1. 문제
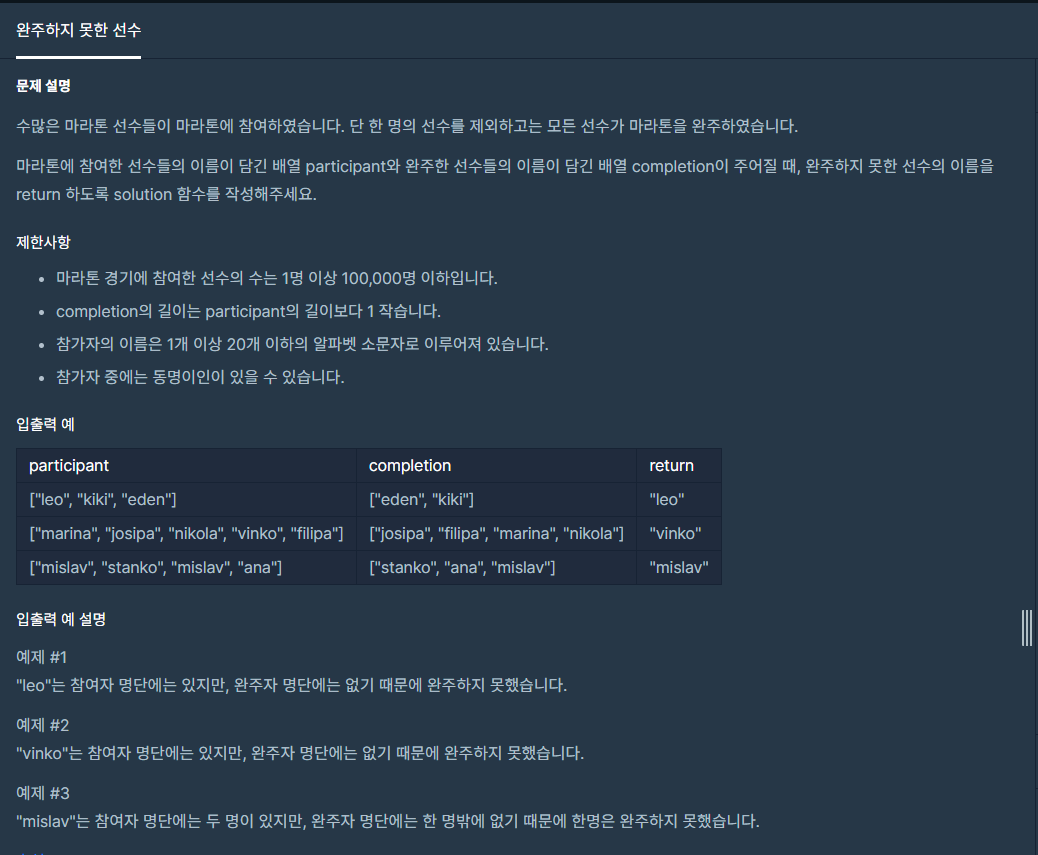
2. 나의 풀이
제한 사항에 보면 completion 은 participant의 길이보다 1 작다고 한다.
이는 완주하지 못한 선수가 한 명이라는 것을 뜻 함을 알 수 있었다.
그러므로 나는 단순하게 정렬된 participant와 completion 배열들의 이름을 순서대로
비교하여 일치하지 않는다면 그 사람은 completion 배열에 존재하지 않기 때문이므로
완주하지 못하였음을 알 수 있다고 판단하였다.
def solution(participant, completion):
participant.sort()
completion.sort()
for i in range(len(completion)):
if participant[i] != completion[i]:
return participant[i]3. 다른 풀이
다른 사람들은 collections 모듈의 .Counter 클래스를 사용하여 풀이하였다.
Counter로 각각 participant 와 completion의 선수 이름들의 빈도수를 계산하고
-를 통하여 participant에는 존재하지만 completion에는 존재하지 않는 선수를 찾고
list(answer.keys())를 통하여 answer의 key 값만 list 형태로 변환하였다.
import collections
def solution(participant, completion):
answer = collections.Counter(participant) - collections.Counter(completion)
return list(answer.keys())[0]4. 새로운 사실
collections 모듈의 .Counter()는 리스트 안의 단어 빈도를 세어
값이 큰 순서로 아래와 같이 반환해준다.
또한 Counter().most_common(n) 을 통하여
가장 개수가 많은 n개의 요소들을 반환할 수 있다.
import collections
word= 'HelloWorld'
print(collections.Counter(word))
#Counter({'l': 3, 'o': 2, 'H': 1, 'e': 1, 'W': 1, 'r': 1, 'd': 1})
print(collections.Counter(word).most_common(2))
#[('l', 3), ('o', 2)]Counter 끼리의 덧셈, 뺄셈이 가능하며, 뺄셈의 경우 기호 -와 subtract를 쓸 수 있는데
-를 쓸 경우 피연산자에서 동일한 요소가 없으면 계산이 무시되고
.subtract를 사용하면 요소가 -(negative)가 되어 피연산자에 저장이 된다.
import collections
A=collections.Counter(['A','B','C'])
B=collections.Counter(['B','C','D'])
print(A-B)
#Counter({'A': 1})
A.subtract(B)
print(A)
#Counter({'A': 1, 'B': 0, 'C': 0, 'D': -1})마지막으로 &(AND)와 |(OR) 연산 또한 가능한데 이는 논리회로와 비슷하게 동작한다.
A&B를 하게 되면 두 카운터의 공통된 값 중 작은 값이 반환되고
A|B를 하게 되면 두 카운터의 모든 값들과 공통된 값 중 큰 값이 반환됨을 볼 수 있었다.
import collections
A=collections.Counter(a=1,b=2)
B=collections.Counter(b=1,c=3)
print(A&B)
#Counter({'b': 1})
print(A|B)
#Counter({'c': 3, 'b': 2, 'a': 1})5. 출처
