웹데이터
1. BeautifulSoup for web data
BeautifulSoup Basic
✏️입력
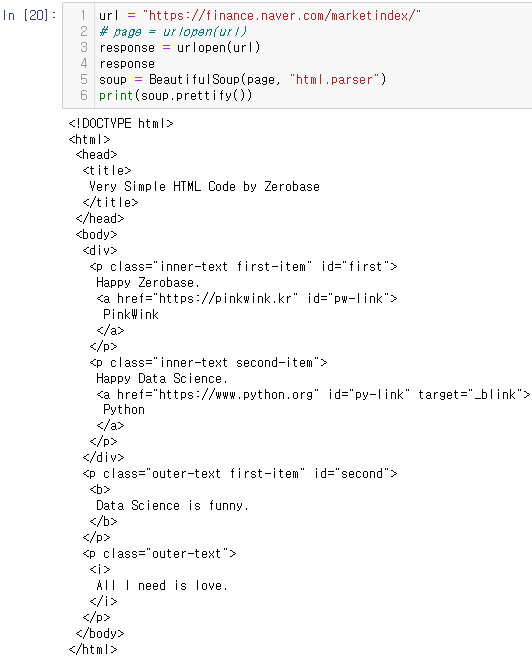
# import from bs4 import BeautifulSoup page = open("../data/03. zerobase.html", "r").read() soup = BeautifulSoup(page, "html.parser") print(soup.prettify()) # html을 들여쓰기로 보기 좋게 하기💻출력
<!DOCTYPE html> <html> <head> <title> Very Simple HTML Code by Zerobase </title> </head> <body> <div> <p class="inner-text first-item" id="first"> Happy Zerobase. <a href="https://pinkwink.kr" id="pw-link"> PinkWink </a> </p> <p class="inner-text second-item"> Happy Data Science. <a href="https://www.python.org" id="py-link" target="_blink"> Python </a> </p> </div> <p class="outer-text first-item" id="second"> <b> Data Science is funny. </b> </p> <p class="outer-text"> <i> All I need is love. </i> </p> </body> </html>
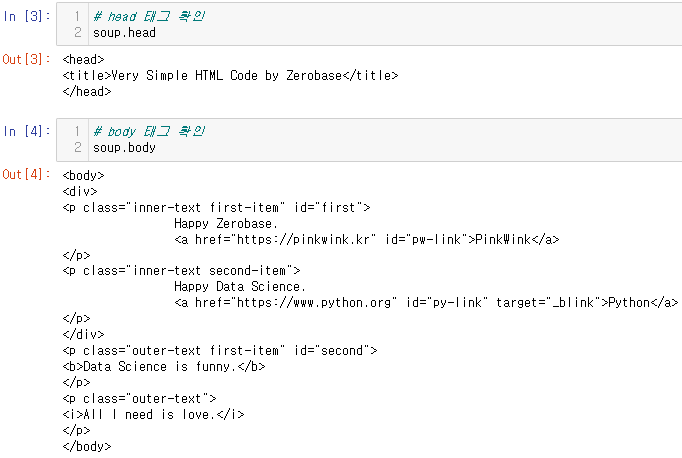
head & body 태그 확인
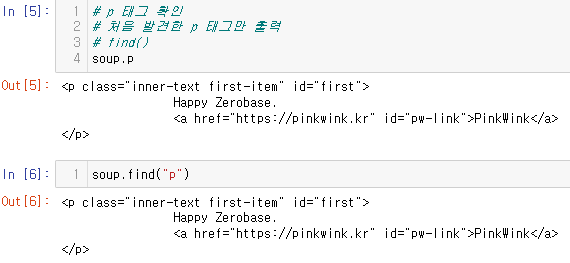
p 태그 확인
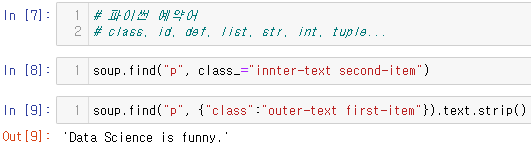
파이썬 예약어랑 겹칠 때 표현
find_all():여러 개의 태그 반환
- 리스트 형태
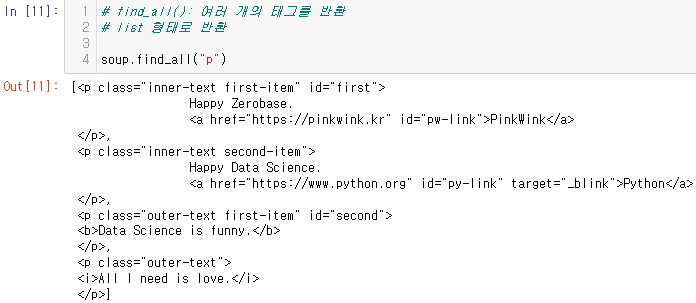
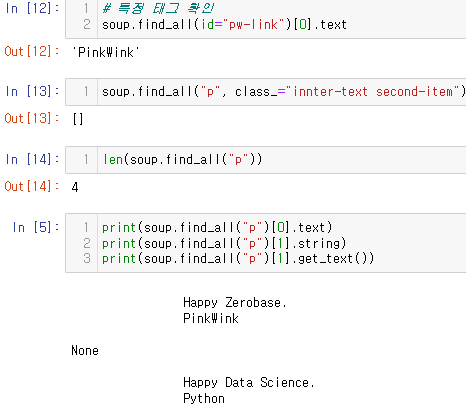
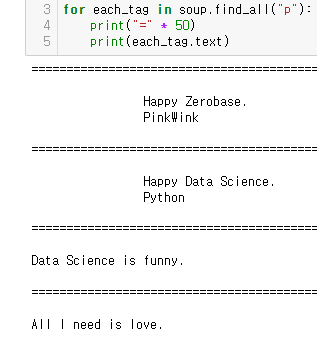
p 태그 리스트에서 텍스트 속성만 출력
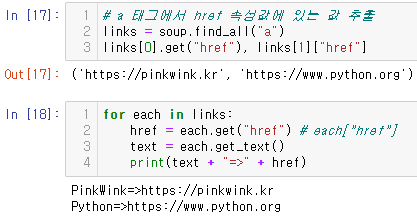
a 태그에서 href 속성값에 있는 값 추출
BeautifulSoup 예제 1-1 - 네이버 금융
# import
from urllib.request import urlopen
from bs4 import BeautifulSouphtml 불러오기
span 태그에 class="value" 값 가져오는 방법
# 1 soup.find_all("span", "value"), len(soup.find_all("span", "value")) # 2 soup.find_all("span", class_="value"), len(soup.find_all("span", "value")) # 3 soup.find_all("span", {"class":"value"}), len(soup.find_all("span", {"class":"value"})) # 텍스트 가져오기 soup.find_all("span", {"class":"value"})[0].text soup.find_all("span", {"class":"value"})[0].string soup.find_all("span", {"class":"value"})[0].get_text()
BeautifulSoup 예제 1-2 - 네이버 금융
- !pip install requests
- find, find_all
- select, select_one
- find, select_one : 단일 선택
- select, find_all : 다중 선택
import requests # from urllib.request.Request from bs4 import BeautifulSoup url = "https://finance.naver.com/marketindex/" response = requests.get(url) # requests.get(), requests.post() # response.text soup = BeautifulSoup(response.text, "html.parser") print(soup.prettify())
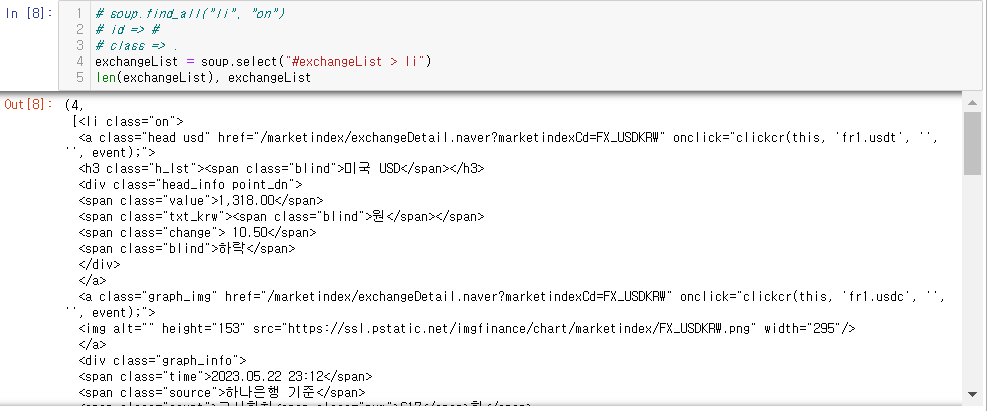
id = "exchangeList" 태그 가져오기
- .select() 이용
- .find_all()일 경우는 # 안에
- 또 다른 방법:
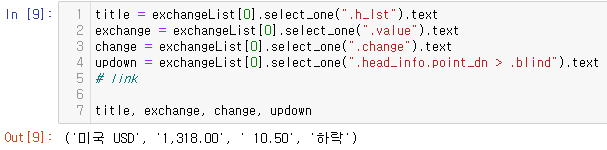
select_one으로 USD 텍스트값 가져오기

base url 준비

4개 금융 데이터 수집
✏️입력
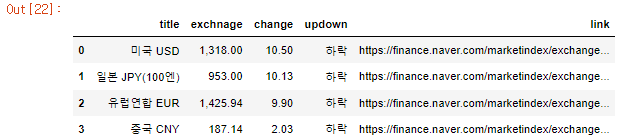
# 4개 데이터 수집 import pandas as pd import warnings warnings.filterwarnings("ignore") exchange_datas = [] baseUrl = "https://finance.naver.com" for item in exchangeList: data = { "title": item.select_one(".h_lst").text, "exchnage": item.select_one(".value").text, "change": item.select_one(".change").text, "updown": item.select_one(".head_info.point_dn > .blind").text, "link": baseUrl + item.select_one("a").get("href") } exchange_datas.append(data) df = pd.DataFrame(exchange_datas) df # df.to_excel("./naverfinance.xlsx", encoding="utf-8")💻출력
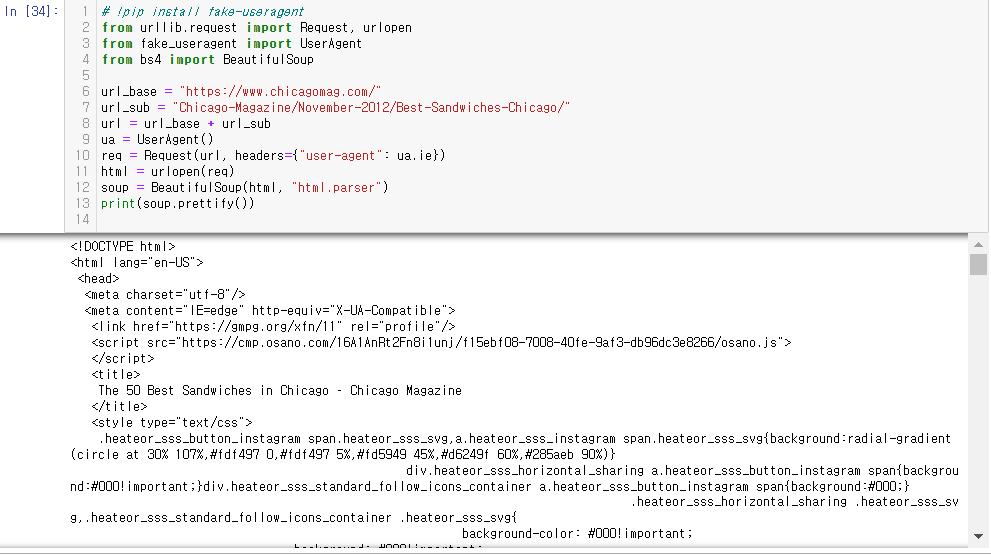
2. 시카고 맛집 데이터 분석 - 개요
- https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/
- chicago magazine the 50 best sandwiches
최종목표
총 51개 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소3. 시카고 맛집 데이터 분석 - 메인페이지
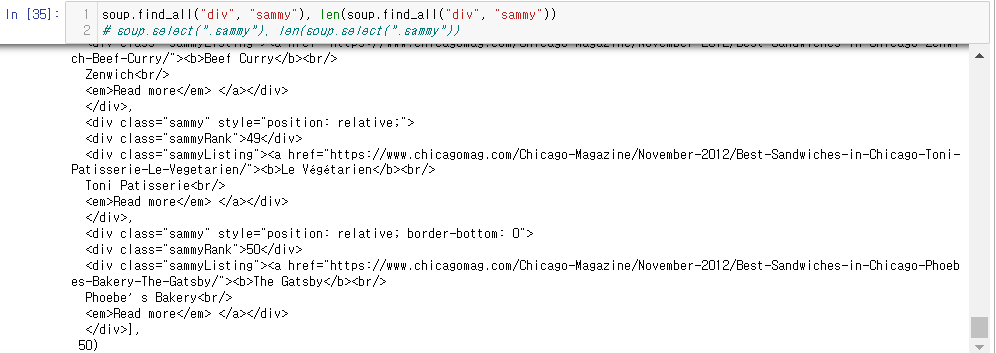
sammy 클래스 태그(50개 가게 데이터) 가져오기
- select 쓸 때는 . 이 클래스 뜻함
sammy 리스트 첫번째 값에서 데이터 추출해보기
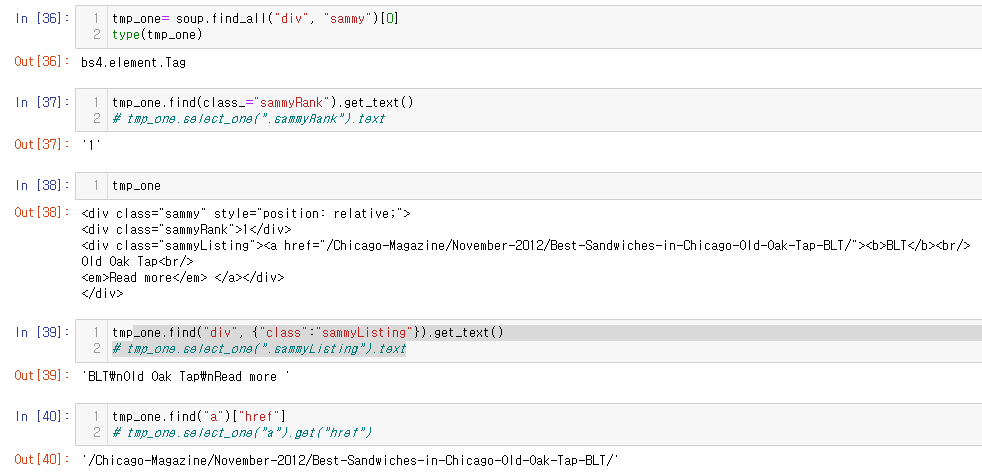
re.split(): 문자열 패턴으로 분리하기
- re 모듈 사용법으로 구분자를 어떻게 쓰는 건지 정확하게 모르겠음. \n|\r\n 이 어떻게 나오는 건지.. 따로 알아보기

반복문으로 순위별 가게 데이터 추출
from urllib.parse import urljoin url_base = "http://www.chicagomag.com" # 필요한 내용을 담을 빈 리스트 # 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정 rank = [] main_menu = [] cafe_name = [] url_add = [] list_soup = soup.find_all("div", "sammy") # soup.select(".sammy") for item in list_soup: rank.append(item.find(class_="sammyRank").get_text()) tmp_string = item.find(class_="sammyListing").get_text() main_menu.append(re.split(("\n|\r\n"), tmp_string)[0]) cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1]) url_add.append(urljoin(url_base, item.find("a")["href"]))
잘 추출됐는 지 확인
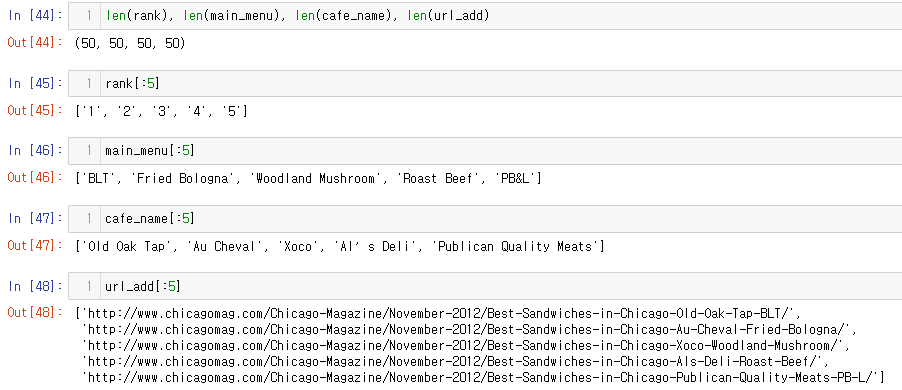
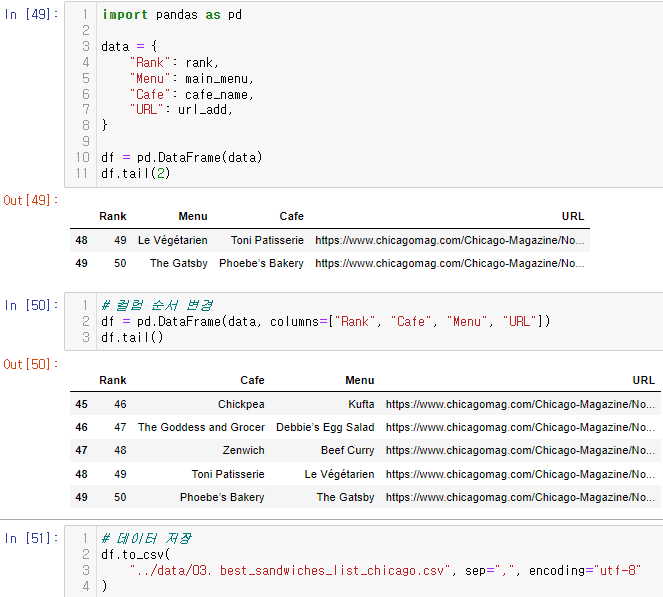
데이터프레임 만들고 저장
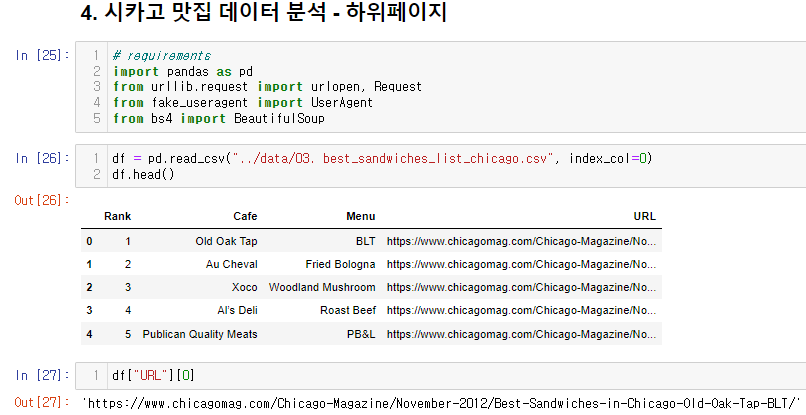
4. 시카고 맛집 데이터 분석 - 하위 페이지
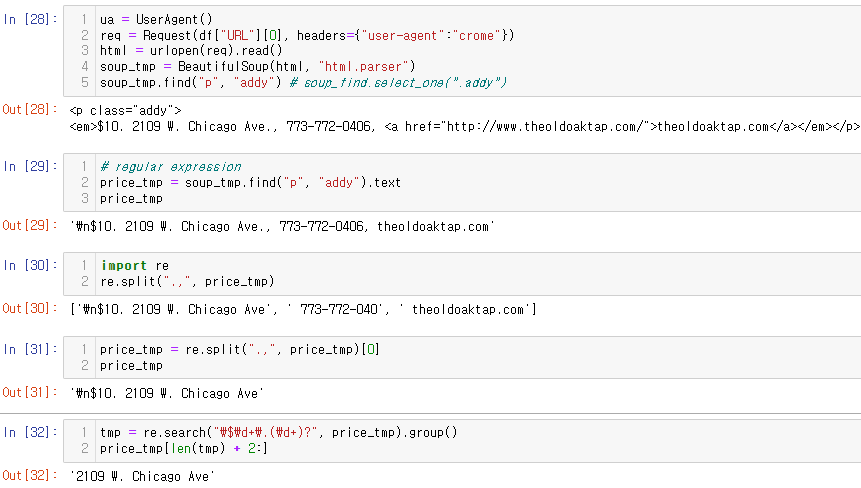
리스트 첫번째 값에서 주소 데이터 추출, 정제해보기
- re.search() / re.group() 정규표현식 관련해서 추가로 학습 필요할 듯..
데이터 제대로 추출됐는 지 확인
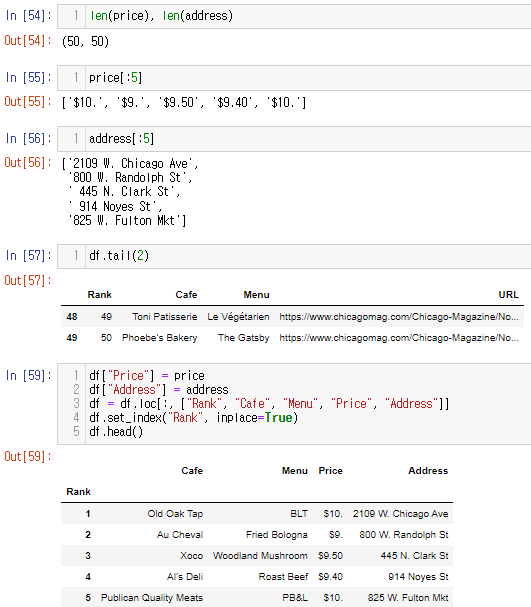
엑셀로 저장, 불러오기
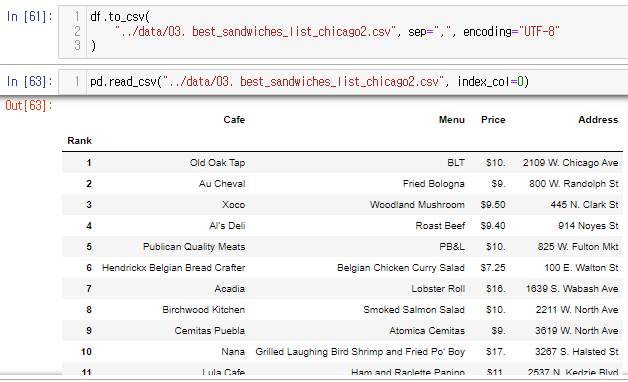
5. 시카고 맛집 데이터 지도 시각화
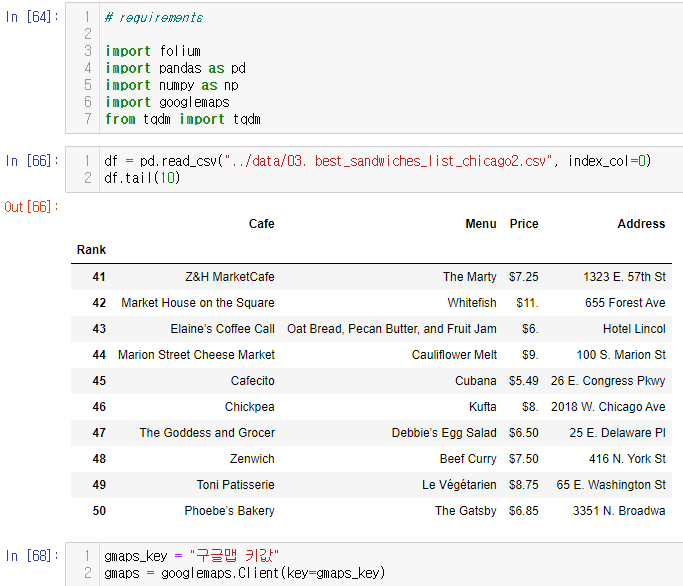
Google Maps로 위도, 경도 추출
- 직접 실습하면서 복습해야 할 듯..
lat = [] lng = [] for idx, row in tqdm(df.iterrows()): if not row["Address"] == "Multiple location": target_name = row["Address"] + ", " + "Chicago" # print(target_name) gmaps_output = gmaps.geocode(target_name) location_output = gmaps_output[0].get("geometry") lat.append(location_output["location"]["lat"]) lng.append(location_output["location"]["lng"]) # location_output = gmaps.output[0] else: lat.append(np.nan) lng.append(np.nan)
리스트에 데이터 잘 담겼나 확인 후에 df에 컬럼 추가
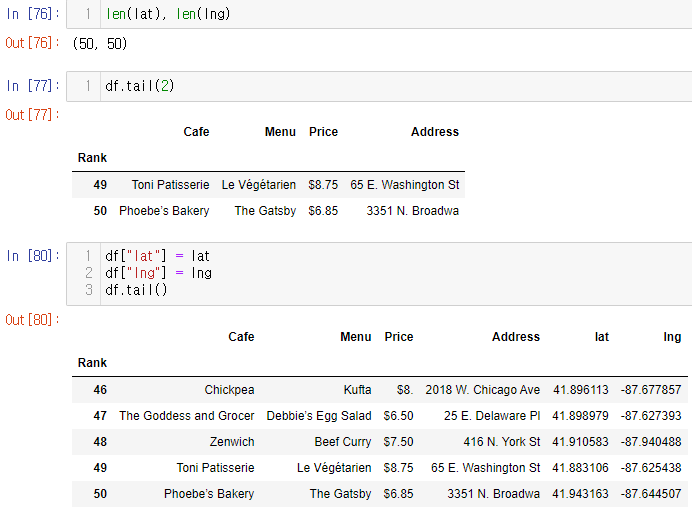
folium
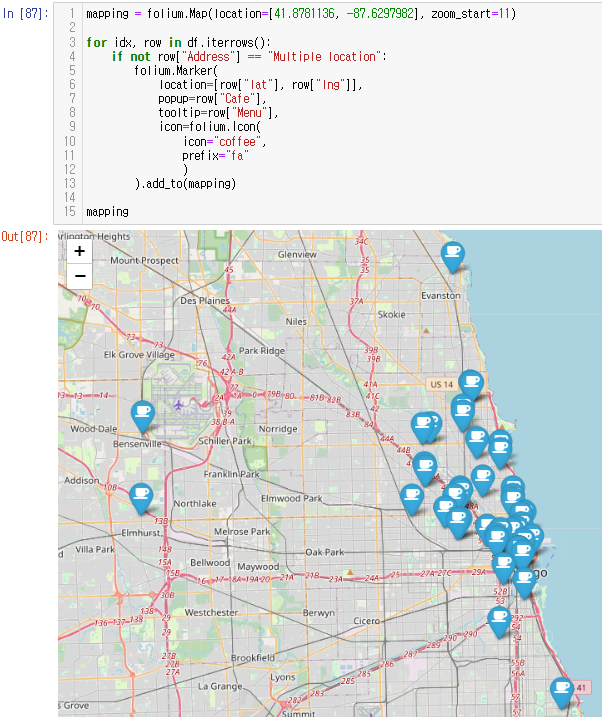
이 글은 제로베이스 데이터 취업 스쿨의 강의자료 일부를 발췌하여 작성되었습니다.

데이터 꿈나물