use nodejs;
select * from member;# 그룹
# select 그룹을 맺은 컬럼 또는 집계함수 from 테이블 group by 컬럼
# select 그룹을 맺은 컬럼 또는 집계함수 from 테이블 group by 컬럼 having 조건# 집계함수: count(), sum(), avg(), min(), max()
select gender from member group by gender;
select gender, count(idx) from member group by gender;
# 집계함수에서 컬럼을 선택할 때 primary key 제약 조건이 있는 컬럼을 선택하는 것을 추천
select gender, count(idx) from member group by gender having gender = '여자';
select gender, count(idx) as cnt from member group by gender having cnt >= 3;
# 유저 테이블에서 포인트가 50이상인 유저 중에서 성별로 그룹을 나눠 각 그룹의 포인트 평균을 구하고 평균의 포인트가 100이상인 성별을 알아보자.
# 단, 성별이 남, 여 모두 출력된다면 포인트가 높은 성별을 우선으로 출력
select gender, avg(point) as avg from member where point >= 50 group by gender having avg>=100 order by avg desc;❇️ MySQL 문자열 함수
# concat: 문자열을 연결해주는 함수
select concat('안녕하세요', 'MySQL') as concat;
select concat(address1, ' ', address2, ' ', address3) as address from member where userid='apple';# left, right: 왼쪽 또는 오른쪽에서 길이만큼 문자열을 반환
select left('ABCDEFGHIJKLMN', 5) as str;
select userid, left(userid, 3) as id from member;# substring: 문자열의 일부를 추출하여 반환
select substring('ABCDEFGHIJKLMN', 5) as str; # 시작위치부터 끝까지 추출
select substring('ABCDEFGHIJKLMN', 5, 3) as str; # 시작위치부터 길이만큼 추출
select userid, substring(address1, 1, 5) as address from member;# char_length: 문자열의 길이를 반환
select char_length('ABCDEFGHIJKLMN') as str;
select email, char_length(email) as len from member;# lpad, rpad: 왼쪽 또는 오른쪽의 문자열을 해당 길이만큼 늘리고, 빈 공간을 채운 문자열을 반환
select lpad('ABCDEFG', 10, '*') as lpad;
select userid, rpad(userid, 20, ' ') as rpad from member;# ltrim, rtrim, trim: 왼쪽, 오른쪽, 양쪽 모든 공백을 제거
select ltrim(' ABCDEF ') as ltrim;
select rtrim(' ABCDEF ') as rtrim;
select trim(' ABCDEF ') as trim;# replace: 문자열에서 특정 문자열을 변경하여 반환
select replace('ABCDEFG', 'CD', '') as rp;
select userid, replace(gender, '자', '') as gender from member;✨ 기억할 것
substring('ABCDEFGHIJKLMN', 5) : 5번째 문자인 E부터 끝까지 출력
substring('ABCDEFGHIJKLMN', 5, 3) : 5번째 문자인 E부터 3개의 문자 출력
char_length : 문자열의 길이 반환
lpad('ABCDEFG', 10, '*') : ***ABCDEFG
rpad(userid, 20, ' ') : userid하고 userid포함해서 길이가 20이 되도록 오른쪽에 공백들어감
ltrim, rtrim : 각각 왼쪽, 오른쪽 공백 제거
trim: 양쪽 공백 제거
❇️ 뷰(view)
-
하나 이상의 테이블의 쿼리 결과를 가상의 테이블 형태로 보여주는 것
-
실제 데이터는 저장하지 않고, 쿼리를 미리 저장해둬서 테이블처럼 사용할 수 있게 함
-
복잡한 쿼리나 자주 사용하는 쿼리를 간단하게 사용할 수 있도록 도와주는 가상 테이블
-
테이블의 일부 열이나 행만 사용자에게 보여줄 수 있음
(민감한 데이터를 보호) -
성능이 떨어질 수 있음.
뷰를 사용할 때마다 원본 테이블에서 데이터를 조회하므로, 큰 데이터셋이나 복잡한 쿼리의 경우 성능이 저하될 수 있음 -
order by는 뷰를 조회할 때 별도로 사용하는 것을 추천
-
insert/update 할 때 복잡하게 적용된 뷰는 데이터를 추가하거나 수정하기 힘들 수 있음
select m.idx, m.userid, m.name, m.gender, p.mbti from member as m join profile as p on m.idx = p.idx;
create view vw_memberinfo as select m.idx, m.userid, m.name, m.gender, p.mbti from member as m join profile as p on m.idx = p.idx;
select * from vw_memberinfo;
select userid, mbti from vw_memberinfo;
select * from member;
create view vw_member as select idx, userid, name, hp, email, gender, point from member;
select * from vw_member;
select * from vw_member order by idx desc;
alter view vw_member as select idx, userid, name, hp, email, gender, regdate, point from member;
select * from vw_member;
drop view vw_member;
select * from vw_member;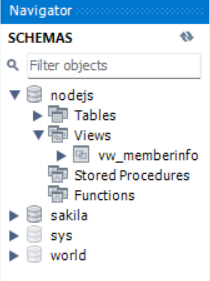
이렇게 view가 생성된 것을 왼쪽에 있는 Navigator를 통해 볼 수 있다.
❇️ 서브쿼리(SubQuery)
-
다른 쿼리 내부에 포함되어 있는 select 문을 의미
-
서브쿼리를 포함하고 있는 쿼리를 외부쿼리라고 부르고, 서브쿼리는 내부쿼리라고 부름
-
서브쿼리는 괄호()를 사용해서 표현
-
select, where, from, having 문장 등에서 사용할 수 있음
create table product(
code varchar(5) not null,
name varchar(20) not null,
detail varchar(1000),
price int default 0,
regdate datetime default now()
);
select * from product;
insert into product values('00001', '맥북에어', '가벼워요~', 1500000, now());
insert into product values('00002', '자동차', '잘가요~', 10000000, now());
insert into product values('00003', '반포자이', '너무비싸요', 1000000000, now());
insert into product values('00004', '현익빌딩3F', '더비싸요', 1000000000, now());
insert into product values('00005', '경비행기', '잘날아요~', 1500000000, now());
# 상품코드가 '00003'의 가격보다 크거나 같은 가격을 가지고 있는 상품의 정보를 모두 출력
select price from product where code='00003';
select * from product where price>=100000000;
select * from product where price>=(select price from product where code='00003');
# product 테이블에서 가장 비싼 상품에 대한 모든 정보를 출력
select * from product order by price desc limit 1;
select * from product where price = (select max(price) from product);
# product 테이블에 모든 데이터를 출력
# 단, 파생 컬럼을 만듬(가장 비싼 상품의 가격)
# code, name, price, '가장 비싼 상품의 가격'
select code, name, price, '가장 비싼 상품의 가격' from product;
select max(price) as '가장 비싼 상품의 가격' from product;
select code, name, price, (select max(price) from product) as '가장 비싼 상품의 가격' from product;
use nodejs;
create table orders (
no int auto_increment primary key,
idx int not null,
product_code varchar(5) not null,
product_cnt int default 0,
regdate datetime default now(),
foreign key(idx) references member(idx)
);
insert into orders (idx, product_code, product_cnt) values (1, '00003', 1);
insert into orders (idx, product_code, product_cnt) values (2, '00004', 1);
insert into orders (idx, product_code, product_cnt) values (1, '00005', 1);
select * from orders;
# product 테이블에 기본키 추가하기
alter table product add primary key(code);
# orders 테이블에 외래키 추가하기
alter table orders add foreign key(product_code) references product(code) on update cascade on delete cascade;
select * from member;
select * from product;
select * from orders;
# 상품을 최소 2번 이상 구입한 횟수가 있는 회원의 아이디와 이름, 성별을 출력
select idx, count(idx) from orders group by idx; -- 각 회원당 구입 횟수
select idx from orders group by idx having count(idx)>=2;
select userid, name, gender from member where idx in (select idx from orders group by idx having count(idx)>=2);
# 데이터 복사하기
create table orders_new (
no int auto_increment primary key,
idx int not null,
product_code varchar(5) not null,
product_cnt int default 0,
regdate datetime default now(),
foreign key(idx) references member(idx)
);
select * from orders;
insert into orders_new(select * from orders);
select * from orders_new;
create table orders_new_new(select * from orders);
select * from orders_new_new;❇️ 유니온(union)
-
합집합을 나타내는 연산자로 중복된 값을 제거함
-
서로 같은 종류의 테이블(컬럼이 같아야 함)에서만 적용이 가능
select 컬럼1, 컬럼2, ... from 테이블1 union select 컬럼1, 컬럼2, .. from 테이블2
use nodejs;
select * from words;
create table words_new (
eng varchar(50) primary key,
kor varchar(50) not null,
lev int default 1,
regdate datetime default now()
);
insert into words_new values('avocado', '아보카도', 2, now());
insert into words_new values('pineapple', '파인애플', 1, now());
insert into words_new values('peach', '복숭아', 2, now());
select * from words_new;
select eng, kor, lev from words union select eng, kor, lev from words_new;
# words_new에 words에 있는 중복데이터를 삽입
insert into words_new values('cherry', '체리', 2, now());
select eng, kor, lev from words union select eng, kor, lev from words_new;
# 날짜/시간 컬럼은 각 데이터마다 유일하기 때문에 중복 데이터로 취급하지 않음
select eng, kor, lev, regdate from words union select eng, kor, lev, regdate from words_new;
# 중복데이터를 제거하지 않음
select eng, kor, lev from words union all select eng, kor, lev from words_new;| 항목 | UNION | UNION ALL |
|---|---|---|
| 중복 제거 | O (중복 제거함) | X (중복 제거 안 함) |
| 성능 | 느릴 수 있음 (중복 검사) | 빠름 |
| 용도 | 결과를 집합처럼 보고 싶을 때 | 결과를 그대로 합칠 때 |
❇️ 정규화(Normalization)
-
데이터 중복을 줄이고, 이상 현상을 방지하기 위해 테이블 구조를 체계적으로 분해하는 과정
-
이상 현상
- 삽입 이상: 어떤 정보를 추가할 수 없는 문제
- 수정 이상: 정보를 수정할 때 여러 곳을 고쳐야 하는 문제
- 삭제 이상: 데이터를 삭제할 때 의도치 않은 정보도 함께 사라지는 문제-
제1정규형(1NF): 모든 컬럼은 원자값을 가져야 한다.
취미: 게임, 등산 (X) -
제2정규형(2NF): 기본키의 "일부"에만 의존하는 컬럼을 없애야 한다.
"학번, 이름, 과목, 교수"가 존재하는 테이블에서 "학번", "이름"은 중복됨. "이름" 컬럼은 삭제해야 함 -
제3정규형(3NF): 기본키가 아닌 속성끼리도 서로 종속되면 안 됨(이행 함수 종속 제거)
-
제4정규형: 실무에 따라 정규형을 모두 지킬 수 없을 때
-
use nodejs;
select * from member;
create table profile(
idx int not null,
height double,
weight double,
mbti varchar(10),
foreign key(idx) references member(idx)
);
select * from profile;
insert into profile values(1, 160, 50, 'ISTJ');
insert into profile values(3, 170, 70, 'ESTP');
insert into profile values(5, 155, 50, 'ISFP');
-- insert into profile values(6, 180, 80, 'ESFP'); -- 삽입 실패(외래키 제약조건)❇️ 조인(join)
-
정규화에 의해 분해한 테이블의 데이터를 합치는 방법
select 컬럼1, 컬럼2, ... from 테이블1 [inner, left, right] join 테이블2 on 테이블1.컬럼 = 테이블2.컬럼inner: 두 테이블 간의 교집합
left/right: 두 테이블이 조인될 때 왼쪽(기본키) 또는 오른쪽(외래키) 기준으로 데이터를 모두 출력
# inner join
select member.idx, userid, name, gender, mbti from member inner join profile on member.idx = profile.idx;
select m.idx, m.userid, m.name, m.gender, p.mbti from member as m join profile as p on m.idx = p.idx;
# left / right join
select m.idx, m.userid, m.name, m.gender, p.mbti from member as m left join profile as p on m.idx = p.idx;
select m.idx, m.userid, m.name, m.gender, p.mbti from member as m right join profile as p on m.idx = p.idx;❇️ MySQL 사용자 계정
create user '사용자이름'@'호스트' identified by '비밀번호';
호스트: IP(로컬접속의 경우 127.0.0.1 또는 localhost)
권한 적용
grant 권한종류 on 데이터베이스명.테이블명 TO '사용자이름'@'호스트';
모든권한: ALL
(select, insert, update, delete, create, drop, alter, index)
변경된 권한을 적용
flush privileges;
사용자 존재 확인
select user, host from mysql.user;
create user 'apple'@'localhost' identified by '1111';
grant all on nodejs.* to 'apple'@'localhost';
flush privileges;
select user, host from mysql.user;
여기서 MySQL Connections 옆에 있는 + 또는 공구 아이콘 눌러서
Connection Name, Username 작성하고 그랬던 것 같다.
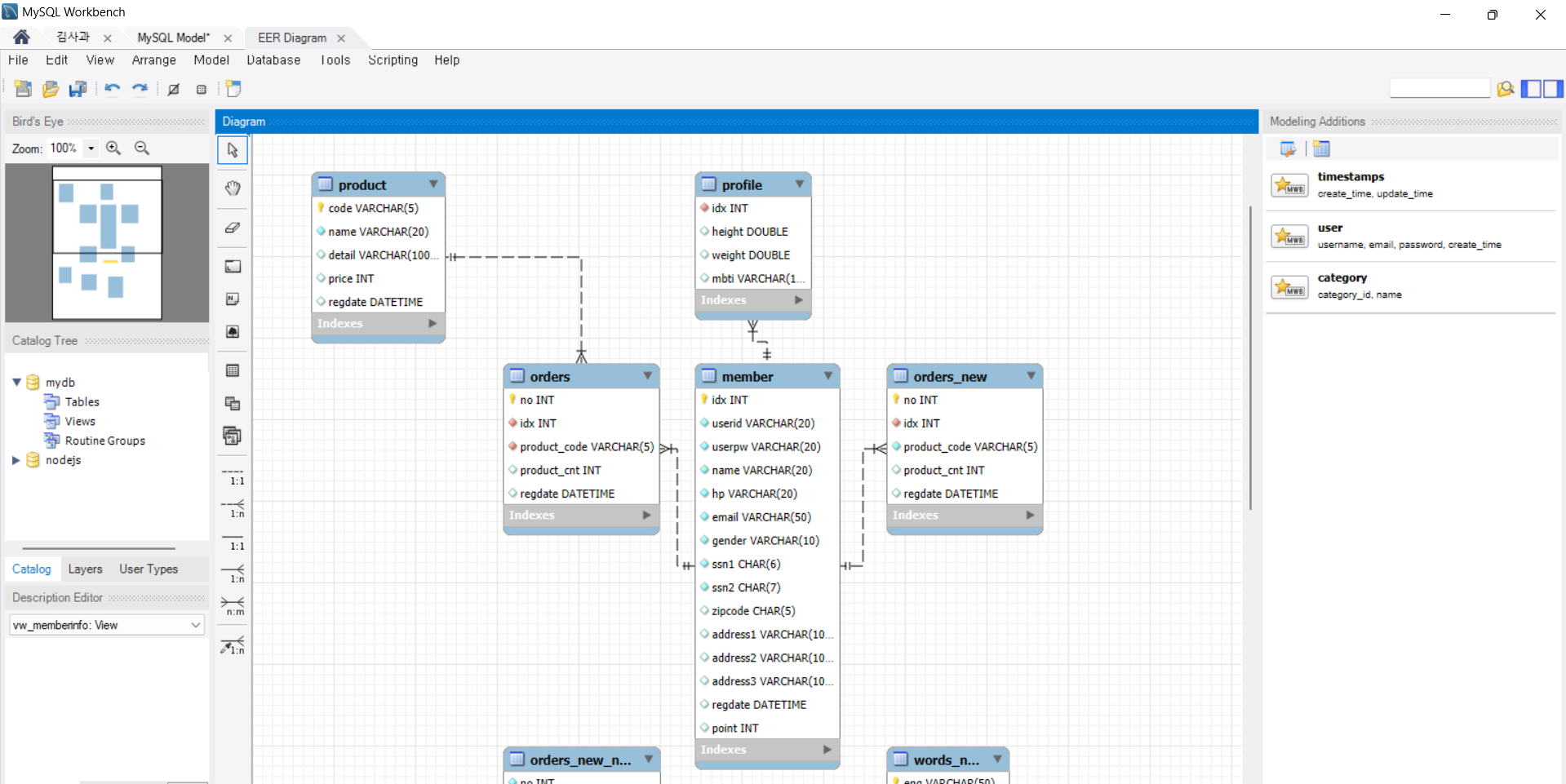
✅ 1. MySQL Workbench 사용하는 방법
📌 MySQL Workbench란?
MySQL에서 공식 제공하는 GUI 툴
ERD 생성 및 편집 기능을 기본적으로 제공함
📌 ERD 확인 방법
MySQL Workbench 실행
좌측 상단에서 Database > Reverse Engineer... 클릭
연결할 데이터베이스 선택
스키마(데이터베이스) 선택
Workbench가 자동으로 테이블 간 관계를 읽고 ERD 생성
시각적으로 테이블과 외래키 관계를 볼 수 있음
🟡 장점: 자동 생성, 관계 시각화, 편집 가능
🔴 단점: 설치 필요