📌Series 데이터
pandas
구조화된 데이터를 효과적으로 처리하고 저장할 수 있는 파이썬 라이브러리
array 계산에 특화된 numpy를 기반으로 만들어져 다양한 기능들을 제제공
데이터 연산 제공
- Series
특수한 딕셔너리, 넘파이 어레이가 보강된 형태로 data와 index로 구성
data=pd.Series([1,2,3,4])
#4개의 데이터가 담긴 시리즈 형태
인덱스를 가지고 있고 인덱스로 접근 가능하다
data=pd.Series([1,2,3,4],index=['a','b','c','d'])
data['b']
#2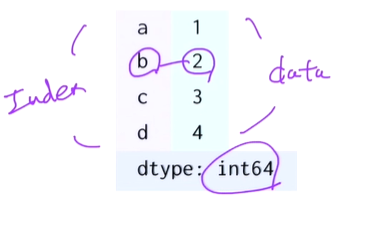
딕셔너리로 만들 수 있다.(변환)

pd.Series(딕셔너리) 함수를 이용해 딕셔너리에서 Series로 변환할 수 있다.
실습
# 국가별 인구 수 시리즈 데이터를 딕셔너리를 사용하여 만들어보세요.
population_dict = {
'korea' : 5180,
'japan' : 12718,
'china' : 141500,
'usa' : 32676
}
country = pd.Series(population_dict)
print(country)
📌DataFrame
- DataFrame
여러 개의 series가 모여서 행과 열을 이룬 데이터

딕셔너리로 만들 수 있다
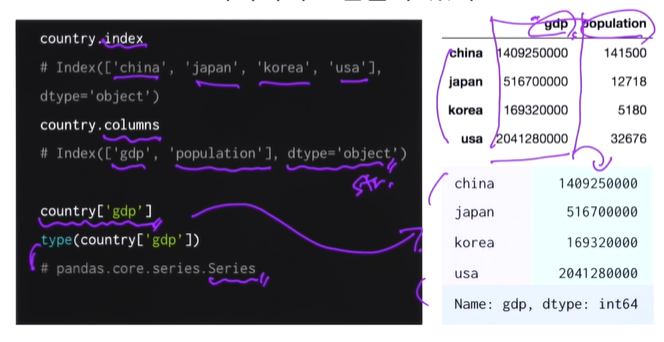
-
왼쪽 인 오른쪽 파풀
dtype은 파이썬 객체다 문자열 > 문자열은 기본적으로 오브젝트 타입 -
country['gap']
type(country['gdp'])
여러 개의 시리즈가 모여 데이터프레임을 이룬다
시리즈 데이터의 가장 기본적인 부분은 numpy가 보강된 형태
Series도 numpy array처럼 연산자를 쓸 수 있다
- 저장과 불러오기
만든 데이터 프레임을 저장할 수 있다
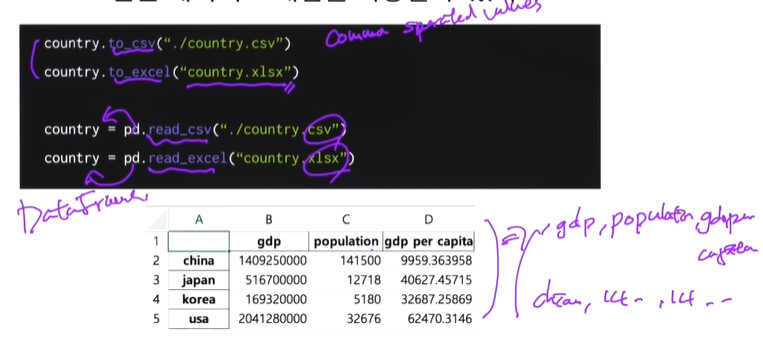
실습
# 두 개의 시리즈 데이터가 있습니다.
print("Population series data:")
population_dict = {
'korea': 5180,
'japan': 12718,
'china': 141500,
'usa': 32676
}
population = pd.Series(population_dict)
print(population, "\n")
print("GDP series data:")
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa': 2041280000,
}
gdp = pd.Series(gdp_dict)
print(gdp, "\n")
# 이곳에서 2개의 시리즈 값이 들어간 데이터프레임을 생성합니다.
print("Country DataFrame")
country = pd.DataFrame({
'population':population,
'gdp':gdp
})
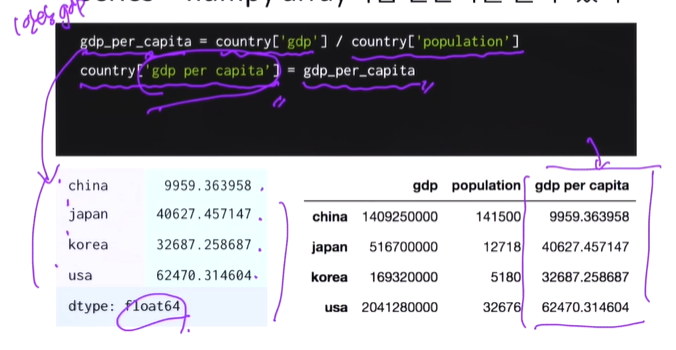
# 데이터 프레임에 gdp per capita 칼럼을 추가하고 출력합니다.
gdp_per_capita = country['gdp'] /country['population']
country['gdp per capita'] = gdp_per_capita
# 데이터 프레임을 만들었다면, index와 column도 각각 확인해보세요.
country.index
country.columns📌indexing & Slicing
- indexing & Slicing
loc:명시적인 인덱스를 참조하는 인덱싱/슬라이싱 - 명시적 스타일
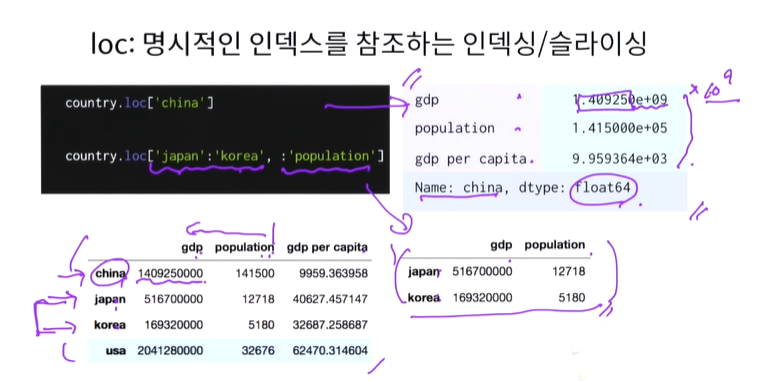
loc[행의번호,'컬럼명']
iloc:파이썬 스타일 정수 인덱스 인덱싱/슬라이싱 - 암묵적 스타일
앞에서부터 숫자를 매겨서 인덱싱을 암묵적으로 가지고있게 그걸 통해 참조할 수 있게

ix는 loc+iloc 혼합사용이지만 지금은 지원 중단
- DataFrame 새 데이터 추가/수정
리스트로 추가하는 방법과 딕셔너리로 추가하는 방법
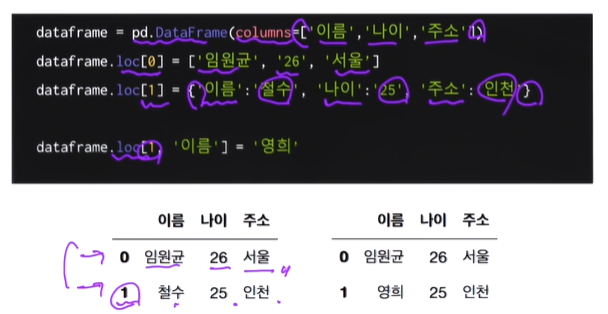
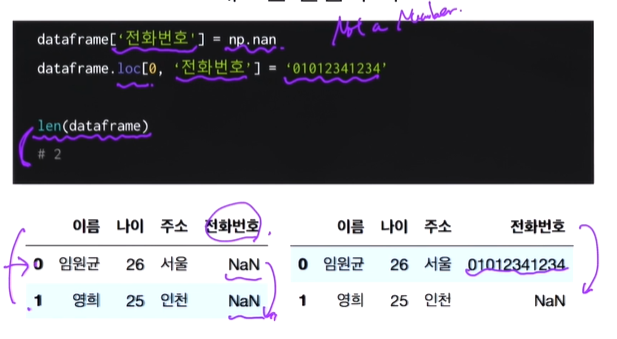
새로운 컬럼 추가
#np.nan => numpy의 not a number 값이 비어있는 값
- 컬럼 선택하기
컬럼 이름이 하나민 있다면 Series,리스트로 들어가 있다면 DataFrame
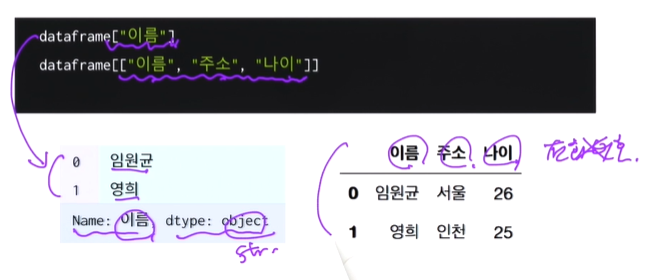
실습
# 첫번째 컬럼을 인덱스로 country.csv 파일 읽어오기.
print("Country DataFrame")
country = pd.read_csv("./data/country.csv", index_col=0)
print(country, "\n")
# 명시적 인덱싱을 사용하여 데이터프레임의 "china" 인덱스를 출력해봅시다.
print(country.loc['china'])
# 정수 인덱싱을 사용하여 데이터프레임의 1번째부터 3번째 인덱스를 출력해봅시다.
print(country.iloc[1:4])📌pandas 연산과 함수
- 누락된 데이터 체크
튜토리얼에서 보는 데이터와 달리 현실의 데이터는 누락되어 있는 형태가 많다
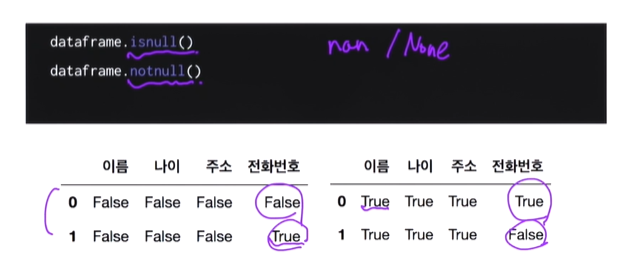
isnull():비어있는가? -nan,none 체크 //비어있으면 t
notnull():비어있지 않은가? //안비어있으면 t
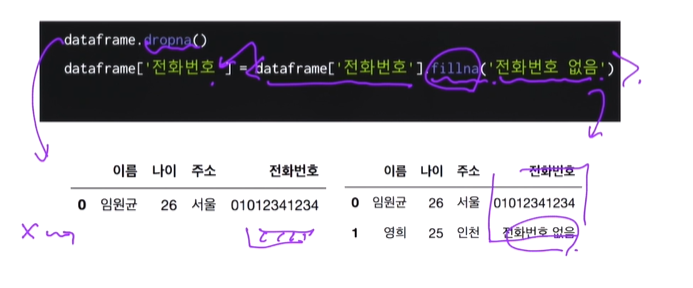
dropna():데이터가 비어있는 row를 삭제
fillna('ㅇㅇㅇ'):비어있는 곳은 ㅇㅇㅇ로 대체
- Series 연산
numpy array에서 사용했던 연산자들을 활용할 수 있다
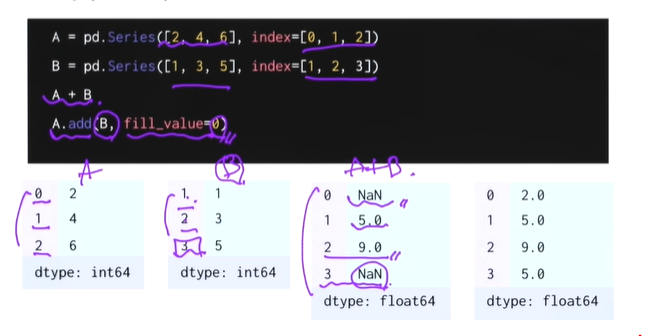
add(+), sub(-),mul(*),div(/)

- 집계함수
numpy array에서 사용했던 sum,mean등을 활용할 수 있다.

실습
print("A: ")
A = pd.DataFrame(np.random.randint(0, 10, (2, 2)), columns=['A', 'B']) #칼럼이 A, B입니다.
print(A, "\n")
print("B: ")
B = pd.DataFrame(np.random.randint(0, 10, (3, 3)), columns=['B', 'A', 'C']) #칼럼이 B, A, C입니다.
print(B, "\n")
# 아래에 다양한 연산을 자유롭게 적용해보세요.
print(A+B)
print(A.add(B,fill_value=0))
📌DataFrame 정렬하기
- 값으로 정렬하기
sort_value()

오름차순으로 정렬

내림차순으로 정렬
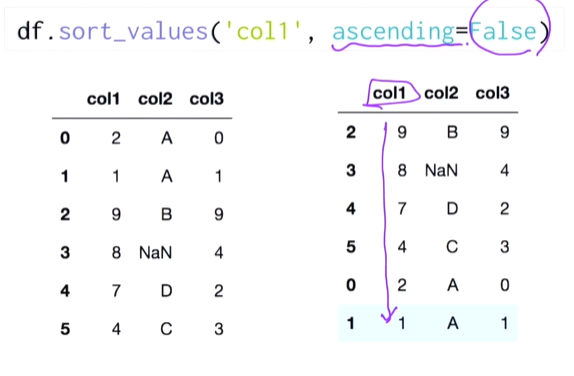
col2정렬 후 같은 값이면 col1로 정렬
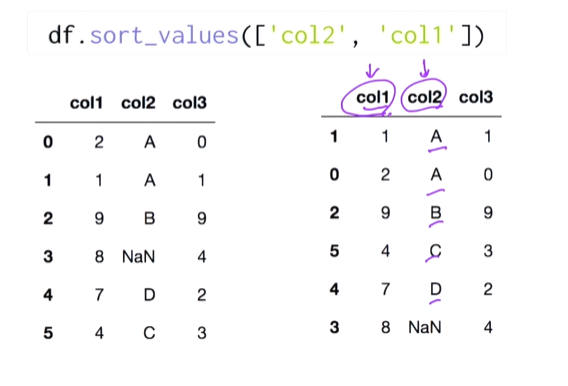
실습
import numpy as np
import pandas as pd
print("DataFrame: ")
df = pd.DataFrame({
'col1' : [2, 1, 9, 8, 7, 4],
'col2' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'col3': [0, 1, 9, 4, 2, 3],
})
print(df, "\n")
# 정렬 코드 입력해보기
# Q1. col1을 기준으로 오름차순으로 정렬하기.
sorted_df1=df.sort_values('col1')
print(sorted_df1)
# Q2. col2를 기준으로 내림차순으로 정렬하기.
sorted_df2=df.sort_values('col2',ascending=False)
print(sorted_df2)
# Q3. col2를 기준으로 오름차순으로, col1를 기준으로 내림차순으로 정렬하기.
sorted_df3= df.sort_val