💻 Inflearn 최주호 강사님의 스프링부트 개념정리(이론) 강의를 듣고 정리한 내용입니다.
😅 구글 Docs로 작성하였다가 옮긴 것이라 표현이 깨지거나 이상할 수 있습니다.
📑 참고 자료
스프링
1강 스프링의 핵심은 무엇인가요?
프레임워크
Framework
frame:틀 work:동작하다 → 틀안에서 동작하다
프레임워크를 만든 이유 : 이 틀안에서 벗어나지 말라, 마음대로 만들지 말고 제공하는 틀에 맞춰서 개발하라
오픈소스
소스코드 공개
스프링이 어떻게 만들어졌는지 내부를 알 수 있음 → 내부를 뜯어 고칠 수 있다.
내부를 고쳐서 contribute(기여)를 할 수 있음
무료
IoC 컨테이너
IoC (Inversion of Control : 제어의 역전)
주도권이 스프링에게 있다
Class/Object/Instance
Class → 설계도
Object → 실체화가 가능한 것
Instance → 실체화 된 것
예시) 롤에서 [누누]라는 캐릭터
Class
누누 {
변수
변수
}
누누를 만들기 위한 설계도
게임할 때 실체로 튀어나오는 캐릭터 → 실체화가 가능 → Object
abstract Class
캐릭터 {
추상적인 의미
}
캐릭터에 누누, 티모, 신지 등 많은 것들이 올 수 있음
캐릭터는 추상적인 것이기 때문에 실체화가 불가능 → Object X
누누가 게임에서 돌아다님 → 실체화가 된 것
가구 (추상적)
의자 : Object
침대 : Object
IoC
의자 s = new 의자();
개발자가 오브젝트(의자)를 직접 new를 해서 heap이라는 공간에 올리게 되면 그 주소는 레퍼런스 변수 s.
이 s는 new를 만든 해당 메서드 내부에서 관리
public void make() {
의자 s = new 의자();
}
의자 s를 실체화해서 메모리에 띄움 → 주소를 s가 들고 있음
근데 이 s는 메소드가 실행되는 순간에만 메모리에 적재
다른 메소드에서 이 의자를 사용하고 싶다면??
public void use() {
의자 s = new 의자();
}
그럼 메모리에 새로운 의자 s가 뜸
메모리에 있는 두개의 의자 s는 서로 다름
각 주소는 각각의 레퍼런스 변수 s가 관리 → 공유가 힘듬
make의 s를 사용하고 싶었는데 use에서 s 공유X
공유 로직을 짜기 어려움
그래서 스프링이 IoC를 해줌
<heap 메모리>
의자 → 의자
붕어빵 스프링 → 붕어빵
사자 ←스캔 → 사자
기린 → 기린
- 스프링이 Object를 읽어서 메모리에 올려줌
DI
Dependency Injection
원래는 개발자가 객체(Object)를 new를 해서 그 객체의 주소를 개발자가 관리를 했다면
이제는 스프링이 스캔을 해서 객체를 메모리에 띄웠기 때문에 스프링이 관리(IoC)
그럼 스프링이 관리하는 이 객체를 개발자가 원하는 모든 곳(Class의 메소드)에서 가져와서 사용할 수 있음
다른 곳에서 사용하는 모든 의자는 하나의 의자 s를 공유한 것(싱글톤)
이렇게 필요한 곳에서 가져다 쓰는 것을 DI라고 함
스프링은 IoC와 DI를 잘 하면 됨
IoC와 DI를 잘하면 코드를 짜는 게 편함
2강 필터란 무엇인가요?
다량의 필터
필터는 검열의 기능(문지기)
스프링 자체에 필터 기능들이 있음
스프링의 필터를 사용할 수 있고 직접 필터 생성도 가능
톰캣을 걸쳐서 스프링 컨테이너에 접근.
톰캣과 스프링 컨테이너에 있는 필터는 이름이 다르게 불림.
톰캣이 들고 있는 필터는 실제로도 필터(filter)라고 불리고
이 필터의 환경설정 파일을 web.xml이라고 함.
스프링 컨테이너가 들고 있는 필터는 인터셉터라고 부름.
AOP라는 개념 존재 (중요!!)
권한 체크를 해줌.
다량의 어노테이션 (리플렉션, 컴파일체킹)
어노테이션
어노테이션 (주석 + 힌트) ← 컴파일러 무시 X
// 글~ (주석) ← 컴파일러 무시
컴파일체킹
Animal {
run()
}
Dog 상속 Animal {
@override
run();
}
↑ Dog 컴파일할 때 @override라는 어노테이션을 보고 Animal에 run()이 있는 것을 확인함.
만약에 run()이라는 함수가 없을 경우 컴파일체킹시 에러가 남.
리플렉션
스프링은 어노테이션을 통해서 주로 객체 생성을 함.
@Component → 클래스 메모리에 로딩
@Autowried → 로딩된 객체를 해당 변수에 집어 넣음
@Component ← IoC 스캔
Class A {} A
Class B {
@Autowired ↓ 분석(리플렉션)
A a; ↓ - 메소드 / 필드 / 어노테이션 체킹 → 명령을 설정할 수 있음
}
리플렉션은 런타임시 분석하는 기법
만약에 heap에 A가 없다면 a엔 null이 들어감
반면에 있다면 IoC가 읽어들인 메모리에서 객체를 타입으로 찾음 (DI)
3강 메시지 컨버터가 무엇인가요?
Message Converter
현재 기본값은 Json
예전 기본값은 xml
자바 Object와 파이썬 Object는 언어가 달라서 통신이 안됨
중간 언어로 json 사용
자바 Object → Json → 파이썬 Object
자바 Object을 파이썬 Object로 변경하는 것은 어려우나 Json으로 변경하는 것은 쉬움
자바 Object Json
Class Animal { {
int num = 10; → “num” : 10,
String name = “사자”; “name” : “사자”
} }
자바 Object를 Json으로 직접 번역해야함
Message Converter를 쓰면 자동으로 번역해서 Json으로 만들어줌
자바 프로그램이 파이썬 프로그램에게 요청(request)를 하면 스프링 라이브러리인 Message Converter가 자바 Object를 Json으로 변경
현재 Message Converter는 Json으로 변경해주는 Jackson 라이브러리로 설정되어 있음
응답(response)을 받을 때도 Json 데이터가 옴
이 때 Json 데이터가 자바 프로그램으로 올 때 Message Converter가 자바 Object로 변경해줌
BufferedReader와 BufferedWriter 쉽게 사용
데이터가 통신을 할 때 전기선을 통해 전류로 이동을 하게 될 때 bit 단위로 통신이 됨
ex) 0, 1, 0, 1, 1, 1, 0, 0 …
bit단위가 아닌 영어 한문자로 통신할려면 8bit 필요 (한글은 최소 16bit 필요)
8bit면 256가지의 문자 전송이 가능함 (28 = 256)
8bit씩 끊어 읽으면 한문자씩 수신 가능 → 8bit를 논리적으로 변경
→ 8bit = 1byte → 1byte : 통신 단위
1byte = 하나의 문자 (한글은 2byte가 한 문자)
전 세계의 언어로 글을 인코딩할 때 각자 다른 byte를 사용하게 되면 통신 불가능
→ 유니코드 : utf-8 제공 (3byte 통신)
이 통신을 Byte Stream이라고 함 (1byte로 보냄)
자바에서 InputStream으로 읽음
InputStream은 바이트 단위로 읽음 → 처리시 문자가 아닌 바이트로 받음
문자로 변형하기 위해서 받은 데이터를 문자(char)로 캐스팅을 해서 처리해야하는데 복잡함
→ InputStreamReader 클래스로 바이트를 감싸면 문자 하나를 줌
InputStreamReader는 문자 하나 뿐만 아니라 배열로 여러개의 문자도 받을 수 있음
단점은 배열의 크기가 정해져있어야 함
적은 양의 데이터를 보낼 때 배열의 공간이 낭비됨
그래서 사용 X
BufferedReader로 데이터를 감싸서 수신
가변길이의 문자를 받을 수 있음
데이터 요청시 데이터를 담아서 요청
→ 상대가 데이터 수신시 BufferedReader로 받아야 함
jsp에서는 request.getReader() 함수를 쓰면 BufferedReader 역할을 해줌
데이터를 쓸 때에도 BufferedWriter를 사용해야 함
근데 내려쓰기 기능이 없어서 자바에서는 PrintWriter를 사용함
PrintWriter는 BufferedWriter랑 똑같지만 PrintWriter는 print()와 println() 함수를 제공
내려쓰기 사용시엔 println(), 미사용시엔 print()
jsp는 out 이라는 내장 객체가 있음 out 자체가 BufferedWriter.
BufferedWriter는 Byte Stream을 통해서 데이터를 전송할 때 전송단위가 문자열로 가변길이 데이터를 쓰게 해주는 클래스.
BufferedWriter와 BufferedReader를 직접 구현할 필요없이 어노테이션으로 제공해줌
@ResponseBody → BufferedWriter 동작
@RequestBody → BufferedReader 동작
계속 발전
계속 발전하고 계속 편해짐
JPA
4강 JPA란 무엇인가요?
Java Persistence API
영속성(persistence)
: 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성.
파일 시스템, 관계형 데이터베이스 혹은 객체 데이터베이스 등을 활용하여 구현함.
RAM은 휘발성 데이터를 저장(전기로 데이터를 저장하기때문에)
→ 컴퓨터를 끄면 데이터가 사라짐
하드디스크(파일시스템)에 데이터를 기록하게 되면 비휘발성이기 때문에 데이터가 사라지지 않음.
자바에서는 데이터를 DBMS에 기록하고 관리함. (하드디스크 일부에 위치)
JPA는 자바가 DBMS에 기록할 수 있도록 환경을 제공하는 API
API
: 애플리케이션(A) → 프로그램
프로그래밍(P) → 프로그램을 만들기 위한 방법
인터페이스(I) → 인터페이스
프로토콜 / 인터페이스
약속 약속
동등한 관계로 존재 상하관계가 존재
인터페이스로 받은 데이터로 프로그래밍을 하면 API
JPA (Java Persistence Application Programing Interface)
: 자바 프로그래밍을 할 때 영구적으로 데이터를 저장하기 위해서 필요한 인터페이스
5강 ORM이란 무엇인가요?
ORM
Object Relational Mapping
object를 데이터베이스에 연결하는 방법론
모델링은 추상적인 개념을 현실세계에 뽑아내는 것
자바에 데이터를 input하면 DML(Delete/Update/Insert)
데이터를 output을 하려면 Select
자바의 데이터 타입과 DB의 데이터 타입이 다름 → class를 통해서 DB 데이터를 모델링함.
Team 테이블 Class Team {
ID | int int id;
Name | varChar → String name;
Year | varChar String year;
}
ORM은 객체 기반 → Class 먼저 생성
Team 테이블 Class Team {
ID | int int id;
Name | varChar ← String name;
Year | varChar String year;
}
이 때 JPA가 가지고 있는 인터페이스가 필요.
ORM은 자바에서 클래스를 실행하면 데이터베이스에 테이블이 자동 생성하게 되는 기법
반복적인 CRUD 작업 생략
자바에서 DB에 connection 요청 → DB가 세션 오픈 → 자바가 connection 소유
→ 자바가 DB에서 쿼리 전송 → DB는 해당 쿼리를 통해서 데이터를 자바에 응답
→ 자바와 DB가 서로 데이터 타입이 다르므로 자바는 해당 데이터를 자바 Object로 변경
자바 Object로 변경하는 것은 단순한 반복 로직임.
JPA에서 위의 모든 작업을 함수 하나로 제공
CRUD를 JPA가 단순하게 처리할 수 있도록 도와줌.
6강 영속성 컨텍스트란 무엇인가요?
영속성 컨텍스트
영속성 : 데이터를 영구적으로 저장
자바에서는 파일시스템이 아닌 데이터베이스에 저장
컨텍스트(context)는 대상의 모든 정보를 가지고 있음.
자바와 DB는 영속성 컨텍스트를 통해서 데이터를 주고받으며 자동으로 처리됨.
자바가 DB에서 데이터를 CRUD하는 모든 과정을 영속성 컨텍스트로 확인 가능함.
DB와 OOP의 불일치성을 해결하기 위한 방법론을 제공
DB에 넣을 수 있는 데이터 타입은 기본자료형 → Object 저장 X
자바에서는 FK대신 Object를 넣을 수 있음 (OOP:객체지향)
JPA가 자동으로 매핑하여 넣어줌
7강 OOP 관점에서 모델링이란 무엇일까요?
OOP의 관점에서 모델링
Class Car extends ED { Class Engine extends ED { Class EntityDate {
int id; (pk) int id; TimeStamp createDate;
String name; int power; TimeStamp updateDate;
String color;
Engine engine;
} } }
car 클래스와 engine 클래스는 컴포지션(결합) 관계. (상속X)
car 클래스와 engine 클래스에 EntityDate 클래스 상속
JPA가 DB 자동생성
Car Engine
id | name | color | engineId | createDate | updateDate id | power | cD | uD
방언 처리 용이
Migration하기 좋고 유지보수하기 좋음.
스프링 → JPA → DB
(추상화 객체)
dialect에는 여러개가 있음 (오라클, 마리아DB, MySQL, MsSQL 등)
JPA에서 추상화 객체를 하나 두고 DB에 연결함.
추상화 객체에 dialect를 넣어서 사용
Springboot 동작원리
8강 HTTP가 무엇일까요?
내장 톰캣
톰캣을 따로 설치할 필요 없이 바로 실행 가능
Socket
운영체제가 가지고 있는 것
소켓통신
A가 5000번 포트에 소켓 오픈 → B가 ip주소를 5000으로 설정하여 A와 통신
→ ip 5000은 B가 쓰고 있으므로 C는 A와 통신 X
↓
A의 5000번 포트는 연결의 용도로만 사용하고 연결되는 순간 새로운 소켓 생성(5001번)
→ B는 5000번 소켓과 연결이 끊기고 5001번 소켓에 연결되어 통신 → 모든 자원을 5001 소켓에서 A와 B가 통신하는데 사용됨 → 5000번 소켓에서 C의 요청을 못받고 작동을 못함(CPU의 자원이 없어서)
↓
5000 소켓에 main 스레드를 생성하여 계속 요청을 받음
5001 소켓에 스레드를 생성하여 B와 통신
C가 메인스레드에 요청 → 5002 소켓과 스레드 생성 → C는 메인스레드와 연결을 끊고 5002 스레드와 통신
time slice 시간을 쪼개서 활동하지만 동시동작하는 것처럼 보임
연결이 끊어지지 않고 계속 지속됨 → 부화가 심함 → 느려질 수 있음
http 통신(문서를 전달하는 통신) - Stateless 방식
요청을 하면 응답을 해주고 연결을 끊음 → 요청자가 누구인지 모름
반면에 소켓통신은 한번 연결하면 계속 지속되기 때문에 서버에서 요청한 상대를 알 수 있음
9강 톰켓이란 무엇인가요?
톰캣
http의 기반은 소켓
톰켓과 웹서버의 차이를 알아야 함.
요청자가 데이터를 가지고 있는 자에게 request(요청)를 함
요청자의 위치를 알려주는 ip주소를 보내야 하고
무엇을 필요로 하는지 알려주는 url이 있어야 함. url은 자원을 요청하는 주소
ex) http:~/a.html // http:~/b.avi
응답자는 요청자의 ip주소를 토대로 response(응답)해줌.
응답자가 웹서버가 됨
Static 자원(정적인 자원)을 지원함
웹서버는 주로 아파치를 사용
JSP 혹은 자바코드를 요청하면 아파치는 자바코드를 이해하지 못함 → 톰켓을 추가
톰켓이 JSP → 자바 → html 문서로 변환 → 아파치가 응답
아파치는 요청한 파일을 응답
톰켓은 요청한 파일중에 자바 코드가 있으면 컴파일하여 html로 번역하여 반환
10강 서블릿 객체의 생명주기가 궁금해요!
서블릿 컨테이너
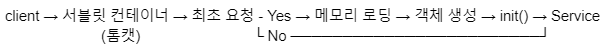
요청을 받을 때 무조건 스프링 동작X, 아파치 동작
URL - 자원 접근 (Location) ex) http://naver.com/a.png
URI - 식별자 접근 (Identity) ex) http://naver.com/picture/a
스프링은 URL 요청 X → 특정한 파일 요청 X, 무조건 자바를 거쳐야 함
{kind=link}
요청이 서블릿 컨테이너에 들어옴
→ Java 자원이면 서블릿 컨테이너 동작 / 정적인 자원이면 아파치 동작
서블릿 컨테이너가 동작을 하게 되면
첫번째 요청이면 서블릿 객체 생성
초기화 메소드 init() 호출
스레드 하나 생성
Service()에서 Post/Get/Put/Delete 확인
Get으로 왔다면 get() 호출 (post(), delete(), put())
→ DB연결, 데이터 검색, html에 담아서 응답
두번째 요청이면 서블릿 객체 재사용
메서드 호출은 독립적
새로운 스레드를 생성하여 Service() 실행
톰켓 기본설정 → 스레드 Auto 20개
스레드가 20개까지 생성되고 21번째 요청은 대기상태
요청이 끝나면 스레드 종료(response)
스레드를 날리지않고 21번째 요청을 실행
위를 재사용 Pooling 기법이라고 함.
컴퓨터의 성능을 업그레이드해서 스레드를 늘리는 것을 scale-up이라고 함.
컴퓨터를 여러개 만들어서 분산처리하는 것을 수평적 확장 scale-out이라고 함.
11강 웹 배포서술자(web.xml)에 대해서 알려줘요!
web.xml
문지기 역할
ServletContext의 초기 파라미터 (암구호)
Session의 유효시간 설정 (인증 유효시간)
Servlet/JSP에 대한 정의
Servlet/JSP 매핑 (요청한 데이터의 위치를 알려줌)
Mime Type 매핑 (가져온 데이터의 타입 확인, 가공)
Welcome File list (위치도 데이터도 없이 온 요청을 모아둠)
Error Pages 처리 (잘못된 요청 수신시 에러페이지)
리스너/필터 설정 (특정 조건 확인)
보안
12강 디스패처 서블릿이 무엇인가요?
FrontController 패턴
최초 앞단에서 request 요청을 받아서 필요한 클래스에 넘겨줌.
web.xml에 다 정의하기엔 힘드므로
request 요청 → .do(특정주소)가 오면 FrontController에 오도록 web.xml에 설정되어 있음
→ URI 혹은 자바파일 요청이 들어오면 톰켓으로 이동 → request와 response 객체를 만듬
→ request엔 요청자의 정보, response는 응답해줘야하는 정보
→ 해당 자원을 찾아가서 request함(재요청)
객체로 저장되면 request.(변수 or 함수) 사용가능
자원에 재요청하게 되면서 request와 response가 새롭게 new될 수 있음
→ RequestDispatcher 필요
RequestDispatcher
필요한 클래스 요청이 도달했을 때 FrontController에 도착한 request와 response를 그대로 유지시켜줌.
DispatcherServlet
FrontController 패턴 + RequestDispatcher
스프링에는 DispatcherServlet이 있으므로 FrontController 패턴을 직접 짜거나 RequestDispatcher를 직접 구현할 필요가 없음.
자동생성되어질 때 수 많은 객체가 생성(IoC)됨. 주로 필터들
13강 애플리케이션 컨텍스트란 무엇인가요?
스프링 컨테이너
ApplicationContext
request → web.xml → ContextLoaderListener→ DispatcherServlet 컴포넌트 스캔/주소 분배
주소 분배를 위해서는 class들이 메모리에 있어야 함.
static은 main 메소드가 실행되기 전부터 메모리에 있음.
자바파일은 객체로 메모리에 있기때문에 생성과 사라짐이 있음.
IoC이기 때문에 직접 생성X → DispatcherServlet이 대신 생성해줌.
컴포넌트 스캔(메모리에 로딩)은 src폴더 - 패키지 - 자바파일을 다 확인함.
어노테이션으로 필요한 파일을 확인하고 메모리에 적재함.
servlet-applicationContext
Servlet만 관리
ViewResolver, Interceptor, MultipartResolver 객체 생성, 어노테이션 Controller, RestController 스캔 → DispatcherServlet에 의해 실행
root-applicationContext
ContextLoaderListener는 공통적으로 사용되는 DB나 스레드를 미리 메모리에 띄움.
ContextLoaderListener는 web.xml → servlet-applicationContext보다 먼저 실행
root-applicationContext파일로 커스터마이징 가능
Bean Factory
@Bean
초기에 메모리 로드X
필요할 때 getBean() 메소드로 호출하여 메모리 로드 (lazy-loading)
14강 스프링부트가 응답(Response)하는 방법이 궁금해요!
요청 주소에 따른 적절한 컨트롤로 요청 (Handler Mapping)
GET 요청 → http://localhost:8080/post/1
해당 주소 요청이 오면 적절한 컨트롤러의 함수를 찾아서 실행
응답
html파일을 응답할지 Data를 응답할지 결정해야 함.
html파일을 응답하게 되면 ViewResolver가 관여함.
어떤 파일인지에 대한 파일 패턴을 만들어줌.
ex) hello라는 파일을 보낼 때 web-INF/views/hello.jsp, 경로와 확장자까지 보냄
Data를 응답하게 되면 MessageConverter가 작동함.
메시지를 컨버팅할 때 기본전략은 json.
ex) { “id”:1, “name”:”홍길동” }
Request → DispatcherServlet → Handler Mapping → ViewResolver
└→ MessageConverter
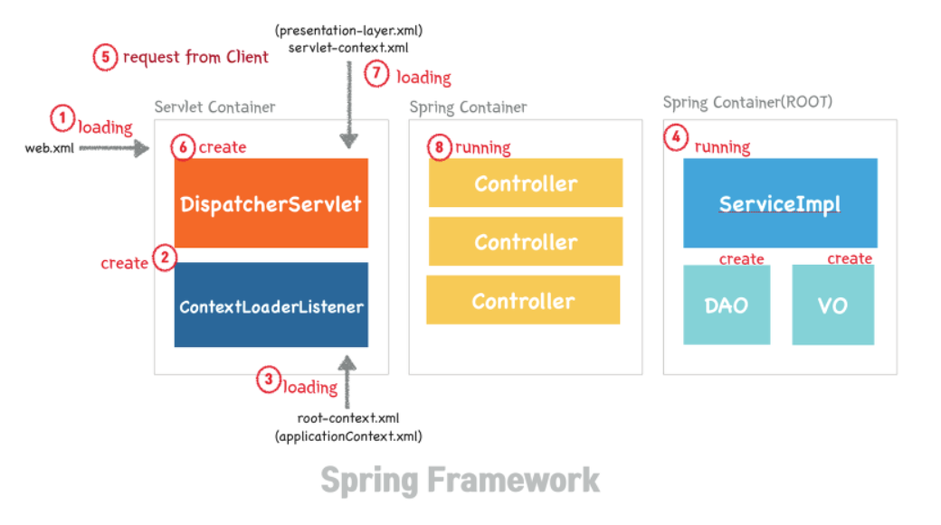
톰켓 실행시 web.xml 로딩 → ContextLoaderListener 생성 → root-context.xml(applicationContext.xml) 로딩 → ServiceImpl, DAO, VO 메모리에 띄어짐
→ request 요청 → DispatcherServlet 동작
→ servlet-context.xml에 의해 DispatcherServlet 읽힘
→ DispatcherServlet이 주소분배 → 배정된 Controller에서 응답(Response)함
