
추석 트래픽
Description
이번 추석에도 시스템 장애가 없는 명절을 보내고 싶은 어피치는 서버를 증설해야 할지 고민이다. 장애 대비용 서버 증설 여부를 결정하기 위해 작년 추석 기간인 9월 15일 로그 데이터를 분석한 후 초당 최대 처리량을 계산해보기로 했다. 초당 최대 처리량은 요청의 응답 완료 여부에 관계없이 임의 시간부터 1초(=1,000밀리초)간 처리하는 요청의 최대 개수를 의미한다.
Input
solution 함수에 전달되는 lines 배열은 N(1 ≦ N ≦ 2,000)개의 로그 문자열로 되어 있으며, 각 로그 문자열마다 요청에 대한 응답완료시간 S와 처리시간 T가 공백으로 구분되어 있다.
응답완료시간 S는 작년 추석인 2016년 9월 15일만 포함하여 고정 길이 2016-09-15 hh:mm:ss.sss 형식으로 되어 있다.
처리시간 T는 0.1s, 0.312s, 2s 와 같이 최대 소수점 셋째 자리까지 기록하며 뒤에는 초 단위를 의미하는 s로 끝난다.
예를 들어, 로그 문자열 2016-09-15 03:10:33.020 0.011s은 2016년 9월 15일 오전 3시 10분 33.010초부터 2016년 9월 15일 오전 3시 10분 33.020초까지 0.011초 동안 처리된 요청을 의미한다. (처리시간은 시작시간과 끝시간을 포함)
서버에는 타임아웃이 3초로 적용되어 있기 때문에 처리시간은 0.001 ≦ T ≦ 3.000이다.
lines 배열은 응답완료시간 S를 기준으로 오름차순 정렬되어 있다.
Output
solution 함수에서는 로그 데이터 lines 배열에 대해 초당 최대 처리량을 리턴한다.
Example
예제1
입력: [
2016-09-15 01:00:04.001 2.0s,
2016-09-15 01:00:07.000 2s
]
출력: 1
예제2
입력: [
2016-09-15 01:00:04.002 2.0s,
2016-09-15 01:00:07.000 2s
]
출력: 2
설명: 처리시간은 시작시간과 끝시간을 포함하므로
첫 번째 로그는 01:00:02.003 ~ 01:00:04.002에서 2초 동안 처리되었으며,
두 번째 로그는 01:00:05.001 ~ 01:00:07.000에서 2초 동안 처리된다.
따라서, 첫 번째 로그가 끝나는 시점과 두 번째 로그가 시작하는 시점의 구간인 01:00:04.002 ~ 01:00:05.001 1초 동안 최대 2개가 된다.
예제3
입력: [
2016-09-15 20:59:57.421 0.351s,
2016-09-15 20:59:58.233 1.181s,
2016-09-15 20:59:58.299 0.8s,
2016-09-15 20:59:58.688 1.041s,
2016-09-15 20:59:59.591 1.412s,
2016-09-15 21:00:00.464 1.466s,
2016-09-15 21:00:00.741 1.581s,
2016-09-15 21:00:00.748 2.31s,
2016-09-15 21:00:00.966 0.381s,
2016-09-15 21:00:02.066 2.62s
]
출력: 7
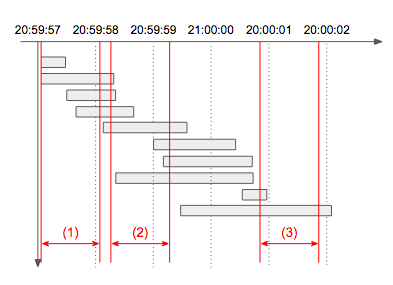
설명: 아래 타임라인 그림에서 빨간색으로 표시된 1초 각 구간의 처리량을 구해보면 (1)은 4개, (2)는 7개, (3)는 2개임을 알 수 있다. 따라서 초당 최대 처리량은 7이 되며, 동일한 최대 처리량을 갖는 1초 구간은 여러 개 존재할 수 있으므로 이 문제에서는 구간이 아닌 개수만 출력한다.
Code
#include <bits/stdc++.h>
using namespace std;
void split_log(string log, vector<pair<int, int> >& log_list){
int l = log.length();
string date = "";
string finish_time = "";
string taken_time = "";
vector<string> s_vec = {};
string s = "";
for(int i=0; i<l; i++){
if(log[i] == ' '){
s_vec.push_back(s);
s = "";
}
else
s+=log[i];
}
finish_time = s_vec[1];
taken_time = s.substr(0, s.length()-1);
vector<string> date_vect = {};
s = "";
for(int i=0; i<finish_time.length(); i++){
if(finish_time[i] == ':'){
date_vect.push_back(s);
s = "";
}
else
s+=finish_time[i];
}
date_vect.push_back(s);
int m_hour = stoi(date_vect[0]) * 1000;
int m_min = stoi(date_vect[1]) * 1000;
s = "";
int m_sec_front;
int m_sec_back;
for(int i = 0; i < date_vect[2].length(); i++){
if(date_vect[2][i] == '.'){
m_sec_front = stoi(s) * 1000;
s="";
}
else
s += date_vect[2][i];
}
m_sec_back = stoi(s);
s = "";
int m_taken_sec_front;
int m_taken_sec_back;
vector<string> divide_dot = {};
for(int i=0; i<taken_time.length(); i++){
if(taken_time[i] == '.'){
divide_dot.push_back(s);
s = "";
}
else
s += taken_time[i];
}
divide_dot.push_back(s);
if(divide_dot.size() == 1){
m_taken_sec_front = stoi(divide_dot[0]) * 1000;
m_taken_sec_back = 0;
}
else{
m_taken_sec_front = stoi(divide_dot[0]) * 1000;
m_taken_sec_back = stoi(divide_dot[1]);
}
int converted_finish_time = m_hour * 3600 + m_min * 60 + m_sec_front + m_sec_back;
int converted_start_time = converted_finish_time - (m_taken_sec_front+m_taken_sec_back) + 1;
log_list.push_back(make_pair(converted_start_time, converted_finish_time));
}
int count_logs(vector<pair<int, int> > log_dict, int time){
int time_end = time + 1000;
int count = 0;
for(auto p : log_dict){
if (!( p.first >= time_end || p.second < time))
count += 1;
}
return count;
}
int solution(vector<string> lines) {
vector<pair<int, int> > log_dict;
int max_count = 0;
for(auto line : lines)
split_log(line, log_dict);
for (auto p: log_dict){
int p_first = count_logs(log_dict, p.first);
int p_second = count_logs(log_dict, p.second);
if(max(p_first, p_second) > max_count)
max_count = max(p_first, p_second);
}
return max_count;
}Thoughts
이 문제는 2017 카카오 신입 공채 1차에서 7번 문제로 5시간에 걸친 긴 시험 시간에 마지막 문제였다.
정답률은 18%였다는 것은 그만큼 난이도가 있으면서 동시에 마지막 문제를 건드리는 사람이 그렇게 많지 않았다는 것 일 수도 있겠지만, 나역시 풀어보면서 굉장히 오래 걸렸다..
문제를 이해하는게 꽤 까다롭고, 이해하고 난 후 어떤식으로 구현할지 사실 막막했다.
문제에서 요구한 것은 1초 동안 처리하는 요청의 최대 개수를 물어봤기 때문에 1초단위로 무엇인가 해야겠다 막연히 생각하고,
주어진 복잡한 string들을 어떻게 파싱해야 좋을지 고민하기 시작했다. 사실 여기까지 걸리는 시간이 꽤걸린다.
다시 한 번 조건을 확인하면 9월 15일 하루의 트래픽에 관심이 있다. 또한 처리되는 데이터들의 처리시간은 0.001 ≦ T ≦ 3.000이다.
적어도 9월 14일 23:59:57.000 과, 9월 16일 00:00:57.001 도 있을 수 있지만 년도와 월 일 정보는 필요가 없겠구나 싶었다.
또 문제에서 가장 강조한 부분이 관심있는 시간단위가 밀리 단위다.
모든 시간 단위를 밀리단위로 바꾸면 시간을 정수로 변환할 수 있다. (이렇게 해석하라고 계속 밀리 단위를 문제에서 보여준건가 싶다)
예를 들어 01:00:04.001 시간이면
(1x1000x3600) + (0x1000x60) + (4x1000+1) = 3600000 + 4001 = 3604001
이런 꼴로 바꿀 수 있고 이런식으로 시작시간, 완료시간을 구할 수 있다.
다음은 그런식으로 주어진 string list들을 구조화 하면, 이제 가장 많은 초당 가장 많은 처리 갯수를 찾아야 한다.
주어진 그림을 유심히 살펴 생각을 했을 때, 어떠한 로그의 시작시간과 완료시간 각각의 1초 구간을 따져보면 구할 수 있을 것이라 판단하여,
각 로그의 (시작시간, 시작시간 + 1), (완료시간, 완료시간 + 1) 구간을 따져서 그안에 다른 로그 기록의 갯수를 새면 가능했다.
정리하자면, 주어진 문자열을 어떻게 효율적으로 파싱해서 원하는 데이터로 변환해줄 것인가,
문제에서 요구하는 시간단위 (밀리초)에 통일되는 단위로 시간을 정수화 해주는 것,
이 정도만 해내면, 그다음 갯수를 찾는 것은 그리 어렵지 않았을 것이다.
다시 한 번 생각해도 문제 자체가 너무 어렵다기보다 문자열을 잘 다룰줄 아는 기본적인 언어 이해도, 문제 해석 능력, 이 부분이 핵심인 것 같다.
결과적 정답률은 마지막 문제였다는 점과, 기본적인 언어 이해도와 문제 해석이 그만큼 어려운 것 같다.
