하둡을 설명하는 4가지 키워드는 다음과 같다.
- 빅데이터
- 분산 컴퓨팅
- 저장
- 분석
그 전에 하둡이라는 이름은 개발자네 아들이 갖고 놀던 노란색 코끼리 인형에게서 왔다고 한다.
 흠..
흠..
빅데이터
- 한 대의 컴퓨터로는 저장하거나 연산하기 어려운 규모의 데이터
분산
- 여러 대의 컴퓨터로 나눠서(병렬로 묶어서) 일을 처리함
저장
- 큰 규모의 파일을 어떻게 저장할 것인가?
- 하둡은 분산되어 있는 여러 대의 컴퓨터에 파일을 쪼개서 저장한다
- 같은 내용을 중복해서 저장한다 (다중 복제), 파일을 쉽고 빠르게 복구 가능
분석
- 여러 대의 컴퓨터에게 일괄 명령 (연산)을 내리면, 독립적인 컴퓨터들이 갖고 있는 데이터를 연산해서 분석된 결과를 하나로 모아서 전달
즉 하둡은, 빅데이터의 저장과 분석을 위한 분산 컴퓨팅 솔루션이다.
하둡은 크게 2가지 구성 요소가 있다.
- HDFS (하둡 분산 파일 시스템)
- Map & Reduce
HDFS
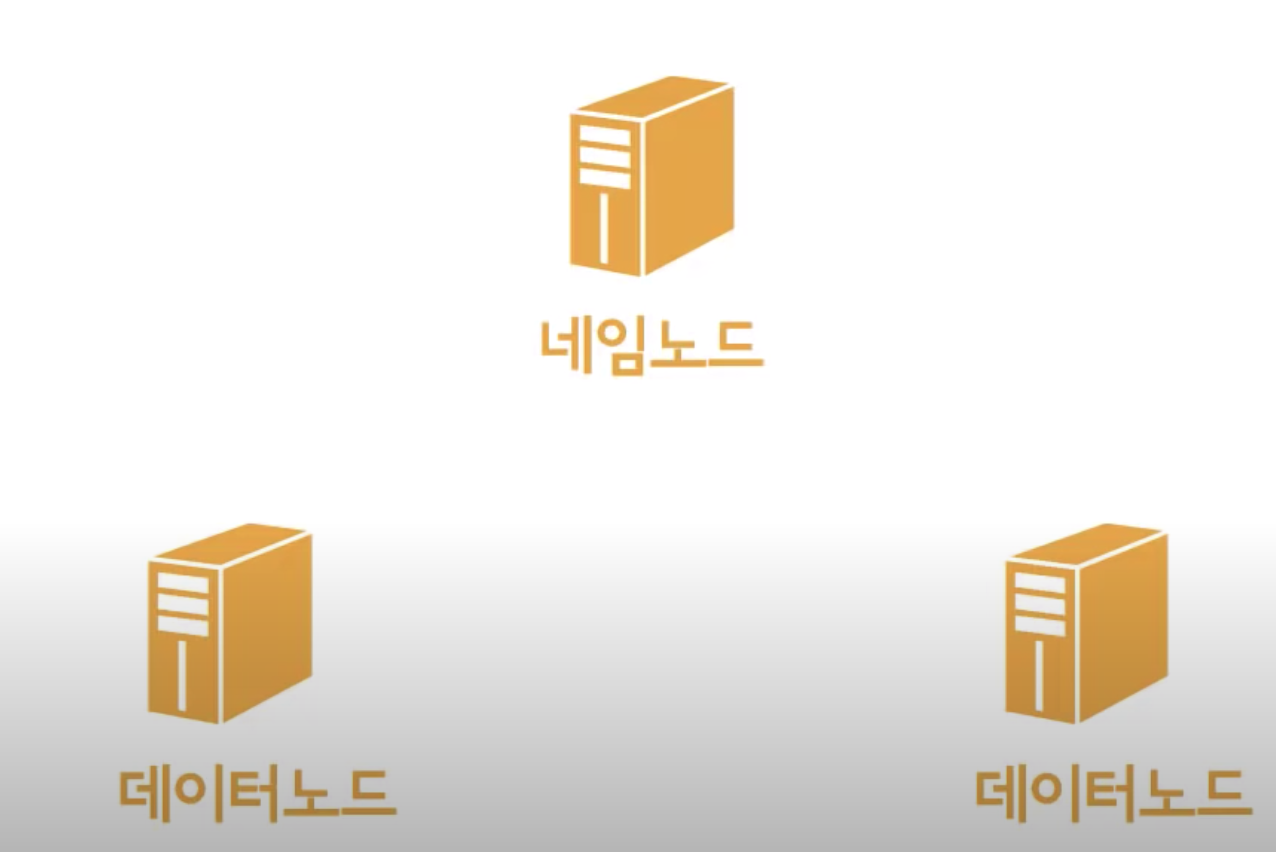
- 대용량 파일을 분산된 서버에 저장하고, 그 저장된 데이터를 빠르게 처리할 수 있게 하는 시스템
- 그림에 있듯이 3개의 컴퓨터가 있다고 해보자.
💡
특정한 기능 수행을 위해 여러 컴퓨터가 네트워크로 연결된 것을 클러스터 라하고, 이 때 클러스터를 구성하는 개별 컴퓨터를 노드라고 한다. 네임 노드
- 대용량 파일을 쪼개주는 역할 (한 대)
- 쪼개진 파일이 어느 데이터 노드에 있는지 알려주는 META DATA
- 파일 이름, 권한 등의 속성 기록
데이터 노드
- 쪼개진 형태로 데이터를 보관하고 있는 각각의 컴퓨터
- 일정한 크기로 나눈 블록 형태로 저장
- 하나의 블록은 3개로 복제되며, 각각 다른 HDFS의 노드에 분산 저장됨
- 하둡 파일 시스템을 제어할 때는
hadoop fs명령어를 쓴다.
특징
- 범용 하드웨어 기반, 클러스터에서 실행되고 데이터 접근 패턴을 스트리밍 방식으로 지원한다.
- 스트리밍 방식?
- 하둡은 자바 기반 프레임 워크이지만, php, python, shell/bash script 등으로도 하둡을 제어할 수 있음
- 자동 복구, 온라인 변경, 범용서버 기반, 다중 복제
- 데이터 수정은 불가능 하지만 파일이동, 삭제, 복사할 수 있는 인터페이스를 제공함.
워크 플로우
- 어플리케이션에서 HDFS 클라이언트에 요청
- HDFS 클라이언트는 네임 노드에 요청 전달
- 파일 저장의 경우 파일 블록들이 저장될 경로 생성을 요청
- 네임 노드는 클라이언트에게 해당 파일 블록들을 저장할 데이터 노드의 목록 반환
- 파일 저장의 경우 파일 블록들이 저장될 경로 생성을 요청
- 네임 노드는 메타 데이터를 통해 파일이 저장된 블록 리스트를 반환
- 파일 저장의 경우, 클라이어느는 첫번째 데이터 노드에게 데이터를 전송한 후 첫번째는 두번째에게, 두번째는 세번째에게 저장 후 전달..
- 클라이언트를 어플리케이션에 데이터 전달/응답 전달
Map Reduce
- 분산 데이터 처리를 위한 소프트웨어 프레임 워크 (분산 프로그래밍 모델)
- 대량의 데이터를 병렬로 분석 가능
Map
- 모든 데이터를 <key, value> 형태로 분류하는 작업
- ex) word count 에서 <dog, 2> <cat, 4> 처럼..
Reduce
- Map에서 출력된 데이터의 중복 데이터 제거, 원하는 데이터 추출
프로세스
input -> split -> map -> shuffle -> reduce -> output
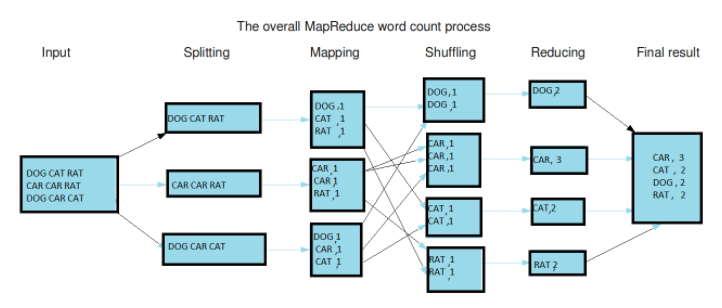
wordcount의 경우..
- split : 문자열 데이터를 라인별로 나눔
- map : 라인별 문자열 입력 받아 <key, value> 형태로 출력
- shuffle : 같은 key를 갖는 데이터끼리 분류
- reduce : 각 key 별로 빈도수 합산 후 출력
- output : reduce 메소드의 출력 데이터를 합쳐서 HDFS에 저장
분명 이거 정리할 때는 나 그 뒤의 하둡 에코 시스템 때문에 정리 시작한 거 같았는데..
확실히 프로그램을 돌려서 직접 분석 해보지 않고 이론으로만 이런 프로그램이 있다 저런 프로그램이 있다 공부하려니까 외워지지 않는 것 같다
그것도 계속 반복되는 분산, 처리, 대용량, 플랫폼.. 다 똑같은 프로그램인데 이름만 달라지는 거 같아..

그게 쉬운 일이었다면, 아무런 즐거움도 얻을 수 없었을 것이다.