주제: 탑승 위치와 탑승 클래스 별 생존율
가설 1 : 탑승 위치에 따라 생존률이 다를 것이다.
가설 2 : 탑승 클래스에 따라 생존률이 다를 것이다.
가설 1 부터 정리
[타이나닉 탑승 위치 정리]
출항: 영국 사우샘프턴(S) ➡️ 기항: 프랑스 셰르부르(C) ➡️ 아일랜드 퀸즈타운(Q) ➡️ 침몰: 북대서양
#탑승위치 값 확인하기
titanic['Embarked'].value_counts()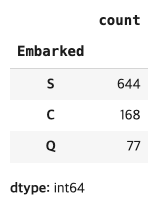
#탑승위치 결측치 확인하기
titanic['Embarked'].info()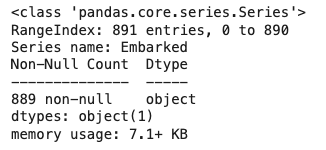
총 데이터 개수: 891개
결측치 2개 dropna 해서 개수 889개
가설 확인
평균 값으로는 탑승 위치 별로 차이가 있는 것을 확인할 수 있었다.
근데 이 값이 진짜 통계적으로 의미가 있는 값인가? 는 다른 문제라고 생각한다.
#탑승위치 별 생존률 구하기
#탑승위치로 그루핑 하기
titanic.groupby('Embarked')['Survived'].mean().round(3) * 100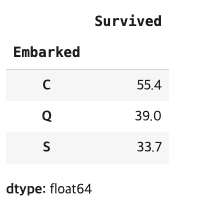
카이제곱 검정 진행하기 (튜터님 조언)
#생존율과 탑승위치의 카이제곱 검정 먼저 진행하기
#라이브세션 강의안 참고
#교차표 만들기 = 교차표란? 두 범주형 변수 간의 모든 조합에 대한 빈도(count)를 보여주는 표
contingency_table = pd.crosstab(titanic['Embarked'], titanic['Survived'])
#카이제곱 검정
from scipy.stats import chi2_contingency
chi2, p_value, df_chi2, expected_frequencies = chi2_contingency(contingency_table)
#결과 도출하기 #분석 단계에서는 p-value로 대체해서 보기 #p-value 써보기
#if p < 0.05:
#print('탑승 위치와 생존률 사이에는 통계적으로 유의한 관계가 있다.')
#else:
#print("탑승 위치와 생존률 사이에 유의미한 관계는 없다.")
#기대 빈도 테이블 확인
print("\n[카이제곱 독립성 검정 결과]")
print(f"카이제곱 통계량 (Chi2 Statistic): {chi2:.3f}")
print(f"자유도 (Degrees of Freedom): {df_chi2}")
print(f"P-value: {p_value:.8f}")
alpha = 0.05
if p_value < alpha:
print("\n✅ 결론: p-value가 0.05보다 작으므로 귀무가설 기각!")
print("→ 탑승 위치와 생존율 사이에 통계적으로 유의미한 관계가 있다.")
else:
print("\n✅ 결론: p-value가 0.05보다 크므로 귀무가설 채택!")
print("→ 탑승위치와 생존율는 독립적이다 (즉, 관계가 없다).")
탑승위치와 생존율에 통계적으로 유의미한 관계가 있다는 것을 확인함
-
그러면 왜
C(프랑스) > Q(아일랜드) > S(영국)순으로 생존율이 다르게 나타났을까? -
다른 두 지역에 비해 프랑스의 생존율이 압도적으로 높은 이유는 무엇일까?
3. 프랑스 승객이 비싼 선실에 탔을 가능성이 높을까?
- 프랑스 승객의 여성와 아이 승객 비율이 높았을까?
3. 프랑스 승객이 비싼 선실에 탔을 가능성이 높을까?
탑승 위치 별 클래스 비율
#탑승 위치 별 클래스 비율 확인하기
(titanic.groupby('Embarked')['Pclass'].value_counts(normalize=True) * 100).round(1)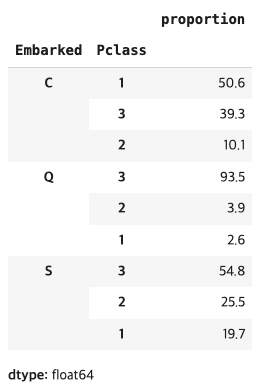
1등석 클래스는 생존률이 제일 높을까?
#클래스 별 생존율 확인하기
(titanic.groupby('Pclass')['Survived'].mean() * 100).round(2)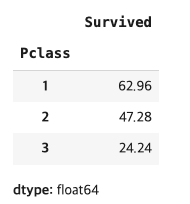
#시각화
import seaborn as sns
import matplotlib.pyplot as plt
sns.barplot(x='Pclass', y='Survived', data=titanic)
plt.title('Survived by Pclass')
plt.ylabel('Survived')
plt.xlabel('Pclass')
plt.ylim(0, 1)
plt.show()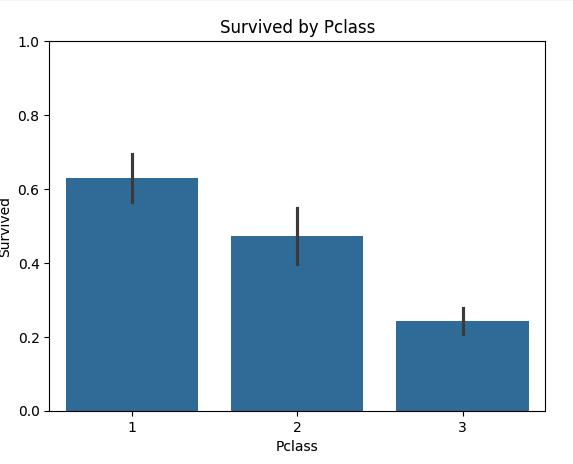
1등 클래스의 생존율이 제일 높다는 것을 확인
프랑스(C)의 생존율(55.4%)이 높다는 것은 확인했는데 아일랜드(Q)에서 탑승한 사람의 93.5%가 3등석에 탑승했는데 왜 생존률이 영국(S)보다 높을까?
클래스+탑승위치 별 생존율을 구해서 통계적으로 분석해보자(둘다 범주형이니까 카이제곱을 써볼까?)
#클래스 별 생존율 확인하기
#검증하기 위해서 탑승위치 + 클래스의 생존률 구해보자
#시각화도 진행하자
titanic.groupby(['Embarked','Pclass'])['Survived'].mean().round(4) * 100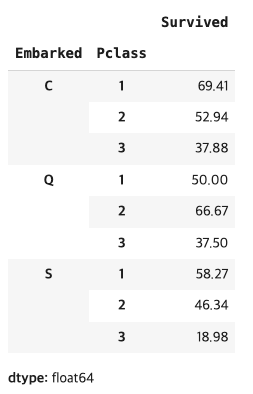
#시각화하기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 생존율 계산 (백분율)
grouped = titanic.groupby(['Embarked', 'Pclass'])['Survived'].mean().round(4) * 100
df_plot = grouped.reset_index() # 시각화를 위해 DataFrame 형태로 변환
# Pclass를 문자열로 변환해서 시각화가 명확하게 되도록 처리
df_plot['Pclass'] = df_plot['Pclass'].astype(str)
# 시각화
plt.figure(figsize=(8, 5))
sns.barplot(data=df_plot, x='Embarked', y='Survived', hue='Pclass', hue_order=['1','2','3'], palette = ['#F0F8FF', '#40E0D0', '#191970'],errorbar=None)
plt.title('Survival_rate_by_Embarked_&_Pclass')
plt.ylabel('Survived')
plt.xlabel('Embarked')
plt.ylim(0, 100)
# 4) 막대 위에 퍼센트 텍스트 표시
for bar in plt.gca().patches:
height = bar.get_height()
if height > 0:
plt.text(
bar.get_x() + bar.get_width() / 2,
height + 1,
f'{height:.1f}%',
ha='center',
va='bottom',
fontsize=10
)
plt.legend(title='Pclass')
plt.tight_layout()
plt.show()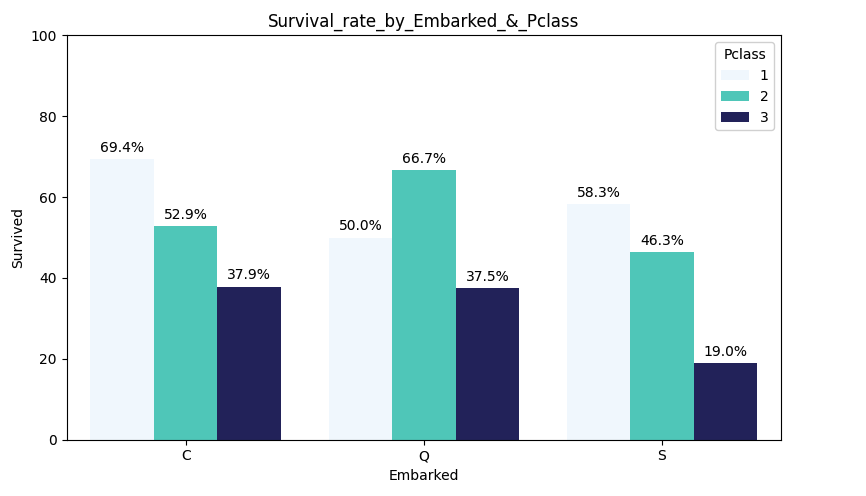
튜터님의 피드백
피드백(07021200)
전체적으로 너무 잘 진행 했어요.... 100점 만점에 110점 입니다!!!
두가지 관점에서 정리해 볼께요.
200점 을 위해
결측치 처리 전략 구체화 Age 컬럼의 결측치(177개)는 데이터의 약 20%를 차지하여 무시하기 어렵습니다. 현재는 결측치를 그대로 두었지만, 만약 예측 모델을 만든다면 반드시 처리해야 합니다.
제안: 단순히 전체 평균/중앙값으로 채우기보다, 더 정교한 방법을 시도해볼 수 있습니다. 예를 들어, 상관관계가 높은 Pclass(선실 등급)나 title(Mr, Master, Miss 등)별로 그룹을 나누어 각 그룹의 중앙값으로 Age를 채우는 방식은 예측의 정확도를 더 높일 수 있습니다.
시각화의 적극적인 활용 Pclass 별 생존율을 barplot으로 확인한 것처럼, 다른 분석 과정에도 시각화를 추가하면 인사이트를 더 명확하게 전달할 수 있습니다.
제안: Embarked와 Pclass와 Survived의 관계를 하나의 그래프로 표현해보세요. Seaborn의 catplot(data=titanic, x='Embarked', col='Pclass', hue='Survived', kind='count') 같은 코드는 각 탑승지별로 어떤 클래스의 승객이 얼마나 탔고, 그중 얼마나 생존했는지를 한눈에 보여줄 수 있습니다.
다음 단계 추천(300점으로 가 봅시다!)
희귀 호칭 그룹화
호칭 vs 생존율 시각화
다중 변수와 결합한 분석 예: Pclass, Sex, title_grouped와 생존율의 관계 분석
나의 인사이트
파이썬이 재밌어졌다. 그리고 어떤 식으로 데이터에 접근해야하는지 확신을 가지게 된 것 같다.
이 데이터는 앞으로의 인사이트를 얻기는 어렵지만 내가 필요할 때 만질 수 있는 데이터로서 연습용으로 충분한 것 같다.
이 가설 검증과 추가 가설 검증이 끝나면 AB test 데이터도 만들어서 인사이트 도출 진행하고 싶다.
