
모든 내용은 Real MySQL 8.0 1권에서 가져왔습니다!!
클러스터링이란 여러 개를 하나로 묶는다는 의미로 주로 사용되는데, 지금 설명하고자 하는 인덱스의 클러스터링도 그 의미를 크게 벗어나지 않는다. MySQL 서버에서 클러스터링은 테이블의 레코드를 비슷한 것(프라이머리 키를 기준으로)들끼리 묶어서 저장하는 형태로 구현되는데, 이는 주로 비슷한 값들을 동시에 조회하는 경우가 많다는 점에 착안한 것이다. MySQL에서 클러스터링 인덱스는 InnoDB 스토리지 엔진에서만 지원하며, 나머지 스토리지 엔진에서는 지원하지 않는다.
8.8.1 클러스터링 인덱스
- 테이블의 프라이머리 키에 대해서만 적용되는 내용
- 프라이머리 키 값이 비슷한 레코드끼리 묶어서 저장하는 것
- 프라이머리 키 값에 의해 레코드의 저장 위치가 겨렂ㅇ됨
- 프라이머리 키 값이 변경되면 그 레코드의 물리적인 저장 위치가 바뀌게 됨
- B-Tree 인덱스도 인덱스 키 값으로 정렬되어 자장되지만 테이블의 레코드가 프라이머리 키 값으로 정렬되어 저장된 경우만 "클러스터링 인덱스" 또는 "클러스터링 테이블"이라고 한다.
[Real MySQL 8.0 그림 8.25]
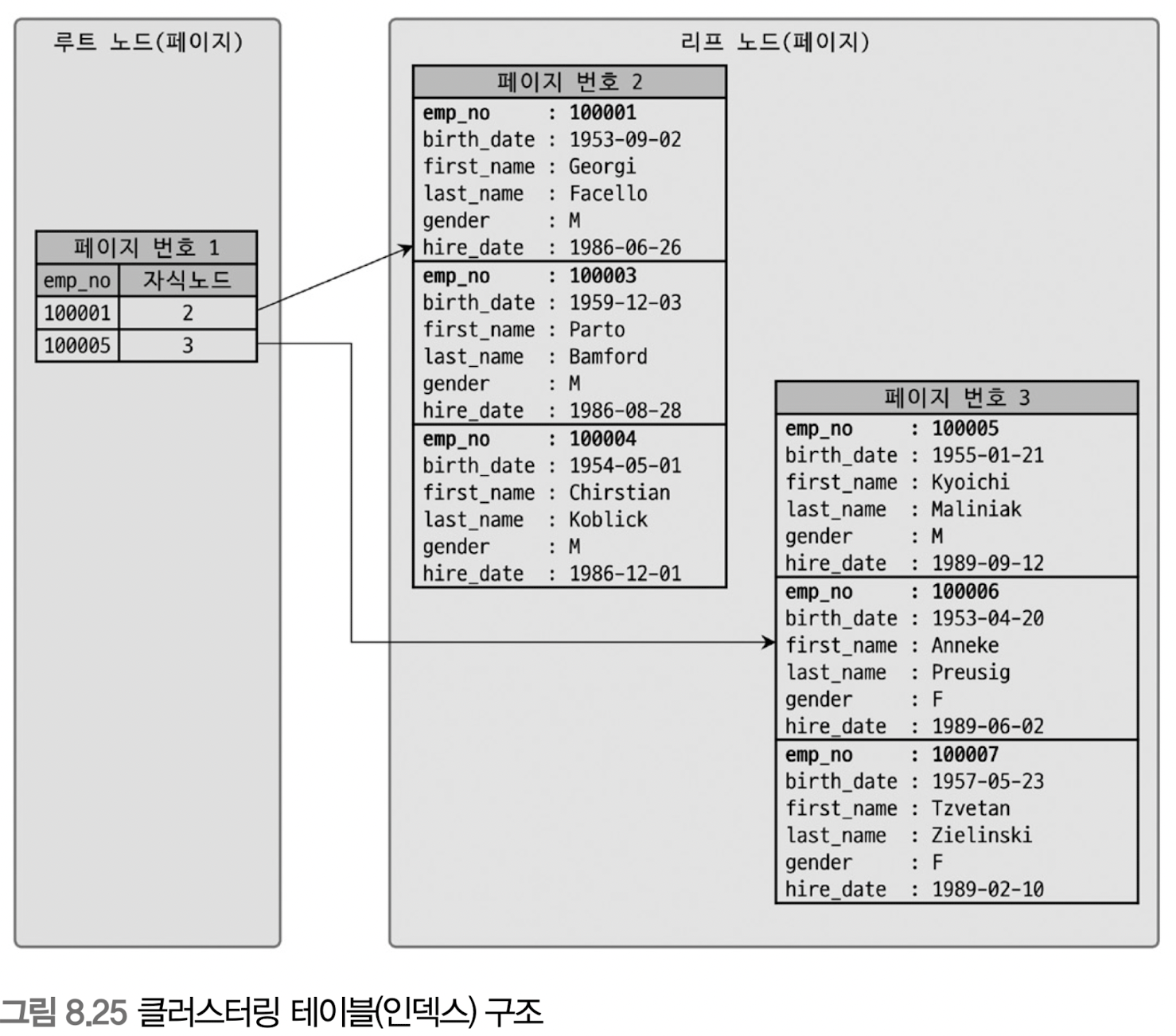
- 클러스터링 테이블 구조 자체는 일반 B-Tree와 비슷하다.
- 하지만 클러스터링 인덱스의 리프 노드에는 레코드의 모든 컬럼이 같이 저장돼 있다.
- 즉, 클러스터링 테이블은 그 자체가 하나의 거대한 인덱스 구조로 관리되는 것이다.
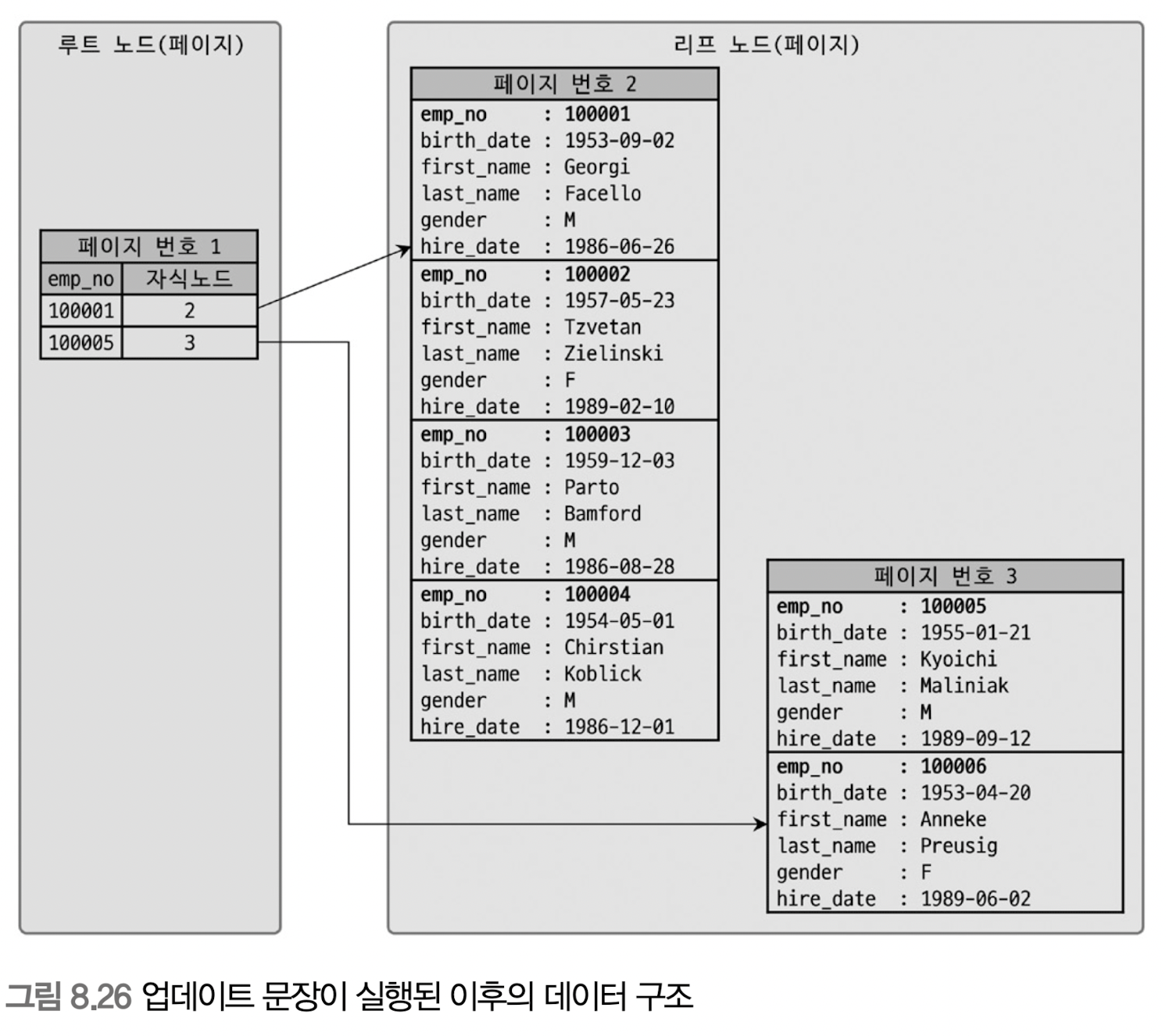
아래와 같이 프라이머리 키(emp_no 컬럼)을 변경하는 문장이 실행되면 클러스터링 테이블의 데이터 레코드엔 어떤 변화가 일어날까?(실제로 프라이머리 키 값이 변경되는 경우는 거의 없다.)
emp_no가 100007인 경우 3번 페이지에 저장되어 있지만 emp_no가 100002로 변경되면서 2번 페이지로 이동하게 된다.
UPDATE tb_test
SET emp_no=100002
WHERE emp_no=100007;[Real MySQL 8.0 그림 8.25]
프라이머리 키가 없는 InnoDB 테이블은 어떻게 클러스터링 테이블로 구성될까? InnoDB는 다음과 같은 규칙으로 프라이머리 키를 대체할 컬럼을 선택하고 클러스터링 테이블을 구성한다.
1. 프라이머리 키가 있으면 기본적으로 프라이머리 키를 클러스터링 키로 선택
2. NOT NULL 옵션의 유니크 인덱스(UNIQUE INDEX) 중에서 첫 번째 인덱스를 클러스터링 키로 선택
3. 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가한 후 클러스터링 키로 선택(자동으로 추가된 프라이머리 키는 사용자에게 노출되지 않는다)
8.8.2 세컨더리 인덱스에 미치는 영향
InnoDB엔진에선 클러스터링 인덱스(테이블) 구조 때문에 모든 세컨더리 인덱스는 해당 레코드가 저장된 주소가 아니라 프라이머리 키 값을 저장하도록 구현되어 있다. 레코드가 저장된 주소를 저장하면 클러스터링 키 값이 변겨될 때마다 데이터 레코드의 주소가 변경되고 이로인해 해당 테이블의 모든 인덱스에 저장된 주소값을 변경해야 한다. 따라서 InnoDB에선 세컨더티 인덱스는 레코드가 저장된 주소가 아니라 프라이머리 키 값을 저장하도록 구현돼 있다.
CREATE TABLE employees (
emp_no INT NOT NULL,
first_name VARCHAR(20) NOT NULL,
PRIMARY KEY (emp_no),
INDEX ix_firstname (first_name)
);SELECT * FROM employees WHERE first_name = "Aamer';InnoDB에선 위 SELECT 쿼리가 실행되면 ix_firstname 인덱스를 검색해 레코드의 프라이머리 키 값을 확인한 후, 프라이머리 키 인덱스를 검색해 최종 레코드를 가져온다.
8.8.3 클러스터링 인덱스의 장점과 단점
장점
- 프라이머리 키(클러스터링 키)로 검색할 때 처리 성능이 매우 빠름(특히 프라이머리 키를 범위 검색하는 경우 매우 빠름)
- 테이블의 모든 세컨더리 인덱스가 프라이머리 키를 가지고 있기 때문에 인덱스만으로 처리될 수 있는 경우가 많음(이를 커버링 인덱스라고 함)
단점
- 테이블의 모든 세컨더리 인덱스가 클러스터링 키를 갖기 때문에 클러스터링 키 값의 크기가 클 경우 전체적으로 인덱스의 크기가 커짐
- 세컨더리 인덱스를 통해 검색할 때 프라이머리 키로 다시 한번 검색해야 하므로 처리 성능이 느림
- INSERT할 때 프라이머리 키에 의해 레코드 저장 위치가 결정되기 때문에 처리 성능이 느림
- 프라이머리 키를 변경할 때 레코드를 DELETE하고 INSERT하는 작업이 필요하기 때문에 처리 성능이 느림
출처
