데이터 비교

#df에 0~1사이의 5개 데이터+2차원의 데이터를 만든다, 컬럼의 이름은 A,B
df = pd.DataFrame(np.random.rand(5,2), column =["A","B"])
#A컬럼에 있는 시리즈데이터가 0.5보다 작다
df["A"] <0.5
2차원 데이터 비교

#df에 0~1사이의 5개 데이터+2차원의 데이터를 만든다, 컬럼의 이름은 A,B
df = pd.DataFrame(np.random.rand(5,2), column =["A","B"])
# 조건
df[(df["A"]<0.5) & (df["B"]>0.3)]
#true,false값으로 나옴
#질문
df.query("A<0.5 and B>0.3")
#마스킹 연산 적용해야 값까지 나온다
#문자열 자체를 그대로 넣는데 컬럼값,계산값을 넣으면 pandas가 알아서
문자열에서의 비교(검색)

#1데이터 애니멀 안에있는 컬럼에 대해 cat이라는 문자열을 포함하면 t
df["Animal"].str.contains("Cat")
#2 Cat과 정확히 매칭이되면 t
df.Animal.str.match("Cat")
#2이런식으로 비교연산도 가능
df["Animal"]=="Cat"
함수로 데이터 처리하기

df = pd.DataFrame(np.arange(5), columns=["Num"])
#1.square라는 함수인데 x값을 받아 x^2을 돌려주는 함수를 만든다
def square(x):
return x**2
#데이터 프레임에 num에 apply를 적용할건데 함수 자체를 인자로 넣음 > 시리즈data
df["Num"].apply(square)
#2.데이터 프레임에 lambda형식 x값을 받아 x의제곱을 넣어줌 그 값울 square에 넣는다
df["Square"] = df.Num.apply(lambda x:x**2)#1.
def hap(x, y):
return x + y
>>> hap(10, 20)
30
#2.
(lambda x,y: x + y)(10, 20)
30 
df = pd.DataFrame(columns=["phone"])
df.loc[0]="010-1234-1234"
df.loc[0]="공일공-일이삼사-1234"
df.loc[0]="010-1234-일이삼사"
df.loc[0]="공1공-1234-1234"
df["preprocess_phone"] =''
#이 데이터로 실제 전화를 걸 수 있는 번호로 바꾸기위해 apply를 사용하겠다 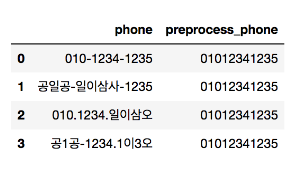
#1.함수 만들기
def get_preprocess_phone(phone)"
mapping_dict={
"공" : "0",
"일" : "1",
"이" : "2",
"삼" : "3",
"사" : "4",
"오" : "5",
"-" : "",
"." : "",
}
#반복문을 돌며 확인 할 예정
#replace를 통해 공을 0 으로 바꿔주는 코드
for key,value in mapping_dict.items():
phone = phone.replace(key,value)
return phone
df["preprocess_phone"] = df["phone"].apply(
get_preprocess_phone)복잡한 연산,데이터처리 할 때 apply를 통해 처리할 수 있다.
데이터 값만 대치하고싶을때?(바꾸고싶을때)
replace

#데이터프레임에 replace적용 male이라는 key 0이라는 value.. 를
#딕셔너리 형태로 넣어서 실행시 시리즈 데이터가 나온다
df.Sex.replace({"Male":0,"Female":1})
#inplace=True를 주면 데이터값이 시리즈데이터가 아니라 데이터 값을 그대로 바꿀 수 있다.
df.Sex.replace({"Male":0,"Female":1}, inplace=True)그룹으로 묶기
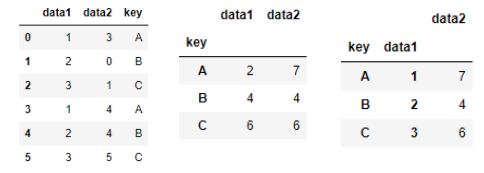
#키 값이 abcabc data1도 123123 data2는 0~6사이 6가지데이터
df = pd.DataFrame({'key' : ['A','B','C','A','B','C',],
'data1':[1,2,3,1,2,3],'data2':np.random.radiant(0,6,6)})
#그냥 매칭되어있는 상태
df.groupby('key')
#키 값을 통해서 묶어주는 역할
#키를 기준으로 합계를 구해달라
#abc key로 묶이고 해당값은 더해짐
df.groupby('key').sum()
#key,data1로 묶어서 sum연산 진행 > 다 더해진 값
df.groupby(['key','data1']).sum()aggregate
groupby를 통해 집계를 한 번에 계산하는 방법
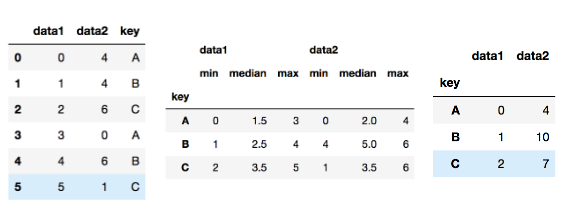
#데이터프레임의 키 값을 통해서 묶는데 aggregate연산을 하는데
#최소,중앙값,최대값 으로 확인 할 예정
df.groupby('key').aggregate(['min','np.median',max])
#df의 키값을 묶고 ag하는데 data1에서 최소, 2에서는 sum을
#딕셔너리로 묶어서 실행하면?
df.groupby('key').aggregate(['data1':''min,
'data2',np.sum)filter
groupby를 통해 그룹 속성을 기준으로 데이터 필터링할때 쓰임
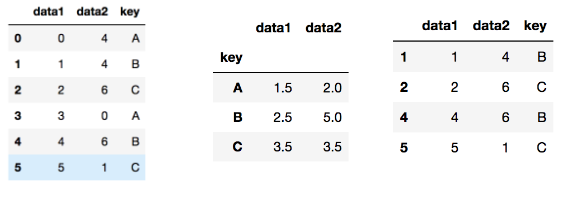
def filter_by_mean(x)"
return x['data2'].mean() > 3
#gruopby의 키값으로 묶은 상태로 평균값을 나오게한다
df.groupby('key').mean()
#평균값이 3보다 큰 애들을 정의하고 싶으니까 일단 함수 만들고
#그룹바이로 묶은 애들중에서 필터를 적용해 함수값을 인자로 넣어줌
df.groupby('key').filter(filter_by_mean)apply
groupby도 apply 적용 가능!
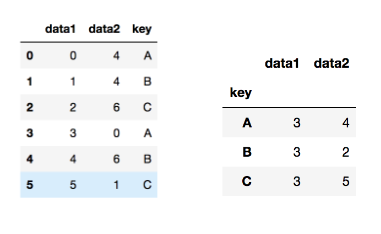
df.groupby('key').apply(lamde x: x.max()-x.min() )get_group

#대학교 정보 가져오기
df=pd.read_csv("./univ.csv")
df.head()
#시도로 묶고 그 중에서 충남이 들어간 대학
df.groupby("시도").get_group("충남")
#개수 확인
len(df.groupby("시도").get_group("충남"))Multiindex
인덱스를 계층적으로 만들 수 있다
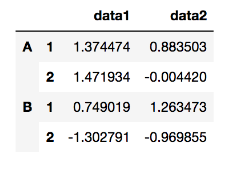
#랜덤값을 집어넣는데
#index에 2차원list가 2번 쌓여진 형태로 진행
df = pd.DataFrame(
np.random.randn(4,2)
index =[['A','A','B','B'],[1,2,1,2]],
columns = ['data1','data2']
)열 인덱스(컬럼)도 계층적으로 만들 수 있다
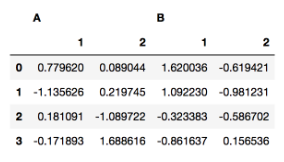
df = pd.DataFrame(
np.random.randn(4,4)
columns=[["A","A","B","B"],["1","2","1","2"]]
)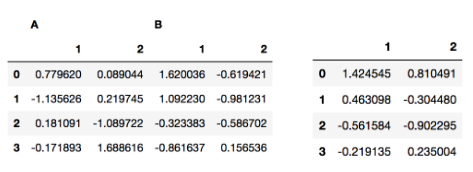
df["A"]
df["A"]["1"]
#loc,iloc 사용 가능pivot_table
데이터에서 필요한 자료만 뽑아 새롭게 요약할 때 사용
index 행 이덱스로 들어갈 key
column에 열 인덱스로 라벨링될 값
value에는 분석할 데이터
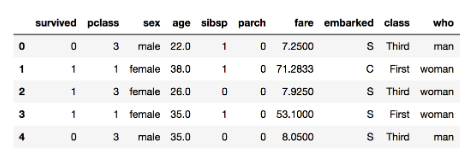
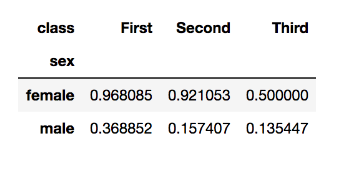
df.pivot_table(
index = 'sex',columns='class',value='survived',
#이 값을 어떻게 채울것인가? -평균값으로 채우겠습니다!
aggfunc=np.mean
)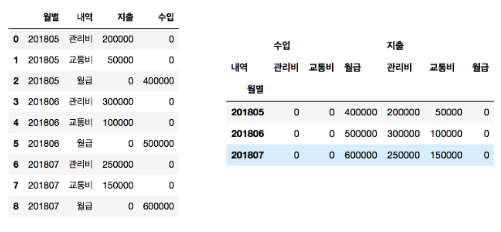
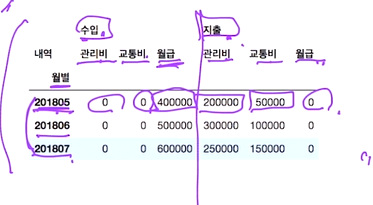
df.pivot_table(
index="월별",columns='내역',values=['수입','지출'])
🥰