
문제 배경
데이터를 내려줄 때 최신순으로 데이터를 내려주기로 했다.
오프셋 방식은
- 데이터 중복문제
- 데이터를 조회할때마다 데이터베이스를 처음부터 스캔
으로 인해 커서 방식을 채택했다.
커서 방식 페이지네이션을 방식을 이용해서 아래와 같이 코드를 구현했고 버그가 발생했다.
조회 요청시 마지막 id가 7이고 7 다음으로 가져와야하는
데이터는 2, 1 인데 실제로는 6, 5, 4, 3, 2, 1번 id가 조회되었다. 어디서 문제가 발생했을까?
먼저 코드를 봐보자!
- controller
@GetMapping
public SeriesSubscribeList.Response getSeriesList(
@RequestParam(required = false) Long lastSeriesId,
@RequestParam @Positive Integer size,
@RequestParam(required = false, defaultValue = "ALL") Category[] categories
) {
return this.seriesService.getSeriesList(lastSeriesId, size, List.of(categories));
}- service
public SeriesSubscribeList.Response getSeriesList(
Long lastSeriesId,
Integer size
) {
PageRequest cursorPageable = PageRequest.of(
0,
size,
Sort.by(Direction.DESC, "createdAt", "id")
);
return new SeriesSubscribeList.Response((
(lastSeriesId == null) ? this.seriesRepository.findAll(cursorPageable)
: this.seriesRepository.findByIdLessThan(lastSeriesId, cursorPageable)
)
}- repository
List<Series> findByIdLessThan(
Long id,
Pageable pageable
);코드를 보면,
처음 페이지 진입시에는 마지막 id를 알지못하기 때문에 null로 요청한다.
createdAt, id를 DESC 정렬 후 id가 null 이기 때문에 findAll로 데이터를 가져온다. (이 부분은 사실상 오프셋 방식의 페이지네이션과 동일하다.)
그 다음 요청시에는 마지막 id값을 기준으로 findByIdLessThan로 데이터를 가져온다. primary key는 인덱스가 걸려있기때문에 처음부터 데이터베이스에서 처음부터 데이터를 스캔하지않고 바로 id값으로 접근할 수 있다. 마지막 id보다 작은 id를 요청한 size만큼 가지고 온다. 코드에 이상한점이 없다고 판단했다.
그렇다면 데이터베이스 시리즈 테이블을 봐보자!
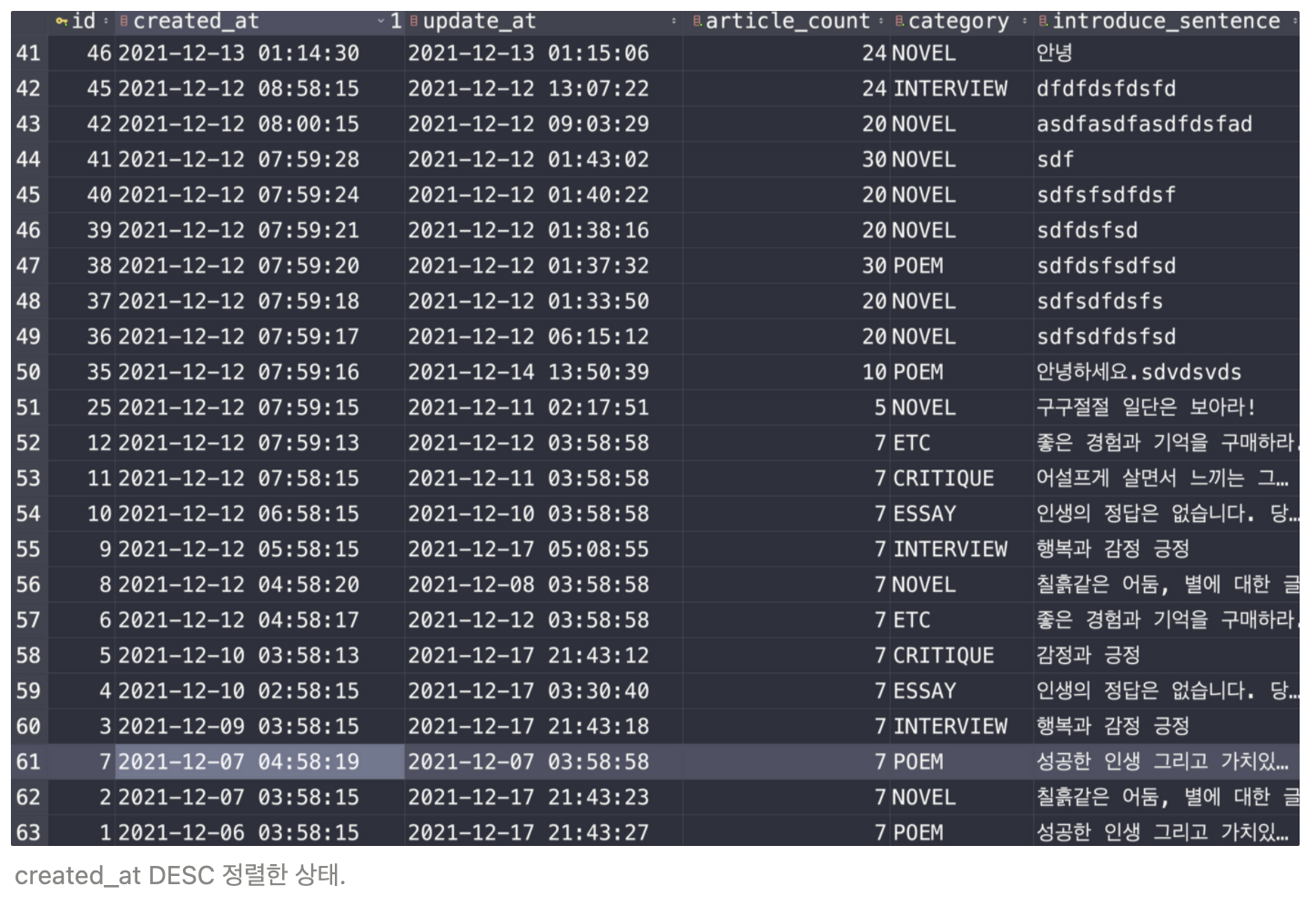
테이블에 다음과 같이 데이터가 들어가있는 상황이었고 id 7 다음으로는 2, 1 번밖에 없다.
왜 6, 5, 4, 3 이 조회가 되는걸까?
여기서 이상한 점이 하나있다.
id는 시리즈가 발행된 시간순에 따라 증가(auto_increment)되기 때문에 created_at으로 정렬했을때 id값도 동일하게 DESC 정렬이 되어야한다고 생각했다.
기대한 시나리오는 id가 6, 5, 4, 3, 2, 1 로 정렬이 되는 것이었는데 id가 6, 5, 4, 3, 7, 2, 1 과 같이 정렬되는 것을 볼 수 있다.
이 부분을 유심히 생각해봤다.
지금 데이터에서
- Sort.by(Direction.DESC, "createdAt", "id") 로 정렬하고,
- findByIdLessThan(lastSeriesId, cursorPageable) 했을 때,
당연히 7보다 작은 6, 5, 4, 3, 2, 1이 전부 조회되는게 맞았다. 로직은 틀리지 않았다.
createdAt 데이터가 기대했던대로 들어가지 않는 이유에 대해 먼저 파악했다.
원인으로는
- 현재 로컬 디비와 운영 디비가 분리되어있지 않는 상황이고,
- 로컬 환경은 한국 시간, ec2 서버는 미국 시간 기준이었다.
결론적으로 id와 created_at이 동일하게 정렬된다는 전제자체가 틀렸던 것 이다.
이 문제를 해결하기 위해서는 어떻게 해야할까? 간단하게 생각난 방법으로는
로컬 환경, 서버 환경 시간을 맞추는 것인데 이 전제는 언제든지 깨질 수 있다고 생각했다.
더 나아가 id가 auto_increment 전략이 아니라 uuid 전략이 된다거나,
커서가 id가 아니라 다른 데이터가 될 수도 있기때문에 이에 대해서도 대응할 수 없다고 판단했다.
그렇다면 id 순서에 상관없이 id를 원하는대로 가지고 오려면 어떻게 해야할까?
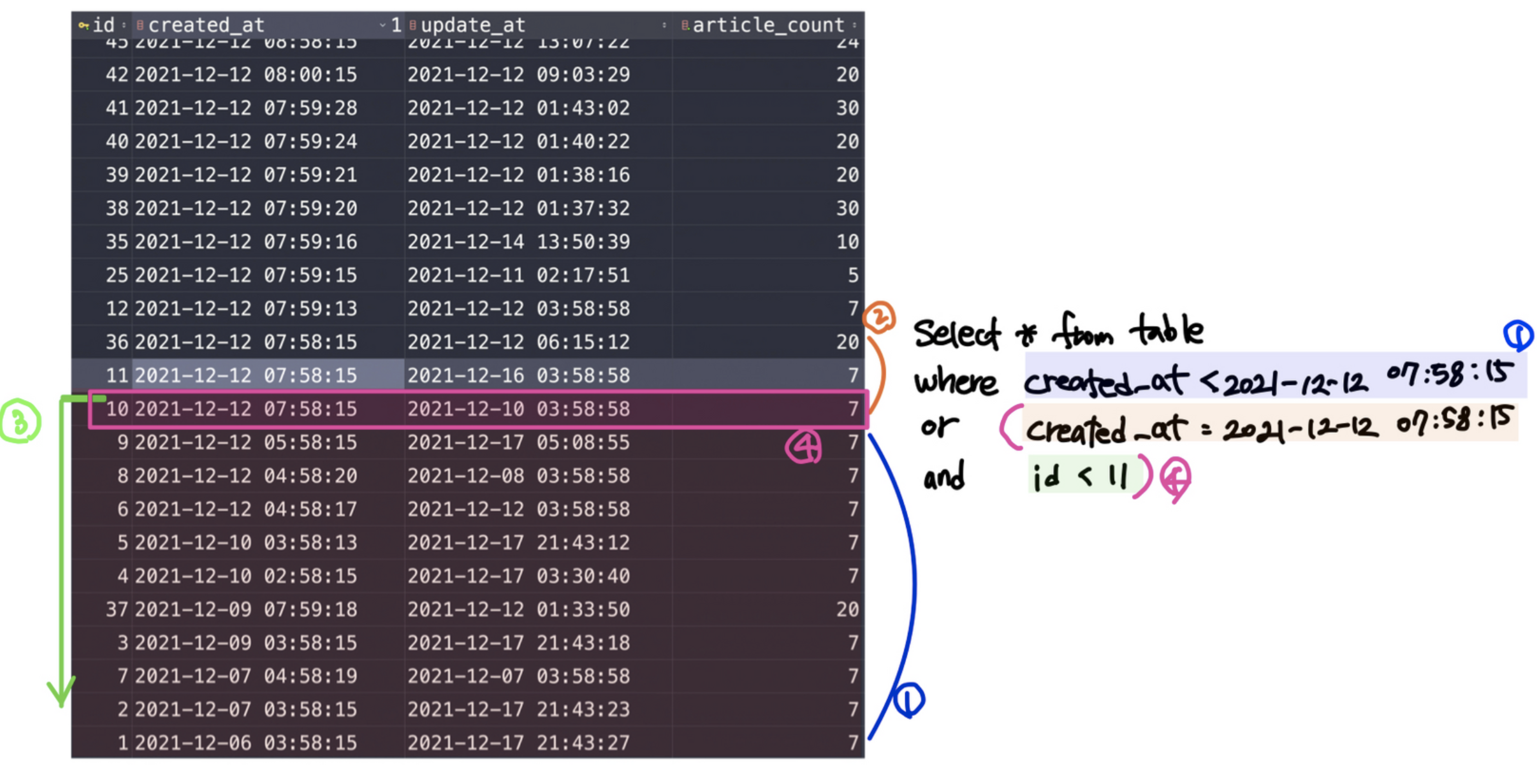
마지막 id 요청이 11로 왔다면 다음 데이터는 10, 9, 8, 6, 5, 4, 37, 3 ... 가 조회되어야 한다.
10~ 1 번까지의 데이터를 어떻게 하면 조회할 수 있을까?
(created_at, id DESC 정렬한 상태)
쿼리를 다시 생각해보면 아래와 같다.
SELECT * FROM table_name
WHERE created_at < "2021-12-12 07:58:15"
OR (
create_at = "2021-12-12 07:58:15"
and id < 11
) 그러니까 일단 2021-12-12 07:58:15 보다 작은 데이터를 가져오고, 혹시 중복될 수 있으니
2021-12-12 07:58:15와 같으면서 id 가 11보다 작은 데이터를 가져오면 원하는 결과를 얻을 수 있다.
그림에서 1번 영역과 4번 영역이 조회해야할 대상이 되는 것이다.
