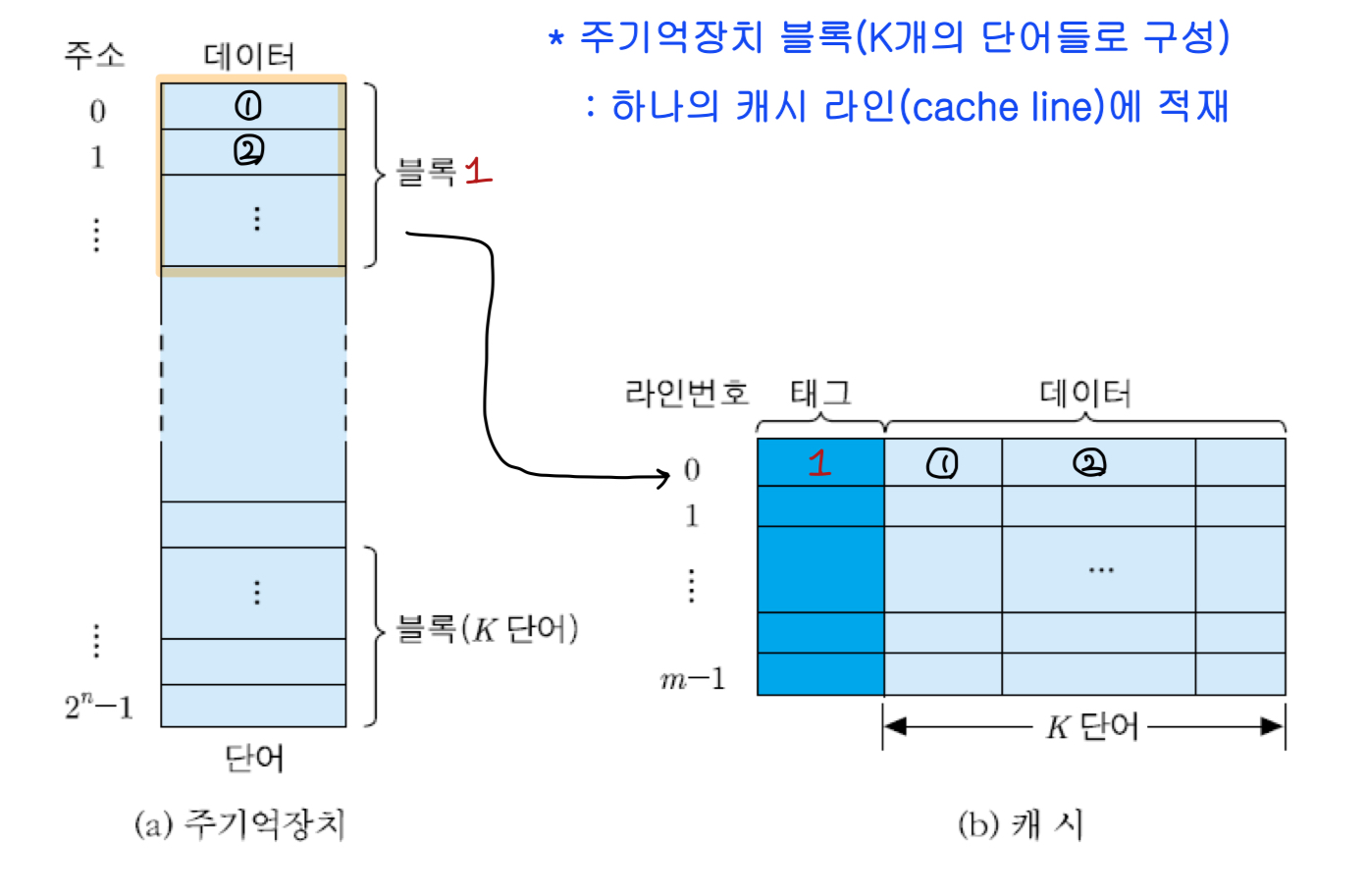
주기억장치와 캐시의 조직
 |  |
|---|
*단어라고 표시되어 있는 것은, 정해지지 않은 용량을 나타낼 때 사용하는 표현이다
블록 : 주기억장치로부터 동시에 인출되는 정보들의 그룹
오른쪽에서 볼 수 있듯이, 몇 개의 주소를 하나의 블록이라는 단위로 묶은 것을 확인할 수 있다. 주기억장치에서 인출할 때, 블록 안의 데이터들이 한 번에 인출되어 캐시로 이동한다.
Q. 주기억장치의 용량이 2^n단어, 블록 = K 단어라면 블록의 수는?
→ 기억장치의 용량 = 주소 개수 x 주소비트 (세로x가로의 개념)
⇒ 그 용량을, K 단어 만큼씩 묶어서 하나의 블록으로 지정한다 했으므로, 2^n / K가 블록의 수가 된다.
라인 : 캐시에서 각 블록이 저장되는 장소
태그 : 라인에 적재된 블록을 구분해주는 정보
직접 사상 (direct mapping)
각 주기억장치의 블록이 하나의 캐시 라인으로만 적재됨

→ 직접 사상 방식의 캐시 구조는 다음과 같다
태그 필드 (t 비트) : 태그 번호 (라인에 적재되어 있는 블록의 번호)
⇒ 캐시의 라인 필드에 적재되어 있는 데이터들(블록)이 주기억장치의 몇 번 블록인지를 나타낸다
라인 필드 (l 비트) : 캐시의 m = 2^l개의 라인들 중 하나를 지정 (m : 캐시 라인 수)
단어 필드 (w 비트) : 각 블록 내 2^w개 단어들을 구분한다.
⇒ 하나의 블록 내에. 여러개의 데이터들이 있는데 그 중에서 무엇을 선택할 지를 나타낸다.
지금은 그렇다 정도로만 알아두고 밑의 예시들을 통해 이해해보자.
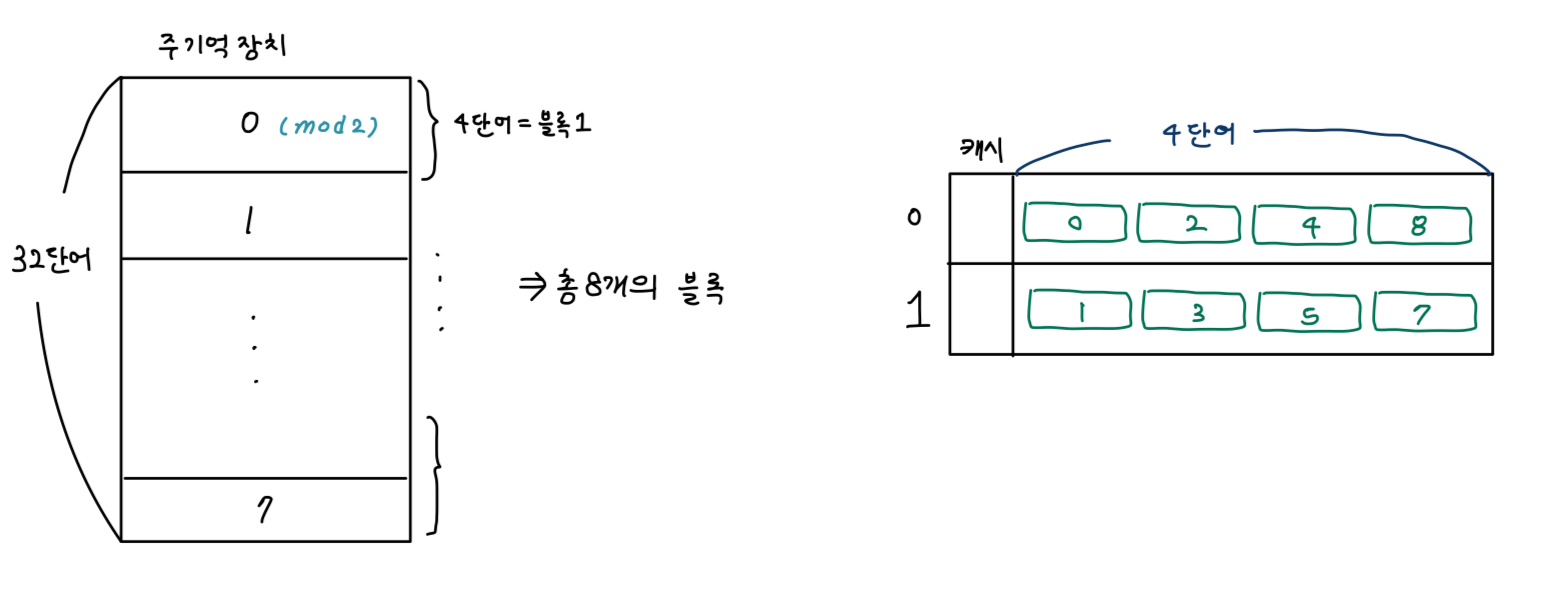
ex) 캐시가 2라인이라고 가정하고, 주기억장치에서는 32개의 단어를 4단어씩 묶어서 하나의 블록으로 둔다고 가정한다
위에서 주기억장치와 캐시의 구조를 얘기할 때 냈던 퀴즈를 떠올려보자
주기억장치에 32개의 단어가 있고, 4개의 단어씩 묶어서 하나의 블록으로 간주한다고 했으니
32/4 = 8로, 총 8개의 블록이 있을 것이다.
직접 사상 방식에서는,
주기억장치의 블록 j가 적재될 수 있는 캐시라인의 번호 i를 계산하는 방법은 다음과 같다
i = j mod m (mod는 나누기 연산을 의미한다)
위의 예시로 다시 한 번 설명하자면, 블록 1번(=j=1)을 캐시 라인 수(=m=2)로 나눈다. 이 값의 나머지 1은 캐시라인의 번호 i가 되고 즉, 위의 그림과 같이 1번 블록은 캐시의 1번 라인에 저장되게 된다.
직접 사상 캐시의 조직 및 동작 원리
(1) l비트의 라인 번호를 이용하여 캐시의 라인을 선택

→ 기억 장치 주소의 라인 비트와 동일한 주소 비트를 가진 부분을 캐시에서 찾는다.
(2) 태그 값 비교

→ 기억 장치 주소의 태그 값과, 캐시 라인의 태그 값을 비교하여, 진짜 원하던 데이터가 맞는지 확인한다.
만약 일치한다면 이는 캐시 적중 (cache hit)이라 부르며, 라인의 단어 필드 값을 이용하여 단어들 중 하나를 인출하여 CPU로 전송한다
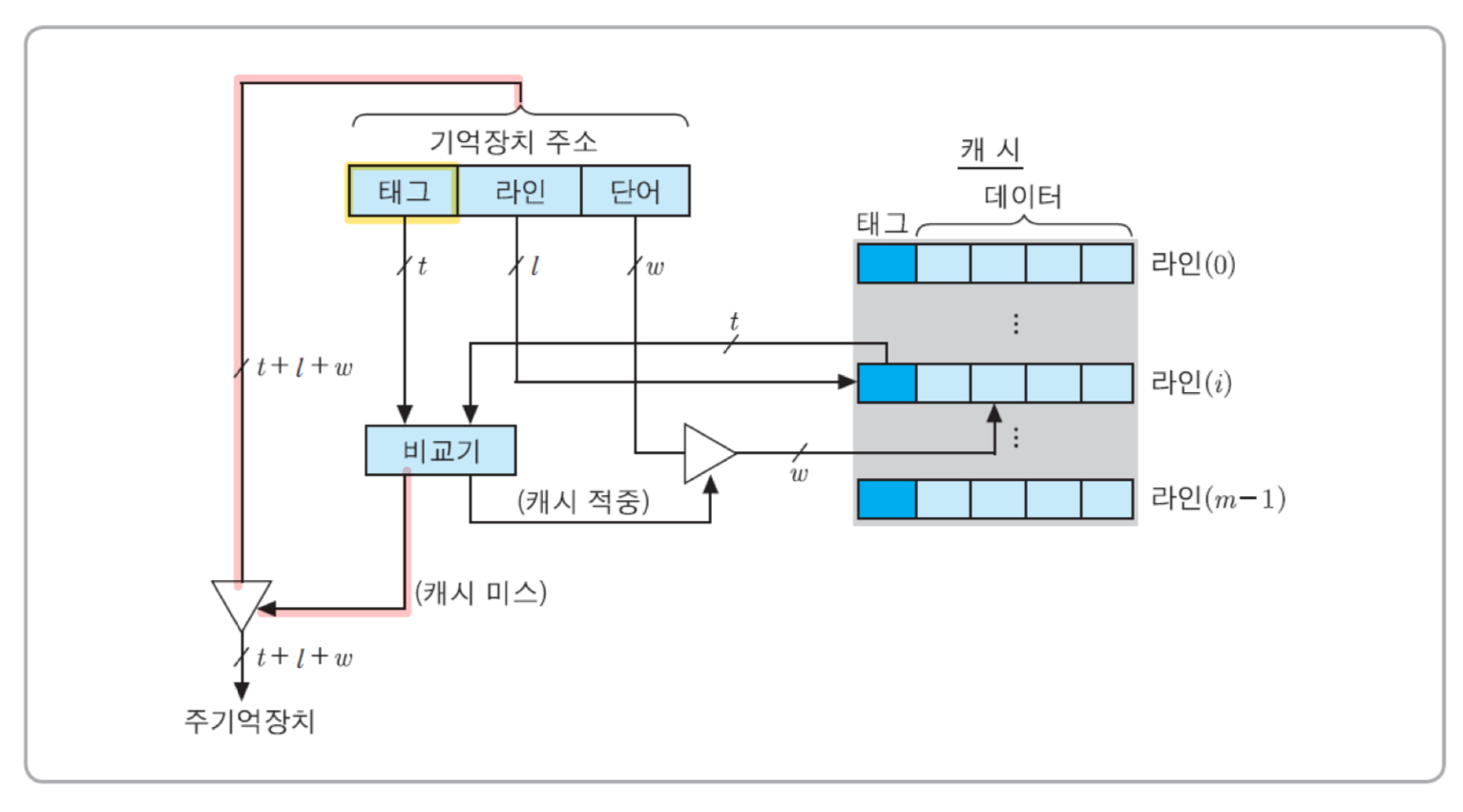
만약 일치하지 않는다면 캐시 미스 (cache miss)라고 부르며, 기억 장치의 주소를 가지고 주기억장치로 가서 해당 데이터를 가지고 다시 들어와서 캐시에 적재한다.
이와 동시에 그 주소의 태그 비트들은 라인의 태그 필드에 기록해야한다.
만약 해당 라인에 이미 다른 데이터가 적재되어 있다면, 덮어쓴다.


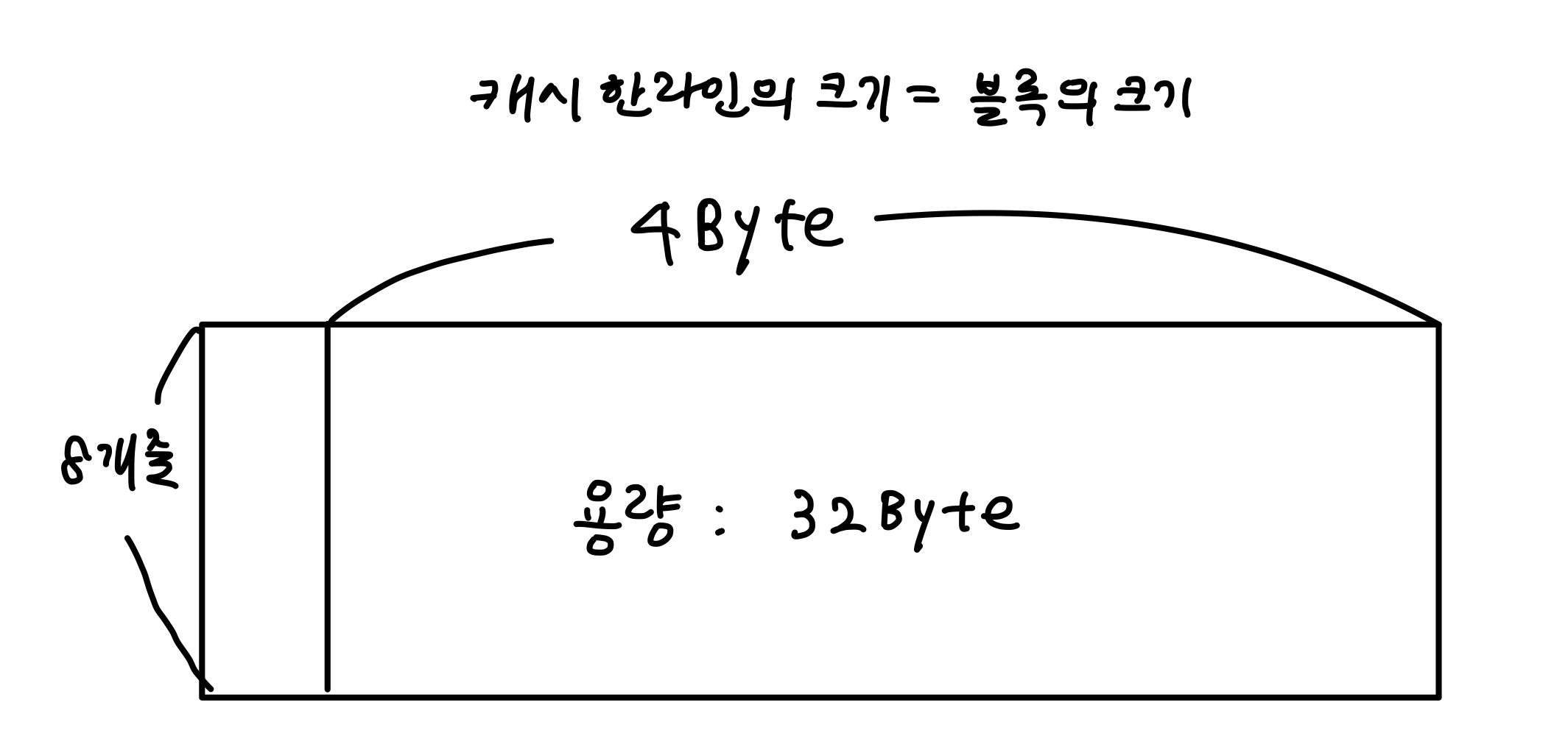
- 풀이 주기억장치의 용량이 2^7 바이트라고 하므로, 가로 폭을 Byte단위로 두면 주소(세로)는 7비트로 구성된다. ⇒ 주소 비트는 7 비트가 필요하다 = 기억 장치 주소 형식은 7비트로 구성되어야 하고, 오른쪽 그림과 같다. 캐시 관련 해설은 다음 그림으로 대체하겠다
직접 사상 캐시에서의 적중 검사 예시

해당 그림에서 데이터 ‘abcd’가 담겨있는 주기억장치의 한 주소는 4단어로 이루어진 한 블록을 축약해서 작성한 것이다.


- 답 1) 캐시 미스 → 2번 라인의 데이터 필드 info, 태그 01 2) 캐시 히트 → 3번 라인에 적재된 상태 3) 캐시 미스 → 5번 라인의 데이터 필드 ‘tech’, 태그 11 4) 캐시 적중 → 6번 라인에 적재된 상태. (단어 필드 값이 10 이므로 ‘c’가 CPU로 읽혀짐)
직접 사상 캐시의 장단점
장) 하드웨어가 간단하고, 구현 비용이 적게 든다.
단) 각 주기억 장치 블록이 적재될 수 있는 캐시 라인이 한 개 뿐이기 때문에, 그 라인을 공유하는 다른 블록이 적재되는 경우에는 overwrite 또는 swap-out된다.
완전 -연관 사상 (fully-associative mapping)
주기억장치 블록이 캐시의 어떤 라인으로든 적재 가능

여기서는 태그 필드 자체가 주기억장치의 블록 번호가 된다.
 |  |
|---|
위에서 보인 직접 사상 방식으로 나타낸 기억 장치 주소 형식을 완전-연관 사상 방식으로 나타내면 오른쪽과 같다.
완전-연관 사상 캐시의 조직

완전-연관 사상 캐시에서의 적중 검사 예

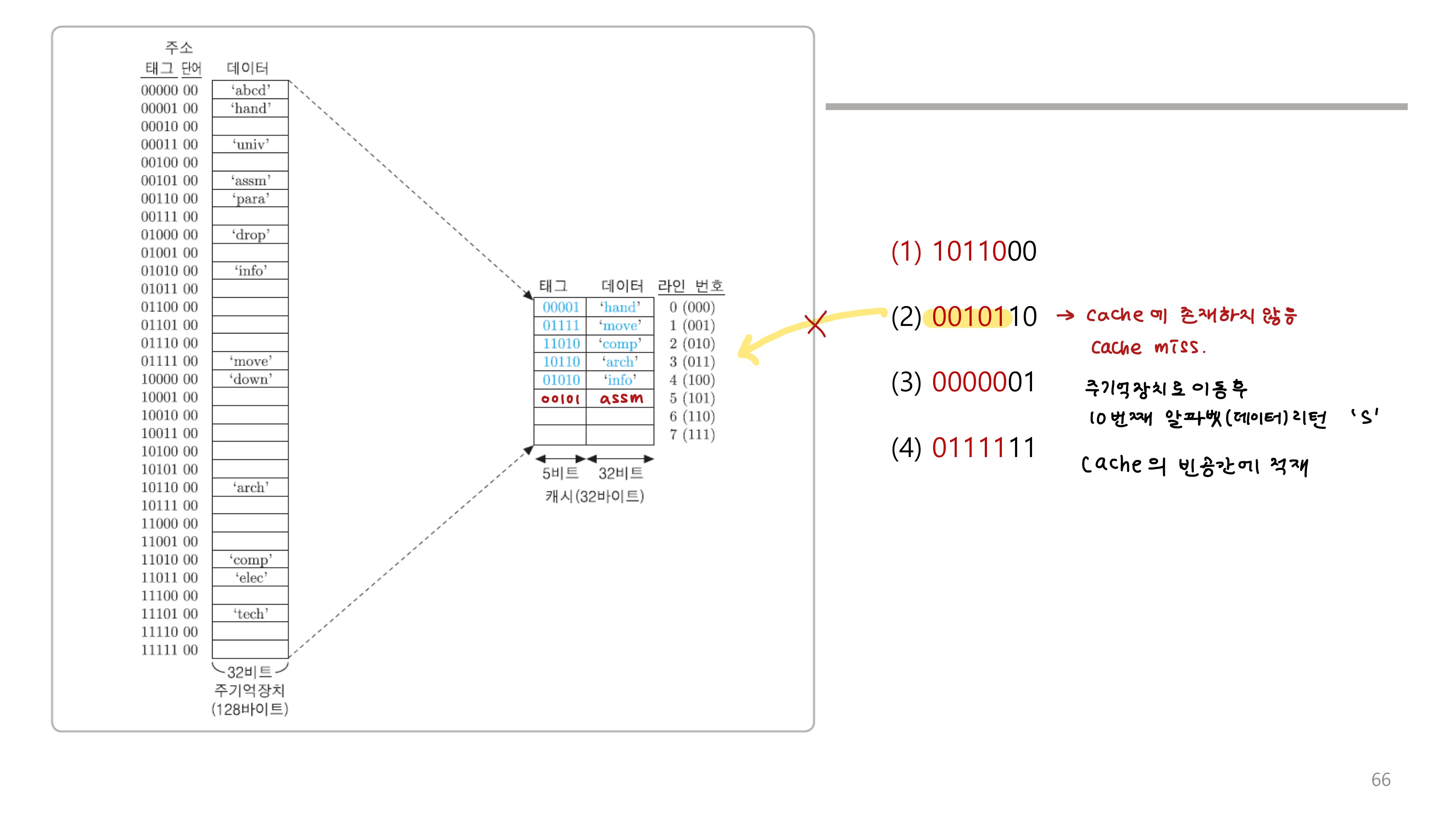
(1) 10110이 캐시의 태그에 있는지 확인한다
(2) 현재 적재되어 있으므로, 캐시 적중상태이다. 단어태그가 1011000 단어 태그가 00이므로 a를 리턴한다
-
캐시 미스의 경우
-
답
(1) 캐시 적중 : 3번 라인에 적재되어 있다
(2) 캐시 미스 : 첫 번째 빈 라인인 5번 라인에 적재된다. assm
(3) 캐시 미스 : 라인 번호 순으로 6번 라이넹 적재된다. abcd
(4) 캐시 적중 : 현재 1번 라인에 적재되어 있다.
완전-연관 사상 캐시의 장단점
장) 새로운 블록이 캐시로 적재될 때 라인의 선택이 매우 자유롭다.
지역성이 높다면, 적중률이 매우 높아진다.
단) 캐시 라인의 태그들을 병렬로 검사하기 위하여 가격이 높은 연관 기억장치 및 복잡한 주변 회로가 필요하다.
