
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
print(x_train)
print(x_train.shape)tensor([[2., 4.],
[6., 8.]])
tensor([[1., 2.],
[3., 4.]])
tensor([[2., 4.],
[6., 8.]])
tensor([[2., 4.],
[6., 8.]])Cost or Loss
linear regression에선 mean squared error (MSE)함수로 계산함
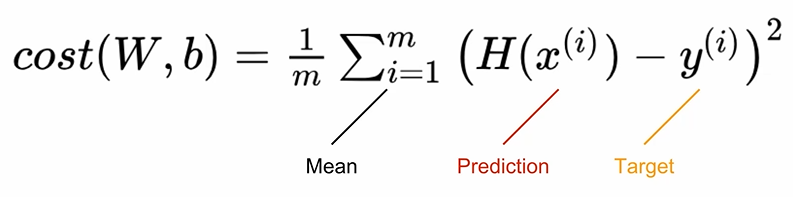
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
hypothesis = x_train * W + bcost = torch.mean((hypothesis - y_train) ** 2)
print(cost)Gradient Descent
optimizer = optim.SGD([W, b], lr=0.01) //3.Optimizer 정의
optimizer.zero_grad() //gradient 초기화
cost.backward() //ackward()로 gragient 계산
optimizer.step() //step()으로 개선Full code
# 데이터 정의
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
# Hypothesis 정의
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 정의
optimizer = optim.SGD([W, b], lr=0.01)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = x_train * W + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} W: {:.3f}, b: {:.3f} Cost: {:.6f}'.format(
epoch, nb_epochs, W.item(), b.item(), cost.item()
))
김효주