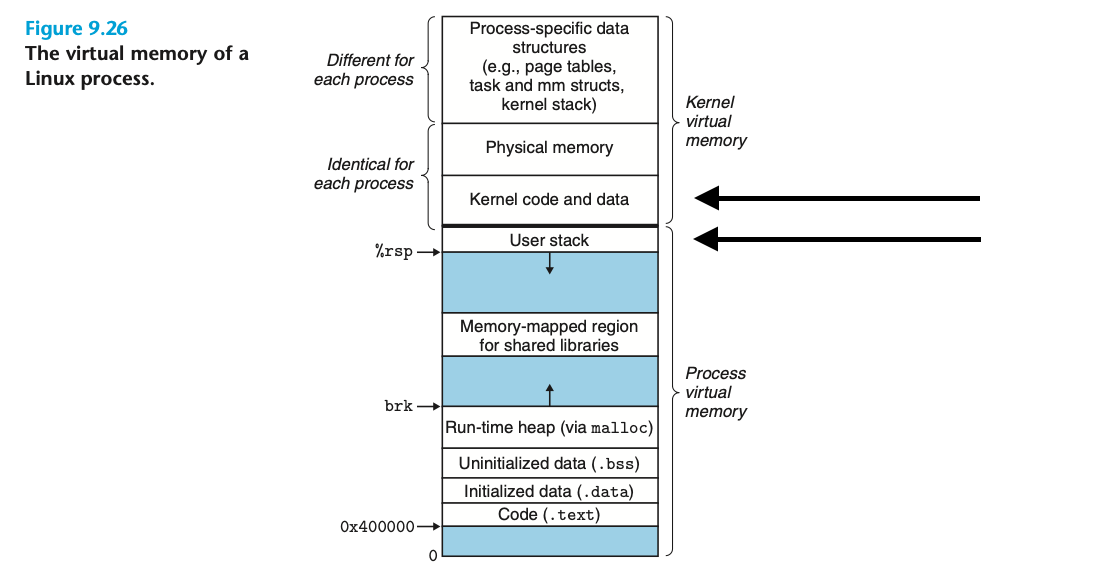 온오프라인의 수많은 그림들 중 이 그림이 가장 도움이 됐다... Project 2를 위해선 최소한 이 커널 스택 - 유저 스택 - 힘과 데이터와 코드 영역 이라는 큰 구조만 이해하면 될 것 같다.
온오프라인의 수많은 그림들 중 이 그림이 가장 도움이 됐다... Project 2를 위해선 최소한 이 커널 스택 - 유저 스택 - 힘과 데이터와 코드 영역 이라는 큰 구조만 이해하면 될 것 같다.
가상주소 ➡️ 물리주소는 어디서 ?
MMU (Memory Management Unit):
CPU에 코드 실행 시, 가상 주소 메모리 접근이 필요할 때 해당 주소를 물리 주소값으로 변환해주는 하드웨어 장치. 가상 주소를 물리 주소로 변환해준다.
syscall fork에 의한 부모-자식 프로세스 생성 및 접근 구현
과제 내용 중에는 여러가지 syscall이 있지만 그중 일부만 기록한다.
syscall fork()는 스레드를 하나 더 복사해낸다. fork()를 통해 만든 자식 프로세스는 부모 프로세스의 user-level 정보를 이어 받아 user-level에서 마저 실행을 해야한다.
아래는 syscall fork()와 그 안에서 실행되는 process_fork()의 코드이다.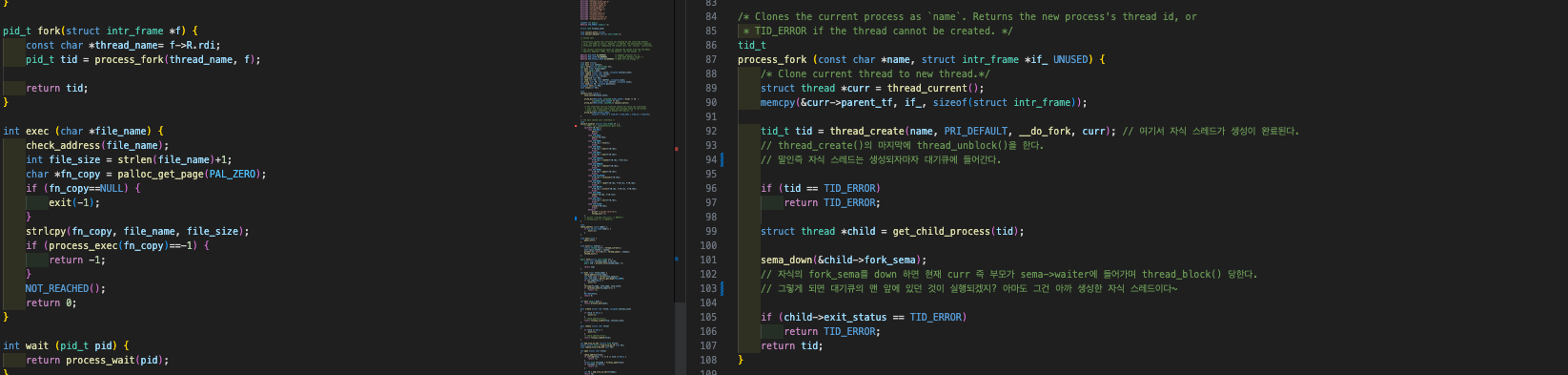 syscall fork()는 인터럽트가 발생하였을 당시에 받아온 인터럽트 프레임 f의 주소를 매개변수로 취한다. 그 받아온 f를 고스란히 process_fork(thread_name, f);로 process_fork()에게 넘긴다.
syscall fork()는 인터럽트가 발생하였을 당시에 받아온 인터럽트 프레임 f의 주소를 매개변수로 취한다. 그 받아온 f를 고스란히 process_fork(thread_name, f);로 process_fork()에게 넘긴다.
process_fork()의 내부에서는
tid_t tid = thread_create(name, PRI_DEFAULT, __do_fork, curr); 가 실행이 된다.
curr는 코드를 보면 알겠지만 현재 러닝되는 스레드이다. 즉, 현재 러닝되는 스레드가 복사되어지는 부모 스레드가 된다.
여기서~ thread_create가 실행된다고 해서 먼저 __do_fork(curr)가 실행이 되는 것은 아니다. 자식 프로세스는 생성되자마자 대기큐에 들어가게 되고, 그 자식 프로세스의 id인 tid를 리턴값으로 변수 tid에 담는 것이다.
그런 뒤, sema_down(&child->fork_sema); 을 해줌에 주목하자.
자식의 fork_sema를 down 하면 현재 curr 즉 부모가 fork_sema에 대한 'waiter 큐'인 sema->waiter에 들어가며 thread_block() 당한다.
그렇게 되면 '대기 큐'의 맨 앞에 있던 것이 실행되겠지? 아마도 그건 아까 생성한 자식 스레드이다~
그럼 이제 우리가 갓 만든 자식 스레드가 실행이 된다. 즉, __do_fork(curr)가 실행이 된다.
__do_fork()는 부모의 실행 컨텍스트를 복사하는 스레드 함수이다. 우린 이 함수가 뭔지 더 알아야 할 필요가 있다. 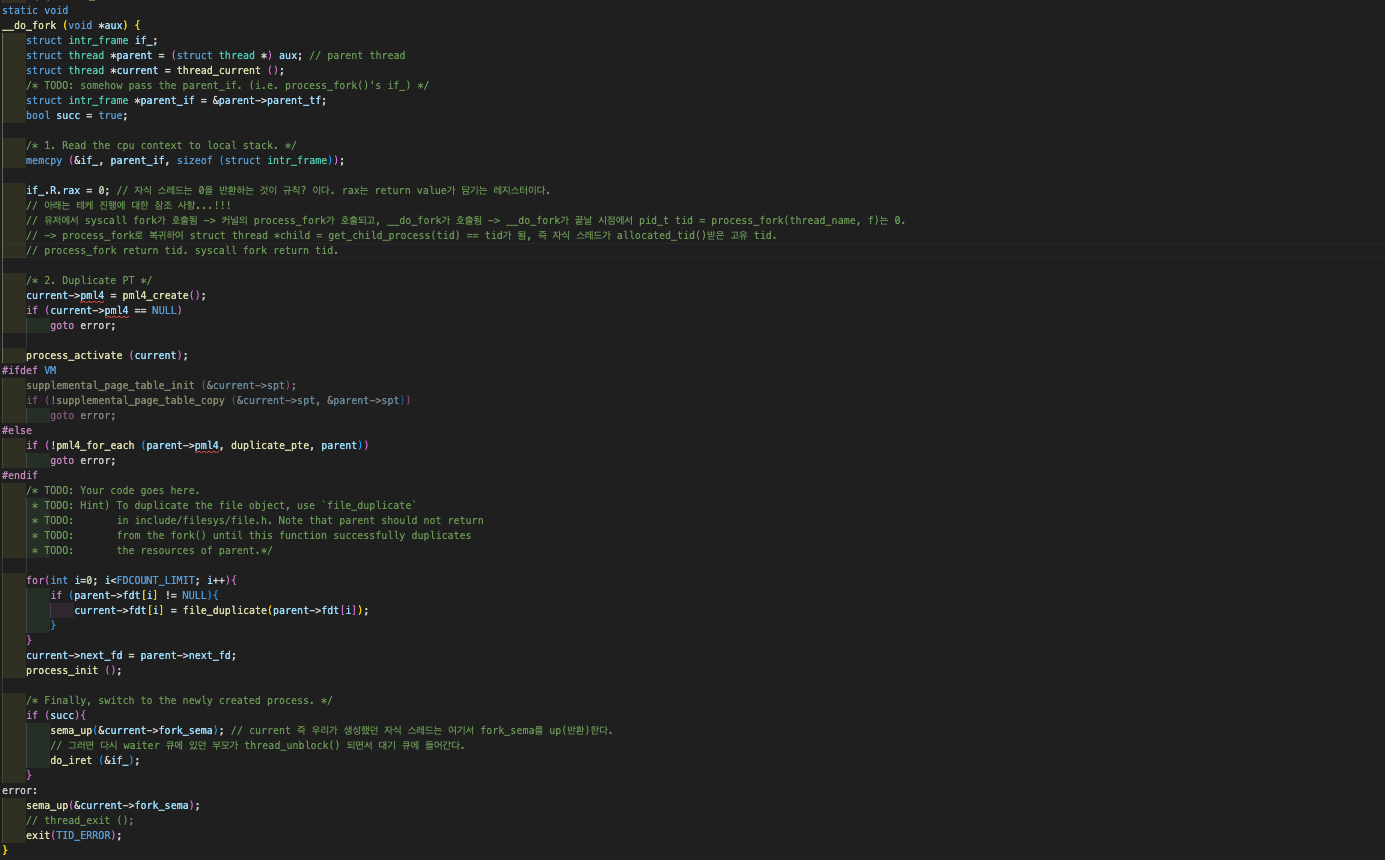 위는
위는 __do_fork()의 코드이다.
간단히 말하면 부모 프로세스의 인터럽트 프레임 f를 복사하여 그걸 if_에 memcpy한 뒤, 최종적으로 do_iret (&if_);을 통해 복사로 만든 프로세스(자식 프로세스)를 실행해주고 있는 모습이다. f는 user-level에서의 부모 프로세스가 실행되던 정보가 담겨 있고, 자식 프로세스는 이제 정보를 이어 받아 user-level에서 마저 실행을 해야한다.
최상단에서 struct intr_frame *parent_if = &parent->parent_tf;를 실행하는 데에 주목해보자. 나는 다음과 같이 thread 구조체에 struct intr_frame parent_tf를 새로 추가했다.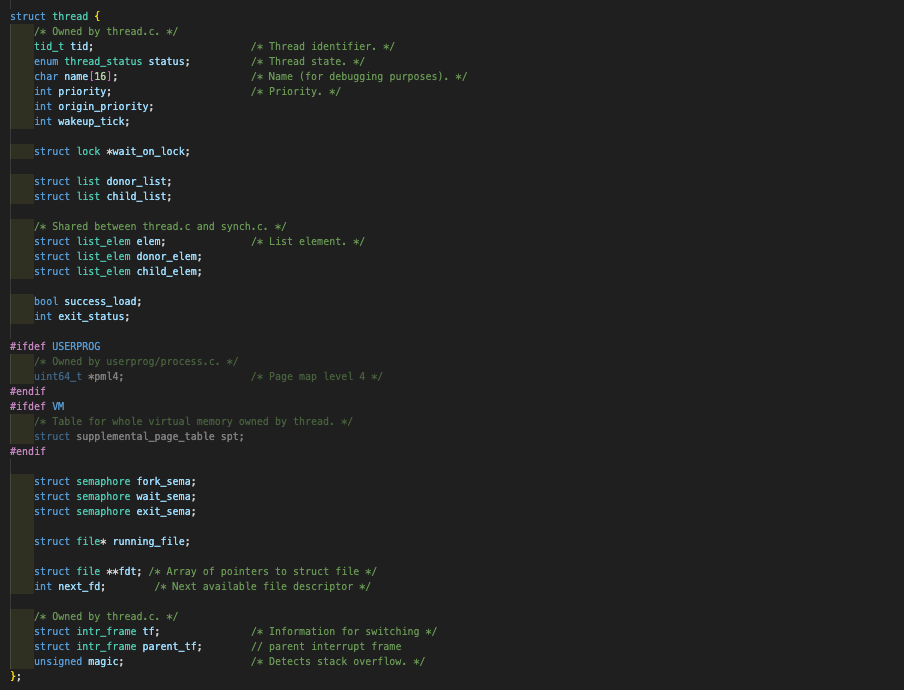 참고로 위 코드는 이후의 프로젝트들까지 완료한 상태의 코드다.
참고로 위 코드는 이후의 프로젝트들까지 완료한 상태의 코드다.
✅ 여기서 맴버 parent_tf를 선언해주는 의의...
이 부분의 구현에 있어서 처음에 &parent->tf를 했었는데, 오류였다.
부모 프로세스가 fork()를 수행하던 도중 context switch가 일어나서 다른 스레드가 실행이 될 경우, tf에는 syscall에 의해 트랩 걸려서 kernel-level로 와 syscall fork()를 수행하던 커널이 어디까지 작업했는지 정보가 저장된다(threads/thread.c의 thread_launch() 함수 참고).
하지만 인자로 받아온 f는, 언제나 user-level에서의 부모 프로세스가 실행되던 정보가 담겨 있다.
fork()해서 만든 자식 프로세스는 부모 프로세스의 user-level 정보를 이어 받아 user-level에서 실행을 마저 해야하므로, 우리는 여기서 f를 복사하는 것이 맞다.
그래서...
if_에 부모의 인터럽트 프레임을 멤카피, if_의 R.rax에 0을 넣고, 부모의 PTE와 FDT 내 정보를 역시 복사해온다. 그런 뒤 process_init()에 이어, sema_up(¤t->fork_sema);를 실행한다!
current, 즉 우리가 생성했던 자식 스레드는 여기서 아까 sema_down됐던 fork_sema를 up(반환)하는 것이다. 그러면 다시 'fork_sema에 대한 waiter 큐'에 있던 부모가 thread_unblock() 되면서 '대기 큐'에 들어간다!
부모가 대기 큐에 들어간 뒤 우리의 자식 스레드는 do_iret (&if_);을 통해 자신의 if_을 인터럽트 핸들러에게 반환하고, 인터럽트가 발생한 지점에서 중단된 코드의 실행을 재개한다.
이제..
__do_fork가 끝날 시점에서 pid_t tid = process_fork(thread_name, f)는 0이다.
그럼..
process_fork로 복귀하여 struct thread *child = get_child_process(tid) == tid가 된다. 즉, 자식 스레드가 allocated_tid()받은 고유 tid.
이어서, 부모 스레드가 process_fork 중 sema_down(&child->fork_sema) 하고, 자식 스레드가 sema_up(¤t->fork_sema) 하고, 그렇게 부모 스레드가 process_fork를 return tid하면, process_fork returns tid, syscall fork returns tid 하여 syscall fork가 최종적으로 자식 스레드가 allocated_tid()받은 고유 tid를 리턴하게 된다.
semaphore 기법을 이용한 syscall wait, exit 구현
syscall wait은 process_wait()을 호출한다. process_wait()는 자식 스레드가 종료되길 기다리는 부모 스레드가 호출한다. process_wait()에게는 종료되길 기다리는 해당 스레드에 대한 pid가 매개변수로써 주어진다.  wait(대기)이라는 수행은 곧 스레드 TID가 종료될 때까지 기다렸다가 종료 상태를 반환하는 것이다.
wait(대기)이라는 수행은 곧 스레드 TID가 종료될 때까지 기다렸다가 종료 상태를 반환하는 것이다.
종료 상태는 경우에 따라 나뉜다. 예외로 인해 종료된 경우 -1을 반환, TID가 유효하지 않거나 호출 프로세스의 호출 프로세스의 자식이 아니거나, process_wait()가 이미 주어진 TID에 대해 성공적으로 호출되었는데 또 불린 경우, -1을 반환한다.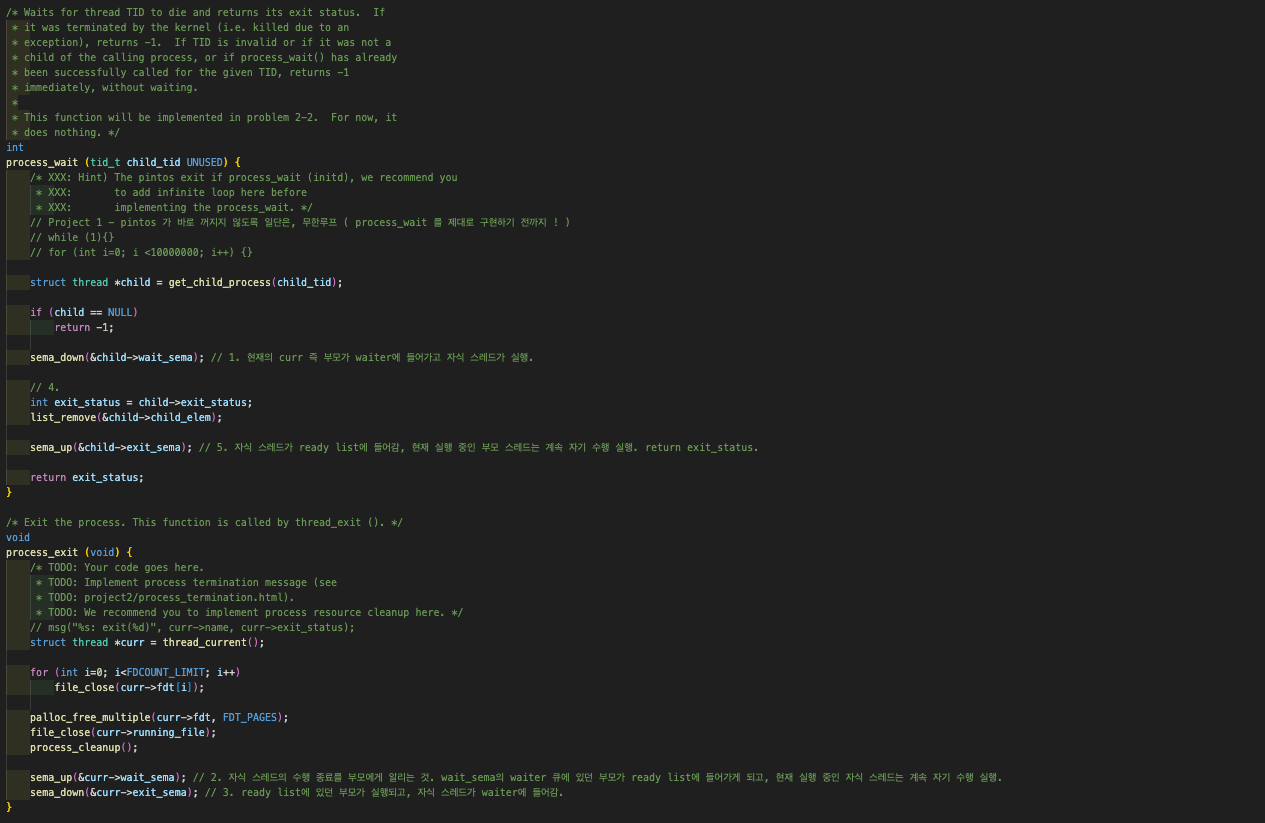 여기서 process_wait()과 process_exit()의 협업의 진행 과정을 살펴 볼 필요가 있다.
여기서 process_wait()과 process_exit()의 협업의 진행 과정을 살펴 볼 필요가 있다. 
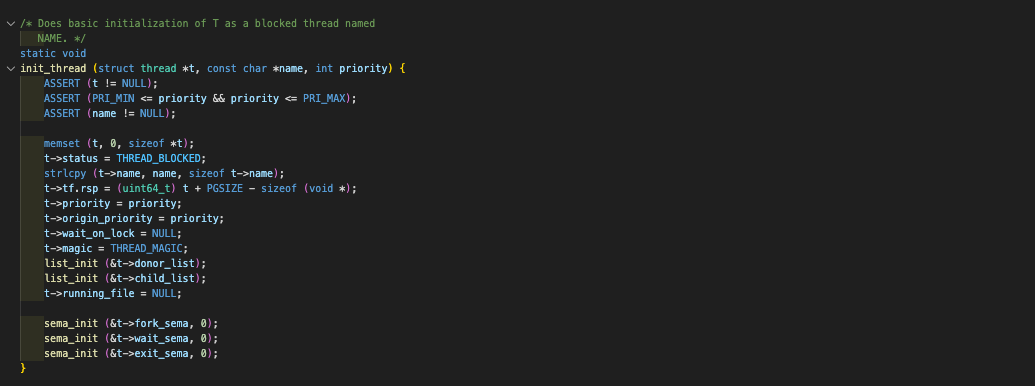 나는 위와 같이 thread 구조체 안에 총 3개의 semaphore 구조체를 선언하게 됐다. 초기화도 잊지 않고 해줘야 한다. (semaphore의 이름은 그냥 어느 함수에서 down되느냐에 따라 작명했다.) 그리고 exit_status 멤버를 스레드 구조체에 하나 만들어준다.
나는 위와 같이 thread 구조체 안에 총 3개의 semaphore 구조체를 선언하게 됐다. 초기화도 잊지 않고 해줘야 한다. (semaphore의 이름은 그냥 어느 함수에서 down되느냐에 따라 작명했다.) 그리고 exit_status 멤버를 스레드 구조체에 하나 만들어준다.
Project 1에서 이미 이해가 되었겠지만 semaphore 기법은 lock을 acquire한 스레드만이 lock을 release할 수 있는 lock 동기화 기법과 달리 semaphore down과 semaphore up의 주체가 다를 수 있다는 점이 그 활용도를 높인다. 아래의 진행 원리를 기반으로 syscall wait이 어떤 과정을 통해 프로세스의 종료 상태를 반환하는지 알 수 있다.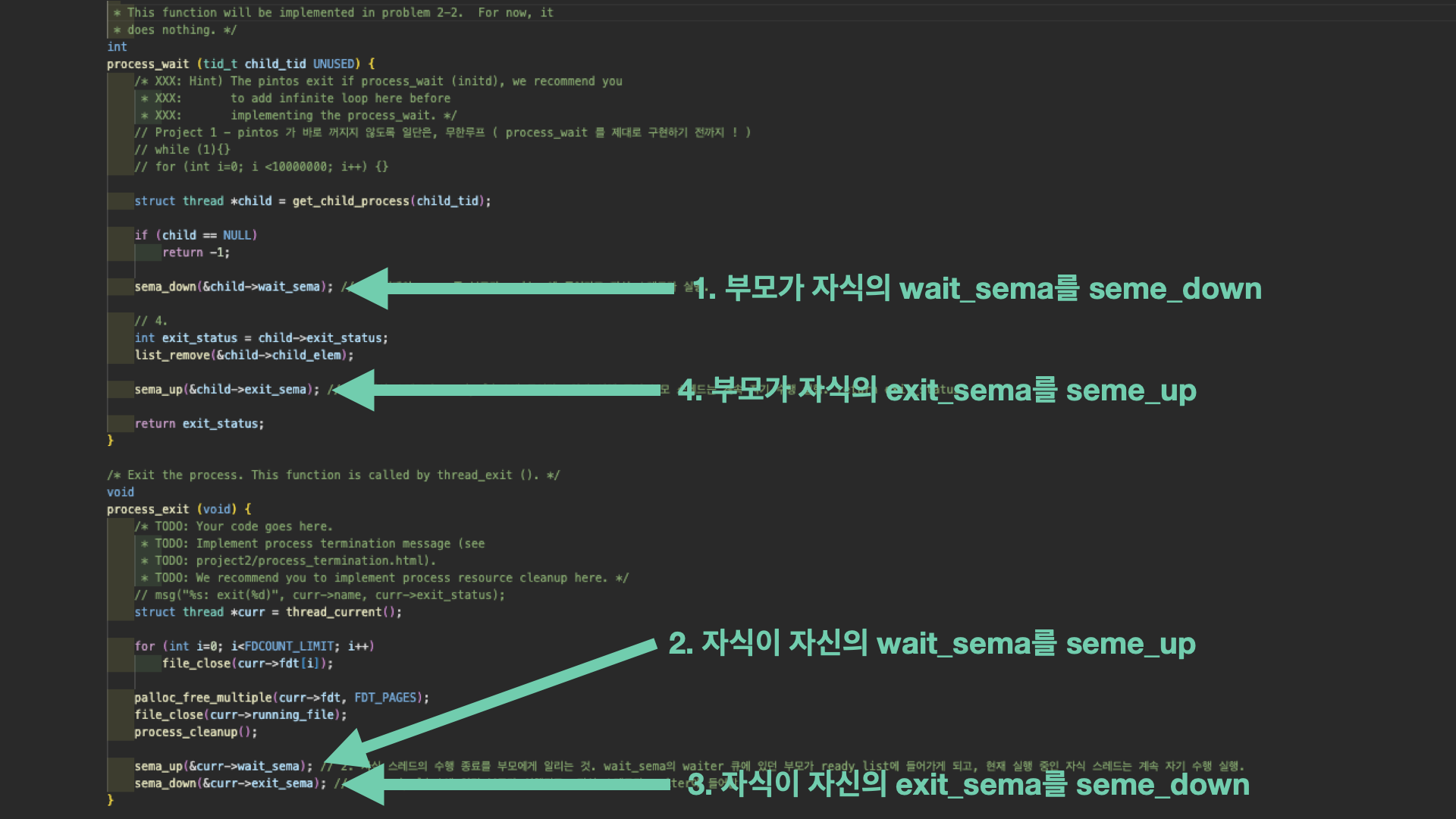 먼저 어떤 부모 스레드는 자식의 종료를 기다리는 syscall wait을 호출할 것이다. 그럼 process_wait()이 호출되고,
먼저 어떤 부모 스레드는 자식의 종료를 기다리는 syscall wait을 호출할 것이다. 그럼 process_wait()이 호출되고,
1️⃣ sema_down(&child->wait_sema);
부모는 process_wait() 도중 자기 자식의 wait_sema을 down한다. 그럼 먼저 현재의 curr 즉 부모 스레드가 자식의 wait_sema에 대한 waiter에 들어가고, 자식 스레드가 실행된다.
자식 스레드는 이제 신나게 자기 할 것을 하다가 종료할 때가 되어 syscall exit을 호출한다. 그러면 아래와 같이 자신의 exit_status를 재설정한 뒤, thread_exit()이 호출되게 된다. 위 코드는 완성된 상태의 exit이다. 그렇다면 thread_exit()은 어떻게 생겼나?
위 코드는 완성된 상태의 exit이다. 그렇다면 thread_exit()은 어떻게 생겼나?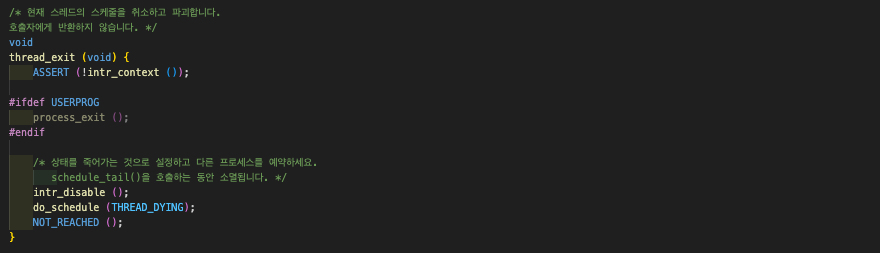 process_exit()을 호출한다. 자식 스레드는 syscall exit을 하기 위해 thead_exit() { process_exit() } 즉 process_exit을 수행하고 있는 상황이다.
process_exit()을 호출한다. 자식 스레드는 syscall exit을 하기 위해 thead_exit() { process_exit() } 즉 process_exit을 수행하고 있는 상황이다.
2️⃣ sema_up(&curr->wait_sema);
자식 스레드는 process_exit()을 수행하며 그 하단부에서 자신의 wait_sema을 up함으로써 자신의 수행 종료를 부모에게 알린다.
그럼 이제 자식의 wait_sema의 waiter 큐에 있던 부모가 대기 큐(ready_list)에 들어가게 되고, 현재 실행 중인 자식 스레드는 계속 자기 하던 수행을 실행할 것이다.
3️⃣ sema_down(&curr->exit_sema);
자식 스레드는 이어서 자신의 exit_sema를 down한다. 그렇게 되면 ready_list에 있던 부모가 ready에서 running으로 상태 전환하여 실행이 되고, 자식 스레드는 자신의 exit_sema에 대한 waiter 큐에 들어간다. 이제 자식 스레드는 process_exit() 수행을 마쳤다.
4️⃣ 부모 스레드는 자식 스레드의 exit_status를 받아온 뒤 자식의 exit_status를 받고(syscall exit에서 받아 왔던 거),
5️⃣ sema_up(&child->exit_sema);
이제 자식 스레드가 ready list에 들어간다. 현재 실행 중인 부모 스레드는 계속 자기 수행을 실행한다. return exit_status.
6️⃣ process_wait returns exit_status. 이젠 실질적으로 자식은 종료가 된 것이나 마찬가지다.
실제론 자식은 현재 ready 큐에 들어가 있으며, 다음 번에 자식이 실행되면 되자마자 아까 실행하고 있던 지점인 thread_exit() 안의 do_schedule (THREAD_DYING);을 실행하게, 즉 상태가 dying으로 전환되게 될 것이다.
파일 디스크립터 테이블(fdt)과 파일 디스크립터(fd) 관련 syscall call들에 대한 이해와 구현
📌 역시 길어져 분기했다.
Project 2 도입 (2-2) | 개념 - 파일 디스크립터 테이블(fdt)과 파일 디스크립터(fd) 관련 syscall call들에 대한 이해와 구현
