
1. 주제선정 이유📖
필자는 2018년 12월부터 두 달간 국토연구원에서 연구인턴 생활을 한 적이 있다. 비록 짧은 기간이지만 정말 많은 것을 배울 수 있었던 기간이었으며, 이러한 주제를 생각할 수 있도록 도움을 주신 권영섭 선임연구원님께 이 글을 통해 감사의 말씀을 드린다.
국토연구원에 가기 전에 논문을 써 본 경험이 전무한 것은 아니었다. 인문계열 학부생활을 했었기에 소논문은 자주 써봤음에도 인턴을 하면서 그동안에 쓴 논문은 전혀 체계적이지 못했음을 알게 되었다. 국토연구원에서의 연구는 선행연구 조사부터 체계적으로 이루어졌기에 '나는 여지껏 논문이란 걸 써보긴 한 것일까?'라는 생각을 하게 만들었다.
국토연구원에서의 선행연구 조사를 간단히 설명하면 다음과 같이 이루어졌다. 일단 정해진 연구 주제의 Keyword로 그 단어를 포함한 모든 선행연구를 검색을 하는 것부터 시작한다. 그렇게 뽑아진 선행연구들을 바탕으로 Keyword를 바탕으로 어떠한 선행연구들이 진행되었는지 파악해보고 Word Cloud를 만들어 시각화한다.
그럼 왜 필자는 논문제목 분석을 통한 선행연구 분석이라는 주제로 프로젝트를 진행했는가 하면 매우 중요한 프로세스임에도 불구하고, 그 일련의 과정들이 지극히 수작업이었기 때문이다. 이러한 이유로 이러한 주제로 프로젝트를 하게 되었고, 프로젝트 진행 간에 추가적인 프로세스도 조금 추가(Networkx Part)해주었다.
2.분석 방법 및 절차📑
2-1. 개발환경 구축
VSCode에서 Jupyter Notebook을 통해 Python 개발환경을 구축해서 진행했다. 지정한 Keyword를 포함한 선행연구의 수집을 위해 Crawling 기술을 사용해야 했으며, 이를 위해 selenium, beautifulsoup를 이용하였다. 또한 명사 단위 분석과 그것을 바탕으로 분석 및 시각화를 위해 각각 Konlpy와 Networkx를 사용하였다.
2-2. 데이터 수집🔨
본 Project는 '유동인구'를 Keyword로 설정하고, 이 Keyword를 온전히 포함하는 논문을 DBpia(Base url)에서 Crawling해서 데이터를 수집했다.
Code를 실행시키면 자동으로 DBpia에 접속하여 설정한 기간 내에서 지정한 단어를 포함한 논문들을 찾아 논문별 제목, 저자, 출판사, 저널명, 볼륨, 날짜, 초록을 Dataframe으로 만들어 CSV 파일 형식으로 저장해준다.
사용 Library🧰
Crawling 부분 코드를 보기 전에 사용한 library를 보면 다음과 같다.
# 사용한 Library
import numpy as np
import pandas as pd
import networkx as nx
from __future__ import division
from networkx.utils import random_state
import sys
import re
import xlrd
from konlpy.tag import Komoran
from konlpy.utils import pprint
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import requests
import urllib.request
from selenium import webdriver
import datetime
import os
import getpass
from decorator import decorator
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import csv
import time
from collections import Counter
from wordcloud import WordCloud
from math import log
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
from sklearn.cluster import MiniBatchKMeans
from matplotlib import font_manager, rc
import plotly.offline as py
import plotly.graph_objects as go
from sklearn.manifold import TSNE
from future.utils import iteritemsCrawling🕸
Crawling을 위해 구현한 코드는 다음과 같다.
(단 2021.08.17 기준으로 정상적인 작동이 안 될 것이므로, 이를 참고하여 사용해야한다면 코드 수정이 필요할 것이다. Project를 마치고 얼마 되지 않아 DBpia가 홈페이지 개편을 하면서 Xpath들의 변동이 생겼다.)
Keyword와 논문 개시 기간을 설정해주고 아래의 코드를 실행하면 Chrome창이 열리면서 자동으로 필요한 것들(제목, 저자, 출판된 곳, 저널명, 분량, 출판일, 다운로드수, 인용수, 요약 내용)을 뽑아와 DataFrame로 만들고 CSV로 저장해준다.
# Scraping(Crawling)
searchQ = "유동인구" # keyword input
startYear = 2000 # startyear input
endYear = 2021 # endyear input
print("start crawling..")
path = 'C:/chromedriver.exe'
driver = webdriver.Chrome(path)
xpath = driver.find_element_by_xpath
# Search
driver.get('https://www.dbpia.co.kr/')
keyword = driver.find_element_by_id('keyword')
keyword.clear()
keyword.send_keys(searchQ)
serach_click_btn = xpath("//*[@id='bnHead']/div[4]/div[6]/div[1]/div[1]/a")
driver.execute_script("arguments[0].click();",serach_click_btn)
# 날짜 지정 및 체크박스 설정
xpath("//*[@id='dev_sartYY']").send_keys(startYear)
xpath("//*[@id='dev_endYY']").send_keys(endYear)
click_btn = xpath("//*[@id='sidebar']/form/div[3]/div/div[1]/ul/li[4]/p/button")
driver.execute_script("arguments[0].click();",click_btn)
for i in range(1):
time.sleep(0.5)
try:
btn = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//*[@id='pub_check_sort3_0']")))
driver.execute_script("arguments[0].click()",btn)
btn2 = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//*[@id='pub_check_sort3_1']")))
driver.execute_script("arguments[0].click()",btn2)
except:
print('retry')
time.sleep(1)
# 더보기
wCount = 0
while(True):
time.sleep(1)
try:
more = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//*[@id='contents']/div[2]/div[3]/div[3]/div[3]/div/a")))
driver.execute_script("arguments[0].click()",more)
except:
print('retry')
break
wCount += 1
print(" + page [{}]".format(wCount))
items_source = driver.page_source
soup = BeautifulSoup(items_source, 'html.parser')
items = soup.find('div','searchListArea').find('div','listBody').find('ul').find_all('li', 'item')
# 논문제목, 저자, 퍼블리셔, 저널명,볼륨,날짜, 초록
titleL = []
authorL = []
authorsL = []
publisherL = []
journalL = []
volumeL = []
dateL = []
use_countL = []
quotation_countL = []
abstractL = []
tLen = len(items)
print("start parsing")
iCount = 0
for item in items :
iCount += 1
if iCount % 20 == 0:
print(" parsing.. [{}/{}]".format(iCount, tLen))
title = ''
try : title = item.find('div','titWrap').find('a').text
except : title = ''
author = ''
try : author = item.find('li','author').text
except : author = ''
authors = ''
try : authors = item.find('li','author').find('input')['value']
except : authors = ''
publisher = ''
try : publisher = item.find('li','publisher').text
except : publisher = ''
journal = ''
try : journal = item.find('li','journal').text
except : journal = ''
volume = ''
try : volume = item.find('li','volume').text
except : volume = ''
date = ''
try : date = item.find('li','date').text
except : date = ''
use_count = ''
try : use_count = xpath('//*[@id="#pub_modalUsageChart"]/span').text
except : use_count = ''
quotation_count = ''
try : quotation_count = xpath('//*[@id="#pub_modalQuoteChart"]/span').text
except : quotation_count = ''
abstract = ''
baseDetailUrl = "https://www.dbpia.co.kr"
pUrl = ''
try : pUrl = item.find('div','titWrap').find('a')['href']
except : pUrl = ''
if (pUrl != ''):
pUrl = baseDetailUrl + pUrl
driver.get(pUrl)
try : driver.find_element_by_xpath('//*[@id="#pub_modalOrganPop"]').click()
except : pass
time.sleep(0.1)
try : driver.find_element_by_xpath('//*[@id="#pub_modalLoginPop"]').click()
except : pass
try :
driver.find_element_by_xpath('//*[@id="pub_abstract"]/div[2]/div/div[1]/div[2]/a').click()
eachPage = driver.page_source
ePsoup = BeautifulSoup(eachPage, 'html.parser')
abstract = ePsoup.find('div','abstFull').find('p','article').text
except : abstract = ''
titleL.append(title)
authorL.append(author)
authorsL.append(authors)
publisherL.append(publisher)
journalL.append(journal)
volumeL.append(volume)
dateL.append(date)
use_countL.append(use_count)
quotation_countL.append(quotation_count)
abstractL.append(abstract)
print("date to .csv file")
resultDict = dict(title = titleL,
author = authorL,
publisher = publisherL,
journal = journalL,
volume = volumeL,
date = dateL,
use_count = use_countL,
quotation_count = quotation_countL,
abstract = abstractL)
fName = "{}_{}_{}.csv".format(searchQ, startYear, endYear)
DB = pd.DataFrame(resultDict)
# 유동인구가 들어가지 않는 행 제거
DB_contains = DB['title'].str.contains("유동인구")
DB = DB[DB_contains]
# csv로 저장
DB.to_csv(fName)2-3. 데이터 분석📝
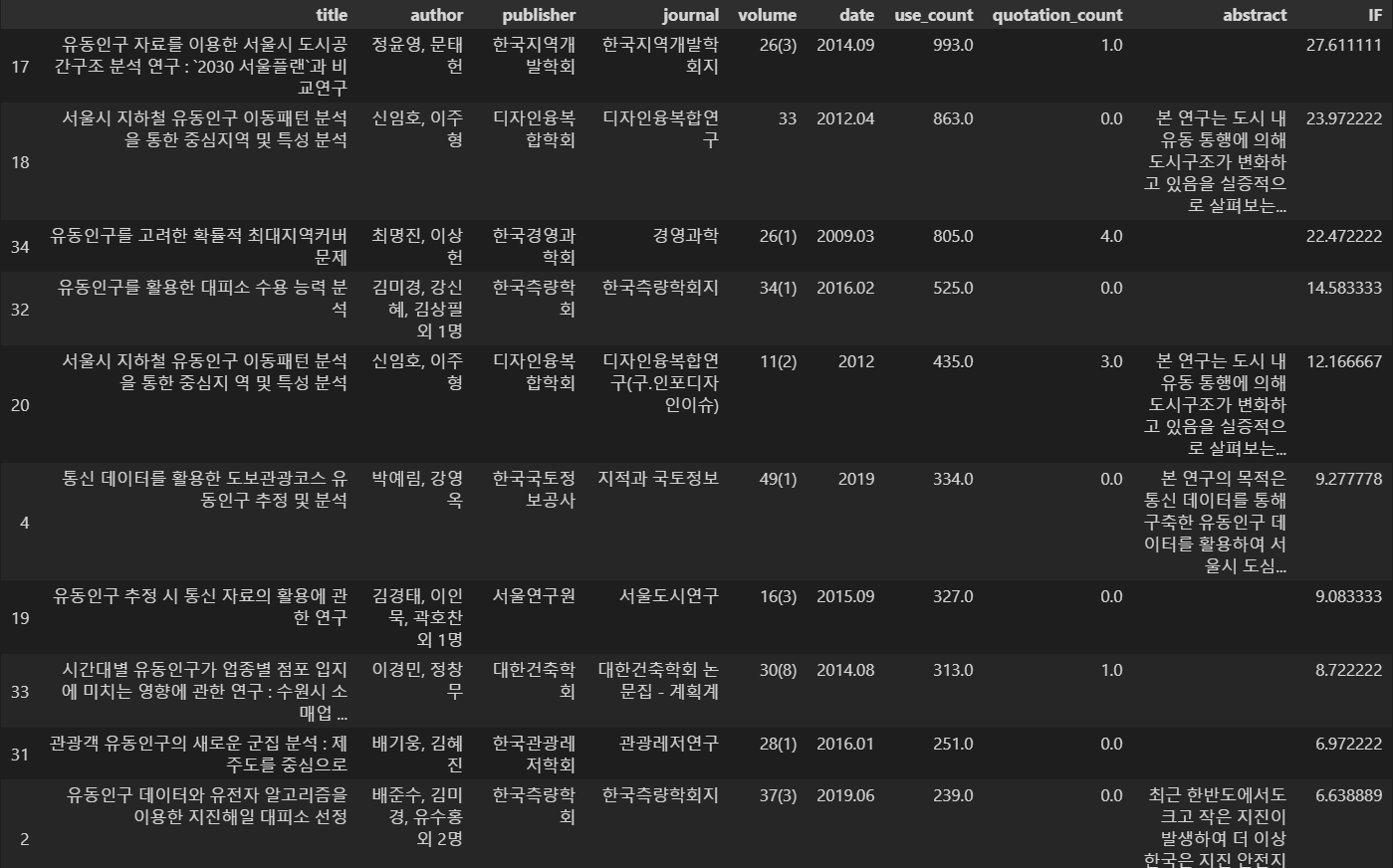
DataFrame 전처리📚
Project의 성격을 고려하여 DataFrame을 전처리하는 과정이 필요하다. 해당 코드를 보기 이전에 IF(영향력 지수)라는 Column을 추가해주고자한다. 분석하는 과정이 선행연구들의 title에서 사용된 명사 단위 요소들의 빈도수 분석과 영향력 지수가 높은 상위 6개의 논문 간의 분석으로 나뉘는데, 영향력 지수가 두 번째 Process에서 쓰이기 때문이다. 이와 같이 두 개의 분석을 거치는 이유는 title에서 사용된 명사 단위 요소들의 빈도수 분석 자체로도 의미가 있지만 영향력이 높은 데이터 만의 분석도 필요할 것이라 판단되어 두 개를 나눠 진행하였다.
계산식으로 보면 아래와 같다.
하지만 실제 사용 중인 영향력 지수를 그대로 사용할 시, 영향력 지수 자체가 0값이 되는 행들이 너무 많아지는 문제가 발생했다. 단순하게 생각하면 영향력이 아예 없다고 생각할 수 있지만, 다운로드 숫자라는 지표가 있어서 마냥 그렇게 결론을 내리고 넘어가기도 애매하였다. 그래서 이번 프로젝트 간에는 영향력 지수를 약간 수정하여 사용하게 되었다.
해당 부분 코드는 아래와 같다.
# 타이틀 부분만 CSV로 저장
DB_title = DB[['title']]
fName_title = "{}_{}_{}_title.csv".format(searchQ, startYear, endYear)
DB_title.to_csv(fName_title)
# IF(영향력 지수 col 만들어주기)
# use_count 숫자형 데이터로 바꾸기
DB["use_count"] = DB["use_count"].replace('[,]', '', regex=True)
DB["use_count"] = pd.to_numeric(DB["use_count"])
# quotation_count 숫자형 데이터로 바꾸기
DB["quotation_count"] = DB["quotation_count"].replace('[,]', '', regex=True)
DB["quotation_count"] = pd.to_numeric(DB["quotation_count"])
# NaN값 0으로 채워주기
DB = DB.fillna(0)
# "IF" 칼럼 만들어주기
DB["IF"] = (DB["use_count"] + DB["quotation_count"]) / len(DB.axes[0])
DB
# "IF" 수치 기준 오름차순
DB.sort_values(by='IF', ascending=False).groupby('title').head()해당 절차를 마친 후의 DataFrame을 보면 다음과 같다.
선행연구들의 title에서 사용된 명사 단위 요소들의 빈도수 분석🔍(feat.Word Cloud)
첫 번째 분석인 선행연구들의 title에서 사용된 명사 단위 요소들의 빈도수 분석을 위해 전처리를 해줘야한다. 정규표현식를 이용하여 Stopword(불용어) 처리를 해주고, Konlpy를 이용하여 형태소 분석을 하여 명사 단위로 요소들을 뽑되, 조건을 주어 한 글자 이상의 단어들만 모아 keyword라는 New column을 만들어 준다. 이후 명사 빈도를 구하여 Word Cloud를 걸어가는 사람 모양의 mask를 적용하여 시각화하고 이를 Image File로 저장하는 과정이다.
해당 코드는 아래와 같다.
""" 필요 없는 문자 제거 """
def clean_text(row):
text = row['title']
pattern = '([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)'
text = re.sub(pattern=pattern, repl='', string=text)
# print("한글 자음 모음 제거 : ", text , "\n")
pattern = '<[^>]*>'
text = re.sub(pattern=pattern, repl='', string=text)
# print("특수기호 제거 : ", text , "\n" )
pattern = '[^\w\s]'
text = re.sub(pattern=pattern, repl='', string=text)
# print("필요없는 정보 제거 : ", text , "\n" )
pattern = '["이용한"]'
text = re.sub(pattern=pattern, repl='', string=text)
return text
DB_title['title_clean'] = DB_title.apply(clean_text, axis=1)
#키워드 추출 from title
komoran = Komoran()
DB_title['keyword'] = ''
for idx_line in range(len(DB_title)):
nouns_list = komoran.nouns(DB_title['title_clean'].loc[idx_line])
nouns_list_c = [nouns for nouns in nouns_list if len(nouns) > 1] # 한글자는 이상한게 많아서 2글자 이상
DB_title.loc[[idx_line], 'keyword'] = set(nouns_list_c)
# title_clean 부분만 추출해 CSV로 저장
DB_title_clean = DB_title[['title_clean']]
fName_title = "{}_{}_{}_title.csv".format(searchQ, startYear, endYear)
DB_title_clean.to_csv("DB_title_clean.csv")
filename = "C:/Users/hyunsuki/DB_title_clean.csv"
f = open("DB_title_clean.csv", 'r', encoding='utf-8')
data_f = f.read()
f.close()
# Komoran 객체 생성
noun = komoran.nouns(data_f)
count = Counter(noun)
# 명사 빈도 카운트
noun_list = count.most_common(100)
#for v in noun_list:
# print(v)
from PIL import Image
from wordcloud import STOPWORDS
mask = Image.open('C:/Users/hyunsuki/image.png')
mask = np.array(mask)
font_path = 'C:\\Windows\\Fonts\\HMKMRHD.ttf'
# wordcloud 만들기
wc = WordCloud(font_path=font_path,
background_color="white",
mask = mask,
width=1000,
height=1000,
max_words=100,
max_font_size=300)
wc.generate_from_frequencies(dict(noun_list))
plt.figure(figsize=(7, 7))
plt.axis('off')
plt.imshow(wc.generate_from_frequencies(dict(noun_list)))
plt.savefig("word_cloud")코드를 실행해서 다음과 같은 결과물(Word Cloud)을 얻었다.

선행연구들의 title에서 사용된 명사 단위 요소들의 빈도수 분석🔍(feat.Networkx-네트워크 이론)
그렇다면 이렇게 각각의 선행연구들의 title에서 뽑아낸 명사 단위 단어들이 서로 어떠한 연관성을 가지고 네트워크를 이루고 있을지 궁금하여 이것도 분석해보았다.
# Network analysis
G = nx.Graph()
edge_list = []
for keywords_dict in DB_title['keyword']:
keywords = list(keywords_dict)
num_keyword = len(keywords)
if num_keyword > 0:
for i in range(num_keyword-1):
for j in range(i+1, num_keyword):
edge_list += [tuple(sorted([keywords[i], keywords[j]]))] # node 간 위해 sorted 사용
edges = list(Counter(edge_list).items())
G = nx.Graph((x, y, {'weight': v}) for (x, y), v in edges)
font_path = "C:/Windows/Fonts/malgunbd.ttf" # 폰트 파일 위치
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
#networkx Graph 작성
nx.Graph()
plt.figure(figsize=(80,80))
pos = nx.spring_layout(G, k=0.0316)
nx.draw_networkx_nodes(G, pos,
node_shape = "o",
node_color='#BB78FF',
node_size=3000)
nx.draw_networkx_edges(G, pos,
style='solid',
width=5,
alpha=0.3)
nx.draw_networkx_labels(G, pos,
font_size=45,
font_family=font_name)
plt.show()
plt.savefig("networkx_graph")
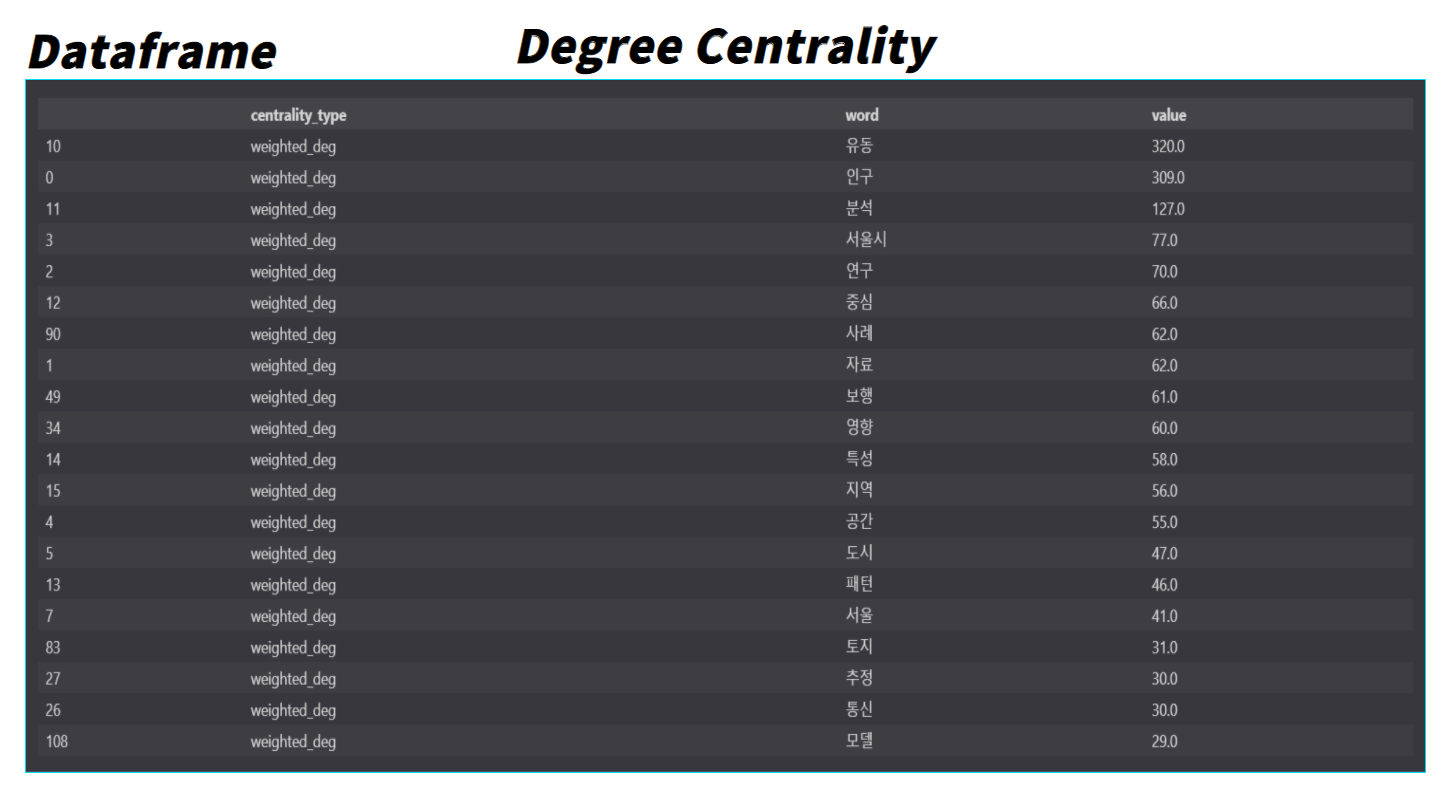
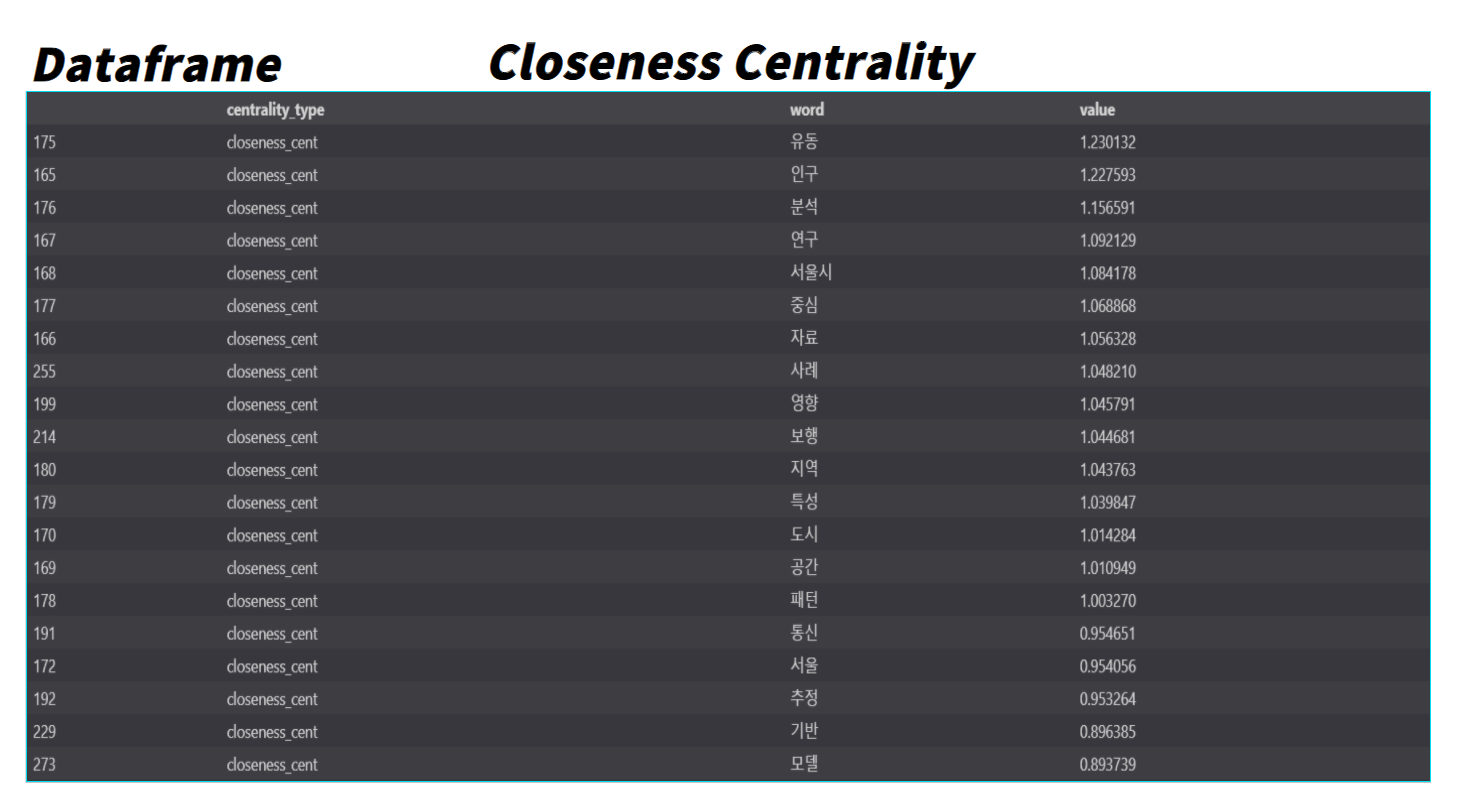
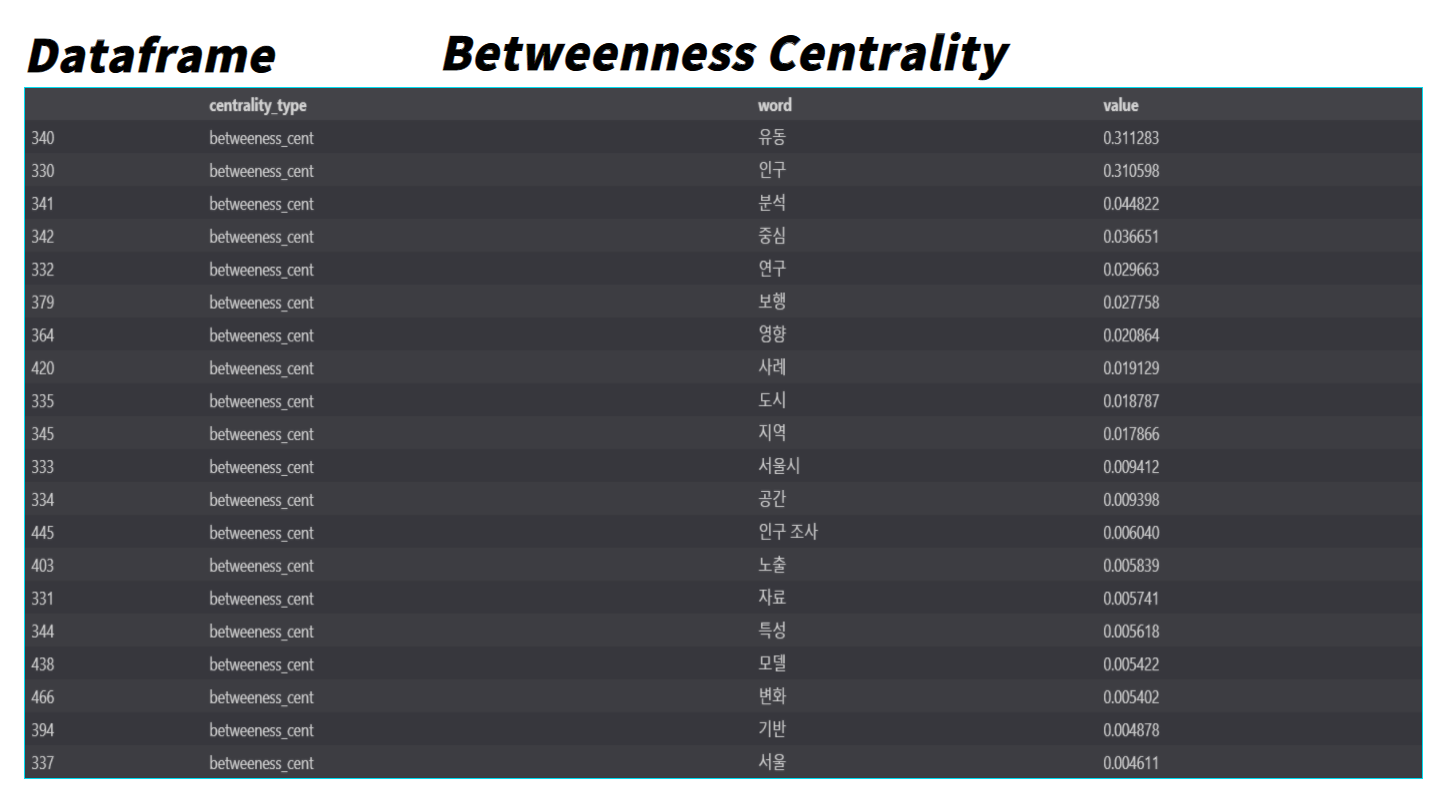
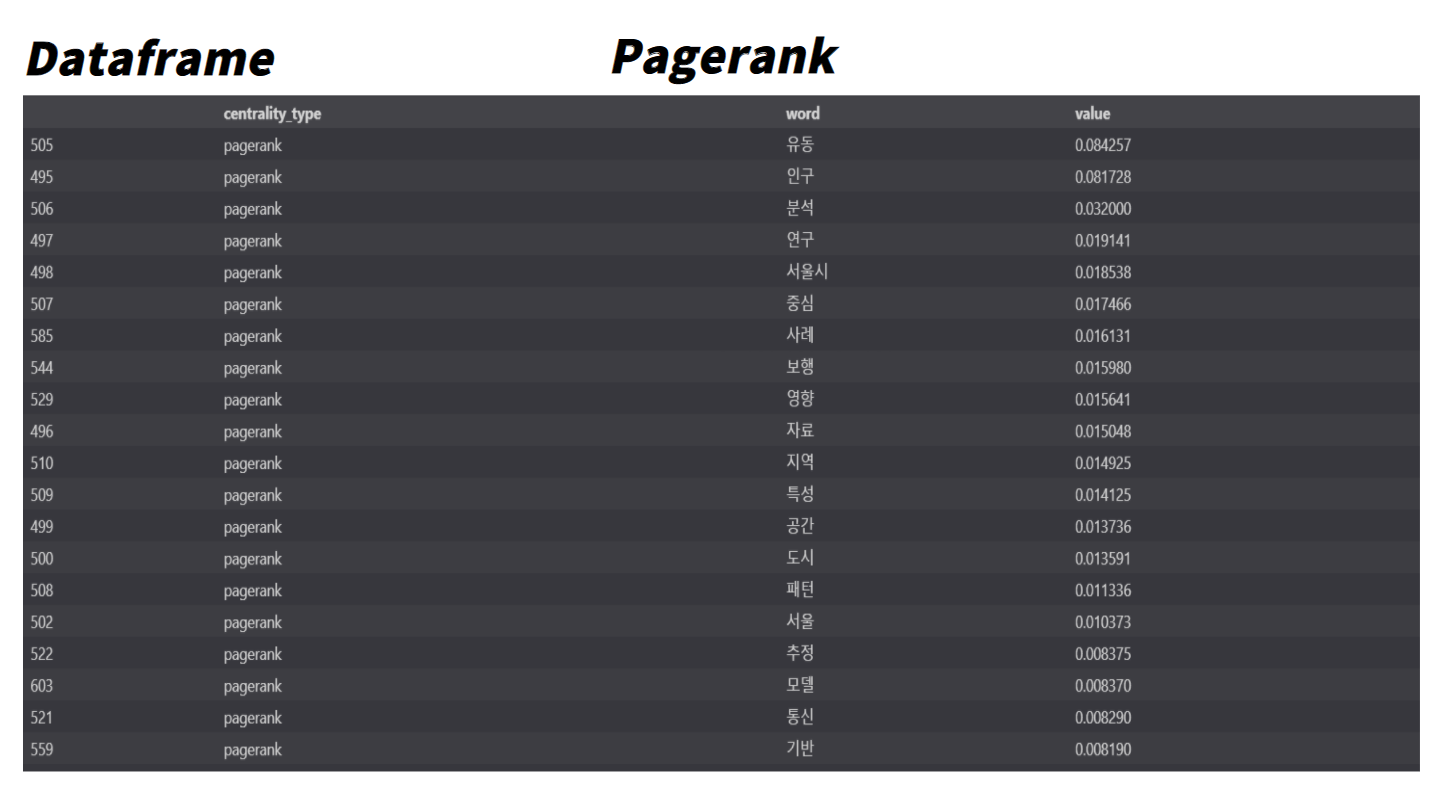
추가적으로 네트워크 이론에서는 Centrality(중심성)이라는 개념이 있는데, 이는 사회 연결망에서 vertex(꼭짓점) 혹은 node의 상대적 중요성을 나타내는 척도이다. 종류로는 Degree Centrality, Closeness Centrality, Betweenness Centrality, Pagerank가 있다. 각각의 Centrality에 대해 간단히 알아보면 다음과 같다.
| 종 류 | 설 명 |
|---|---|
| Degree Centrality | 연결중심성은 한 노드에 연결된 모든 간선의 갯수를 통해 네트워크의 중심성 정도를 판단하는 방법 |
| Closeness Centrality | 근접중심성으로 중요한 노드일수록 다른 노드까지의 거리가 짧다는 이론을 근거로 계산 |
| Betweenness Centrality | 매개중심성은 노드 간 경로에 있는 사람이 더 중심도가 높다는 이론을 근거로 계산 한마디로 노드와 노드 사이를 잇는 나들목에 여러번 등장하는 노드가 중요하다는 뜻 |
| Pagerank | 고유벡터 중심성의 변형인 Katz 중심성의 변형. Katz 중심성에선 한 노드의 중요성이 그와 연결된 다른 노드들에게도 전파되는 특징이 있음 이때 한 노드가 비정상적으로 중요하게 계산될 경우, 그 주변의 노드들도 함께 중요하게 계산 되는 편파적인계산이 나올 수 있는데 이러한 문제를 해결한 중심성 |
각각의 Centrality를 활용하여 Centrality 종류에 따른 명사들의 중요성을 분석해 보았다.
# centrality analysis
def return_centralities_as_dict(input_g):
# weighted degree centrality를 딕셔너리로 리턴
def return_weighted_degree_centrality(input_g, normalized=False):
w_d_centrality = {n:0.0 for n in input_g.nodes()}
for u, v, d in input_g.edges(data=True):
w_d_centrality[u]+=d['weight']
w_d_centrality[v]+=d['weight']
if normalized==True:
weighted_sum = sum(w_d_centrality.values())
return {k:v/weighted_sum for k, v in w_d_centrality.items()}
else:
return w_d_centrality
def return_closeness_centrality(input_g):
new_g_with_distance = input_g.copy()
for u,v,d in new_g_with_distance.edges(data=True):
if 'distance' not in d:
d['distance'] = 1.0/d['weight']
return nx.closeness_centrality(new_g_with_distance, distance='distance')
def return_betweenness_centrality(input_g):
return nx.betweenness_centrality(input_g, weight='weight')
def return_pagerank(input_g):
return nx.pagerank(input_g, weight='weight')
return {
'weighted_deg':return_weighted_degree_centrality(input_g),
'closeness_cent':return_closeness_centrality(input_g),
'betweeness_cent':return_betweenness_centrality(input_g),
'pagerank':return_pagerank(input_g)
}
for k, v in return_centralities_as_dict(G).items():
print("{}: {}".format(k, v))
# 중심도 종류에 따라 DataFrame 분류
word_centralities = (pd.DataFrame(return_centralities_as_dict(G)).T
.stack()
.apply(pd.Series)
.stack()
.reset_index(-1, drop=True)
.reset_index())
# dataframe 정리
word_centralities.columns = ['centrality_type','word','value']
word_centralities_weighted_deg = word_centralities[word_centralities['centrality_type'].str.contains('weighted_deg')]
word_centralities_closeness_cent = word_centralities[word_centralities['centrality_type'].str.contains('closeness_cent')]
word_centralities_betweeness_cent = word_centralities[word_centralities['centrality_type'].str.contains('betweeness_cent')]
word_centralities_pagerank = word_centralities[word_centralities['centrality_type'].str.contains('pagerank')]
# 내림차순 정렬
word_centralities_weighted_deg = word_centralities_weighted_deg.sort_values(by='value',ascending=False)
word_centralities_closeness_cent = word_centralities_closeness_cent.sort_values(by='value',ascending=False)
word_centralities_betweeness_cent = word_centralities_betweeness_cent.sort_values(by='value',ascending=False)
word_centralities_pagerank = word_centralities_pagerank.sort_values(by='value',ascending=False)
word_centralities_weighted_deg.head(20)
word_centralities_closeness_cent.head(20)
word_centralities_betweeness_cent.head(20)
word_centralities_pagerank.head(20)각각의 Centrality에 따른 단어들의 중요도들은 아래와 같다.
영향력 지수가 높은 상위 6개의 논문 간의 분석🔍
두 번째로 위에서 수정한 영향력 지수(IF)를 활용하여 상위에 위치하는 6개의 선행연구 논문들의 각각의 키워드 간의 연관성을 분석해보았다.
코드는 아래와 같다.
xlsx = pd.read_excel("C:/Users/hyunsuki/DB_Networkx_keywords_2.xlsx")
xlsx.to_csv("C:/Users/hyunsuki/DB_Networkx_keywords_2.csv",encoding = 'utf-8-sig')
DB_Networkx_keywords = pd.read_csv("C:/Users/hyunsuki/DB_Networkx_keywords_2.csv")
DB_Networkx_keywords = DB_Networkx_keywords.drop(['Unnamed: 0', 'Unnamed: 0.1'], axis=1)
#Network analysis
g = nx.Graph({'weight': 'IF'})
g = nx.from_pandas_edgelist(DB_Networkx_keywords,source='keywords',target='title',edge_attr='IF')
font_path = "C:/Windows/Fonts/malgunbd.ttf" # 폰트 파일 위치
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
# edges,weights 리스트 만들기
edges,weights = zip(*nx.get_edge_attributes(g,'IF').items())
# 간선의 너비 늘리기 ( corr를 이용해 구현해서 가중치 안 늘리면 너무 가늘게 나옴)
weights = tuple([(1+abs(x))**2 for x in weights])
nx.Graph()
plt.figure(figsize=(190,80))
pos = nx.spring_layout(g, k=0.0316)
nx.draw_networkx_nodes(g, pos,
node_shape = "o",
node_color='#BB78FF',
node_size=7000)
nx.draw_networkx_edges(g, pos,
style='solid',
width=5,
edge_vmin = min(weights),
edge_vmax=max(weights),
alpha=0.3)
nx.draw_networkx_labels(g, pos,
font_size=70,
font_family=font_name)
plt.show()코드를 실행해서 나온 IF(영행력 지수) 상위 6개 논문의 키워드 네트워크 분석 결과는 아래와 같이 나왔다.
3. 프로젝트를 마치며📌
자연어 처리에 대한 경험이 전무한 상태에서 아이디어만으로 Project를 진행하다보니 어려움도 많았고, 아쉬움 또한 많이 남는다. 하지만 이번 Project는 혼자서 머리 속에서 구상한 것을 처음부터 끝까지 혼자 힘으로 끝낸 것에 의의를 투고자 하며 아래에 개선이 필요한 부분을 남기면서 이만 마치고자 한다.
개선이 필요한 부분👀
• Crawling Code에 작가 선정 키워드와 IF를 Dataframe에 자동으로 추가하는 기능 추가
• 선행 연구충분성 지수를 추가하여 다양한 분석해보기
• Stopwords Dictionary를 제대로 완성하여 좀 더 유의미한 분석 이끌어내기
• Networkx에 대한 공부를 통해 깔끔하고 다양한 Data visualization해보기
