
# Intro
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ목표하던 바를 끝냈다.하하하하..구현하는 것보다 정리하는 것이 더 어려운 이유는 뭐지??
블로그 쓰는데만 반나절이 넘어가는 이유는 뭐지???
블로그 쓸때 집중력이 너무 구리다...구리구리...
그냥 개발만 하면 얼매나 조을까요....😩😩😩
오늘은 그동안 배웠던 자료구조가 어디에 쓰이는지도 정리해 보자!
1. Tree
1. Tree가 무엇?
- 부모와 자식관계를 가지는 노드로 이루어진 자료구조
- Graph의 일종
2. Tree의 구조
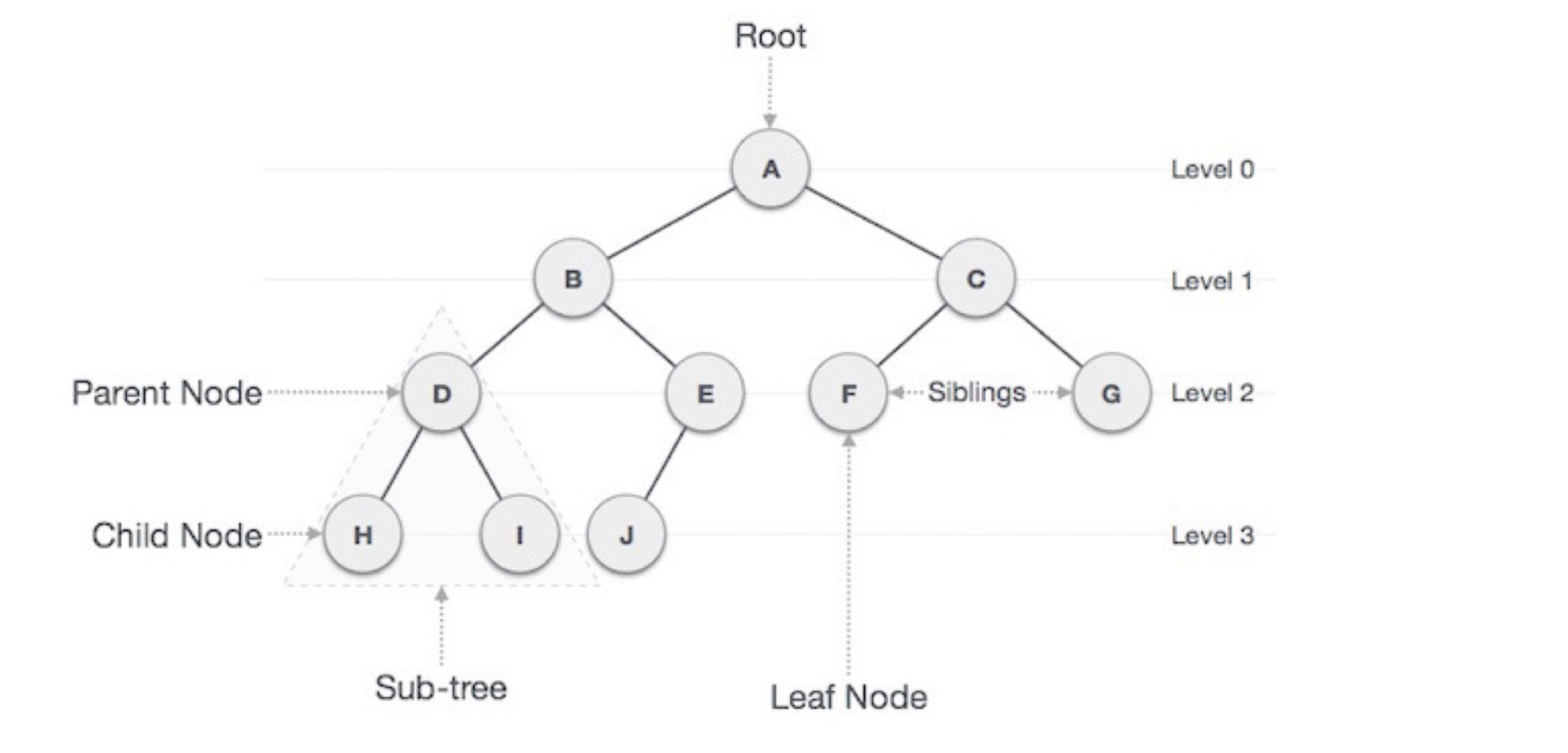
- 루트 노드(root node): 부모가 없는 노드, 트리는 하나의 루트 노드만을 가진다.
- 단말 노드(leaf node): 자식이 없는 노드, ‘말단 노드’ 또는 ‘잎 노드’라고도 부른다.
- 내부(internal) 노드: 단말 노드가 아닌 노드
- 간선(edge): 노드를 연결하는 선 (link, branch 라고도 부름)
- 형제(sibling): 같은 부모를 가지는 노드
- 노드의 깊이(depth): 루트에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수
- 노드의 레벨(level): 트리의 특정 깊이를 가지는 노드의 집합
- 노드의 차수(degree): 노드가 지닌 가지의 수
- 트리의 차수(degree of tree): 트리의 최대 차수
- 트리의 높이(height): 루트 노드에서 가장 깊숙히 있는 노드의 깊이
3. Tree의 종류
-
크게 non-binary-tree, binary-tree로 나뉜다.
-
non-binary-tree
1) trie
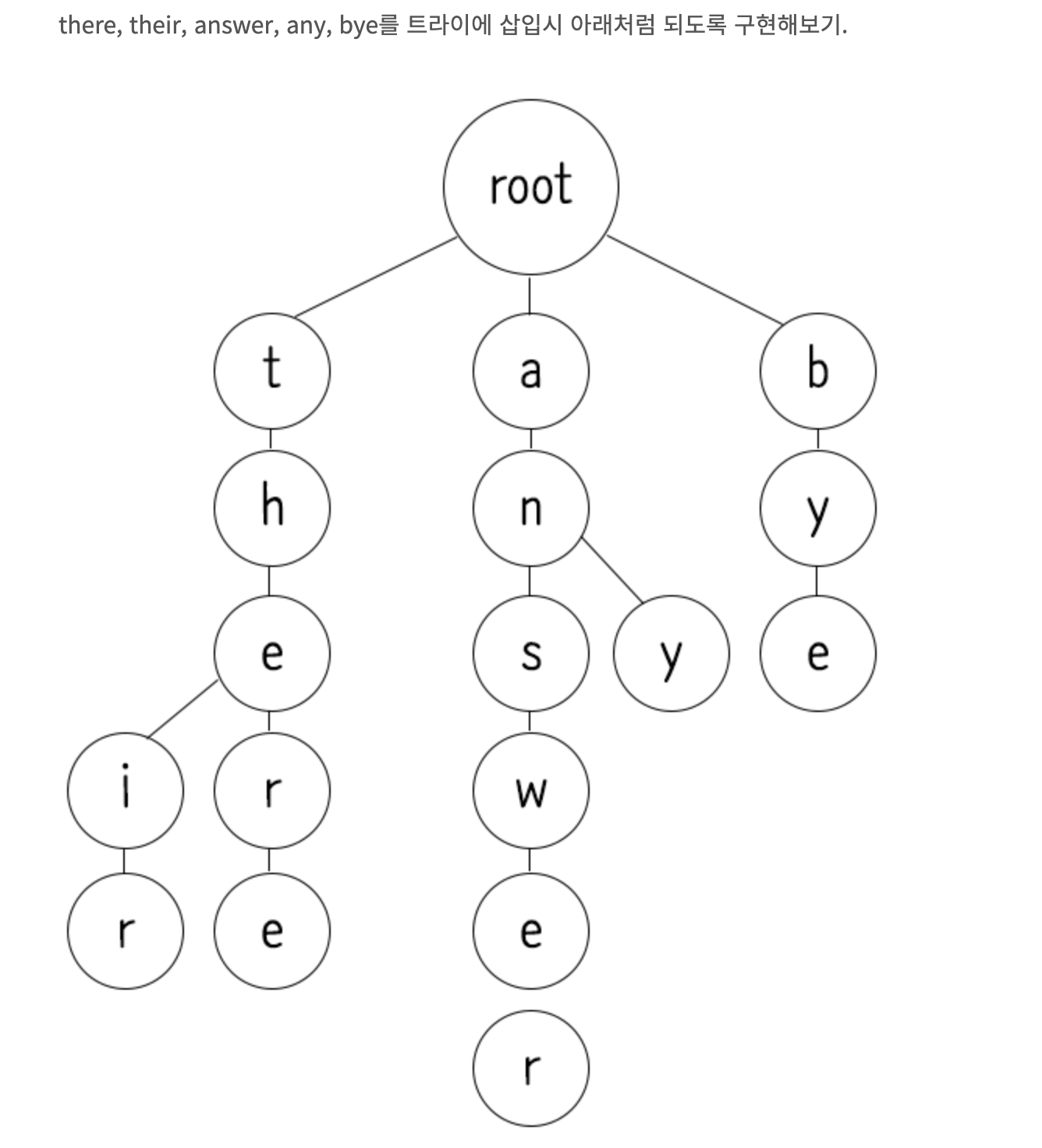
-
binary-tree
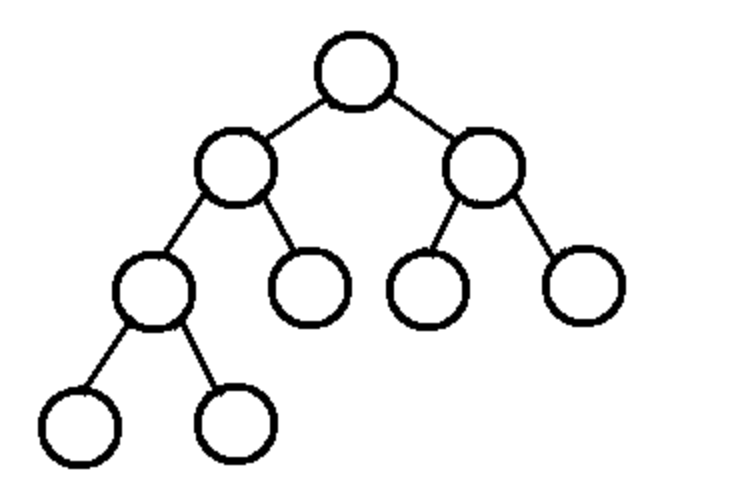
1) 완전 이진 트리(complete binary tree) : 마지막 레벨을 제외하고는 모든 자식노드가 채워져있는 트리이다.
2) 포화 이진 트리(perfect binary tree) : 모든 노드의 차수가 0아니면 2를 가지며, 모든 리프노드가 같은 레벨에 있는 트리. 그냥 꽉 차 있는 트리라고 생각 ㄱㄱ
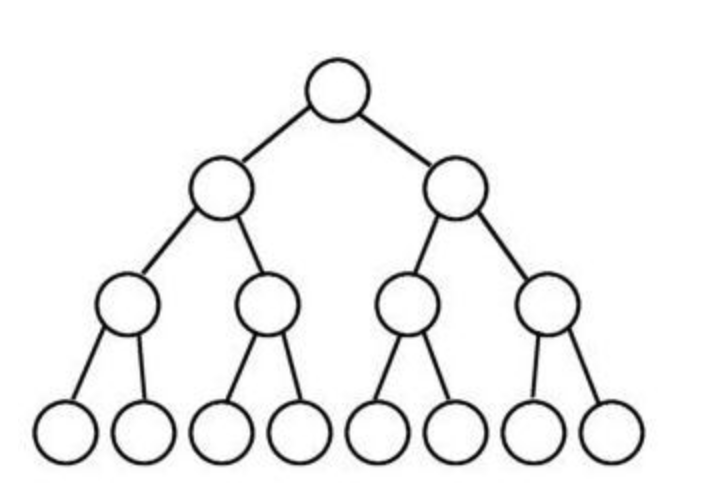
3) 정 이진 트리(full binary tree) : 모든 노드의 차수가 0아니면 2인 트리
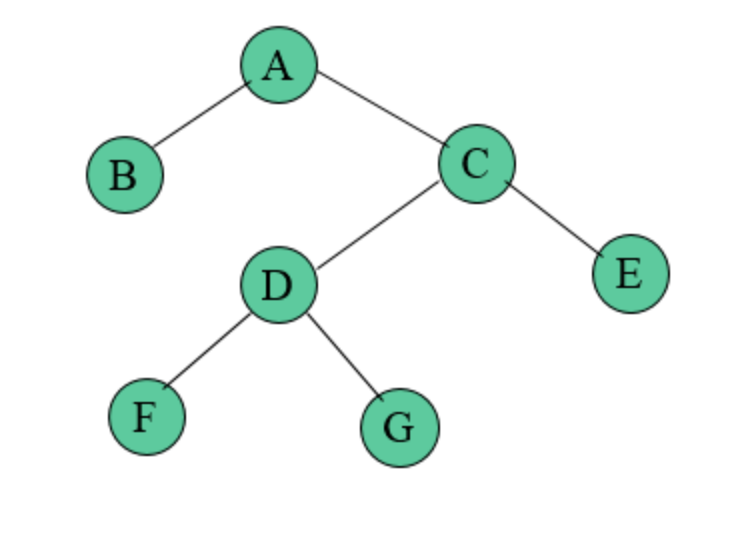
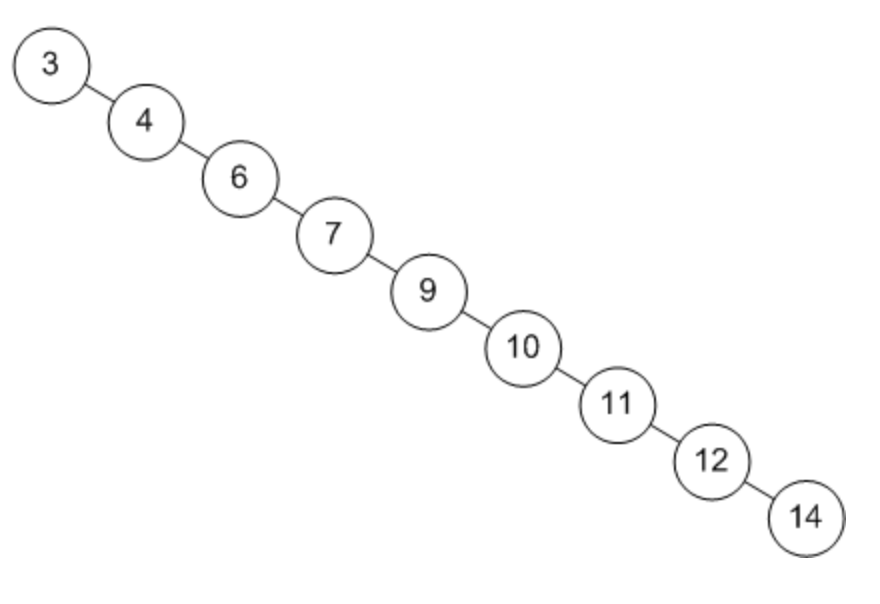
4) 편향 이진 트리(skewed binary tree) : 말 그대로 노드들이 전부 한 방향으로 편향된 트리이다.
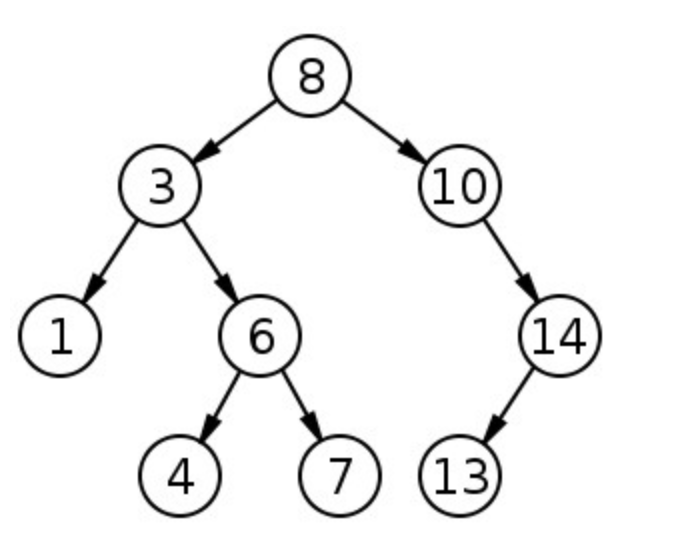
5) 이진 탐색 트리(binary search tree) : 왼쪽 자식노드의 값이 부모노드보다 작고, 오른쪽 자식노드의 값이 루트노드보다 큰 트리를 이진 탐색 트리라고 한다.-
이진 탐색 트리는 루트노드보다 계속 큰 값이 들어 올 경우에, 불균형한 편향 이진 트리가 될 수 있다.
-
그래서 "Balanced binary search tree"가 등장
-
“Splay tree”, “AVL tree”, “Red Black tree” 가 대표적인 예시이다.
-
4. Tree의 시간 복잡도(Time Complexity)
-
균형이 잡힌 tree의 탐색, 추가, 삭제는 O(logN)의 시간 복잡도를 가진다.
-
균형이 잡히지 않고 한쪽으로 치우칠수록 tree의 탐색, 추가, 삭제는 O(N)의 시간 복잡도를 가질 확률이 올라간다.
Tree의 탐색(중요)
- 다음과 같은 방법으로 트리의 노드를 순회한다.
1) 전위순회(pre-order) : "부모 - 좌 - 우"
2) 중위순회(in-order) : "좌 - 부모 - 우"
3) 후위순회(post-order) : "좌 - 우 - 부모"
Time Complexity : logN
"흔히 알고리즘을 공부하다보면 logN의 시간 복잡도를 심심치 않게 만나게 된다.
이미 대다수의 사람들이 트리를 사용할 때 시간 복잡도가 로그 값이 나온다는 사실에 대해서 알고 있을 것이다.
이때, 많은 사람들이 이 로그의 값이 어디에서 나오게 된 것인지 제대로 이해를 하지 않고, 단순히 암기를 하려고 한다.
사실, logN의 시간 복잡도가 나오는 이유는 그리 어렵지 않다.
예를 들어서 2개의 자식 노드를 가지는 이진 트리(binary tree)를 이용해서 M개의 값들 중에서 원하는 값을 찾는다고 해 보자.
처음에는 M개의 값들 모두 탐색 대상이지만, 루트 노드에서 첫 번째 자식 노드 층으로 이동하게 되면 그 수가 절반으로 줄게 된다.
이제 M/2개의 값들이 남게 되는데, 다시 한번 다음 자식 노드 층으로 넘어가게 되면 M/4개의 값들이 남게 된다.
이런 식으로 매번 층을 내려갈 때마다 남은 값의 수들이 절반이 되게 된다.
만약 탐색을 해야 하는 자료의 수가 2^n 개라면, 이진 트리를 사용할 경우 n번의 탐색을 통해서 원하는 값을 찾을 수 있게 된다.
log_2(2^n) = n 이기 때문에, 이진 탐색 트리(Binary Search Tree)를 이용한 이진 탐색 기법의 시간 복잡도가 log_2(N)이 되는 것이다.
다시 말해서, 자식 노드의 수가 m개인 트리로 N개의 자료에서 원하는 값을 탐색하는 알고리즘의 시간 복잡도는 log_m(N)이 된다."
[출처: tstory블로그, https://neos518.tistory.com/145 [As I've always been]] - 다음과 같은 방법으로 트리의 노드를 순회한다.
5. 구현 코드
- 구현은 binary search tree로 구현했다.
- addToTail(insertion)은 tail뒤에 추가하는 방법으로 구현했다.
- 순회는 중위순회로 구현했다.
- Deletion을 다시 구현해보고 수정한 코드를 올려야겠다.
class BinarySearchTreeNode {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
insert(value) {
let newNode = new BinarySearchTreeNode(value);
function recursion(node) {
if (node.value < newNode.value) {
if (node.right) {
recursion(node.right);
}
else {
node.right = newNode;
}
}
else if (node.value > newNode.value) {
if (node.left) {
recursion(node.left);
}
else {
node.left = newNode;
}
}
}
recursion(this);
}
contains(value) {
let hasVal = false;
function recursion(arr) {
let hasCNodeArr = [];
for (let item of arr) {
if (item.value === value) {
hasVal = true;
return;
}
if (item.left) {
hasCNodeArr = hasCNodeArr.concat(item.left);
}
if (item.right) {
hasCNodeArr = hasCNodeArr.concat(item.right);
}
}
if (hasCNodeArr.length > 0) {
recursion(hasCNodeArr)
}
}
recursion([this.left, this.right])
return hasVal;
}
inorder(callback) {
function travel(node){
if(node !== null){
travel(node.left);
callback(node.value);
travel(node.right);
}
}
travel(this);
}
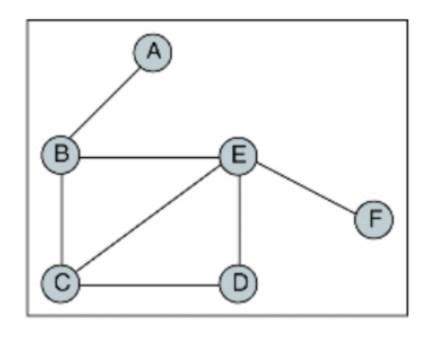
}2. Graph
1. Graph란?
- 그래프는 정점(Vertex)과 간선(Edge)으로 이루어진 자료구조
- 정점(Vertex)간의 관계를 표현하는 자료구조
- Graph 용어
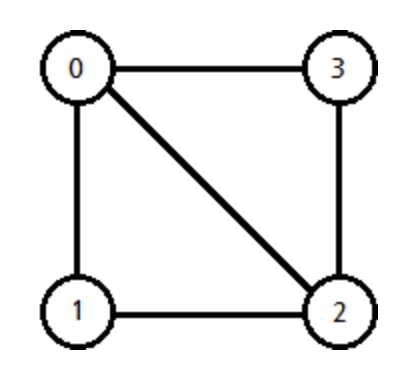
- 정점(vertex) : 노드(node)라고도 하며 정점에는 데이터가 저장된다. (0, 1, 2, 3)
- 간선(edge): 링크(arcs)라고도 하며 노드간의 관계를 나타낸다.
- 인접 정점(adjacent vertex) : 간선에 의해 연결된 정점으로 위에서 (정점0과 정점1은 인접 정점)
- 단순 경로(simple-path): 경로 중 반복되는 정점이 없는것, 같은 간선을 자나가지 않는 경로
- 차수(degree): 무방향 그래프에서 하나의 정점에 인접한 정점의 수 (정점 0의 차수 = 3)
- 진출 차수(out-degree) : 방향그래프에서 사용되는 용어로 한 노드에서 외부로 향하는 간선의 수를 뜻합니다.
- 진입 차수(in-degree) : 방향그래프에서 사용되는 용어로 외부 노드에서 들어오는 간선의 수를 뜻합니다.
2. Graph 종류
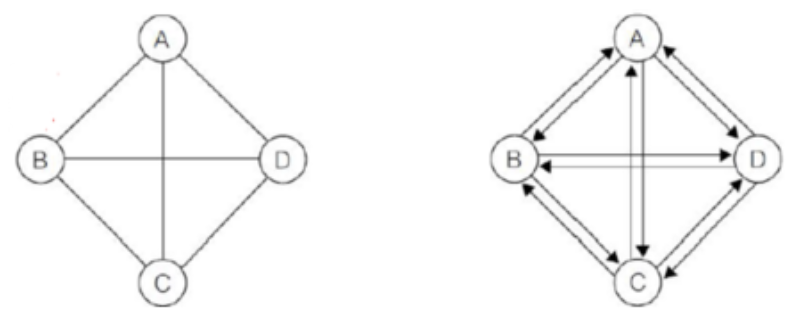
1) 무방향 그래프(Undirected Graph)
- 엣지에 방향이 없는 그래프이다.
- 정점 A와 B를 연결하는 간선을 [A, B]라고 하면, 이때 [A, B]와 [B, A]는 같은 엣지이다.
2) 방향 그래프(Directed Graph)
- 방향 그래프는 다이그래프(digraph)라고도 하는데, 엣지에 방향이 있는 그래프이다.
- 정점 A와 정점 B를 연결하는 엣지를 [A, B]라고 하면, 이때 [A, B]와 [B, A]은 같을 수 없다, [A, B]는 정점 A에서 B로만 갈 수 있는 엣지를 의미한다.
3) 완전 그래프(Complete Graph)
- 완전 그래프는 한 정점에서 모든 다른 정점과 연결되어 최대의 간선수를 가지는 그래프다.
- 무방향 그래프에서의 최대 간선 수 : n(n-1)/2
- 방향 그래프에서의 최대 간선 수 : n(n-1)/1
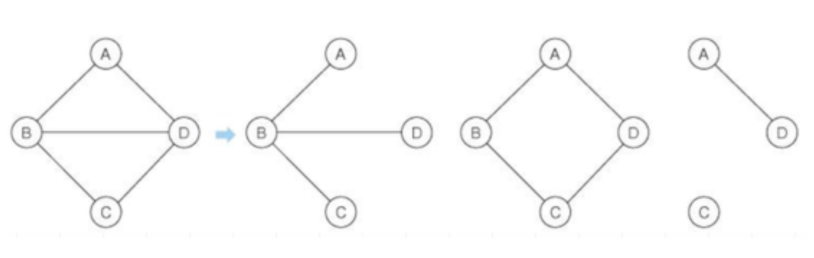
4) 부분 그래프(subgraph)
- 기존의 그래프에서 일부의 정점이나 엣지를 제외하여 만든 그래프를 의미한다.
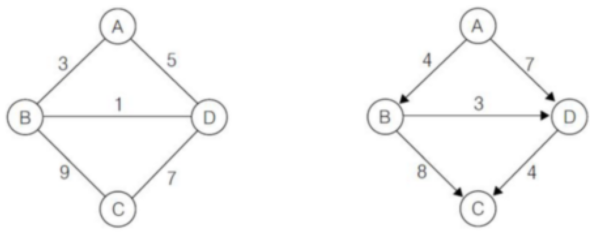
5) 가중 그래프(Weight Graph)
- 엣지에 가중치를 할당한 그래프를 의미한다.

3. Graph 시간 복잡도(Time Complexity)
-
그래프는 구현 방법에 따라 시간 복잡도가 다르다.
-
구현 방법은 인접 배열, 인접 리스트 두 가지가 있다.
-
V = 정점(Vertex)의 개수
-
E = 간선(Edge)의 개수
-
1) 인접 리스트
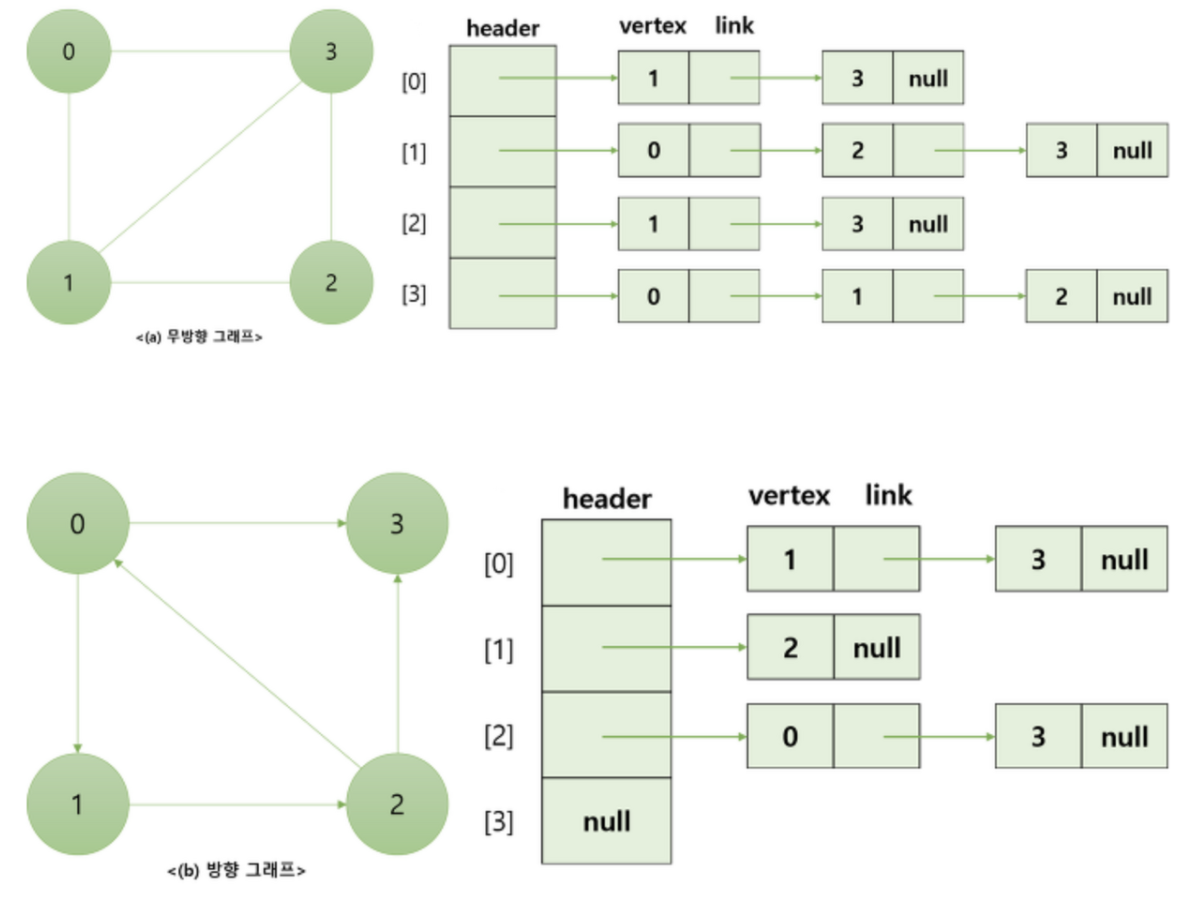
- Add Vertex : O(1)
이중연결리스트 tail의 nextNode로 지정하기 때문에 상수 시간만큼 소요된다. - Remove Vertex : O(V+E)
정점을 삭제하면 삭제된 공간을 채우기 위해 다시 색인하는 과정이 필요하므로 정점과 엣지의 개수를 합한 만큼의 시간이 소요된다. - Add Edge : O(1)
Node Add와 같은 이유. - Remove Edge : O(E)
최악의 상황은 한 줄로 정점이 연결되어 있는 경우이다. 삭제하기 위해 마지막 Edge까지 탐색해야 한다.
- Add Vertex : O(1)
-
2) 인접 배열
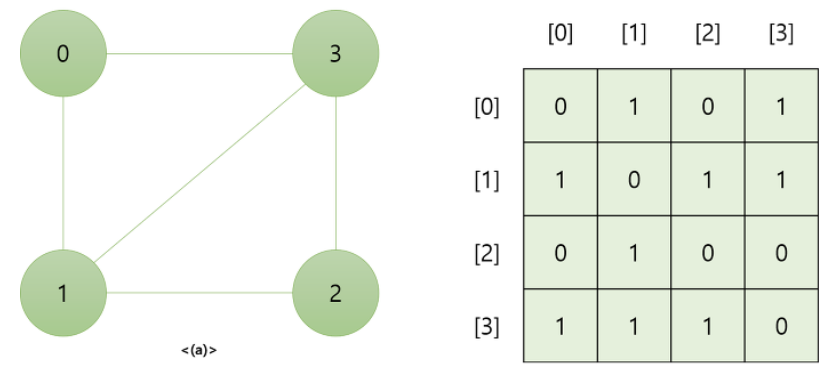
- Add Vertex : O(V^2)
행과 열을 모두 추가해야 하므로 정점 개수의 제곱만큼의 시간이 필요합니다. 추가로 새로 생긴 행과 열에 대한 각 셀을 채워야 합니다. - Remove Vertex : O(V^2)
Node Add와 같은 이유. - Add Edge : O(1)
Edge 추가는 특정 셀의 값만 변경(0, 1)하면 되므로 상수 시간만큼 소요됩니다. - Remove Edge : O(1)
Edge 삭제는 특정 셀의 값만 변경(0, 1)하면 되므로 상수 시간만큼 소요됩니다.
- Add Vertex : O(V^2)
4. Graph 탐색 방법
-
하나의 정점에서 시작하여 그래프에 있는 모든 정점을 한번씩 방문하는 것을 그래프 순회 또는 그래프 탐색 이라고 한다. 그래프 탐색 방법은 깊이 우성 탐색과 너비 우선 탐색이 있다.
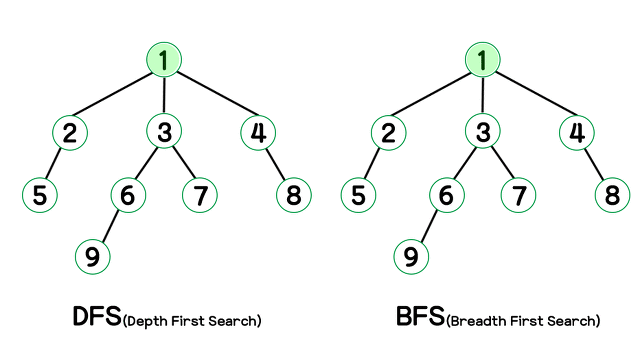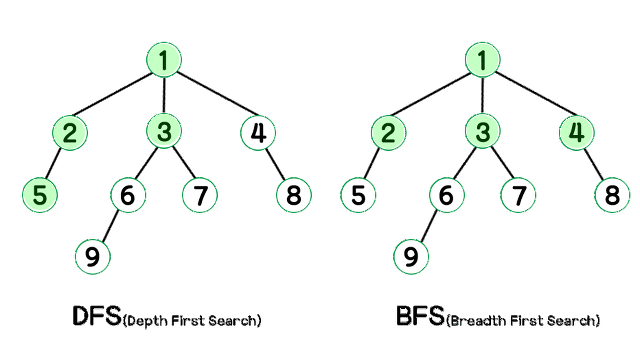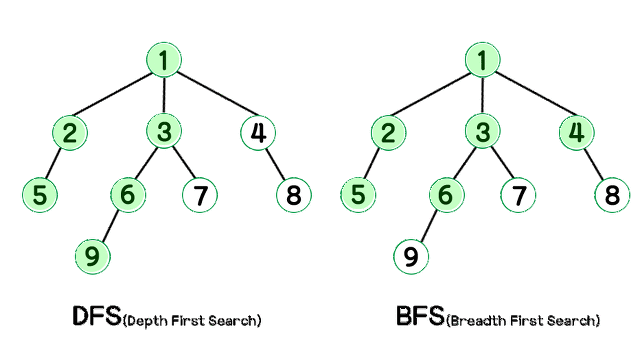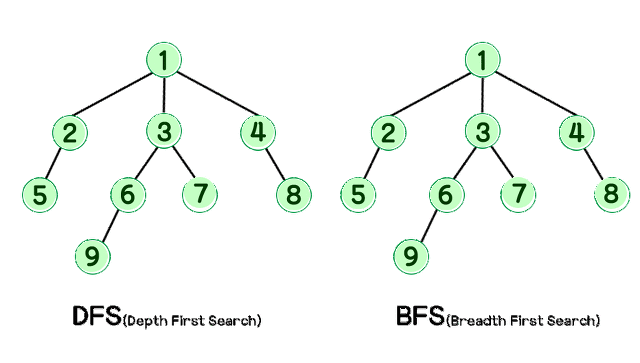
-
1) 깊이 우선 탐색, DFS(Depth First Search) : 스택, 재귀함수 사용
깊이 우선 탐색은 시작 정점에서 한 방향으로 갈 수 있는 가장 먼 경로까지 깊이 탐색해가다가 더 이상 갈 곳이 없으면 가장 마지막에 만났던 갈림길 간선이 있는 정점으로 되돌아와서 다른 방향의 간선으로 탐색을 계속함으로써 모든 정점을 방문하는 순회 방법이다. -
2) 너비 우선 탐색, BFS(Breath Frist Search) : 큐 사용
너비 우선 탐색은 시작 정점으로 부터 인접한 정점들을 모두 차례로 방문한 후, 발문했던 정점을 다시 시작점으로 하여 인접한 정점들을 차례로 방문하는 방법으로, 가까운 정점들을 먼저 방문하고 멀리 있는 정점들은 나중에 방문하는 순회 방법이다.
5. 구현 코드
- 구현은 무방향 그래프로 구현했다.
- vertex와 edge의 관계는 객체와 배열로 나타냈다. (인접배열, 인접리스트 사용 x)
class Graph {
constructor() {
/*
* ex)
* nodes = {
* 0: [ 1, 2 ],
* 1: [ 0 ],
* 2: [ 0 ]
* }
*/
this.nodes = {};
}
addNode(node) {
this.nodes[node] = this.nodes[node] || [];
}
contains(node) {
return this.nodes[node] ? true : false;
}
removeNode(node) {
this.nodes[node].forEach(function(item){
this.removeEdge(node, item);
})
delete this.nodes[node]
}
hasEdge(fromNode, toNode) {
if(this.nodes[fromNode] && this.nodes[toNode]){
return this.nodes[fromNode].includes(toNode) && this.nodes[toNode].includes(fromNode)
}
else{
return false;
}
}
addEdge(fromNode, toNode) {
this.nodes[fromNode].push(toNode);
this.nodes[toNode].push(fromNode);
}
removeEdge(fromNode, toNode) {
this.nodes[fromNode].splice(this.nodes[fromNode].indexOf(toNode), 1);
this.nodes[toNode].splice(this.nodes[toNode].indexOf(fromNode), 1);
}
}3. 정리
1. 자료구조 시간복잡도 총 정리
- big-O는 worst case, big-Omega는 best case, big_Theta는 average case를 나타낸다.
- 추가로 sorting과 heap의 시간복잡도도 올린다.
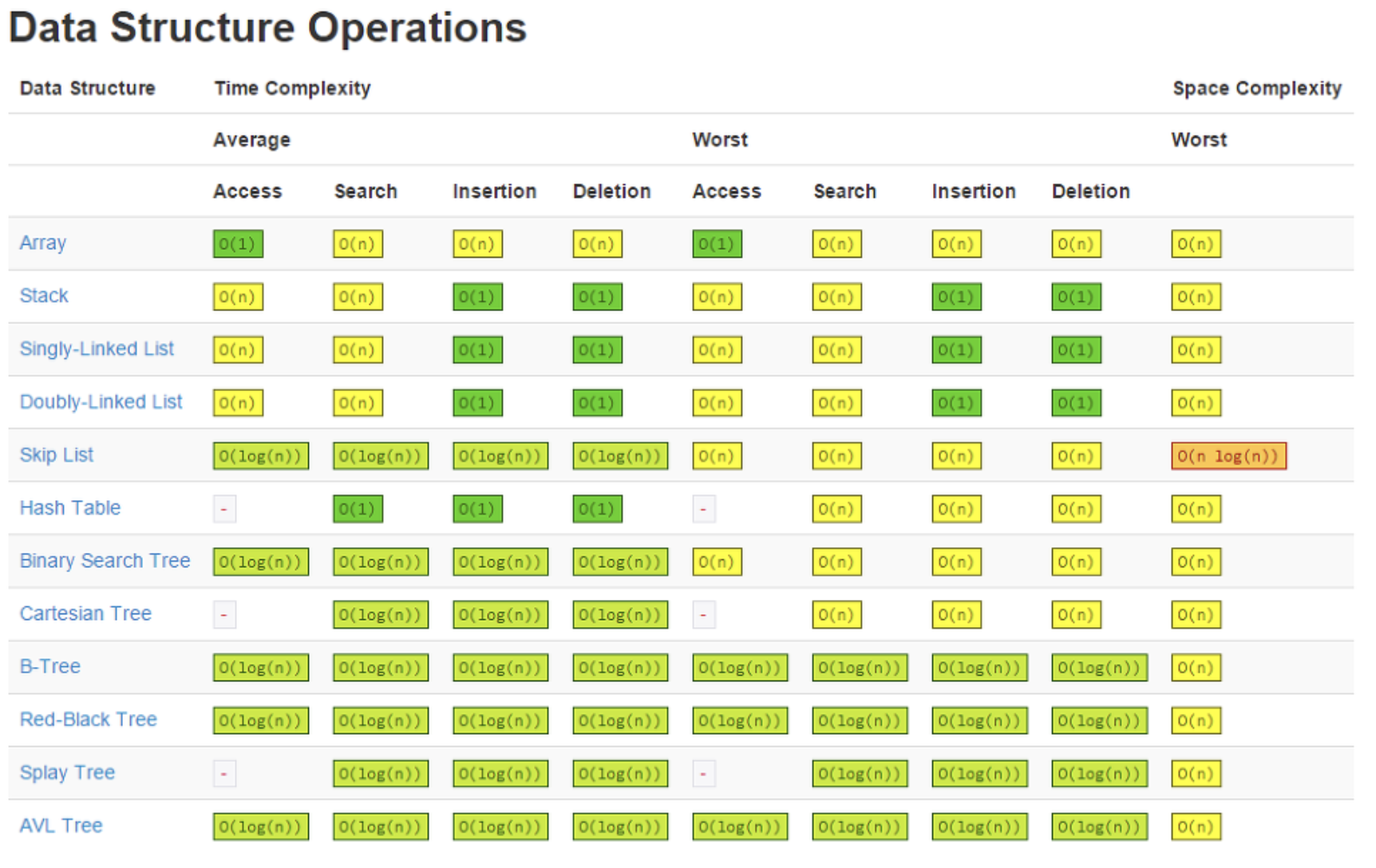

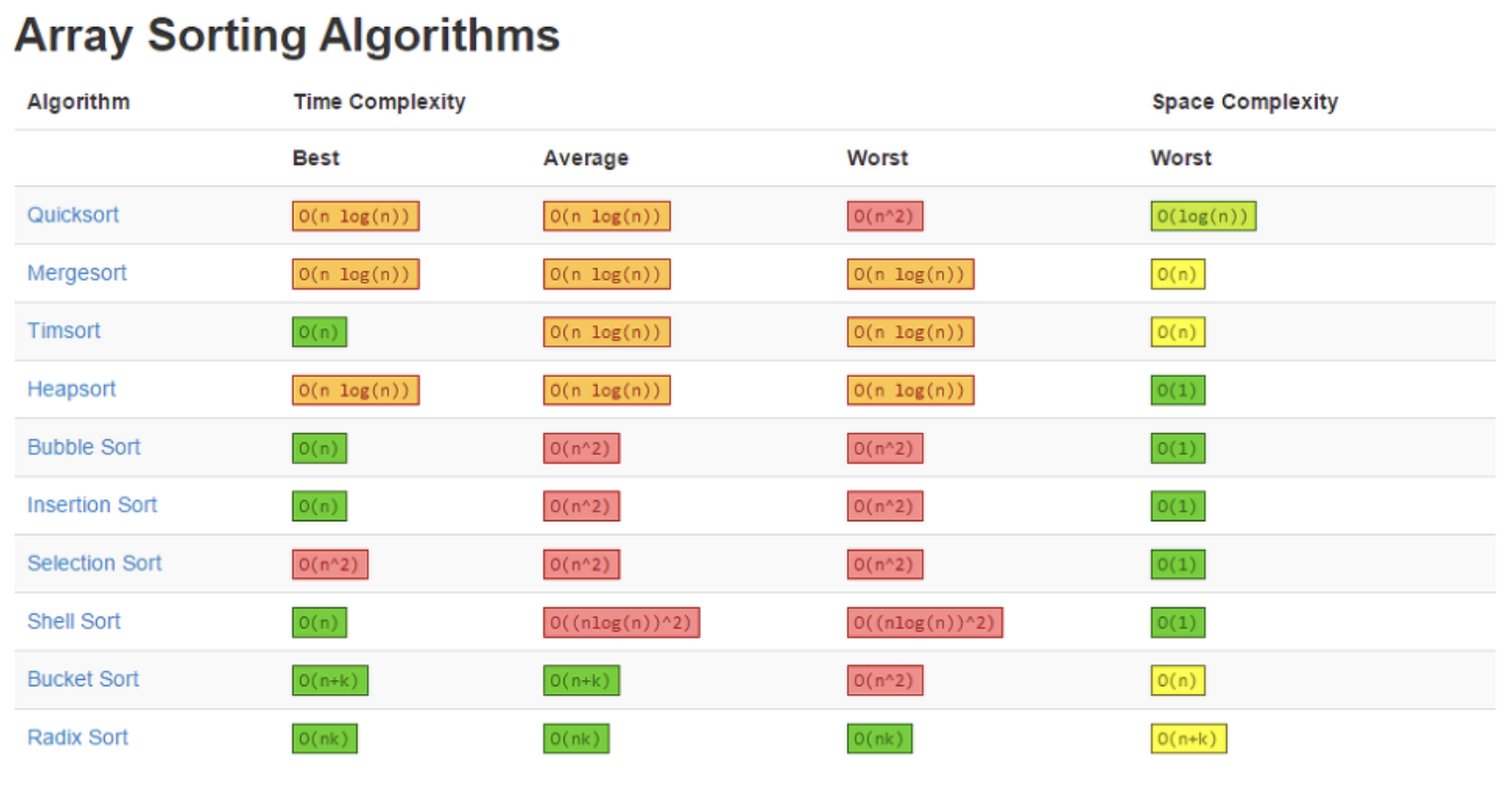
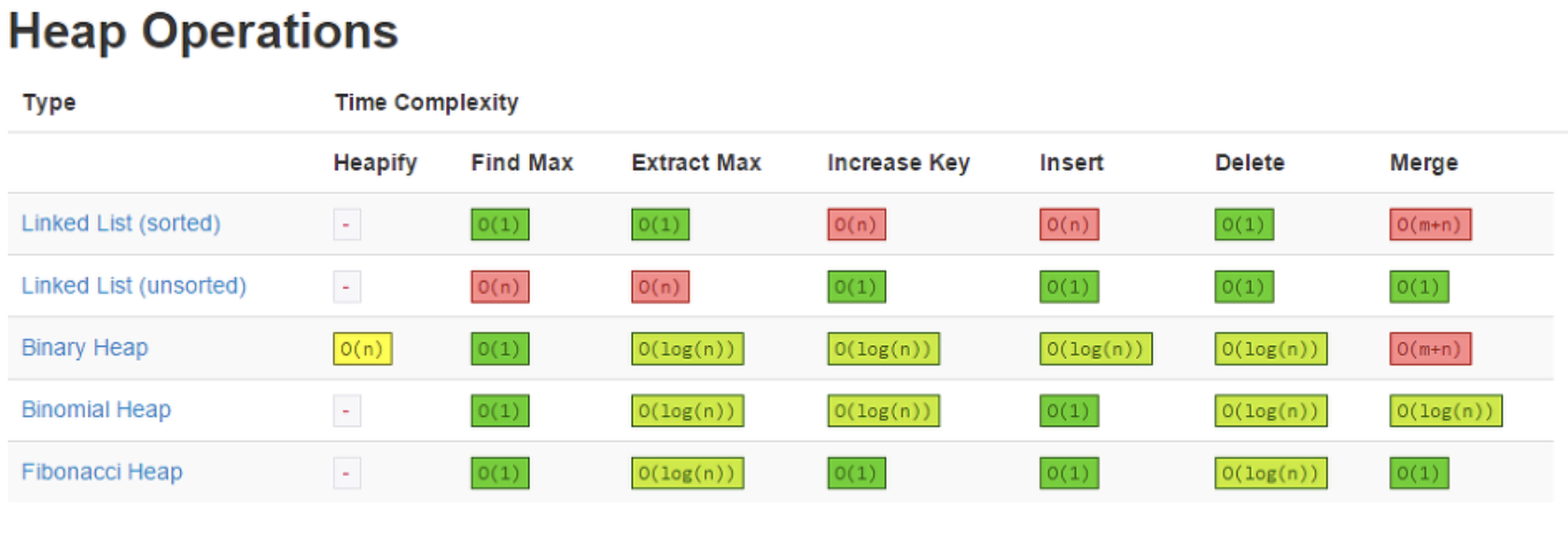
2. 자료구조의 적용 사례
-
Stack : 프로그래밍 언어의 런타임에서 함수의 호출을 관리(Call Stack), undo(이게뭔지 알아보자), 재생목록관리
-
Queue : 메세지 큐, 메세지 브로커, node.js 런타임에서 이벤트 큐, BFS(너비우선탐색)
-
Linked List : 파일시스템(자료의 추가 / 삭제가 빈번히 일어날 경우에 사용)
-
Hash Table : 딕셔너리(객체), Map, p2p, 시스템의 노드 주소관리, 로드밸런싱
-
Tree : binary search tree, 2-3-4 tree, b-tree, radix tree(자동완성, 검색), patricia tree
-
Graph : 네비게이션, sns
3. Queue, Tree, Graph는 최근 기업의 알고리즘 테스트에서 많이 출제된다.
4. 자료구조는 면접 단골 질문! 필수적으로 이해하기.
# Work Off
요새 스타트업이라는 드라마가 방영중인데, IT창업을 주제로 하는 드라마라서 흥미가 간다.
주인공이 영상처리로 카메라에 담기는 객체를 분석하는데, 옛날에 학부시절에 한 것들이 생각이 났다.
그거 깃허브에 담는건 괜찮은데.....블로그에 내용을 포스팅 하려니 골이 아프다....ㅎ
하... 갑자기 backpropagation이 생각남...
아~ 척추뽑히겠당~
그만 써야겠다ㅎㅎ
👋👋
기본기가 탄탄한 풀스택 개발자가 되는 그날까지 🔥🔥🔥


전 구현도 어렵고, 블로깅도 어려운데... 어쩌죠. ㅠㅠㅠㅠㅠ