캐글 따라하기 (House Price Prediction)
먼저 데이터 분석에 필요한 패키지를 불러오겠습니다.
import warnings
warnings.filterwarnings("ignore")
import os
from os.path import join
import pandas as pd
import numpy as np
import missingno as msno
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import KFold, cross_val_score
import xgboost as xgb
import lightgbm as lgb
import matplotlib.pyplot as plt
import seaborn as sns
import re
import glob
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import os
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from keras.callbacks import EarlyStopping
from keras.layers.normalization import BatchNormalization#정규화시켜줌
from keras.layers import Dropout
from keras import regularizers캐글에서 제공한 House Price Prediction 데이터를 불러오겠습니다.
아래 사이트에서 데이터 확인 및 다운 받으면 됩니다.
[https://www.kaggle.com/c/2019-2nd-ml-month-with-kakr/overview]
train_data_path = join('/data', 'train.csv')
test_data_path = join('/data', 'test.csv')
print(train_data_path)
print(test_data_path )
train = pd.read_csv(train_data_path)
test = pd.read_csv(test_data_path)
print(train.shape)
print(test.shape)(15035, 21)
(6468, 20)
전처리 하기
train 데이터는 라벨을 포함하고 있기 때문에 21열이고 test데이터는 라벨을 포함하고 있지 않기 때문에 20열입니다. 우리가 해야할 과제는 train데이터를 통해 데이터를 학습하고 test데이터를 기반으로 예측하여 나온 값으로 label을 찾는 것 입니다.
- 데이터를 보니 ID는 필요없을 것 같고 DATE의 T000부분은 필요없어 보입니다. 아래에서 전처리 하도록하겠습니다.
train.head()
train['date'] = train['date'].apply(lambda x :x[:6]).astype(int)
train.head()
- price는 라벨이기 때문에 분리 해주고 trian에서 삭제합니다.
y=train['price']
del train['price']
print(train.columns)Index(['id', 'date', 'bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot',
'floors', 'waterfront', 'view', 'condition', 'grade', 'sqft_above',
'sqft_basement', 'yr_built', 'yr_renovated', 'zipcode', 'lat', 'long',
'sqft_living15', 'sqft_lot15'],
dtype='object')
- id도 분석을 하는데 있어서 필요없기 때문에 삭제합니다.
del train['id']
print(train.columns)Index(['date', 'bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot', 'floors',
'waterfront', 'view', 'condition', 'grade', 'sqft_above',
'sqft_basement', 'yr_built', 'yr_renovated', 'zipcode', 'lat', 'long',
'sqft_living15', 'sqft_lot15'],
dtype='object')
- test 데이터도 동일한 전처리를 진행합니다.
test['date'] = test['date'].apply(lambda x :x[:6]).astype(int)
del test['id']
print(test.columns)y 라벨 부분 값의 분포를 보니 한쪽으로 치우쳐있는 것을 볼 수 있습니다. 다듬어 주도록 하겠습니다.
sns.kdeplot(y)
plt.show()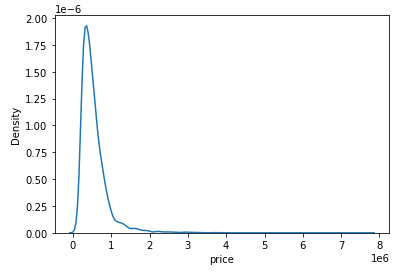
y= np.log1p(y)
y0 12.309987
1 12.100718
2 13.142168
.
.
sns.kdeplot(y)
plt.show()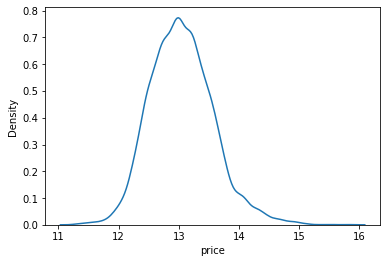
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error캐글의 평가요소인 loss값을 만들어 줍니다.
def rmse(y_test,y_pred):
return np.sqrt(mean_squared_error(np.expm1(y_test),np.expm1(y_pred)))분석에 사용할 모델을 호출합니다.
머신러닝의 분석기법을 이용합니다.
- XGBRegressor
- LGBMRegressor
- GradientBoostingRegressor
- RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressorrandom_state는 모델초기화 랜덤 시드값입니다.
random_state=2020
gboost = GradientBoostingRegressor(random_state=random_state)
xgboost = XGBRegressor(random_state=random_state)
lightgbm = LGBMRegressor(random_state=random_state)
rdforest = RandomForestRegressor(random_state=random_state)
models = [gboost, xgboost, lightgbm, rdforest]df = {}
for model in models:
# 모델 이름 획득
model_name = model.__class__.__name__
# train, test 데이터셋 분리 - 여기에도 random_state를 고정합니다.
X_train, X_test, y_train, y_test = train_test_split(train, y, random_state=random_state, test_size=0.2)
# 모델 학습
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 예측 결과의 rmse값 저장
df[model_name] = rmse(y_test, y_pred)
# data frame에 저장
score_df = pd.DataFrame(df, index=['RMSE']).T.sort_values('RMSE', ascending=False)
df{'GradientBoostingRegressor': 128360.19649691365,
'XGBRegressor': 110318.6704088949,
'LGBMRegressor': 111920.36735892233,
'RandomForestRegressor': 125367.2973747959}
지금까지의 과정을 하나의 함수로 만들겠습니다.
def get_scores(models, train, y):
df = {}
for model in models:
model_name = model.__class__.__name__
X_train, X_test, y_train, y_test = train_test_split(train, y, random_state=random_state, test_size=0.2)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
df[model_name] = rmse(y_test, y_pred)
score_df = pd.DataFrame(df, index=['RMSE']).T.sort_values('RMSE', ascending=False)
get_scores(models, train, y)모델 구축은 했으니 하이퍼 파라미터 수정으로 score를 올리는 일만 남았습니다.
from sklearn.model_selection import GridSearchCVgrid에 탐색을 할 xgboost관련 하이퍼 파라미터를 넣습니다.
param_grid = {'n_estimators':[50,100], 'max_depth' : [1,10],}LGBMRegressor를 사용해서 적용해보겠습니다.
model = LGBMRegressor(random_state = random_state)grid_model = GridSearchCV(model, param_grid=param_grid, \
scoring='neg_mean_squared_error', \
cv=5, verbose=1, n_jobs=5)
grid_model.fit(train, y)grid를 통해 얻은 값은 gridmodel.cv_results에 저장이 됩니다., 그중에 우리는 params 중 테스트 점수 인 mean_test_score값만을 호출하겠습니다. 다른 정보보다는 우리가 보고 싶은 것이 params에 대한 점수니까요
params = grid_model.cv_results_['params']
params[{'max_depth': 1, 'n_estimators': 50},
{'max_depth': 1, 'n_estimators': 100},
{'max_depth': 10, 'n_estimators': 50},
{'max_depth': 10, 'n_estimators': 100}]
score = grid_model.cv_results_['mean_test_score']
scorearray([-0.17974603, -0.17912826, -0.03545062, -0.0352382 ])
results = pd.DataFrame(params)
results['score'] = score
results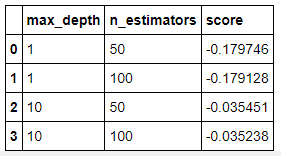
호출한 score값이 음수이기 때문에 양수로 바꿔줍니다. 음수였던 이유는 MSE에 음수 값을 넣어 scoring을 하기 때문입니다.
results['RMSE'] = np.sqrt(-1 * results['score'])
results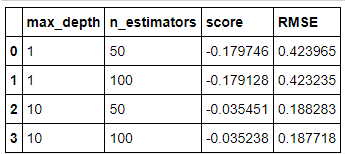
앞에서 y에 log값을 취에 다듬었기 때문에 RMSE값도 log값이 취해진 결과로 나옵니다. 그렇기 때문에 이름을 변경해주겠습니다.
results = results.rename(columns={'RMSE': 'RMSLE'})
results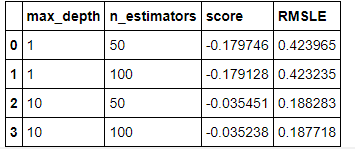
순서를 좋으 순으로 바꿉니다!
results = results.sort_values('RMSLE')
results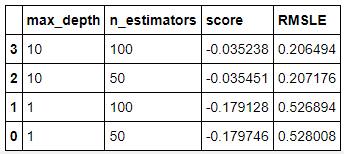
GridSearch 를 통해 알아낸 과정을 하나의 함수로 만듭니다.
def my_GridSearch(model, train, y, param_grid, verbose=2, n_jobs=5):
# GridSearchCV 모델로 초기화
grid_model = GridSearchCV(model, param_grid=param_grid, scoring='neg_mean_squared_error', \
cv=5, verbose=verbose, n_jobs=n_jobs)
# 모델 fitting
grid_model.fit(train, y)
# 결과값 저장
params = grid_model.cv_results_['params']
score = grid_model.cv_results_['mean_test_score']
# 데이터 프레임 생성
results = pd.DataFrame(params)
results['score'] = score
# RMSLE 값 계산 후 정렬
results['RMSLE'] = np.sqrt(-1 * results['score'])
results = results.sort_values('RMSLE')
return resultsparam_grid = {
'n_estimators': [50, 100],
'max_depth': [1, 10],
}
model = LGBMRegressor(random_state=random_state)
my_GridSearch(model, train, y, param_grid, verbose=2, n_jobs=5)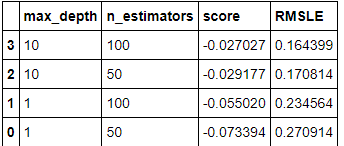
위에서 gird를 통해 얻은 값을 통해 파라미터를 LGBMRegressor에 적용해보겠습니다.
아래 max_depth=20, n_estimators=300로 설정한 이유는 맨 아래 파라미터 값들을 여러번 수정하며 가장 좋은 값을 찾아서 적용했습니다. ㅎㅎ
model = LGBMRegressor(max_depth=20, n_estimators=300, random_state=random_state)
model.fit(train, y)
prediction = model.predict(test)
predictionarray([13.12160458, 13.10226918, 14.15043868, ..., 13.05037436,
12.67158278, 13.01735592])
앞에서 y값에 대해서 진행한 스케일을 되돌립니다
prediction = np.expm1(prediction)
predictionarray([ 499619.74521686, 490052.17258291, 1397838.90879818, ...,
465269.55869982, 318564.30877008, 450157.90324192])
나온 결과를 바탕으로 저장해보겠습니다
data_dir = 'C:/Users/hoo45/Desktop/PythonTech/kaggle-kakr-housing-data/data'
submission_path = join(data_dir, 'sample_submission.csv')
submission = pd.read_csv(submission_path)
submission.head()
submission['price'] = prediction
submission.head()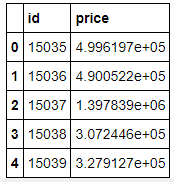
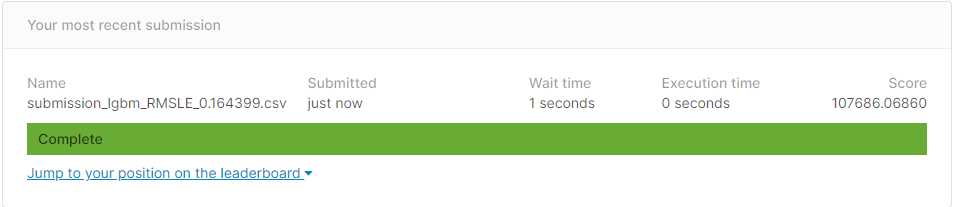
submission_csv_path = '{}/submission_{}_RMSLE_{}.csv'.format(data_dir, 'lgbm', '0.164399')
submission.to_csv(submission_csv_path, index=False)
print(submission_csv_path)SCORE 끝.
아래 코드를 통해 몇번 파라미터를 바꿔봤는데 LGBMRegressor 분석기법이 가장 좋았고 n_estimators, max_depth 를 수정하며 가장 좋은 파라미터 값을 찾아서 제출해보니 바로 통과했네요... 캐글에서 순위로는 45등 정도 합니다.
Keras를 이용해보자!
머신러닝 말고도 딥러닝을 이용해서 예측해 볼 수 있습니다.
RMSE 먼저 정의합니다.
from keras import backend as K
def root_mean_squared_error(y_true, y_pred):
return K.sqrt(K.mean(K.square(y_pred - y_true)))
keras의 dense레이어를 이용하여 분석해보겠습니다.
model=keras.models.Sequential()
model.add(keras.layers.Dense(64, activation='relu',input_shape=[len(X_train.keys())]))
model.add(keras.layers.Dense(128, activation='relu'))
model.add(keras.layers.Dense(64, activation='relu'))
#model.add(BatchNormalization())
model.add(keras.layers.Dense(1))model.compile(loss=root_mean_squared_error,
optimizer='Adam')model.summary()
가장 좋은 부분에서 멈추도록 earlyStopping을 사용했고 적용시켰습니다.
- SE값이 VAL 데이터에서도 250000이상으로 나오는 것으로 볼때 위에서 사용한 머신러닝 알고리즘 보다는 좋지 않은 성능 일 것으로 예상됩니다.
- 닝의 RMSE값을 높이는 방법은 여러가지 있지만 제가 할 수 있는 하이퍼 파라미터 변경, 정규화, drop out 등 사용했지만 데이터가 크지 않아서 단순한게 가장 좋은 모델로 나옵니다.
s=EarlyStopping(monitor='val_loss',mode='min',verbose=1,patience=10)
model.fit(X_train,np.expm1(y_train), epochs=100, batch_size=10,callbacks=[es], validation_data=(X_test, np.expm1(y_test)))
y_pred=model.predict(test)
y_predarray([[ 710453.75],
[ 536851.25],
[1279097. ],
...,
[ 435745.5 ],
[ 356353.44],
[ 479380.62]], dtype=float32)
결과를 바탕으로 저장해서 캐글에 제출해보겠습니다
data_dir = 'data/data'
submission_path = join(data_dir, 'sample_submission.csv')
submission = pd.read_csv(submission_path)
submission.head()
submission['price'] = y_pred
submission.head()
submission_csv_path = '{}/submission_{}_RMSE_{}.csv'.format(data_dir, 'dense', '')
submission.to_csv(submission_csv_path, index=False)
print(submission_csv_path)매우 안.좋..;;

딥러닝보다 머신러닝이 더 좋게 나오는 이유는 무엇일까요?
단순히 제 머리에서 생각한 부분은
- 우리가 분석할 때 사용하는 데이터는 이미 특징을 가지고 있습니다. 즉 머신러닝으로 회귀를 예측할때 이미 전처리해준 특징을 기반으로 결과를 반환하기 때문이라고 할 수 있습니다.
- 반면에 딥러닝은 데이터의 특징을 가지고 분석하기 보다는 스스로 특징을 발견하고 그것을 기반으로 값을 추출합니다. 여기서 사용한 데이터 만으로는 특징을 발견하고 예측하기에는 데이터량이 약간 부족하거나 제 분석기법이 안좋았던것 같습니다..
