
모든 내용은 Real MySQL 8.0 1권에서 가져왔습니다!!
8.3.7 B-Tree 인덱스의 가용성과 효율성
8.3.7 B-Tree 인덱스의 가용성과 효율성
쿼리의 WHERE 조건이나 GROUP BY, 또는 ORDER BY 절이 어떤 경우에 인덱스를 사용할 수 있고 어떤 방식으로 사용할 수 있는지 식별할 수 있어야 한다. 그래야만 쿼리의 조건을 최적화하거나 역으로 쿼리에 맞게 인덱스를 최적으로 생성할 수 있다.
8.3.7.1 비교 조건의 종류와 효율성
다중 컬럼 인덱스에서 각 컬럼의 순서와 그 컬럼에 사용된 조건이 동등 비교("=")인지 크다(">") 또는 작다("<") 같은 범위 조건인지에 따라 각 인덱스 컬럼의 활용 형태가 달라지며, 그 효율 또한 달라진다.
SELECT * FROM dept_emp
WHERE dept_no = 'd002' AND emp_no >= 10144;위 쿼리를 위해 아래와 같이 인덱스를 생성했다고 하자.
- 케이스 A: INDEX(dept_no, emp_no)
- 케이스 B: INDEX(emp_no, dept_no)
케이스 A인 경우 dept_no = 'd002' AND emp_no >= 10144인 레코드를 찾고 dept_no가 'd002'가 아닐 때까지 인덱스를 그냥 쭉 읽기만 하면 된다.
하지만 케이스 B인 경우 dept_no = 'd002' AND emp_no >= 10144인 레코드를 찾고, 그 이후 모든 레코드에 대해 dept_no가 'd002'인지 비교하는 과정을 거쳐야 한다.
두 케이스가 무슨 차이가 있는지 아래 그림을 보면서 이해하자.
[Real MySQL 그림 8.17]
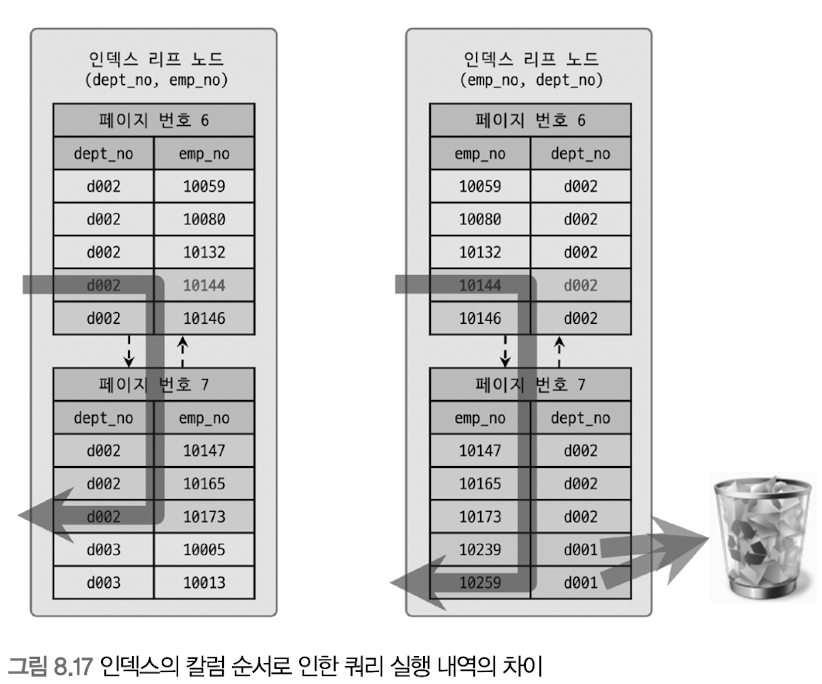
왼쪽(케이스 A)는 정확히 'd002'인 데이터 까지만 읽으면 그 이후론 더 이상 탐색을 하지 않아도 된다.
하지만 오른쪽(케이스 B)는 모든 데이터에 대해 계속 'd002'인지 탐색을 해야 한다. 따라서 읽고 사용되지 않는 데이터가 훨씬 많아질 수 있다.
8.3.7.2 인덱스의 가용성
B-Tree 인덱스의 특징은 왼쪽 값에 기준해 오른쪽 값이 정렬돼 있다는 것이다.
- 케이스 A: INDEX(first_name)
SELECT * FROM employees WHERE first_name LIKE '%mer';위 쿼리는 인덱스 레인지 스캔 방식으로 인덱스를 이용할 수 없다.
- 케이스 B: INDEX(dept_no, emp_no)
SELECT * FROM dept_emp WHERE emp_no >= 10144;위 쿼리도 선행 컬럼인 dept_no 조건 없이 emp_no 값으로만 검색함으로 인덱스를 효율적으로 사용할 수 없다.
