- 실제 스타벅스 음료 메뉴에 있는 정보들을 크롤링하여 csv 파일로 저장하고 데이터베이스에 넣어보자
- 스타벅스 홈페이지의 음료 카테고리에 있는 메뉴들에 대해서 ERD로 모델링을 해보고, 해당 ERD를 토대로 Django에서 models.py에 코드로 옮겨보자
- 데이터베이스에 넣을 때 스크립트 파일을 작성하여 자동으로 모든 데이터를 저장할 수 있게 해보자
ERD 그리기
이번에 관계형 데이터베이스를 공부하면서 ERD 그림으로 표현하는것이 순탄치는 않았다. 먼저 내가 작성한 ERD는 다음과 같다.

- One To One
영양정보와 음료와의 관계를 1:1으로 지정하였다. 왜냐하면 하나의 음료수에는 해당 음료수에만 유효한 영양 정보들이 저장되어 있기 때문이다. 반대로 영양 정보들도 해당 음료에만 유효할 뿐, 다른 음료에는 그 영양 정보가 유효하지 않는다. 따라서 One to One 으로 지정했다.
- Many To Many
알레르기와 음료를 n:m 관계로 설정했다. 하나의 음료에는 여러가지 알레르기 유발 요인들이 포함되어 있으며, 이 알레르기 유발 요인들은 다른 음료에도 알레르기 유발 요인으로 작용을 하기 때문이다.
- One To Many
위의 두 경우를 제외하고는 모두 1:m 관계로 지정하였다. 근거는 다음과 같다.
- Category - Drink : 하나의 카테고리에는 여러가지의 음료가 포함되어 있지만, 하나의 음료는 하나의 카테고리에만 속한다.
- Drink - Description : Description table은 음료에 하나의 Field로 지정해주어도 되지만 하나의 테이블로 따로 빼서 1:m 관계를 설정한 이유는 하나의 음료에는 서로 다른 두 가지의 상품에 대한 설명이 적혀있기 때문이다. 따라서 하나의 음료에는 여러개의 상품에 대한 설명이 적혀있고, 해당 상품 설명은 해당 음료에만 유효하다.
- Size : Size도 사실 Drink 테이블에 하나의 Field로 적어주어도 된다. 하지만 똑같은 '톨' 이라는 사이즈에 대한 데이터가 여러번 중복되어 데이터에 저장된다. 그래서 생각한 부분이 홈페이지에서 보면 결국 제품 영양 정보 안에 사이즈가 표기되어있다. 따라서 Nutirition table과 Size를 하나의 ForeignKey로 묶고, Nutrition과 Drink를 OneToOne Field로 묶기로 결정했다.
- Thumbnail : 제품의 이미지 정보를 가지고 있는 url을 의미한다. 나중에 이미지의 수정 여부와 같은 확장성을 고려하여 하나의 테이블로 빼서 Drink와 연결시켜주었다. 하나의 음료에는 여러가지의 이미지들이 저장될 수 있지만 해당 이미지는 해당 상품에만 유효한 속성이다. 따라서 One To One 관계로 구성했다.
Crawling
ERD를 그려보았으니 데이터를 크롤링해보자. 스타벅스 페이지는 JS로 표현 된 웹 사이트로써, 단순히 Beautifulsoup으로만은 데이터가 크롤링되지 않는다. 따라서 Selenium과 Beautifulsoup을 섞어서 사용했다. 또한 크롤링 한 데이터를 데이터베이스에 저장하기 위해서 csv 파일형태로 크롤링이 되도록 했다.
CSV
csv_filename = 'Starbucks_Menu.csv'
csv_open = open(csv_filename, 'w+', encoding = 'utf-8')
csv_writer = csv.writer(csv_open)
csv_writer.writerow(('category', 'name', 'description_info1', 'description_info2', 'thumbnail', 'size', 'one_serving_kcal', 'sat_FAT_g', 'protein_g', 'fat_g', 'trans_FAT_g', 'sodium_mg', 'sugars_g', 'caffeine last_mg', 'cholesterol_mg', 'chabo_g', 'allergy'))- 생성 할 csv 파일의 이름을 설정해준다.
- csv_file을 열고, 쓸 수 있는 권한을 부여한다. 인코딩 타입은 utf-8로 한다.
- csv 파일의 column 명을 적어준다.
csv_writer.writerow((category, name, description_info1, description_info2, thumbnail, size, kcal, sat_FAT, protein, fat, trans_FAT, sodium, sugars, caffeine_last, cholesterol, chabo, allergy))실제 크롤링이 된 후 파일에 저장 될 변수 명들을 적어준다. 위의 변수는 내가 크롤링 한 데이터들이 저장되는 변수다.
csv_open.close()파일 저장이 완료 된 후 csv_open 기능을 종료시킨다.
Selenium
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome('/Users/apple/Downloads/chromedriver')
driver.implicitly_wait(5)
driver.get('https://www.starbucks.co.kr/menu/drink_list.do')- ChromeWebDriver 설정을 해준다.
- 5초의 시간을 주어서 조금의 안정 될 시간을 부여한다.
- 크롬 드라이버를 사용하여 정보를 가지고 올 URL을 지정해준다.
driver.close()모든 작업이 완료 된 후 드라이버를 종료시킨다.
BeautifulSoup
html_source = driver.page_source
bs = BeautifulSoup(html_source, 'html.parser')- 크롬 드라이버에서 지원하는
page_source기능을 사용하여 지정한 URL의 source를 가지고 온 후 BeautifulSoup으로 Parsing한다.
Crawling
products = bs.select('.product_list dd a')
prod_cd = [[product['prod'], product.find('img')['alt']] for product in products]
for prod in prod_cd:
cd = prod[0]
name = prod[1]
driver.get('https://www.starbucks.co.kr/menu/drink_view.do?product_cd={prod_cd}'.format(prod_cd = cd))
html_source = driver.page_source
bs = BeautifulSoup(html_source, 'html.parser')
try:
category = bs.select_one('.sub_tit_wrap .sub_tit_inner h2 img')['alt']
except Exception:
pass
description_info1 = bs.select_one('.product_view_detail .myAssignZone p').get_text()
description_info2 = bs.select_one('#container > div.content02 > div.product_view_wrap2').get_text()
thumbnail = bs.select_one('#product_thum_wrap > ul > li > a > img')['src']
size = bs.select_one('#product_info01').get_text()
kcal = bs.select_one('.product_info_content .kcal dd').get_text()
sat_FAT = bs.select_one('.product_info_content .sat_FAT dd').get_text()
protein = bs.select_one('.product_info_content .protein dd').get_text()
fat = bs.select_one('.product_info_content .fat dd').get_text()
trans_FAT = bs.select_one('.product_info_content .fat dd').get_text()
sodium = bs.select_one('.product_info_content .sodium dd').get_text()
sugars = bs.select_one('.product_info_content .sugars dd').get_text()
caffeine_last = bs.select_one('.product_info_content .caffeine dd').get_text()
cholesterol = bs.select_one('.product_info_content .cholesterol dd').get_text()
chabo = bs.select_one('.product_info_content .chabo dd').get_text()
try:
allergys = bs.select_one('.product_factor p').get_text().split(':')[1]
allergy = allergys.split("/")
except Exception:
allergy = None- 처음에 모든 음료들을 어떻게 다 정보들을 가지고 와야할까에 대한 고민이 많았다. 셀레니움을 사용하면 마우스 클릭 이벤트를 사용할 수 있으니 모든 페이지들을 각각 클릭해서 가지고와야할까..? 너무 비효율적이라는 생각이 들어서 다른 쪽으로 생각을 해봤다. 그리고 얻은 결론은 url에 있었다. 각 음료마다 가지고 있는 고유의번호값이 있었다. 개발자 도구에서 이 부분을 확인할 수 있었다. 그래서 이 고유 번호만 추출해서 반복문을 이용해서 다음의 음료로 이동하겠다고 생각했다.
- 그 이후엔 내가 추출하고자 하는 tag나 selector들의 경로를 분석해서
select_one을 사용해서 해당 정보만 가지고 올 수 있게 구성하였다. - 중간중간 예외처리를 해주었는데, 중간중간 몇개의 음료에 내가 추출하고자 하는 부분이 비어있는 경우가 있었다. 이럴 경우 예외처리를 사용하여 내가 얻고자 하는 정보만을 담았다.
- 알레르기 부분은 추후 csv 파일에 저장할 때 list 형태로 iterable하게 넣기 위해서 최대한 크롤링 할 때부터 split하여 원하는 형태의 데이터를 얻고자 하였다.
models
데이터를 모두 크롤링했다면 이제 ERD를 토대로 어떤식으로 모델을 구성할지 직접 코드를 구현해야한다.
ERD에 그린대로 하나의 테이블을 하나의 클래스로 만든다.
이미 ERD를 그릴 때 모두 설명했기 때문에 자세한 설명은 생략한다. ERD를 기반으로하여 각 클래스를 지정해주고 관계를 고려하여 필요에 맞는 Field들을 설정해주면 된다.
모델을 생성했기 때문에 migration 작업을 반드시 진행해주어야한다.
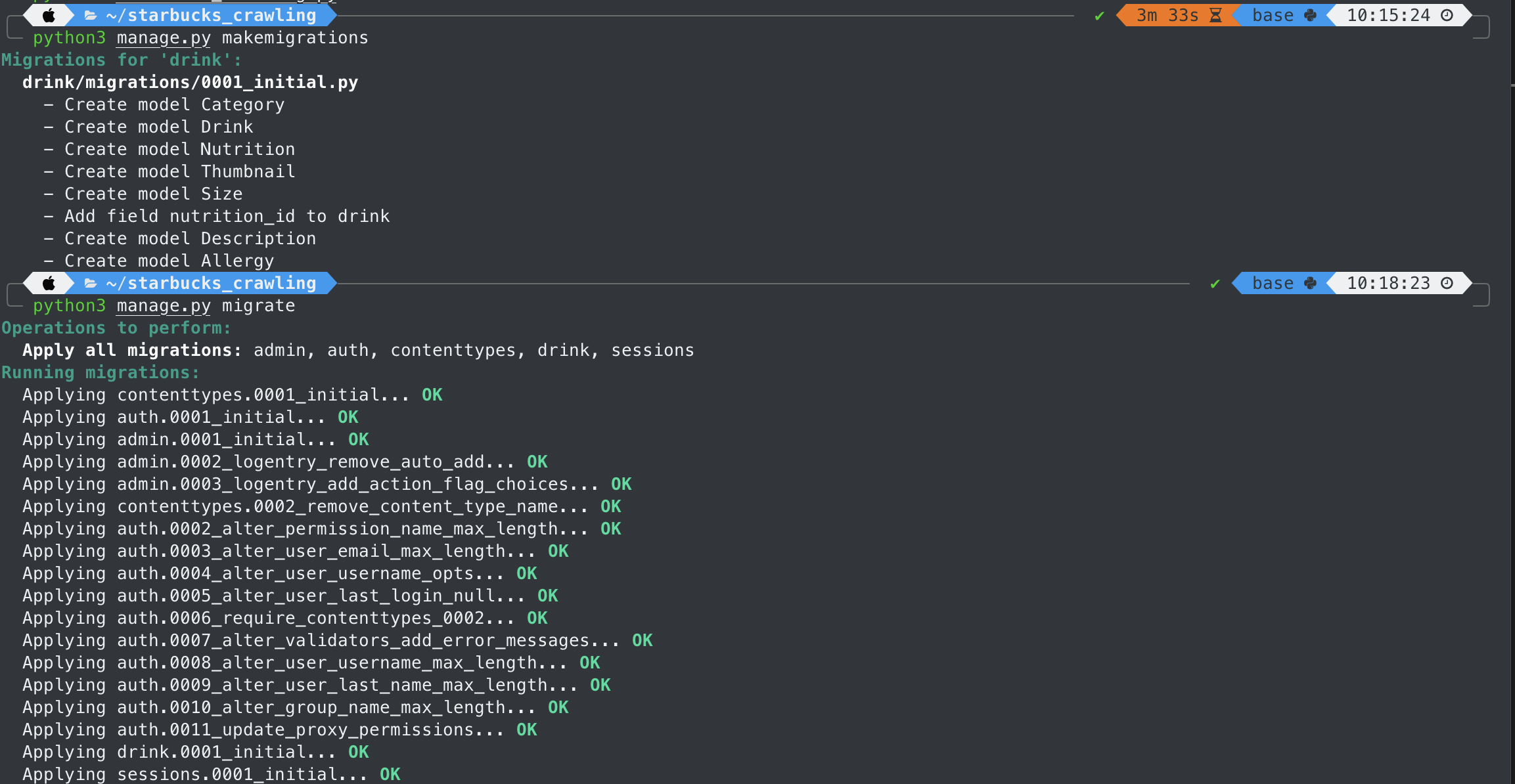
makemigrations? migrate?
- makemigrations는 실제 데이터가 저장되는 명령어가 아니다. Django와 DataBase 사이에서 해당 데이터들을 저장할거라는
인식을 시켜주는 작업이다. 이 단계에서는 저장이 되는것이 아닌것에 유의하자.- migrate 명령어를 수행함으로써 실제로 데이터베이스에 값이 저장된다
db_script
db에 넣을 pythion file 하나를 생성해주고, csv 파일을 연동시키기 위하여 초기 세팅을 해준다.
import os, django, csv, sys
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'starbucks.settings')
django.setup()
from drink.models import *
CSV_PATH_PRODUCTS = './Starbucks_Menu.csv'우선 가장 처음인 카테고리부터 db에 넣어 보자.
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
category_name = row[0]
Category.objects.create(name = category_name)category_name에 어떤 로우의 값이 저장될 것인지에 대한 설정을 해준다. 그리고 Category Table을 create 하면서 값을 저장한다.
- 결과 확인
생성한 스크립트 파일을 실행시켜준다.

결과 확인 시 카테고리 데이터가 잘 들어간 것을 확인할 수 있다. 이제 데이터베이스에 넣을 로직을 위와 같은 느낌으로 계속 작성해주면 된다.
get_or_create
get 메소드를 사용하여 데이터를 저장하려고 하면 아마 중복되는 값으로 인해서 굉장히 잦은 오류를 경험할 것이다. 이 때 유용하게 사용 될 수 있는 메소드가 get_or_create 메소드이다.
이 메소드는 데이터베이스에 값을 저장할 때 이미 값이 존재한다면 기존에 저장되어 있던 값을 가지고 와서 사용하고, 기존에 데이터베이스에 저장된 값이 없다면 그 때 생성한다. 따라서 굉장히 유용한 메소드이다.
유용하다고 막 사용하면 안된다. 내가 테이블에 값을 저장할 때, 중복되는 값이 들어가도 되는지 안되는지에 대한 생각을 하고 사용해야한다. 예를 들어, 나는 Category의 경우 데이터가 중복되면 불필요하게 메모리를 너무 많이 사용하기 때문에 데이터의 중복을 막기위해 해당 메소드를 사용했다.
그에 반해 영양 정보에 대한 값을 저장해줄 땐 단순히 get(), create()를 사용했는데, 두 음료의 영양 정보가 같을 수도 있기 때문에 이런 경우에는 중복된 값이더라도 계속 저장해주어야 하기 때문에 get_or_create 메소드를 사용하지 않았다.
해당 메소드에 대한 자세한 정보는 다음에서 확인할 수 있다.
QuerySet API reference | Django documentation | Django
항상 많은 생각을 해보고 필요한 경우 적재적소에 맞게 사용하는 습관을 기르도록 하자.
어려웠던 점
- ERD 그리기. 관계형 데이터 베이스에 대한 개념은 이해가 가는데 막상 그림으로 표현하는것은 개념의 이해와는 다른 문제였다. 충분히 많은 생각이 필요하고 엑셀로 직접 표로 그려도 보고 문장으로 적어서 논리적으로 문제가 없는지 등 여러 경우를 모두 판단해야했다.
- 스타벅스 크롤링 시 각 음료 페이지들을 어떻게 이동시켜줘야할지 처음에는 감이 잡히지 않았다. 좋은 답을 얻기 위해서는 많은 분석이 필요하고 그 분석은 결국 개발자 도구에서 이루어진다. 데이터를 크롤링 할 때 항상 개발자도구에서 많은 부분을 분석해서 가장 최선의 방법을 찾도록 노력하자.
- 크롤링 할 때 데이터가 나왔다고 그저 좋아할것이 아니라 크롤링 할 때 부터 최대한 활용할 수 있는 형태로 크롤링 할 수 있도록 하자. 따라서 적절히 가공하기 위해 split을 어떻게 하면 좋을지에 대한 생각과 정규표현식에 대해서 공부를 해야했고 앞으로도 해야할 부분이다.
- models.py에 지정한 순서대로 웬만하면 데이터를 집어넣자. models.py에서 순서대로 로직을 실행하는데 데이터베이스에서 테이블에 데이터를 넣는 단계에서 순서가 models.py와 일치하지 않으면 아직 정의되지 않은 Table을 참조하려고 하는 경우 에러가 발생하기 때문이다. 이걸 이해하는데 시간이 꽤 걸렸다.
- ManyToManyField를 사용하면 Django에서는 중간 테이블을 알아서 생성해준다. 그래서 중간 테이블을 modles.py에 따로 만들지 않았다. 그런데 알아서 생성해주는 중간 테이블에서 막상 ForeignKey를 연결시켜주는것이 쉽지 않았다. 알레르기를 manytomany field와 get_or_create를 사용해서 데이터를 저장하려는데 자꾸
AttributeError:'tuple' objects has no attribute 'drink_id'와 같은 에러가 발생했다. 알고보니 get_or_create는 내가 저장하고자 하는 변수 외에도 boolean값을 입력해주어야했으며, 반환값이 Tuple 형태였다는 것이다. 어느 부분에서 Tuple로 반환이 되길래 저런 에러가 발생하는지 검색을 해도 알 수가 없었는데 답은 역시 공식문서에 있었다. - ManyToManyField에서 get_or_create() 를 사용할 경우, 데이터를 저장해주고
addorset메소드를 실행시켜주자. 주의할 점은 get_or_create만 한 상태로 스크립트 파일을 한번 실행시켜주고 그 후에addorset을 사용하자. 한번에 사용할 경우 정상적으로 동작되지 않는다.
벨로그에서는 토글을 지원하지 않아 코드 전문을 올리기에는 글의 요지보다는 글의 길이만 너무 길어질 것 같아 올려놓지는 않았습니다. 다음의 링크에서 토글을 열면 코드 전문을 확인할 수 있습니다.
노션 - 스타벅스 크롤링
