최근 3D 콘텐츠 생성 분야에서 최적화 기반의 3D 생성 기법은 점수 증류 샘플링(Score Distillation Sampling, SDS)을 활용하여 주목할 만한 성과를 보였지만, 샘플당 최적화 시간이 길어 실용성에 한계가 있었습니다.
이러한 문제를 해결하기 위해 Tang 등(2024)은 ICLR 2024에서 "DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation"이라는 논문을 통해 효율성과 품질을 동시에 달성하는 새로운 3D 콘텐츠 생성 프레임워크를 제안하였습니다. (arxiv.org)
1. Introduction
기존 접근법의 한계
기존의 3D 콘텐츠 생성 기법은 크게 두 가지로 분류됩니다:
-
추론 기반 3D 네이티브 방법(Inference-only 3D native method): 대규모 3D 데이터셋을 활용하여 모델을 학습시키는 방식으로, 빠른 생성이 가능하지만 데이터 수집의 어려움과 생성된 모델의 다양성 및 현실감에서 한계가 있습니다.
-
최적화 기반 2D 리프팅 방법(Optimization-based 2D lifting method): 2D 확산 모델을 사용하여 3D 모델을 최적화하는 방식으로, 현실감 있고 다양한 모델을 생성할 수 있지만, 생성 시간에 많은 시간이 소요됩니다.
이러한 한계를 극복하기 위해, 본 논문에서는 3D Gaussian Splatting 기법을 생성적 설정에 적용하여 효율적이고 고품질의 3D 콘텐츠 생성을 목표로 합니다.
3D Gaussian Splatting의 개념
3D Gaussian Splatting은 3D 공간에서 가우시안 분포를 사용하여 물체를 표현하는 기법으로, 각 가우시안은 위치, 크기, 색상 등의 속성을 가집니다. 이러한 가우시안들의 집합을 통해 3D 물체를 표현하고, 이를 2D 이미지로 렌더링할 수 있습니다. 기존의 Neural Radiance Fields(NeRF)와 달리, 가우시안의 점진적 밀도 증가를 통해 빠른 수렴을 보이며, 이는 3D 생성 작업에서 효율성을 높입니다.
3D Gaussian Splatting 논문을 다룬 자세한 글은 이 글을 참고해주시면 감사하겠습니다.
2. Overview
2D lifting 방법은 NeRF모델에 SDS Loss를 적용하게 되는데, NeRF의 랜더링 방식 때문에 optimization 시간이 상당히 오래 소요됩니다. 논문 저자는 속도를 개선하기 위해 occupancy pruning을 적용해 보았지만, SDS Loss로 모델을 학습시킬 때 효과적이지 못했다고 합니다. 때문에 NeRF대신에 pruning이 필요없는 이미지 퀄리티가 좋고 빠른 학습 속도를 가진 3D Gaussain Splatting을 적용 해보았다고 합니다. 단순히 3D Gaussian을 적용하였을 땐 결과물이 blurry하였기 때문에 추가적인 기법이 적용됬습니다.
(SDS Loss는 아래에서 설명하겠습니다)
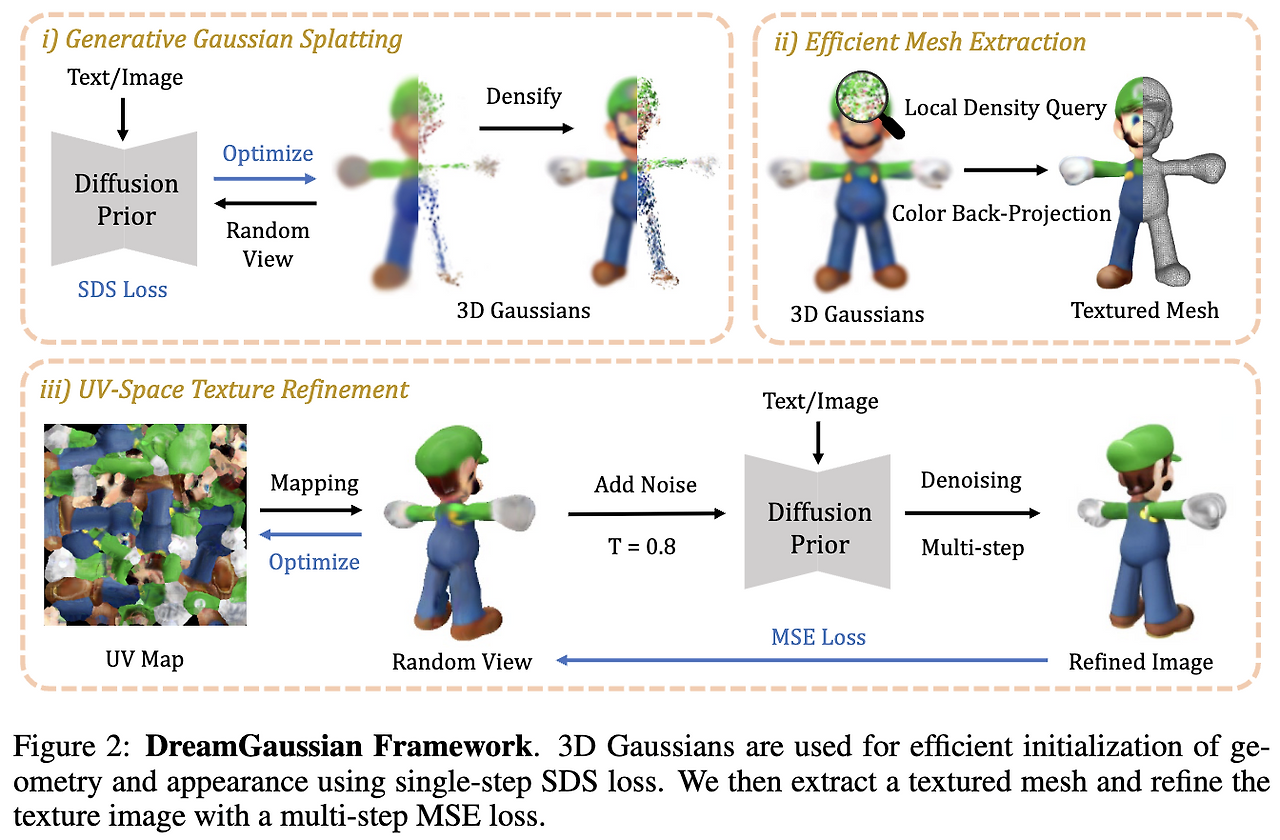
알고리즘은 총 3가지 단계로 구성됩니다.
-
Text/Image를 입력받아 SDS Loss로 3D Gaussian Splatting을 구성
-
3D Gaussian에서 Textured Mesh를 생성
-
UV Texture Map을 정제
3. Method
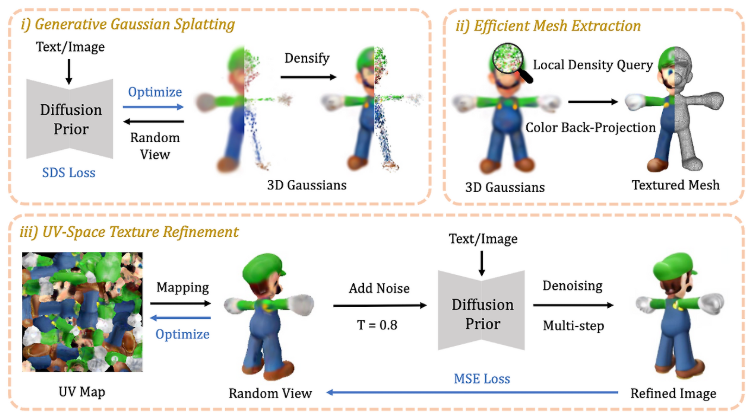
Generative 3D Gaussian Splatting
원래 3D Gaussian Splatting은 3D reconstruction을 위한 모델이다. 본 논문은 3D Generation task에서 이 모델을 이용하려고 합니다.
3D Gaussian의 parameter는 {x,s,q,α,c}로 x는 중심 좌표, s는 scaling factor, q는 rotation quaternion, α는 opacity, c는 color(SH를 사용하지 않음)를 나타냅니다. Optimizable 파라미터는 Θ로 나타내고 i번째 가우시안의 파라미터는 {}이다. 3D Gaussian들을 2D Gaussian들로 project시키고 이를 통해 volumetric rendering을 수행해 최종 color과 alpha의 추정값을 구합니다. 기존 3D Gaussian Splatting 방식을 이용해 Θ를 최적화합니다.
논문에서는 구 내에서 random 위치에서 샘플링된 unit scaling과 no ratation을 가진 3D Gaussian으로 초기화합니다. 3D Gaussian들은 optimization을 통해 점진적으로 desification됩니다. 기존 3D gaussian splatting과 다른 점은 더 적은 Gaussian들로 시작해서 더 자주 densification을 진행한다. 각 스텝마다 random camera pose p를 샘플링해서 RGB image 와 transparency 를 렌더링합니다. 학습동안 linear하게 t를 줄인다고 합니다. 그리고 나서 다른 2D diffusion prior ϕ가 사용됩니다
Image-to-3D를 기준으로 학습과정을 정리하면,
-
입력 이미지의 배경을 제거하고 사물을 가운데 위치시킵니다.
-
우선 구형 공간안에 랜덤 position 값으로 5000개의 3D Gaussian을 초기화합니다.
-
각 step에서 물체를 중심으로 반지름이 2(or 2.5)인 반구의 표면에 랜덤으로 camera pose(=view)를 지정(샘플링)합니다.
-
Text 또는 이미지를 입력으로 받아, SDS Loss를 사용해 3D Gaussian들의 위치, 크기, 회전정도, 투명도, 색상을 업데이트합니다. 3D Gaussian Splatting과 다른 부분은 color를 계산시에 SH function을 사용하지 않고, RGB 3개의 실수값으로 정의합니다. DreamGaussian에서는 각도에 따라 사물이 다른 색상을 랜더링하도록 모델링하지 않기 때문입니다.
-
100 step마다 Gaussian Clone/split하는 Densification과정을 수행합니다.
-
RGB 이미지와 transparency이미지를 랜더링합니다. 이 때 배경은 랜덤으로 흰색 또는 검정색으로 랜더링합니다.
-
랜더링 되는 이미지 해상도를 64에서 512까지 증가시키며 총 500step을 진행합니다.
Image-to-3D Loss
Image-to-3D task에서 이미지 와 foreground mask 가 input으로 주어지고 Zero-1-to-3 XL이 2D diffusion prior로 적용됩니다. SDS Loss는 다음과 같이 계산됩니다.
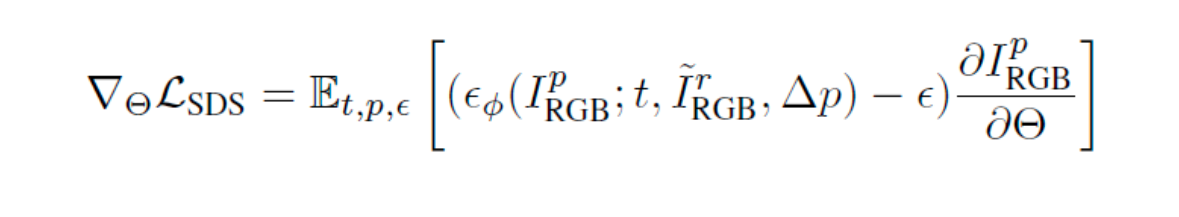
- t는 time, p는 카메라 pose, ϵ는 가우시안 분포,
- ϵΦ는 2D Diffusion prior의 U-net,
- I_p_RGB는 Gaussian Splatting으로 그려진 이미지,
- ~I_r_RGB은 입력 이미지,
- Θ는 Gaussian Splatting의 학습 parameter입니다.
추가로 reference view image 와 transparency 를 input에 align하도록 다음과 같이 최적화합니다.
다시말해 입력 이미지(=reference view image)와 최종 랜더링된 이미지간의 MSE값 + 입력 이미지에 대한 transparency(=background mask 추정)와 최종 합성 이미지에 대한 transparency 값이 상수 비율만큼 곱해져서 Loss로 사용됩니다.
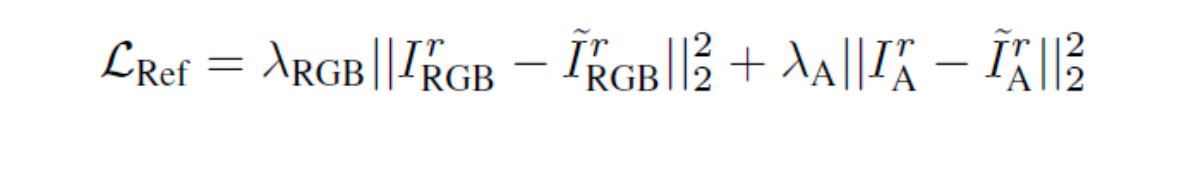
Text-to-3D Loss
Text-to-3D에서는 text만 input으로 사용되고 StableDiffusion이 사용된다. SDS Loss는 다음과 같이 계산된다.
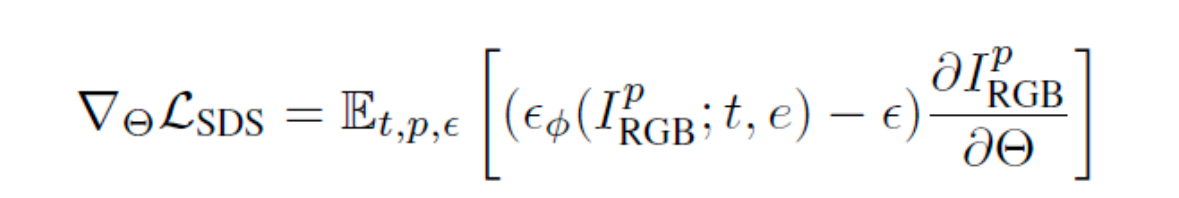
위와 다른 점은 e인데, 이는 text를 latent vector로 임베딩(embedding)하는 모델인 CLIP에 해당합니다. U-net은 text에 해당하는 이미지를 생성 할 수 있게끔 3D Gaussian의 parameter를 업데이트합니다.
이렇게 3D Gaussian Splatting 으로만 모델링 할 경우, 상당히 blurry한 것을 볼 수 있습니다. 각 optimization step이 inconsistent 3D guidance를 제공하기 때문에, under-reconstruction 지역을 정확하게 densification하거나 over-reconstruction을 pruning하는 것에 어려움을 겪습니다. 그래서 이러한 관측을 통해 mesh extraction과 texture refinement 디자인을 도입하게 됩니다.
Efficient Mesh Extraction
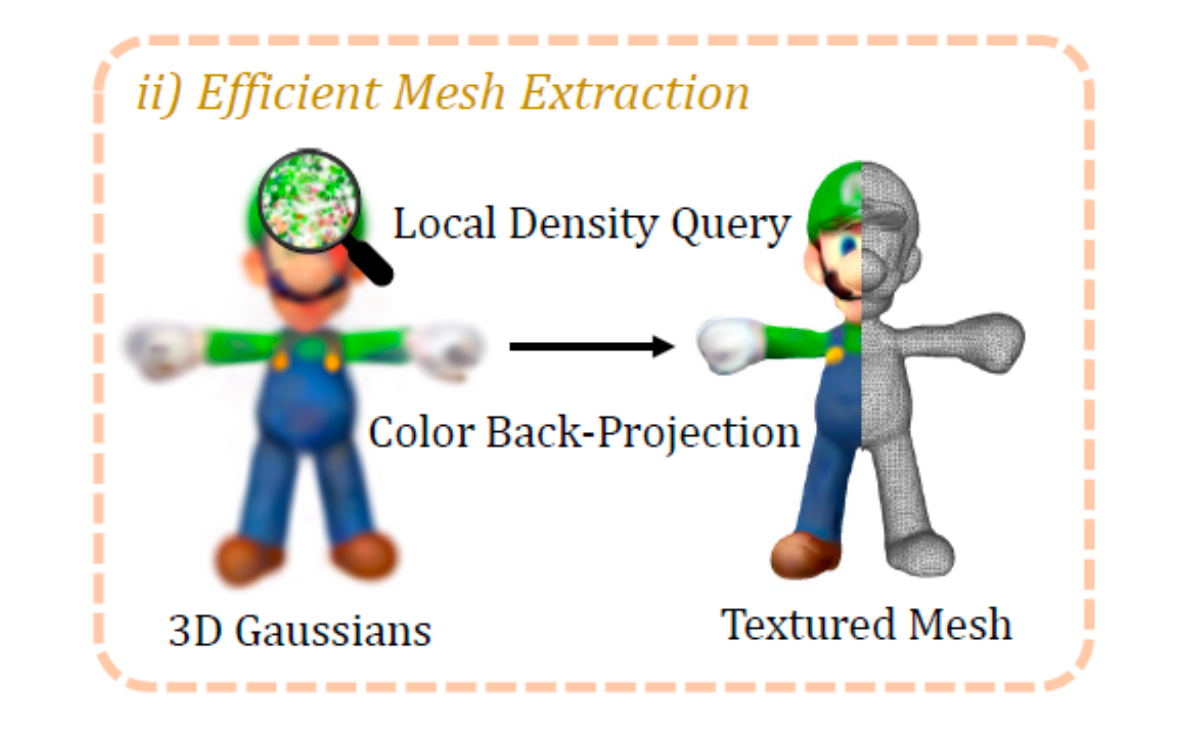
3D Gaussian들을 mesh로 변환한 최초의 시도라고 표현하고 있습니다. 3D Gaussian Splatting 논문에선 이미지 plane으로 projection하는 것은 소개되었지만, 3D mesh로 projection은 언급되어있지 않습니다. Local Density Query와 Color Back-projection 기법을 통해 Mesh Extraction하는 방법을 소개하고 있습니다.
Local Density Query
의 3D 공간을 의 overlapping block들로 나눕니다. 그러고 나서 각 block에 중심이 속하지 않는 Gaussian들은 culling합니다. 그렇게 함으로써 특정 block에 대해 계산할 때 그 block에 속한 Gaussian에 대해서만 계산하게 해서 효율적으로 만듭니다. Grid position 에서 각 query에 대해, 남은 3D Gaussian의 opacity를 weighted sum으로 표현할 수 있습니다.
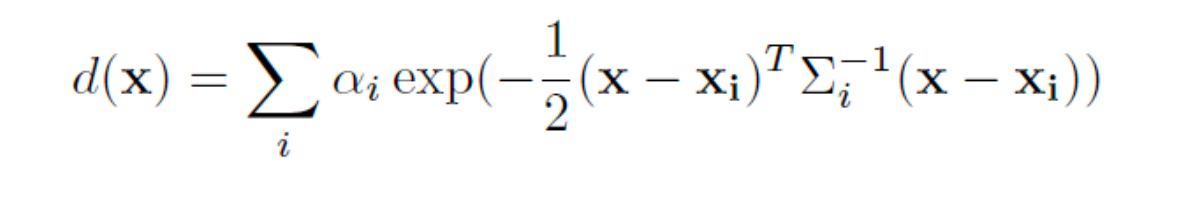
여기서 는 scailing 와 rotation 으로부터 만들어진 covariance matrix입니다. 이 후 Marching cube 알고리즘에 따라 각 grid의 8개의 모서리의 opacity가 임의의 thresould를 넘을 경우 True로 판정하고, 미리 정의된 256개 경우의 수 중 한가지의 polygon형태로 변환합니다. 이 128^3개의 grid를 모두 합치면 하나의 mesh로 생성되게 됩니다.
Color Back-projection
Local Density Query 과정에서 mesh geometry를 얻었기 때문에, rendered RGB image를 mesh surface로 back-project할 수 있고 texture로 bake할 수 있습니다. 처음에는 3D mesh를 2D UV coordinate들을 unwrap하고 빈 texture image로 초기화합니다. 대응되는 RGB image를 렌더링하기 위해 8개의 azimuth()와 3개의 elevation($)와 위 아래 view를 uniform하게 선택합니다. RGB image들로부터 각 픽셀은 UV coordinate에 기초한 texture image에 back-project 될 수 있고, 여기서 mesh boundary에서 unstable projection을 피하기 위해서 카메라의 z축과 표면의 법선 벡터의 각이 작은 픽셀들은 배제한다고 합니다. 이렇게 back-projected texture image는 다음 스테이지에서 initialization으로 주어집니다. 기존 3D Gaussian Splatting에서는 Image Plane으로 Projection하게 되는데, 여기선 triangle으로 projection한다고 생각하면 좋을 것 같습니다.
이렇게 생성된 texture image는 다음단계에서 fine-tuning되어 집니다.
UV-Space Texture Refinement
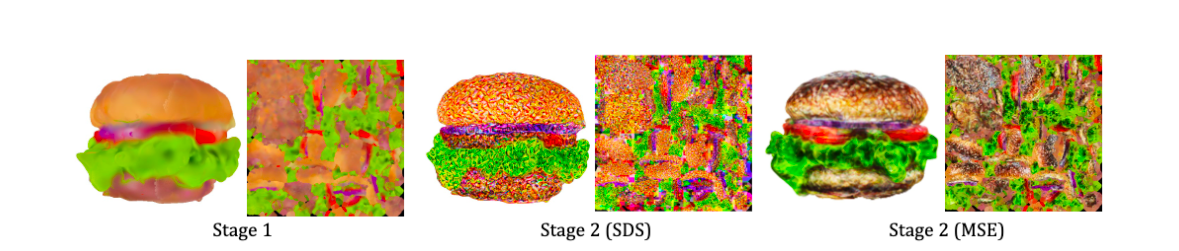
이 단계에서는 앞선 coarse texture를 refine합니다. 그 과정에서 SDS Loss를 바로 사용하면 위 그림처럼 artifacts가 발생합니다. 이는 rasterize할 때 mipmap(여러 해상도의 이미지들) texture sampling 기법 때문이라고 합니다. mipmap(서로 다른 해상도의 이미지들)으로 전파되는 graident들이 과도한 채도(saturation) block들을 만들기 때문입니다. 그래서 blurry한 texture를 fine-tune하기 위한 방법을 제시하고 있습니다.
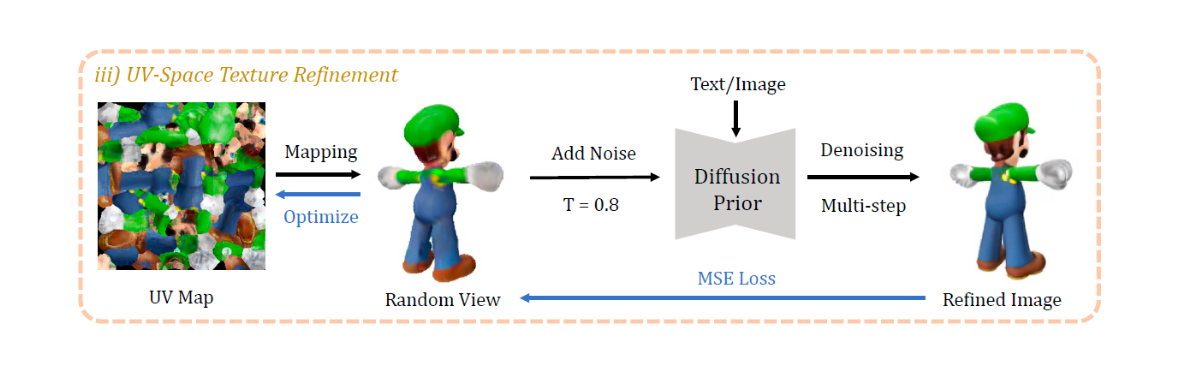
초기화된 texture를 가지고 있기에 앞단계에서 만들어진 textured mesh 모델을 토대로, 임의의 camera pose에서 blurry한 이미지를 만듭니다. 이 blurry한 이미지를 2D diffusion prior(=stable diffusion)의 denoising process에 통과시켜 정제된 이미지를 생성합니다.

다음은 refine된 이미지를 만드는 수식입니다.
여기서 는 에서 random noise이고, 는 image-to-3D에서는 이고 text-to-3D에서는 입니다. 시작 timestep 는 noise strength를 제한하기 위해 조심스럽게 선택된다고 합니다. 그 결과 original content를 파괴하지 않으면서 detail들을 강화할 수 있다고 합니다.
이 후 Pixel-wise MSE Loss를 사용해서 texture를 최적화합니다.
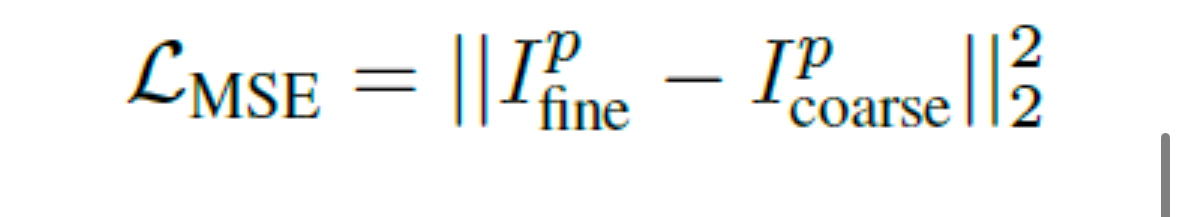
정리하자면, coarse한 이미지를 2D diffusion prior의 denoising process를 통해 refine한 이미지로 생성하고, refined된 이미지로 만들 수 있도록 Textured Mesh의 UV Map을 pixel단위로 업데이트 하는 것이러고 할 수 있겠습니다.
4. Experiments
Qualitative Camparisons

Image-to-3D의 경우
optimization기반 방법(Zero-1-to-3)과 inference-only 방법(One-2-3-45, Shape-E)을 구분했을 때, DreamGaussian은 3D geometry fidelity관점, visual apperance 관점에서 가장 좋은 성능을 가집니다. optimization기반 방법보다는 빠르지만 inference-only 방법보다는 느립니다.

Text-to-3D의 경우
Optimization기반 방법을 적용한 DreamFusion과 비교 했을 때, DreamGaussian은 학습 속도가 10배 이상 개선되었고 퀄리티도 개선되었습니다.
Quantitative Comparision

CLIP similarity(다양한 view에서 얼마나 일관성을 가지는지를 판단)와 generation 속도를 정량적으로 비교하는 실험을 진행되었는데, DreamGaussian이 높은 수치를 가지는 것을 확인할 수 있습니다.
Ablation Study
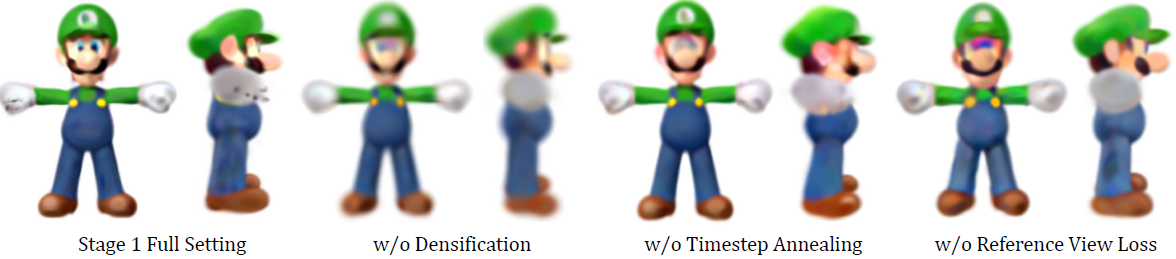
- 3D Gaussian Splatting의 Densification과정이 없을 경우
- SDS loss계산시 Timestep Annealing이 없을 경우
- refine이미지를 생성에 사용된 reference view Loss L_Ref가 없을 경우
이 3가지 경우에 대하여 시각적으로 평가하였습니다. 한가지라도 빠졌을 경우 블러리한 결과를 만드는 것을 알 수 있습니다.
5. Limitations and Conclusion

이전의 Text-to-3D 연구와 동일하게, Janus 문제(야누스 문제: 얼굴이 여러개 생기는 현상)과 baked lighting(빛이 Texture에 포함되는 현상)이 발생했습니다. 최신 multi-view 2D diffusion model연구들과 latent BRDF auto-encoder연구들을 통해 학습을 더 길게 하면 완화될 수 있다고 합니다.
마지막으로
3D Gaussian으로 Mesh를 만드는 방법이랑, Texture Map을 만드는 것이 매우 신기하였다. 3D Gaussian splatting을 공부한 후 다루는 첫 논문인데, 아직 NeRF, Diffusion Mode에 대한 나의 이해가 완벽하지 않다는 느낌이 들었다. 가능하다면 위 논문들에 대해서도 리뷰 해볼 예정이다.
