구글폼
- 소수를 찾는 코드를 써보고 간단한 설명도 써보자
num = int(input())
def prime(num):
if num < 2:
return False
for i in range(2, num):
if num % i == 0:
return False
return True
print(prime(num))- 분류와 회귀에 대해 설명해본다면?
- 분류: 입력값이 이산적, 범주
- 회귀: 입력값이 연속적, 숫자 데이터
-
과대적합에 대해 설명해본다면?
모델이 훈련 데이터에 너무 과하게 맞춰져서, 테스트 데이터에 대해서는 성능이 떨어지는 현상이다. -
16진수로 변환하는 내장함수는 무엇일까?
hex -
내가 가장 기억에 남는 알고리즘
생략 -
이건 어떤 정렬일까. ???에 들어갈 답은 무엇일까.
data = [8,7,6,2,1]
for i in range(len(data)):
min_idx = i
for j in range(i+1,???):
if data[j] < data[min_idx]:
min_idx = j
data[i], data[min_idx] = data[min_idx], data[i]
print(data)선택 정렬, len(data)
한글 파일 정리
1. 인공지능 개념 정리
1.1 인공지능 학습
- 지도학습: 정답이 있는 데이터를 통해 학습하는 방식. 분류는 범주형 값을 예측한다
- 비지도학습: 정답 없이 데이터 간 숨겨진 구조나 패턴을 찾는 방식.
1.2 KNN 알고리즘: 새로운 데이터 분류에서 가까운 K개 데이터를 활용해 다수결로 판단. 거리 기반 알고리즘 (유클리드 거리 등 사용)
1.3 분류와 회귀 - 분류: 입력값이 이산적, 범주
- 회귀: 입력값이 연속적, 숫자 데이터
1.4 훈련 데이터와 테스트 데이터 - 훈련 데이터: 모델 학습용
- 테스트 데이터: 성능 평가용
- 구분해서 사용함
1.5 과대적합과 과소적합
- 과대적합: 훈련 데이터에 너무 맞춰져 실제 문제에서 성능이 떨어짐
- 과소적합: 학습이 덜 되어 단순한 문제도 제대로 해결하지 못함
1.6 데이터 결측치: 데이터 일부가 빈 상태, 모델 신뢰도 낮아짐
1.7 데이터 전처리: 학습 전 데이터 정리 - 결측치 처리, 이상치 정리, 노이즈 정리, 정규화, 범주형 데이터 변환 포함
- 프로그래밍: 프로그램을 만드는 데 필요한 명령어의 순서를 설계하고, 프로그래밍 언어로 옮겨 실제 프로그램으로 만드는 모든 과정
2. 출력
2.1 출력 규칙
- ' ' 안에 있는 건 문자 취급 -> 숫자 연산이어도 그대로 출력
ex. print('2+3') -> 2+3 출력됨
- 유의사항
print('12'-3)위 코드는 12는 문자, 3은 숫자 데이터인데 12-3으로 표시하게 되면 12가 숫자 데이터인지 문자 데이터인지 구분할 수 없기에 출력시 오류 발생
2.2 연산자
- + : 숫자는 덧셈, 문자는 연결
- , : 데이터 중간에 공백 생김
- : 곱셈
- ** : 거듭제곱
- / : 나눗셈
- // : 나눗셈의 몫
- % : 나눗셈의 나머지
2.3 sep
print(a,b,c, sep=“...”)
결과: I...love...you
2.4 오류 메시지
print 앞에 들여쓰기는 불가능하다.
하게 되면 IndentationError: unexpected indent이라는 오류 메시지가 뜬다.
2.5 n진수 변환
- 2진수: bin -> 0b 꼴 출력
- 8진수: oct -> 0o 꼴 출력
- 16진수: hex -> 0x 꼴 출력
3. 변수
3.1 변수 저장
a=1 : 메모리 공간에 a라는 이름으로 변수를 만들고 이 변수에 10을 저장하라.
4. 조건문
4.1 if의 들여쓰기
if 함수를 쓰다보면 자동으로 들여쓰기가 되는 걸 볼 수 있다. 이는 if 밑에 나오는 조건이 if 산하에 있을 때 들여쓴다고 볼 수 있다. 예를 통해 설명해보겠다.
age = int(input('나이를 입력하세요'))
if age > 19:
print('성인입니다')
else:
print('미성년자입니다')위 코드에서 '성인입니다'를 출력하기 위해서는 19살 초과여야한다는 조건이 먼저 성립되어야 한다. 즉, if의 경우 특정 행동을 할 때 if에 적힌 조건이 전제 된다면 들여쓴다. (포함관계라고 생각하면 조금 더 쉬울 것이라 생각한다.)
4.2 elif와 else
if로만은 모든 조건을 다 표기하기 어렵다. 좀 더 간단한 코딩을 위해 elif와 else를 사용한다. elif의 경우 조건이 여러 가지일 때 if 다음으로 사용하고, else는 위 조건을 제외한 나머지 조건을 말할 때 사용한다.
즉 사용 순서를 정리하면 if -> elif (원하는 만큼) -> else 의 구조라고 할 수 있다.
4.3 기타 유의사항
if, elif, else 모두 각 조건의 끝에 : 를 써야한다.
ex. if i > 1: else:
5. for
5.1 for 함수의 구조
for i in range(a,b,c)라면 a부터 b-1까지의 범위에서 c만큼 증가한다는 것으로, a가 생략되면 0부터 시작하고 c가 생략되면 1씩 증가한다.
case1. 0부터 n-1까지
for i in range(n):
print(i)case2. a부터 b-1까지
for i in range(a, b):
print(i)case3. a부터 b-1까지 n만큼 증감하면서
print(i)- print(i, end=' ')의 의미: i를 출력하고 범위가 끝나면 줄바꿈 대신 공백을 출력한다는 뜻이다. ' '안에 다른 걸 넣으면 다른 문자로 출력된다.
5.2 for 들여쓰기 및 규칙
for도 if와 마찬가지로 작성한 뒤 : 표기 및 들여쓰기가 필요하다.
6. while
6.1 while
조건이 참인 동안 반복해서 실행 후 조건이 거짓되면 반복을 멈춘다. 조건문에 오류가 있으면 계속 반복될 수도 있는 이런 경우 무한 루프 라고 부른다.
a = 1
sum = 0
while sum <= 10:
sum = sum + a
a = a+1
print(sum)6.2 while 들여쓰기 및 규칙
while도 if, for과 마찬가지로 작성한 뒤 : 표기 및 들여쓰기가 필요하다.
6.3 함수 내 변수 재정의
sum=sum+10과 같은 코드는 어떻게 해석해야 할까? 등호 기준 오른쪽 sum은 처음 저장된 값을, 왼쪽 sum은 10이 더해져 업데이트된 값을 의미한다.
6.4 print의 위치에 따른 출력값 차이
sum = 0
for i in range(10) :
sum = sum + 10
print(sum)이 코드의 출력값은
10
20
30
40
50
60
70
80
90
100이다.
sum = 0
for i in range(10) :
sum = sum + 10
print(sum)이 코드의 출력값은 100이다.
7. 배열
7.1 리스트
숫자나 문자 등을 주어진 순서에 따라 저장하는 데이터 타입을 말한다. index는 0번부터 시작한다!!
list = ['권유빈', '권은수', '이민주', '류희진']
list[2] = 이민주7.2 리스트 내 명령어
은근 뭐가 많아요..ㅎㅎ 예시를 보면서 이해하면 좀 더 쉬울 것 같아 다음 리스트를 가지고 설명해볼게요
이 리스트에 대해서 명령어를 적용해볼게요
1. append(항목) : 리스트 마지막에 항목 추가
fruits.append('orange')
print(fruits) #출력값 ['apple', 'banana', 'apple', 'cherry', 'banana', 'orange']- remove(항목) : 리스트의 항목 삭제
fruits.remove('apple')
print(fruits) #출력값 ['banana', 'apple', 'cherry', 'banana', 'orange']
- count(항목) : 특정 항목이 리스트에 몇 개 있는지 개수 셈
print(fruits.count('banana')) #출력값 2- index(항목): 리스트에서 항목이 나타나는 위치 조사 (0번부터 시작)
print(fruits.index('cherry')) #출력값 2- len(list명): 리스트 크기 (리스트 전체 항목 수)
print(len(fruits)) #출력값 5- sort(): 리스트 오름차순 정렬
fruits.sort()
print(fruits) # 출력값 ['apple', 'banana', 'banana', 'cherry', 'orange']- 항목 in list명: 리스트에 항목이 있는가? (True / False로만 판정)
print('apple' in fruits) #출력값 True
print('grape' in fruits) #출력값 False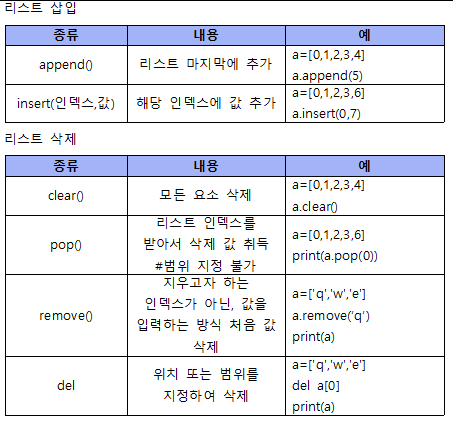
8. 함수
8.1 함수 정의
함수 정의는 def를 사용한다.
def f(x):
y=2*x+1
return y위와 같은 코드를 통해 설명해보자. 우선 def를 통해 새로운 함수 f(x)를 정의했다. 우리는 앞으로 f(x)를 y라고 하기로 약속했어요~ 왜냐하면 return이라는 게 있기 때문! f(x)를 y로 돌려준다(=출력한다)고 이해하면 돼요. 근데 코드 안에 보면 y를 2x+1이라고 정의한 거에요.
복잡해져서 정리하자면 그냥 f(x)를 y=2x+1이라고 정의했다고 이해하면 됩니당
위와 같이 f(x)라는 함수를 정의하면 뭐가 좋냐? y=2x+1 연산을 할 때 이 식을 또 쓰지 않고 사용이 가능해요 (마치 복잡한 함수 치환하는 감성)
result = f(3)
print(result)이걸 실행하면 이제 f(x)에 3을 넣은 값이 자동으로 계산됩니다
8.2 함수에서 사용되는 용어
- 인수: 함수 호출시 넘겨주는 값
- 매개 변수: 인수 전달받기 위해 사용하는 변수
- 반환값: 함수 처리한 결과를 호출한 쪽으로 되돌려주는 값
8.3 함수의 특징
1. 복잡하고 큰 프로그램을 작은 단위의 여러 부분 프로그램으로 나눌 수 있다.
2. 프로그램을 기능 중심으로 단순하고 이해하기 쉽게 표현할 수 있다.
3. 중복되는 부분을 함수로 만들어 반복호출함으로써 코드의 불필요한 중복을 최소화할 수 있다.
4. 프로그램의 크기를 줄일 수 있고 오류 발생시 수정하기가 용이하다.
5. 함수를 재사용함으로써 프로그래밍의 생산성을 높일 수 있다.
9. 정렬과 탐색
9.1 스택
- 데이터가 LIFO(Last In, First Out) 방식으로 저장되고 제거되는 자료구조
- 마지막에 추가된 요소가 가장 먼저 제거
stack = []
stack.append(1) # push
stack.append(2)
print(stack.pop()) # 2 (pop)
print(stack.pop()) # 1 (pop)9.2 큐
- 데이터가 FIFO(First In, First Out) 방식으로 저장되고 제거되는 자료구조
- 처음에 추가된 요소가 가장 먼저 제거
9.3 선택 정렬
- 가장 작은 요소 선택 후 앞에서부터 순서대로 정렬
- 시간 복잡도 O(n^2): 이중 반복문 사용해서
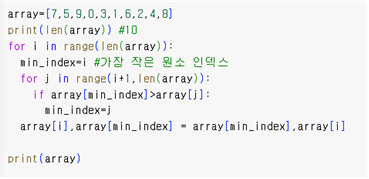
9.4 버블 정렬
- 이웃한 데이터 비교 후 가장 큰 데이터를 가장 뒤로 보내 정렬
9.5 선형 탐색
- 배열이나 리스트 등의 자료구조에서 처음부터 끝까지 순차적으로 탐색
- 데이터 정렬 안되어 있어도 사용 가능
9.6 이진 탐색
- 배열 정렬되어 있어야 한다
- 반씩 나누어 검색. 검색 범위 절반으로 줄여나감
