
머신러닝(유사도분석)
데이터 간의 유사도 측정하기
어떤 기준으로 각 데이터 간의 유사도를 측정할 것인가를 결정하는 것은 머신러닝, 특히나 군집화 알고리즘 등에서도 중요한 사항이다.
예를들어 자연어 처리에서는 문서의 유사도를 구하여 각 문서간의 주제 유사도를 판별하기도 한다.
이번 포스팅에서는 벡터를 비롯한 데이터에 대하여 각 정보 간의 유사도를 판별하는 기법에 대해 알아보자
코사인 유사도
코사인 유사도는 두 벡터 간의 각도를 기반하여 구할 수 있는 값이다. 두 벡터의 각도, 즉 방향이 완전히 일치하다면 1을 반환하게되며, 수직일 경우 0, 완전 정반대 일경우 -1를 반환하게 된다.

from numpy import dot
from numpy.linalg import norm
import numpy as np
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
vec1=np.array([0,1,1,1])
vec2=np.array([1,0,1,1])
cos_sim(doc1, doc2) //0.67유클리드 거리
유클리드 거리는 다차원 공간에서의 점과 점 사이의 거리를 구하는 공식이다. 공식 자체는 피타고라스 정리에서 삼각형의 빗면을 구하는 방식과 똑같다.

import numpy as np
def dist(x,y):
return np.sqrt(np.sum((x-y)**2))
vec1 = np.array((2,3,0,1))
vec2 = np.array((1,1,0,1))
dist(vec1,vec2) // 2.23606797...
자카드 유사도
자카드 유사도는 각 집합에 대하여 얼마나 같은 원소를 포함하고 있는가를 구하는 기법이다. 자카드 유사도는 0과1사이의 값을 가지며, 두 집합이 동일하다면 1의 값을 가지고, 공통 부분이 없다면 0의 값을 가지게 된다.
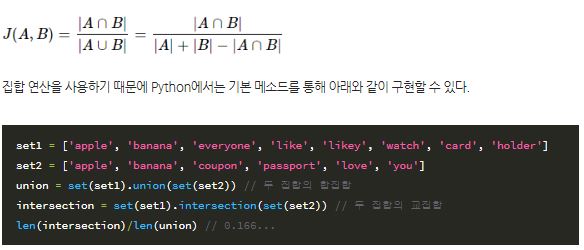
set1 = ['apple', 'banana', 'everyone', 'like', 'likey', 'watch', 'card', 'holder']
set2 = ['apple', 'banana', 'coupon', 'passport', 'love', 'you']
union = set(set1).union(set(set2)) // 두 집합의 합집합
intersection = set(set1).intersection(set(set2)) // 두 집합의 교집합
len(intersection)/len(union) // 0.166...
맨허튼 거리
맨허튼 거리는 유클리드와 마찬가지로 좌표상의 거리를 표현하지만 해당 거리 차이를 절대값의 차이로 계산하는 기법이다.
수학식으로 나타내면 다음과 같다.

import numpy as np
def dist(x,y):
return np.sum(np.absolute(x-y))
dist(np.array([1,2,3]),np.array([1,2,5])) // 2
