출처 : 한국경제학보 제26권 제2호
(The Korean Journal of Economics Vol. 26, No. 2 (Autumn 2019) )
작년부터 관심있게 봤던 논문인데 아직 한번도 제대로 본 적이 없어서 쉬어가는 타이밍에 ML 관련 내용을 정리해보고자 한다 !
요약
본 논문은 경제학 전공자를 대상으로 인공 지능을 구현하는 핵심 기법인
머신 러닝의 개념과 주요 방법론, 경제학과 경제에 미치는 영향을 개괄적
으로 소개하고자 한다. 먼저 머신 러닝의 주요 범주인 지도 학습, 비지도
학습, 강화 학습의 개념을 소개하고 기존 계량경제학 접근법과의 차이점을
설명한다. 그리고 학계와 산업계에서 널리 연구되고 활용되는 지도 학습
분야에서 분류 및 회귀를 위해 사용되는 주요 방법론을 예를 통해 설명한
뒤 머신 러닝 기법이 활용된 경제학 분야의 최신 연구들, 노동시장에 미치
는 영향, 데이터의 가치를 둘러싼 논쟁에 대해 살펴본다.[ 핵심 주제어 : 인공 지능, 머신 러닝, 지도 학습, 빅데이터 ]
I. 서론
본 논문은 인공 지능 분야에 대한 사전 지식이 없는 경제학 전공자를 대
상으로 인공 지능, 그리고 그 하위 개념이라 볼 수 있는 머신 러닝(ML,
machine learning)의 개념, 주요 방법론 및 활용, 경제와 경제학에 미치
는 영향을 개괄적으로 논의하고자 한다.
-
제Ⅱ장 : 인공지능과 머신러닝의 개념을 살펴본 후 머신러닝의 세
가지 범주인 지도 학습(supervised learning), 비지도 학습(unsupervised
learning), 강화 학습(reinforcement learning)이 무엇인지 설명한다.
그리고 머신 러닝이 기존 계량경제학의 방법론과 어떤 차이가 있는지 설명한다. -
제Ⅲ장 : 학계와 산업계에서 널리 연구, 활용되고 있는 지도 학
습의 주요 기법들을 소개한다. 구체적으로, 분류(classification)와 회귀
(regression)를 위해 쓰이는 KNN(K-Nearest Neighbors), 의사결정 트
리(decision tree), 서포트 벡터머신(SVM, support vector machine),
규제된 회귀(regularized regression) 기법들을 예를 통해 살펴본다. -
제Ⅳ장 : 이미 머신 러닝 기법이 활용되기 시작한 경제학 분야의 관련 연구
들을 살펴본다. -
제Ⅴ장 : 인공 지능이 노동시장에 미치는 영향을 이해하기 위해 알고 있어야 할 배경 지식을
소개한다. 또한, 엄청난 수익을 올리고 있는 구글, 페이스북 같은 거대 테크 기업들의 데이터가 사실 이들 회사의 무형 자본이 아니라 사용자들이 제공한 노동의 대가라는 주장들이 최근 학계와 정치계에서 나오고 있는 가운데 이에 대한 논리와 반론을 살펴본다. -
제VI장 : 머신러닝이 경제학자들의 주된 관심사 중 하나인 인과관계 추론(causal inference)과 어떤 관계를 가지며 어떻게 기여할 수 있는지에 대한 최근 논의를 간단하게 소개한다.
II. 머신러닝의 개념 및 유형
1. 머신러닝의 유형
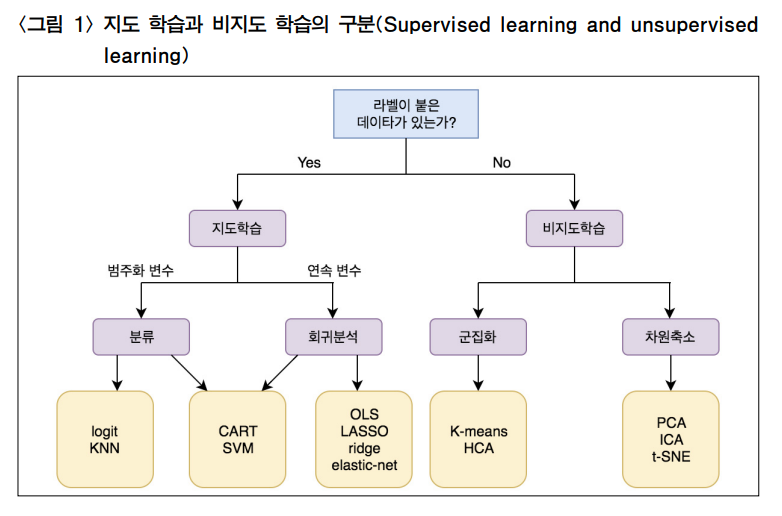
(1) 지도 학습(Supervised Learning)
지도 학습이 비지도 학습과 구별되는 가장 큰 특징은 라벨(label)이 붙어
있는 데이터(labeled data)를 이용한다는 것이다. 데이터의 형태는 인데 는 라벨(이름표 내지 정답), 는 특성(features)이다.
예를 들어, 스팸 메일 여부가 0과 1로 표시된 변수가 , 스팸 메일의 전형적인 특징들(특정 문구 유무, 이메일 주소 등)이 에 해당한다. 사진 속에 고양이가 있는지 여부를 가리는 작업의 경우 사진 속에 고양이가 있는지 여부가 0과 1로 표시된 변수가 , 고양이 얼굴의 특성에 대한 픽셀 정보 등이 가 된다. 지도 학습의 목적은 를 통해 를 예측하는 것이다.
위 정의에 따르면, 선형 회귀분석(linear regression)도 지도 학습의 한 예가 될 수 있다. OLS 방식으로도 부른다.
요약하면 지도 학습은 라벨이 붙어 있는 데이터를 이용해서 모형을 학습시키고 검증한 뒤, 새로운 데이터를 보여주고 해당 데이터의 라벨을 예측하는 것이다. 지도 학습의 알고리듬으로는 로짓, 나이브 베이즈(naïve Bayes), KNN(K-Nearest Neighbors), 의사결정 트리(decision tree), SVM(Support Vector Machine), 규제된 회귀(regularized regression), 랜덤 포레스
트(random forest), 신경망(neural net), 딥러닝(deep learning) 등이 있다.
(2) 비지도학습(Unsupervised Learning)
비지도 학습은 지도 학습과 달리 라벨이 없는 데이터, 즉 없이 만 있는 데이터를 군집화(clustering)하거나 차원 축소(dimensionality reduction)할 때 사용한다. 구글 포토 등 사진 앱에서 누구의 사진이라고 이름을 붙이지 않아도 앱에서 자동으로 사람 별로 사진들을 분류해 주는데 바로 비지도 학습의 전형적인 예이다. 이외에도 의료 영상을 판독한다든가 차원 축소를 통해 DNA 정보를 축약하는 목적 등에 사용한다.
군집화에 많이 쓰이는 알고리듬으로는 k-means, HCA(Hierarchical Cluster Analysis), 기대값 극대화(expectation maximization) 등이 있고 시각화, 차원 축소와 관련해서는 주성분 분석(PCA, Principal Component Analysis), ICA (Independent Component Analysis), kernel PCA, LLE (Locally-Linear Embedding), t-SNE(t-distributed
Stochastic Neighbor Embedding) 등이 많이 사용된다.
(3) 강화 학습(Reinforcement Learning)
주어진 환경 하에서 의사결정을 하고 그 결과에 따라 보상 또는 벌칙을 받는 방식으로 훈련을 하는 것을 강화 학습이라 하며 원리상 마코프 프로세스(Markov process)에 기반한 동태적 최적화(dynamic optimization)의 개념과 일치한다.
특히 강화 학습에서 최근 자주 쓰이는 생성적 적대 신경망(GAN: Generative Adversarial Network)은 생성자(generator)와 감별자(discriminator)가 서로 경쟁하게 만드는
방식으로 학습한다.
2. 기존 계량경제학 방법론과의 차이
머신러닝의 방법론, 특히 지도 학습의 방법론은 기본적으로 계량경제학의 방법론과 근본적 차이는 없지만, 목적, 진행 방식, 용어에서 차이를 보인다.
목적의 차이
Varian(2014)은 기존 통계학과 계량경제학의 분석 목적은 예측, 요약, 추정, 가설 검정으로 이루어져 있으나 머신 러닝은 예측(prediction)의 문제를 다룬다고 본다. 통상적으로 계량경제학의 기본적인 작업은 표본 전체를 이용해서 평균자승오차나 우도 함수를 최적함으로써 모수를 추정하고
가설을 검증하는 방식으로 이루어진다.
진행 방식의 차이
반면 머신러닝 작업에서는 통상적으로 표본의 70-80% 정도를 추출해서 훈련 세트를 구성하고 이 훈련 세트를 대상으로 추정(모형을 훈련)한다. 그리고 얻어진 결과를 검증 세트라 부르는 나머지 표본을 이용해서 예측하고 평가한다. 예측의 문제에서 가장 중요한 것은 좋은 표본 외 예측(out-of-sample prediction)을 하는 것인데 상대적으로 복잡한 모형일수록 훈련 세트 내 예측에 비해 검증 세트 내 예측의 성능이 떨어지는 문제가 발생한다. 이를 과대 적합(overfitting)이라
부른다.
용어의 차이
이 문제를 부분적으로 해결하기 위해 모형의 복잡도(complexity)에 대해 패널티를 주는데 이를 규제(regularization)라 부른다. 또 다른 용어의 차이로 계량경제학에서 흔히 사용하는 설명변수(explanatory variables) 또는 독립변수(independent variables)란 용어 대신에 머신
러닝 분야에서는 특성(features)이라 부른다. 그리고 피설명변수, 종속 변수는 흔히 타겟 변수(target variable)라 한다.
표본 사용 방식의 차이
표본을 사용하는 방식도 상이하다. 위에서 언급한 바와 같이 계량경제학에서는 일반적으로 표본 전체를 추정에 사용하지만 머신 러닝은 훈련 세트와 검증 세트로 나누어서 각각 훈련(추정)과 표본 외 예측을 위해 사용한다.
이때 검증 세트 추출의 자의성을 줄임으로써 모형의 성능을 제고하는 방법 중 하나가 k겹 교차 검증(k-fold cross-validation)이다. 예를 들어 k=5인 경우 표본을 다섯 개의 서브 샘플(1,2,3,4,5)로 나눈 후 첫번째 단계에서는 서브 샘플 1,2,3,4를 훈련 세트, 5를 검증 세트로 사용하고 두번째 단계에서는 2,3,4,5를 훈련 세트, 1을 검증 세트로 사용하는 방식이다.
이렇게 5번의 추정을 종합하여 모형을 평가한다. 이런 방식으로 추정할 경우 검증 세트의 자의성을 줄일 수 있는데 Varian(2014)은 기존의 계량경제학 기법에서도 교차 검증을 적극 사용할 것을 권장하고 있다.
또 한 가지 차이점은 초매개변수 조정(hyperparameter tuning)의 필요성이다. 좋은 표본 외 예측 능력을 갖추기 위해서 초매개변수 조정이 필요한데 초매개변수에 대해서는 아래에서 예를 들어 설명을 한다.
