다음 논문을 리뷰합니다.
- RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
https://arxiv.org/abs/2309.00267
RL from human feedback(RLHF) 의 등장과 한계
- 사용자의 선호(preference)를 모델에 일치시키는(align) 효과적인 방식으로 제안되었고, chatGPT나 Bard와 같은 LLM의 성공의 핵심 요소로 꼽히고 있다.
- 기존의 전통적 지도학습으로는 다루기 힘든 복잡하고 미분이 어려운 task은 강화학습으로 학습시키는 것이 효율적
- 하지만 고품질의 사용자 레이블(feedback)을 대량으로 확보하는 것은 큰 난관이기에 이를 인공적(artificially)하게 생성시키면서 비슷한 효과(결과)를 얻을 수 있을지에 대한 관심 고조
RL from AI feedback (RLAIF) 의 등장
- 2023년 Gilardi의 연구에서, AI로부터 얻는 preference를 리워드 모델 학습에 사용한 사례 등장
- 인간과 AI의 선호 시그널을 혼합하여 상용한 사례이고, feedback을 사용하지 않은 지도학습 기반 finetune 모델과 비교하였다.
- 하지만 인간 feedback과 AI feedback 사이의 직접적 비교는 하지 않았다.
우리 연구의 성과
- AI feedback과 Human feedback 사이의 직접적 비교 연구를 수행하였고 AI feedback 만으로도 human feedback 에 근접한 성과를 낼 수 있음을 보였다.
- AI feedback을 huamn feedback에 최대한으로 일치(align)시키는 방법에 대해서 살펴보았다. 상세한 지시(instruction) 과 COT 를 유도하는 것이 효과적임을 보였다.
- AI feedback을 생성하는 LLM이 얼마나 커야 하는지? AI feedback을 얼마나 많이 생성해야 하는지에 대한 기준을 제시하였다.
사전 지식
지도 미세학습 (supervised finetune)
- pretrained LLM을 특정 task 혹은 다양한 micro task에 적합하게 학습시키는 것
- 이렇게 얻은 모델을 SFT model이라고 하고 baseline에 해당한다.
Reward Modeling (RM)
-
입력 문장 x 에 대해서 LLM으로부터 두 개의 서로 다른 답변 (y1, y2)를 얻어내고 human labeler로 하여금 두 개의 답변에서 더 우월한(적합한) 것이 어떤 것인지 고르게 한다.

-
reward model은 위의 triplet dataset D 에 대해서 대조학습(contrastive) 을 하는 것

Reinforcement Learning
- SFT로부터 정의되는 초기 정책과, 보상모델(RM)으로 얻는 보상이 주어졌을 때 이를 최대화하도록 강화학습을 하는 것
- 정책 변화시에 원래 SFT로 너무 급격히 변화하지 못하도록 양 분포간의 차이(KL divergence)를 penalty term으로 추가한다. (다른 말로는 reward hacking 방지)
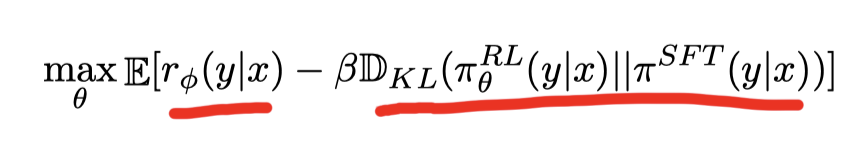
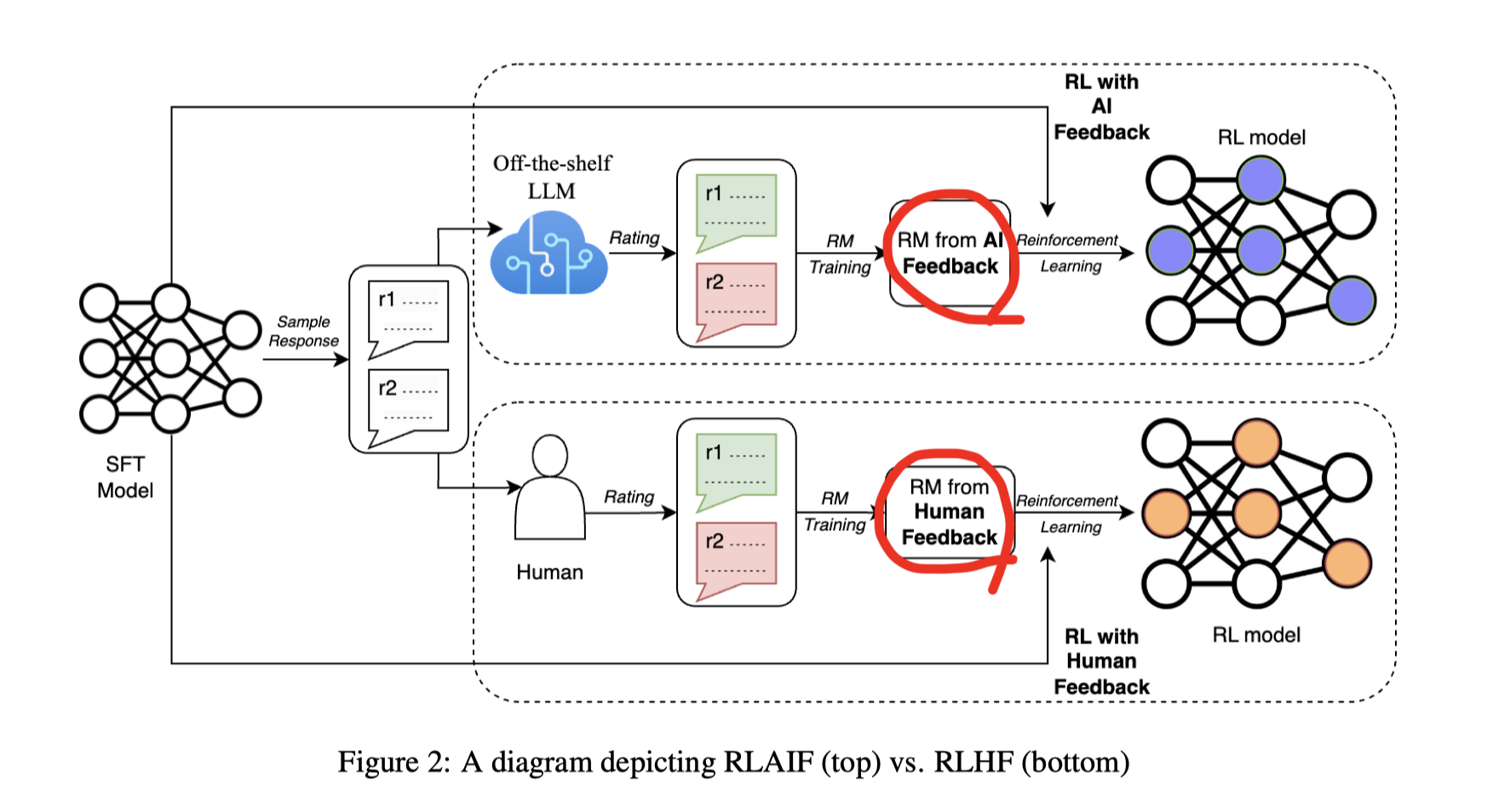
RLAIF 구성
LLM들을 바탕으로 선호 라벨을 획득
-
선반에서 바로 끄낸(off-the-shelf) LLM 을 labeler로 사용한다.
- 여기서는 google 내의 PaLM 류를 사용
- 미세학습(fine-tune) 없이 순수한 pretrained 상태의 모델 사용
-
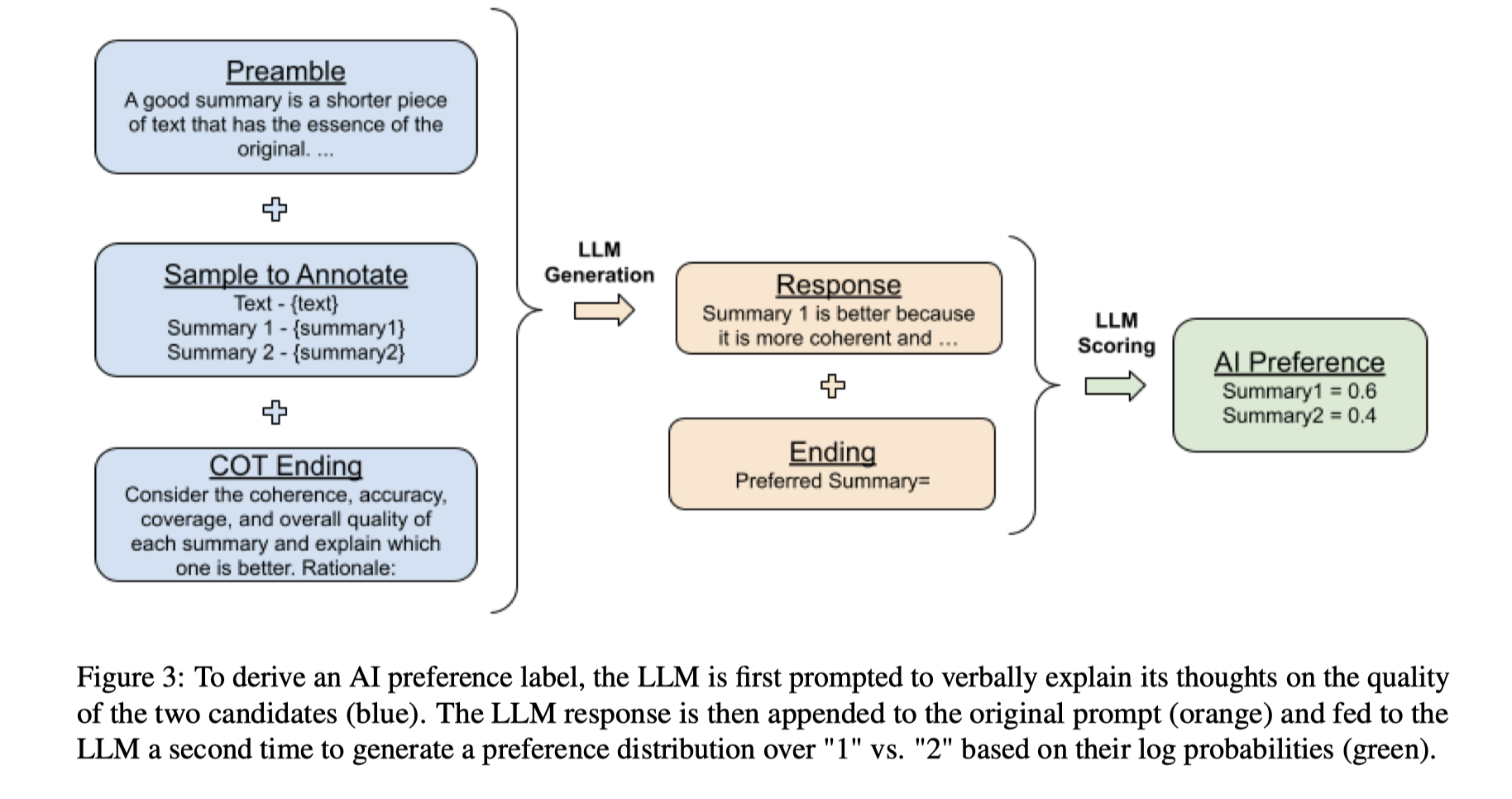
요약(summarization) task에 대해서 하나의 긴 입력 문장에 대해서 두 개의 서로 다른 요약문이 있을 때 LLM labeler로의 prompt은 다음과 같이 구성된다.
- Preamble (도입문과 지시문), fewshot, 풀 문제 제시, ending
-
prefered summary 쪽에 1, 또는 2가 쓰여질 텐데, token 1 (선호), token 2 (비선호) 에 대한 log 확률값을 얻어서 softmax를 취해 선호와 비선호에 대한 비율을 측정한다.

Preamble의 구성 방식
- 간단한 버젼과 상세한 버젼 (base v.s. OpenAI)
- 상세한 버젼은 실제 human 라벨러들에게 업무 가이드라인으로 openai에서 배포한 것을 사용하였다.

%20b8113254d7224d2585bb48512b4b232c/Untitled%206.png)
위치 편견(position bias)
두 개의 문장의 제시 순서가 선호에 영향을 미칠까?
- 미치는 것이 측정되었다. (Pezeshkpour and Hruschka, 2023).
이 편견 현상을 완화하기 위해서 한번만 추론하는 것이 아니라 두 개의 문장의 순서를 바꾸어서 한번 더 추론한다. 각 추론에서 나온 softmax 분포값을 평균해서 최종 선호 분포를 결정한다.
생각의 사슬(Chain-of-thought) 유도를 통한 더 나은 일치(alignment)
- 단순히 선호 문장은? 이라고 묻기 보다는 이러이러한 평가 기준이 있는데 너는 왜 이것을 선호했는지 설명해봐~ 라는 식으로 깊은 생각을 유도


- 첫번째 pass 에서는
- Preamble + fewshot + COT ending으로 Rationale을 생성
- 두번째 pass 에서는
- Preamble + fewshot + COT ending + rationale + ending으로 1또는 2의 이진 선택 유도
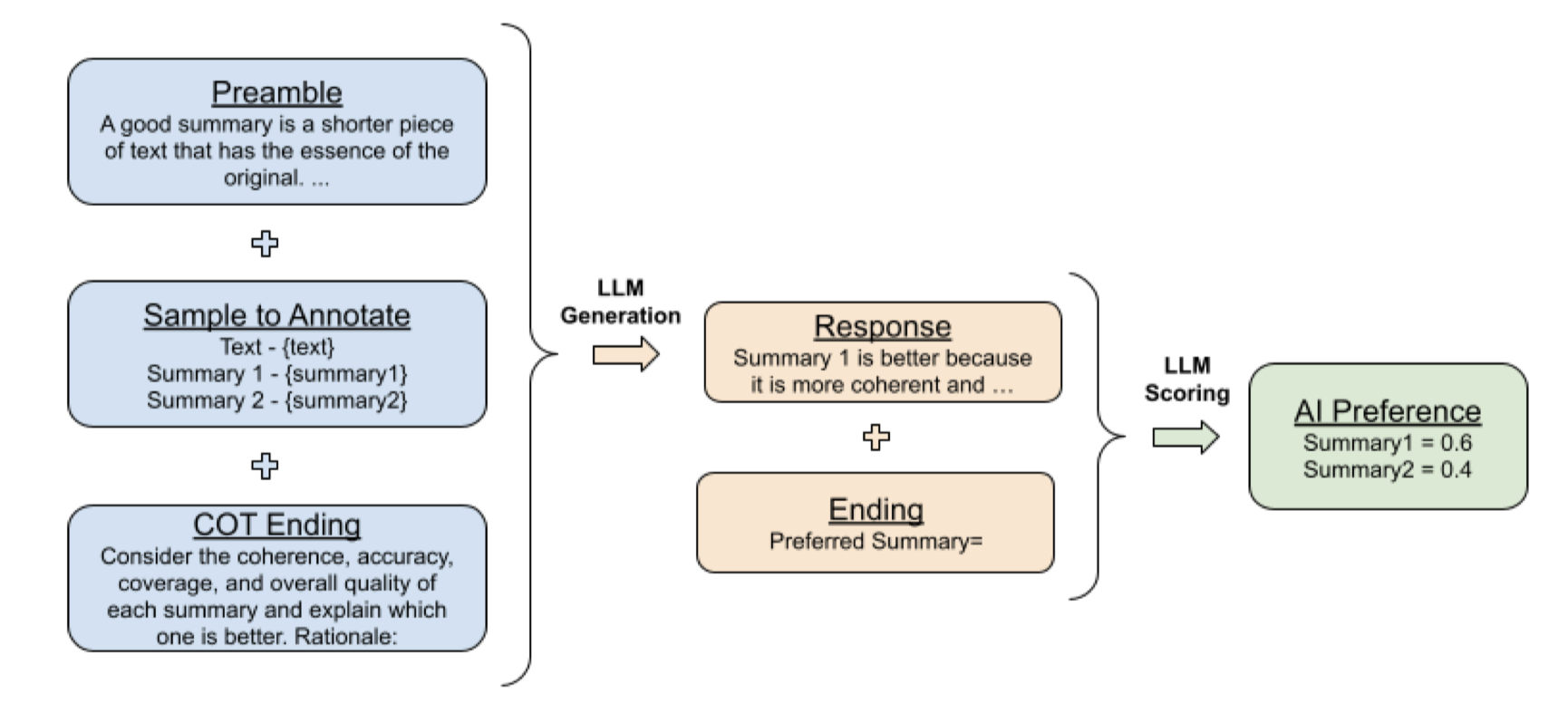
- Preamble + fewshot + COT ending + rationale + ending으로 1또는 2의 이진 선택 유도
자기 일관성(self-consistency)을 향상한 AI feedback 생성
- 같은 입력에 대해서 디코딩 온도를 달리하여 얻은 다양한 선호분포를 평균내서 최종 분포를 결정함

AI feedback을 사용한 보상 모델 학습 및 최종 강화학습
- 선호 분포가 softmax를 한 확률 분포이므로(,ex) 0.6, 0.4) cross-entropy를 loss로 사용하였다.
- 선호 모델을 얻는것은 일종의 모델 distillation으로 간주할 수 있다. 즉 선호 모델이 없다할지라도 LLM labeler자체를 강화학습시에 보상(reward)를 생성하는데 직접적으로 사용할 수도 있기는 하지만, 이 경우 매우 비용이 많이들기 때문에 LLM을 축소하여 선호모델을 만들어 낸 것이라고 볼 수 있다.
- 강화학습은 흔히 사용하는 PPO 보다는 A2C 를 사용하였다.
평가 기준
- AI labeler alignment - 인간 선호를 ground truth로 간주하고 이와 얼마나 일치하는지 측정한 정확도이다.
- ex) AI: 0.6, 0.4. Human : 1.0, 0.0. ⇒ 1개 맞춤
- Win Rate of A v.s B.
- A와 B는 두 개의 보상 모델이라 볼 수 있고,
- 인간 선호를 ground truth로 간주할 때, A 대비 B의 승률을 따지는 것
실험 상세
평가 Dataset
- 2020년 OpenAI가 3백만개의 Reddit TLDR data를 리뷰해서 고품질의 13만여개의 post를 추려내었다. 이를 filtered Reddit TL;DR 데이터로 칭한다.
- filtered Reddit TLDR에 대해서 openai가 인간 labeler를 고용해서 triplet preference dataset을 만들어 두었다.
- 하나의 긴 단락 ⇒ 두 개의 요약 문장 ⇒ 두 개 중에 어떤게 더 좋은가
- 최종적으로 92k 의 preference dataset
AI labeler 선정
- 92k 의 preference 중에서 랜덤 선정한 2800여개의 data를 평가셋으로 AI labeler alignment를 측정하였다.
- 모델 크기가 크면 클수록 alignment가 좋아지는 것을 확인했고 최종적으로는 PaLM 2L을 AI labeler로 선정하였다.

- context length = 4096 tokens
- decoding length = 512 tokens (T=0)
- 자기 일관성 실험에서는 T=1, Top-40 sampling decoding 사용
모델 학습
- PaLM 2 XS 를 initial point로 하고, filtered TLDR셋 (not preference )을 학습셋으로 해서 SFT model 을 생성하였음
- human preference dataset을 이용하여 보상 학습 모델을 일차 학습하고??????????????
- PaLM 2L을 AI labeler로 선정하여 획득한 preference data를 이용해서 2차 학습시켰다.
- 그리고 강화학습 진행 (with A2C)
Summary 생성 품질 평가(human evaluation)
- SFT, RLAIF, RLHF 의 생성 품질을 정성적으로 평가하기 위해서 1200 개의 요약문을 수동으로 평가하였다. (human evaluation)
- RLHF 가 SFT를 이긴 비율과 RLAIF가 SFT를 이긴 비율이 비슷한 것으로 봐서 RLHF와 RLAIF 가 비등(comparable)함을 알 수 있다.
- RLHF가 RLAIF를 50%의 확률로 이긴 것은 두 개가 비등함의 또다른 증거이다.
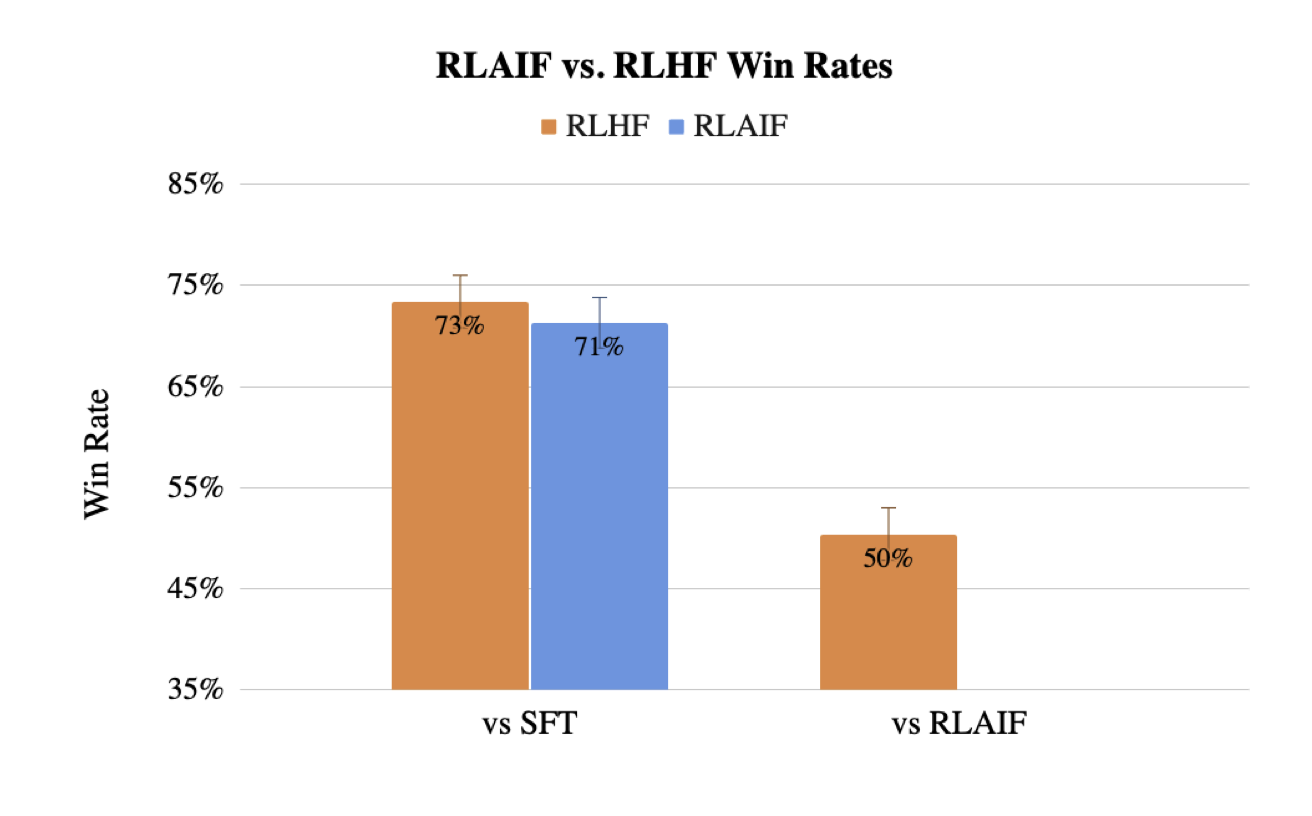
- RLAIF가 상대적으로 더 긴(longer) 요약문을 생성하는 경향이 있고 이것이 품질 향상의 근거가 아닌 가 싶다.

- 만약 생성 길이를 제약(controlled)하면 SFT 대비한 승률이 다소 낮아진다. (70% ⇒ 60%) . 하지만 여전히 RLHF와 RLAIF는 comparable하다.
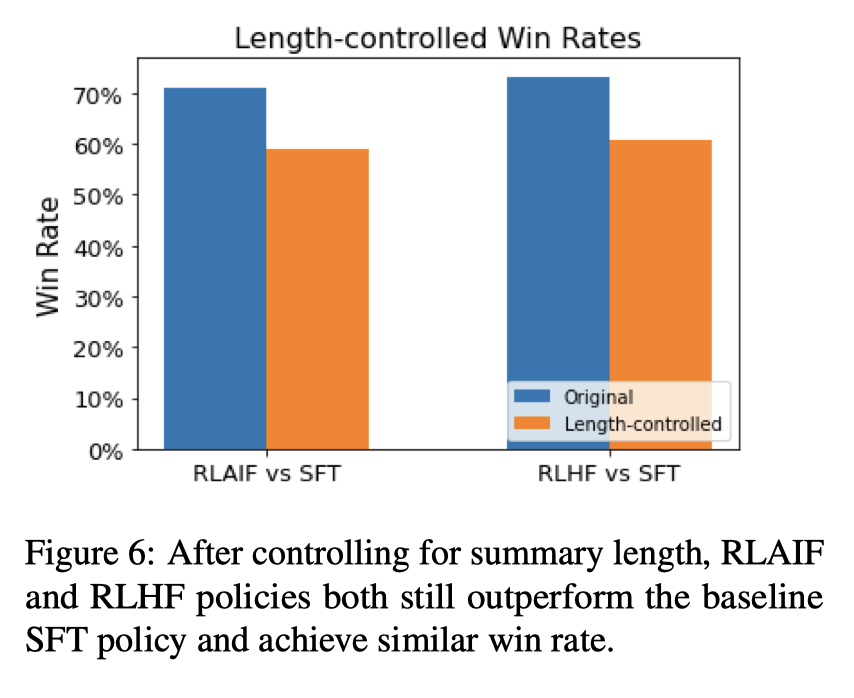
효과적인 AI feedback 생성 방식 제시
1) AI labeler 는 크면 좋다.
- 큰 것이 더 AI labeler alignment가 크게 측정
- 작은 LLM에서는 위치 편향이 커지기 때문이 아닐까 한다

2) 간단 지시문 v.s 복잡 지시문 ⇒ 복잡한 것이 좋다.
3) 생각의 사슬을 만들어 주는 것이 좋다.

4) 높은 온도 + 자기 일관성 향상은 애매하다.
- 낮은 온도와 한 번의 greedy한 디코딩 + 생각의 사슬이 가장 좋다
- 온도를 높히면 저품질의 rationale이 생성될 가능성이 높아져서 일관성 이외의 부작용이 생기는 듯 하다

5) AI feedback 생성 개수가 많으면 많을수록 계속 개선된다? No
- human feedback은 개수가 많아지면 많아질수록 계속 개선되는 것처럼 보이지만
- AI feedback은 초반에는 개수가 적어도 품질 향상에 크게 기여하나 얼마 안있어서 한계에 도달하고(plateuas) 개수가 많아져도 크게 개선은 없는 듯하다.

RLHF 대비 몇가지 정성적 차이 (객관적 증거는 없음)
- RLAIF 가 더 환각 생성이 적다.
- RLAIF가 다소 응집성이 떨어지고 문법이 틀리는 경향이 있다.
결론
AI feedback을 사용하는 것은 human feedback을 사용하는 것과 비슷한 효과를 낸다 (비용은 매우 싸다)
효과적인 AI feedback 생성 전략을 고찰하였다. (AI labeler는 크게, 지시문을 정성들여 만들고, COT 활용, 생성 개수는 scale-up의 한계가 있음)
단순히 요약 task에만 적용한 것이라서 일반적으로 이러한지 말하기 힘든 한계가 있고, 두 개를 결합하는 것(RLHF + RLAIF)의 효과도 측정되지 못해서 미래 연구과제로 남긴다.
