
이 프로젝트의 결과는 여기, 코드는 여기에서 볼 수 있습니다.
개발 배경
아래 배경에 관한 자세한 설명은 이전 글에서 다뤘으므로 있으니 여기선 간략하게만 설명하고 넘어가자.
한글의 incremental search
요즘 점점 늘어나고 있는 검색 관련 UX로 incremental search가 있다. 간단히 설명하자면 검색할 내용을 모두 친 다음에 검색 버튼을 누를 때 결과를 보여주는 것이 아니라 한글자 한글자 칠 때마다 갱신된 결과를 실시간으로 보여주는 것이다. 특히 SPA와 Virtual DOM이 나오면서 incremental search로 구현을 해도 랜더링 속도가 괜찮기 때문에 더욱 늘어나는 것 같다. 단순히 검색의 메인 결과를 보여주는 것 뿐만 아니라 페이지에서 찾기, 자동 완성 목록 등 다양한 곳에서도 이와 비슷한 UX를 구성하고 있다.
그러나 한글은 초성 종성 중성을 한 글자에 합치는 시스템을 이루기 때문에 incremental search에 적합하지 못하다. 예를 들어 한글로 코드를 칠 경우 그 과정은 ㅋ, 코, 콛, 코드가 된다. 그러나 일반적인 문자열 매칭 함수로는 그중 코와 코드만이 포함된다. 따라서 실제로 보여져야 하는 결과나 나타났다가 사라졌다가 하는 좋지 못한 UX를 제공하게 된다.
한글의 Unicode 저장 방식
이 문제를 해결하려면 일단 한글의 초성 중성 종성을 분해해서 다뤄야 하므로 한글이 디지털상에 어떻게 저장되어 있는지 확인해야 한다. 결론만 말하자면 한글은 초성 19글자, 중성 21글자, 종성 27글자 + 받침이 없는 경우가 전부 조합되어 19*21*28 = 11172 글자가 순서대로 저장되어 있다.
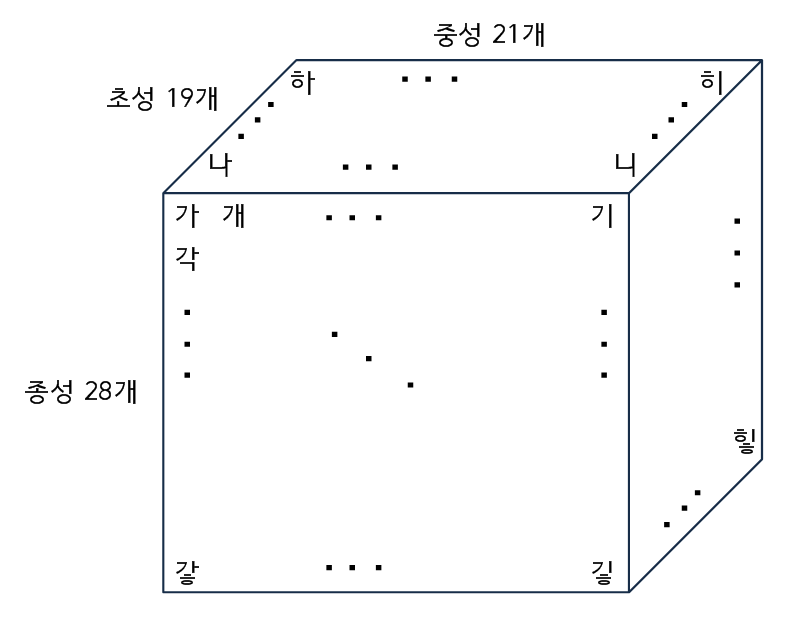
따라서 중성과 종성의 갯수로 나눈 나머지와 몫을 잘 활용하면 모든 글자를 쉽게 분해할 수 있다.
한글 분해하기
위 내용을 토대로 한글을 분해하는 작업을 해보자. 여기서 할 작업은 한글이 들어오면 실제로 우리가 타이핑하는 형태로 나열하는 것이다. 예를 들어 원이라는 글자가 들어오면 [ㅇ, ㅜ, ㅓ, ㄴ]을 반환하는 것이 목표이다.
먼저 현재 들어올 문자가 내가 분해할 대상인지 아닌지부터 판별해야 한다. 우리가 분해할 글자는 가부터 힣까지의 완전체 한글이고, 다행히도 이 모든 글자는 위에서 말한 3차원 배열과 같은 형태로 순서대로 저장되어있다. 따라서 해당 범위의 첫 글자인 가와 마지막 글자인 힣의 유니코드를 이용하면 된다. 각 글자의 유니코드는 charCodeAt(0)을 통해 얻을 수 있다.
const ga = "가".charCodeAt(0);
const hih = "힣".charCodeAt(0);
if(c.charCodeAt(0) < ga || c.charCodeAt(0) > hih) return [c];나머지는 위에서 설명했듯이 중성과 종성의 갯수에 잘 맞춰서 저장되에 있으니 몫과 나머지를 잘 사용해서 구현하면 된다.
const choseong = [
"ㄱ", "ㄲ", "ㄴ", "ㄷ", "ㄸ", "ㄹ", "ㅁ", "ㅂ", "ㅃ", "ㅅ",
"ㅆ", "ㅇ", "ㅈ", "ㅉ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ"
];
const jungseong = [
["ㅏ"], ["ㅐ"], ["ㅑ"], ["ㅒ"], ["ㅓ"], ["ㅔ"], ["ㅕ"], ["ㅖ"], ["ㅗ"],
["ㅗ", "ㅏ"], ["ㅗ", "ㅐ"], ["ㅗ", "ㅣ"], ["ㅛ"], ["ㅜ"], ["ㅜ", "ㅓ"],
["ㅜ", "ㅔ"], ["ㅜ", "ㅣ"], ["ㅠ"], ["ㅡ"], ["ㅡ", "ㅣ"], ["ㅣ"]
];
const jongseong = [
[], ["ㄱ"], ["ㄲ"], ["ㄱ", "ㅅ"], ["ㄴ"], ["ㄴ", "ㅈ"], ["ㄴ", "ㅎ"],
["ㄷ"], ["ㄹ"], ["ㄹ", "ㄱ"], ["ㄹ", "ㅁ"], ["ㄹ", "ㅂ"], ["ㄹ", "ㅅ"],
["ㄹ", "ㅌ"], ["ㄹ", "ㅍ"], ["ㄹ", "ㅎ"], ["ㅁ"], ["ㅂ"], ["ㅂ", "ㅅ"],
["ㅅ"], ["ㅆ"], ["ㅇ"], ["ㅈ"], ["ㅊ"], ["ㅋ"], ["ㅌ"], ["ㅍ"], ["ㅎ"]
];
const korCode = (c.charCodeAt(0) - ga);
const res = [
choseong[Math.floor(korCode / (jungseong.length * jongseong.length))],
...jungseong[Math.floor((korCode % (jungseong.length * jongseong.length)) / jongseong.length)],
...jongseong[korCode % jongseong.length]
]
return res;여기서 주의할 점은 종성의 첫 번째는 받침이 없는 경우라는 것과 중성의 ㅘ나 종성의 ㄶ과 같이 두 글자가 합쳐져 있는 경우를 고려해서 배열을 만들어야 한다는 것이다.
문자열 매칭 (Z algorithm)
한글을 분해하는 함수를 완성했으니 이제 쿼리와 데이터를 모두 분해시킨 후 매칭 함수를 돌리면 된다. 사실 여기서 그냥 원래 있는 indexOf함수를 가져다 써도 된다. 그러나 indexOf는 맨 첫 번째 매칭만 반환하기 때문에, 만약에 모든 매칭 결과를 얻고 싶다면 그 뒤의 문자열에 대해 계속 indexOf함수를 실행해야 한다. indexOf의 내부 구현을 잘 몰라서 자세히 말하긴 힘들지만, 이러한 방식은 잘못하면 시간복잡도가 제곱으로 걸릴 수 있다. 따라서 선형시간 안에 모든 매칭을 찾는 함수를 구현하고 싶었고, 이를 위해 Z algorithm을 써서 직접 문자열 매칭을 구현했다. Z algorithm의 구현부는 여기를 참고하면 된다.
Z algorithm은 모든 위치에 대해 최대 몇 글자까지 매칭되는지를 알려준다. 그러나 우리는 전부 매칭된 인덱스만 찾으면 되니 저 배열에서 값이 쿼리의 길이인 인덱스만 모아서 반환하면 된다.
return Z.slice(query.length).reduce((a, x, i) => {
if(x >= query.length) a.push(i);
return a;
}, [])구현된 기능들
koreanIndexOf, koreanAllIndexOf
위에서 만든 분해 함수로 문자열의 각 문자들을 분해한 후 이어붙인 다음 여기에 위에서 구현한 Z algorithm을 적용시키면 모든 매칭 결과를 선형시간 안에 얻는 koreanAllIndexOf를 구현할 수 있다. 그리고 이 결과에서 첫 번째 값, 혹은 배열이 비어있을 경우 -1을 반환하도록 하면 koreanIndexOf를 구현할 수 있다.
import { koreanIndexOf, koreanAllIndexOf } from 'korean-index-of';
koreanIndexOf("콛", "내 코드");
/// 2
koreanAllIndexOf("갭", "개와 개불과 개발자 사이의 갭");
/// [3, 7, 15]koreanIndexRangeOf, koreanAllIndexRangeOf
일반적인 매칭 함수들은 매칭의 끝 위치를 따로 알려주진 않는다. 왜냐하면 쿼리의 길이가 곧 매칭의 길이가 되기 때문이다. 그러나 한글에서는 두 값이 다를 수 있다. 왜냐하면 마지막 자음이 초성이 될지 종성이 될지 모르기 때문이다. 예를 들어 갭은 갭과도 매칭이 되고 개발과도 매칭이 되는데 첫 번째의 경우에는 한 글자, 두 번째의 경우에는 두 글자와 매칭이 된다. 이렇게 한글을 매칭할 경우에는 마지막 매칭 위치도 같이 알려줘야 한다. 그리고 이는 처음에 글자를 분해할 때 원래 문자열에서의 위치를 저장하여 나중에 매칭 결과와 비교하면 알아낼 수 있다.
import { koreanIndexRangeOf, koreanAllIndexRangeOf } from 'korean-index-of';
koreanIndexRangeOf("콛", "내 코드");
/// [2, 3]
koreanAllIndexRangeOf("갭", "개와 개불과 개발자 사이의 갭");
/// [[3, 4], [7, 8], [15, 15]]koreanOnsetIndexOf, koreanAllOnsetIndexOf
위 내용만 보면 한글은 UX적으로 단점만 있는 것 같지만, 다른 언어에는 존재하지 않는 엄청나게 좋은 UX도 있다. 바로 초성 검색이다. 초성 검색은 30%밖에 안 되는 타이핑으로 굉장히 정확하면서 직관적인 결과를 얻을 수 있는 훌륭한 UX이다. 위에서 한글을 분해하는 작업은 이미 했으니 여기서 첫 번째 결과만 추출하는 방식으로 구현하면 초성 검색을 지원하는 함수도 쉽게 만들 수 있다.
import { koreanOnsetIndexOf, koreanAllOnsetIndexOf } from 'korean-index-of';
koreanOnsetIndexOf("ㄱㅂ", "개와 개불과 개발자 사이의 갭");
/// 3
koreanAllOnsetIndexOf("ㄱㅂ", "개와 개불과 개발자 사이의 갭");
/// [3, 7]다만 쿼리에서 초성과 완전체 한글이 섞여있는 경우 제대로 동작하지 않는다.
import { koreanAllOnsetIndexOf } from 'korean-index-of';
koreanAllOnsetIndexOf("개ㅂ", "개와 개불과 개발자 사이의 갭");
/// []만약에 기존 indexOf함수처럼 문자열에서 바로 붙여다 쓰는 prototype 방식이 그립다면 아래와 같이 하면 된다.
import { koreanIndexOf } from 'korean-index-of';
String.prototype.kIndexOf = function(query) {
return koreanIndexOf(query, this);
}
"내 코드".kIndexOf("콛");
/// 2normailze()와 비교
피드백을 받다가 ES6에 normalize라는 함수가 있다는 내용을 알게 되었다. 그리고 이 함수를 사용하면 한글을 바로 분해할 수 있다.
// U+D55C: 한(HANGUL SYLLABLE HAN)
// U+AE00: 글(HANGUL SYLLABLE GEUL)
var first = '\uD55C\uAE00';
// U+1112: ᄒ(HANGUL CHOSEONG HIEUH)
// U+1161: ᅡ(HANGUL JUNGSEONG A)
// U+11AB: ᆫ(HANGUL JONGSEONG NIEUN)
// U+1100: ᄀ(HANGUL CHOSEONG KIYEOK)
// U+1173: ᅳ(HANGUL JUNGSEONG EU)
// U+11AF: ᆯ(HANGUL JONGSEONG RIEUL)
var second = first.normalize('NFD'); // '\u1112\u1161\u11AB\u1100\u1173\u11AF'그래서 처음에는 내가 삽질을 했나 했다가 이 함수의 분해는 incremental search에서 사용하기에 적합하지 않다는 것을 알게 되었다.
우선 이 함수의 결과에서는 같은 자음이어도 초성의 위치에서와 종성의 위치에서 유니코드가 다르다. 하지만 실제로 우리가 검색할 땐 그 글자가 초성이 될지 종성이 될지 모른다. 예를 들어 검색 과정이 갭이었다면 이 ㅂ이 종성의 ㅂ이 될지 초성의 ㅂ이 될지 알 수 없다. 그래서 normalize를 쓰면 종성의 ㅂ만 매칭되므로 원하는 결과를 얻을 수 없다.
또한 이 함수는 겹모음이나 겹자음을 나눠주지 않는다. 즉, 않과 같은 글자의 경우 ㅇㅏㄴㅎ이 아니라 ㅇㅏㄶ으로 분리된다. 그러나 우리의 키보드에 ㄶ이라는 글자는 없다. 따라서 이를 치는 중간 과정인 안이라는 글자와는 매칭이 되지 않는 문제점이 생긴다.
따라서 제대로 된 한글에서의 incremental search를 구현하려면 직접 분해하는 함수를 만들어서 사용하는게 맞는 것 같다.