< 썸네일 출처 >
https://www.bigocheatsheet.com/
시간복잡도
-
Q. 시간복잡도란 뭔가요?
A. 시간복잡도란 '입력을 나타내는 문자열 길이의 함수로서 작동하는 알고리즘의 시간을 정량화한 것' 입니다. -
Q. 시간복잡도가 왜 필요한가요?
A. 더 효율적인 알고리즘을 분간하기 위해서입니다. -
Q. 시간복잡도의 Big O notation 에는 왜 상수가 사용 안 되나요?
A. 무어의 법칙을 고려해 상수가 의미가 없기 때문입니다. 또한 개개의 컴퓨팅 차이도 있을텐데 상수까지 고려하면 너무 복잡해지기 때문입니다. -
Q. nlogn 의 시간복잡도를 가지는 알고리즘을 대보세요.
A. merge sort, quick sort 등이 있습니다.
시간복잡도는 원래 자료구조 기본의 떼우고나서 시작해야하는 개념인데, 알고리즘의 기본이자 골격을 이루는 내용인 만큼 그냥 이것부터 시작하련다.
시간복잡도. Time Complexity
시간복잡도의 정의는 ‘입력을 나타내는 문자열 길이의 함수로서 작동하는 알고리즘을 취해 시간을 정량화하는 것’ 이다. 이러한 시간복잡도는 크게 Big O 표현을 사용한다.
얼핏 보면 Big O 는 상수를 무시하는데 n^2 와 5n^2 을 똑같이 취급한다는 것이다. 둘은 분명히 다를텐데 왜 이렇게 취급은 하나?
첫째, 무어의 법칙에 의해 컴퓨팅의 속도는 대략적으로 2배씩 빨라진다.(사실 최근 이 증가세는 느려지고 있다고는 한다.) 즉, 지금은 2 이어도 내년에는 1안에 가능해진다. 이렇게 지수적으로 증가하는데 숫자는 큰 의미 없고 n 만이 의미가 있다. 그래서 상수는 모두 제거하고 표현을 한다.
둘째, 각 개개의 컴퓨팅의 속도가 다르다는 점을 고려해 상수를 제거한다. 만약 상수까지 철저히 고려했으면 컴퓨팅의 발전이 느려질 정도로 일이 많아진다. 그래서 이러한 상황을 피하기 위해 상수는 제거하고 입력량에 따라만 고려하게 n 만을 사용하기로 했다.
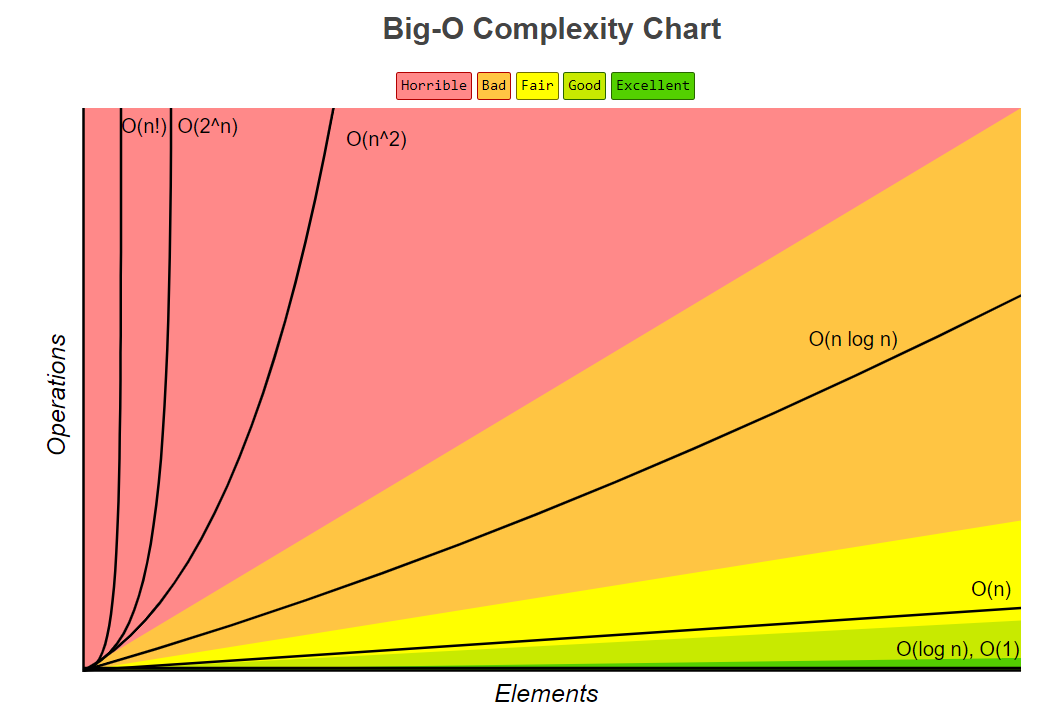
시간복잡도의 예시를 보자. O(n) : 보토 search 한번할때 나타나는 복잡도. N 만해도 사실 실생활에 아주 잘 접목을 시킬 수 있다.
O(1) : 딕셔너리나 인덱싱 같은 경우이다. 상수이며 바로 연산이 이루어진다.
O(logn) : 이진탐색에서 주로 나타난다. 로그의 알고리즘이 혼자서 쓰이는 경우는 거의 없고 n 번 돌려 총 nlogn 의 복잡도를 쉽게 찾아볼 수 있다.
O(nlogn) : sorting 에서 주로 나타난다. Sorting 으로 일반적으로 사용되는 merge sort 와 quick sort 이 해당되며 O(nlogn) 이 이제 실생활에 사용할 수 있는 복잡도의 마지노선이라고 생각해도 된다.
O(n^2) : for 문을 두번 겹치면 나타나는 복잡도. Sorting 중에서 bubble sort 등이 해당된다. O(n^2) 의 복잡도는 실용성이 매우 떨어진다.
O(2^n) : 회귀 Recursion 을 잘못 사용하면 나타날 수 있는 복잡도. 절대 나타나서는 안되며 이보다 좋은 알고리즘은 무조건 존재한다.
O(n!) : 팩토리얼. 그냥 망한 경우이며 얼른 바꾸자. 주로 시간복잡도의 중요성을 입증하기 위해 사용되며 망한 알고리즘과 효율적인 알고리즘에서 그 차이를 아주 잘 보여준다.
위의 그림과 같이 실질적으로 사용할 수 있는 시간복잡도는 O(nlogn) 이 마지노선이다. 실제 sorting 알고리즘들은 average 가 nlogn 인 것이 증명되기도 했다.
시간복잡도의 정의를 잘 알아두고 해당되는 예시들도 몇 개 알아두자.
